blog
Using MySQL Galera Cluster Replication to Create a Geo-Distributed Cluster: Part One

It is quite common to see databases distributed across multiple geographical locations. One scenario for doing this type of setup is for disaster recovery, where your standby data center is located in a separate location than your main datacenter. It might as well be required so that the databases are located closer to the users.
The main challenge to achieving this setup is by designing the database in a way that reduces the chance of issues related to the network partitioning. One of the solutions might be to use Galera Cluster instead of regular asynchronous (or semi-synchronous) replication. In this blog we will discuss the pros and cons of this approach. This is the first part in a series of two blogs. In the second part we will design the geo-distributed Galera Cluster and see how ClusterControl can help us deploy such environment.
Why Galera Cluster Instead of Asynchronous Replication for Geo-Distributed Clusters?
Let’s consider the main differences between the Galera and regular replication. Regular replication provides you with just one node to write to, this means that every write from remote datacenter would have to be sent over the Wide Area Network (WAN) to reach the master. It also means that all proxies located in the remote datacenter will have to be able to monitor the whole topology, spanning across all data centers involved as they have to be able to tell which node is currently the master.
This leads to the number of problems. First, multiple connections have to be established across the WAN, this adds latency and slows down any checks that proxy may be running. In addition, this adds unnecessary overhead on the proxies and databases. Most of the time you are interested only in routing traffic to the local database nodes. The only exception is the master and only because of this proxies are forced to watch the whole infrastructure rather than just the part located in the local datacenter. Of course, you can try to overcome this by using proxies to route only SELECTs, while using some other method (dedicated hostname for master managed by DNS) to point the application to master, but this adds unnecessary levels of complexity and moving parts, which could seriously impact your ability to handle multiple node and network failures without losing data consistency.
Galera Cluster can support multiple writers. Latency is also a factor, as all nodes in the Galera cluster have to coordinate and communicate to certify writesets, it can even be the reason you may decide not to use Galera when latency is too high. It is also an issue in replication clusters – in replication clusters latency affects only writes from the remote data centers while the connections from the datacenter where master is located would benefit from a low latency commits.
In MySQL Replication you also have to take the worst case scenario in mind and ensure that the application is ok with delayed writes. Master can always change and you cannot be sure that all the time you will be writing to a local node.
Another difference between replication and Galera Cluster is the handling of the replication lag. Geo-distributed clusters can be seriously affected by lag: latency, limited throughput of the WAN connection, all of this will impact the ability of a replicated cluster to keep up with the replication. Please keep in mind that replication generates one to all traffic.
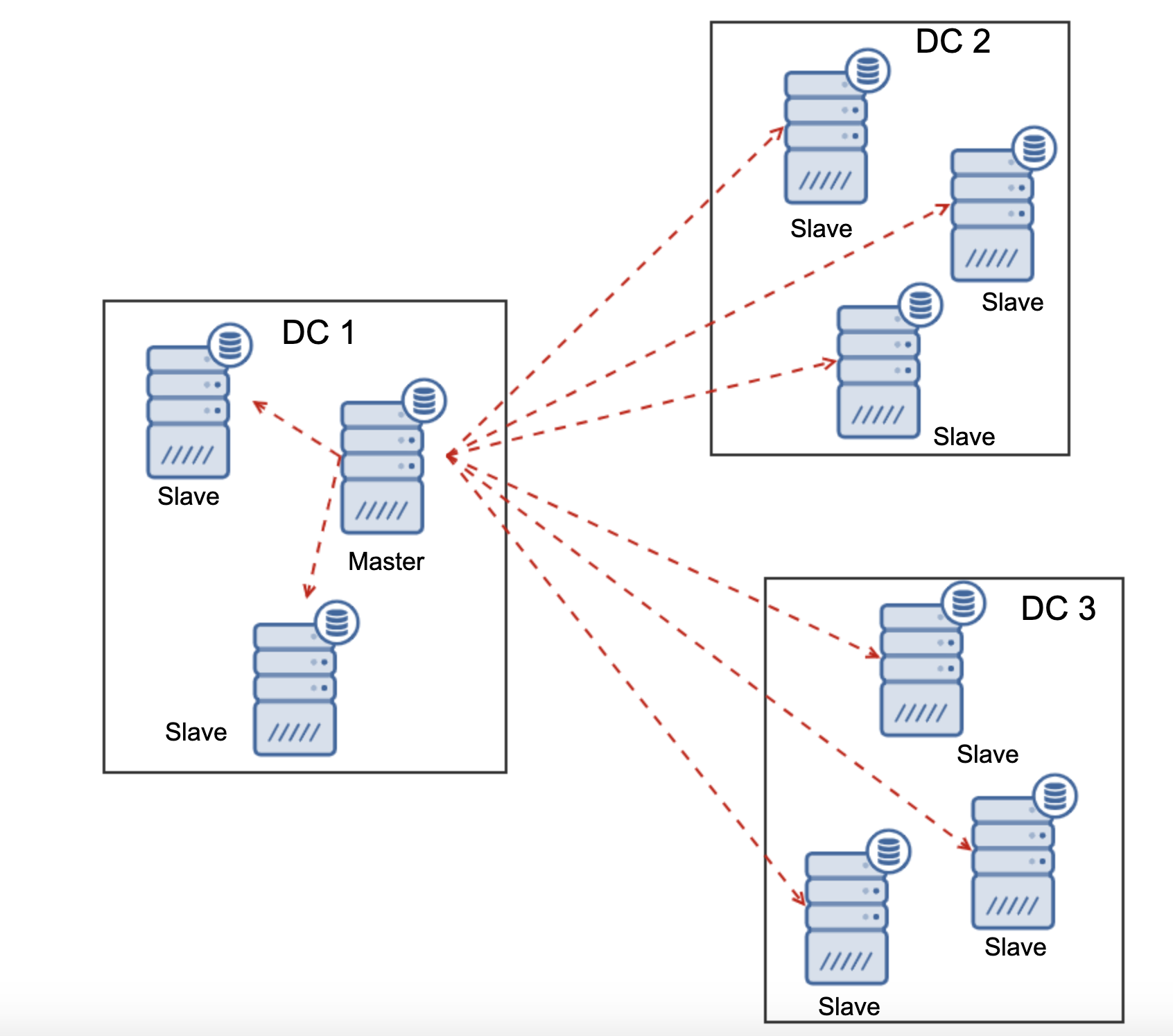
All slaves have to receive whole replication traffic – the amount of data you have to send to remote slaves over WAN increases with every remote slave that you add. This may easily result in the WAN link saturation, especially if you do plenty of modifications and WAN link doesn’t have good throughput. As you can see on the diagram above, with three data centers and three nodes in each of them master has to sent 6x the replication traffic over WAN connection.
With Galera cluster things are slightly different. For starters, Galera uses flow control to keep the nodes in sync. If one of the nodes start to lag behind, it has an ability to ask the rest of the cluster to slow down and let it catch up. Sure, this reduces the performance of the whole cluster, but it is still better than when you cannot really use slaves for SELECTs as they tend to lag from time to time – in such cases the results you will get might be outdated and incorrect.
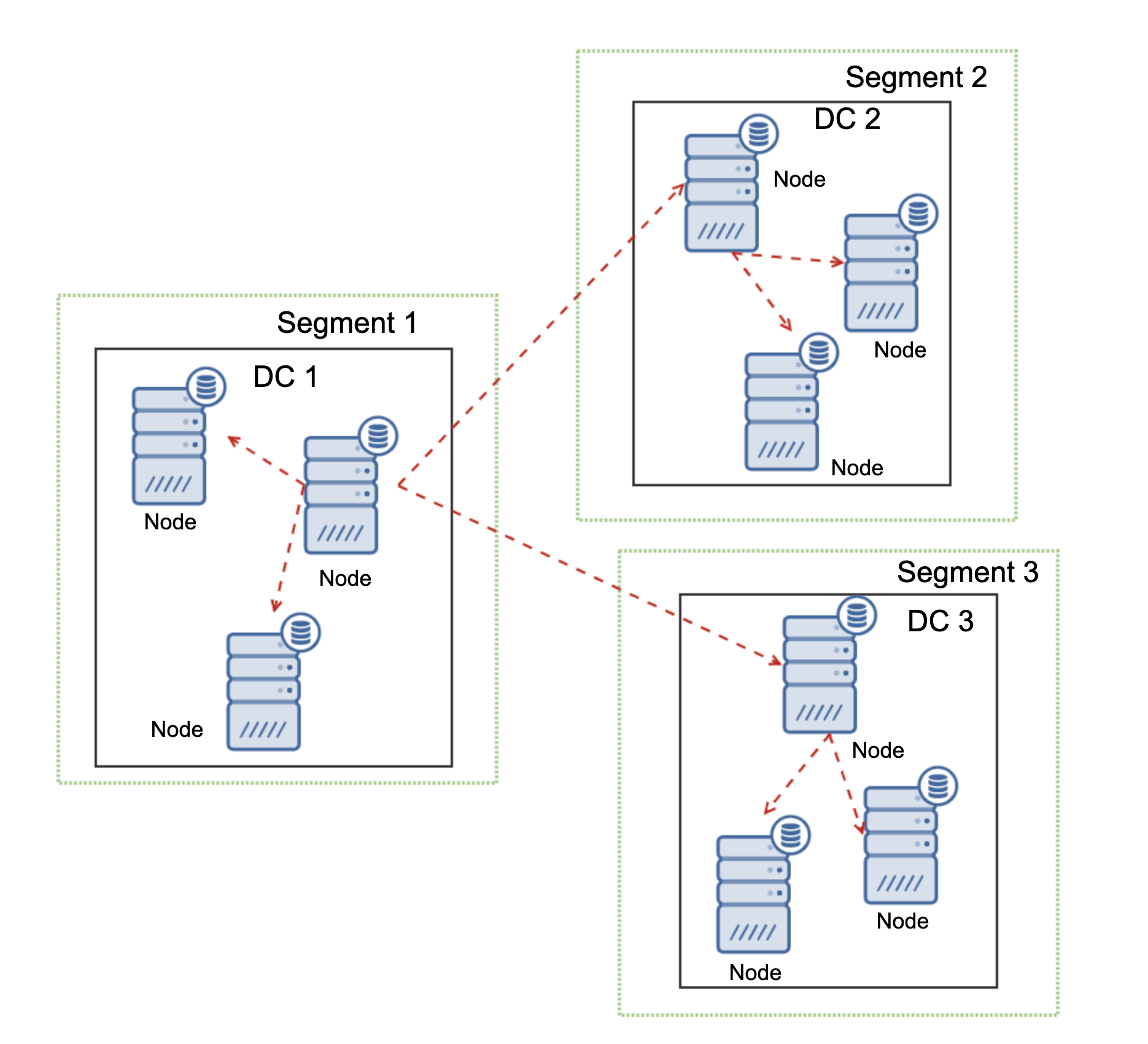
Another feature of Galera Cluster, which can significantly improve its performance when used over WAN, are segments. By default Galera uses all to all communication and every writeset is sent by the node to all other nodes in the cluster. This behavior can be changed using segments. Segments allow users to split Galera cluster in several parts. Each segment may contain multiple nodes and it elects one of them as a relay node. Such node receives writesets from other segments and redistribute them across Galera nodes local to the segment. As a result, as you can see on the diagram above, it is possible to reduce the replication traffic going over WAN three times – just two “replicas” of the replication stream are being sent over WAN: one per datacenter compared to one per slave in MySQL Replication.
Galera Cluster Network Partitioning Handling
Where Galera Cluster shines is the handling of the network partitioning. Galera Cluster constantly monitors the state of the nodes in the cluster. Every node attempts to connect with its peers and exchange the state of the cluster. If subset of nodes is not reachable, Galera attempts to relay the communication so if there is a way to reach those nodes, they will be reached.
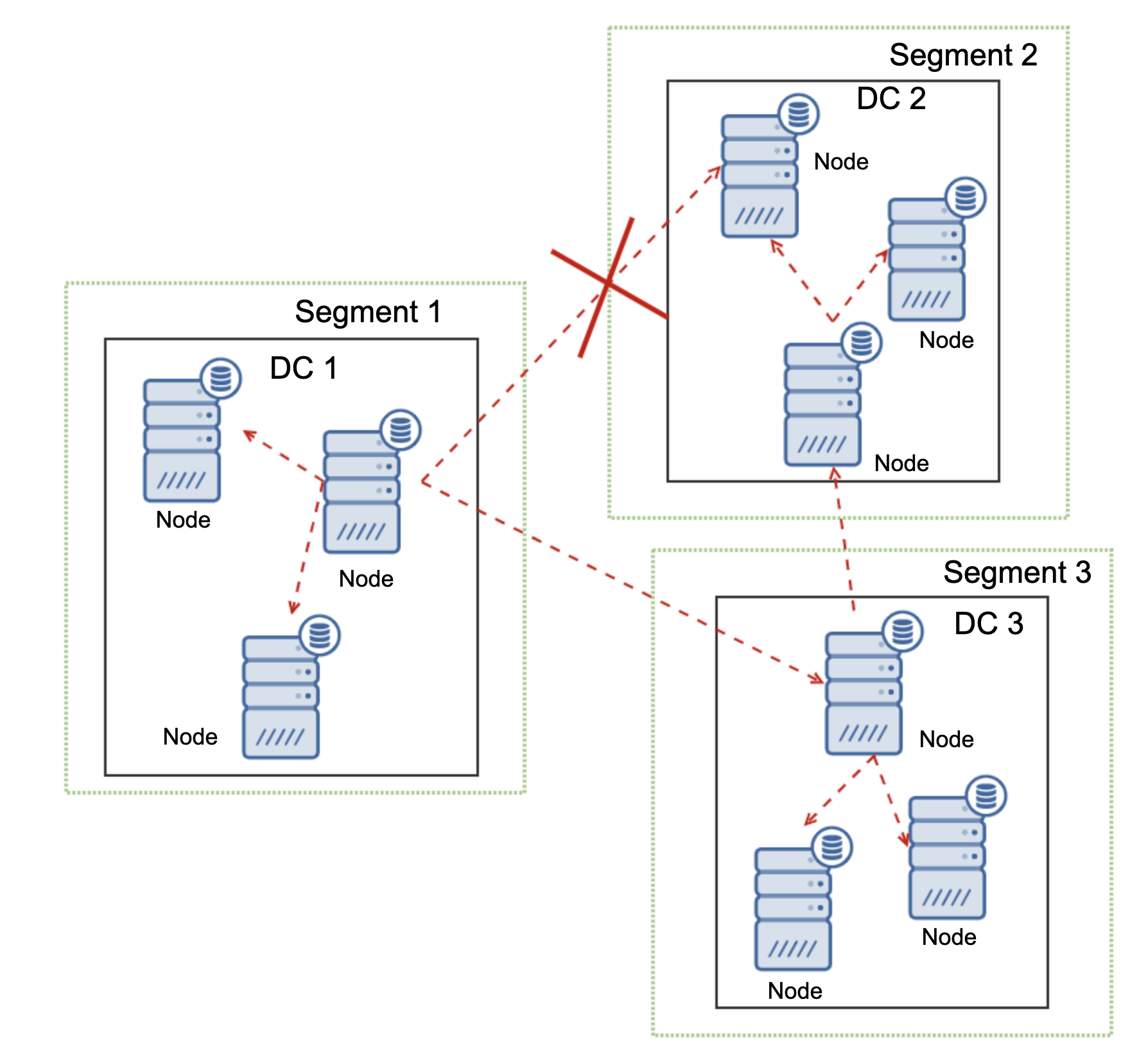
An example can be seen on the diagram above: DC 1 lost the connectivity with DC2 but DC2 and DC3 can connect. In this case one of the nodes in DC3 will be used to relay data from DC1 to DC2 ensuring that the intra-cluster communication can be maintained.
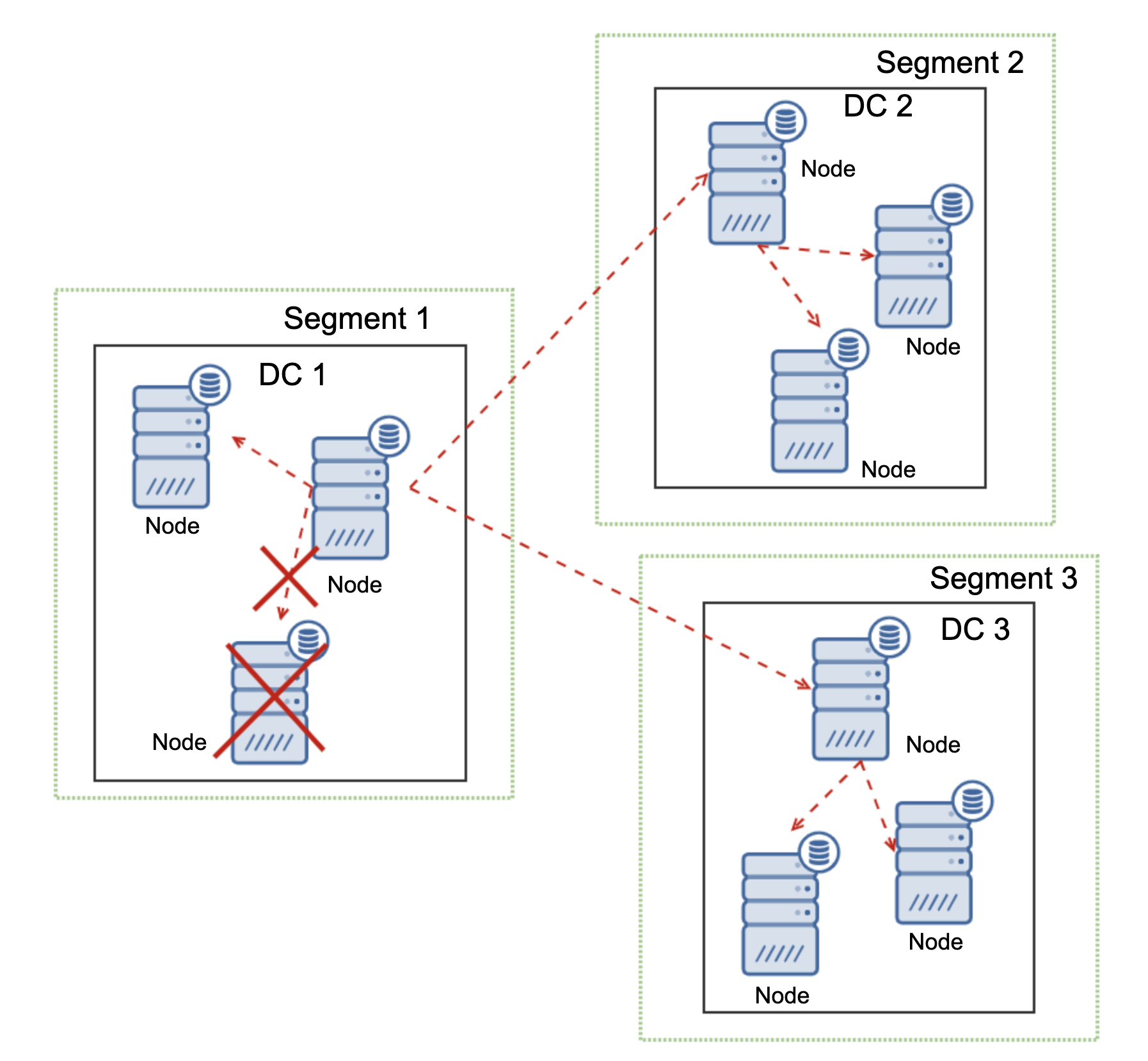
Galera Cluster is able to take actions based on the state of the cluster. It implements quorum – majority of the nodes have to be available in order for the cluster to be able to operate. If node gets disconnected from the cluster and cannot reach any other node, it will cease to operate.
As can be seen on the diagram above, there’s a partial loss of the network communication in DC1 and affected node is removed from the cluster, ensuring that the application will not access outdated data.
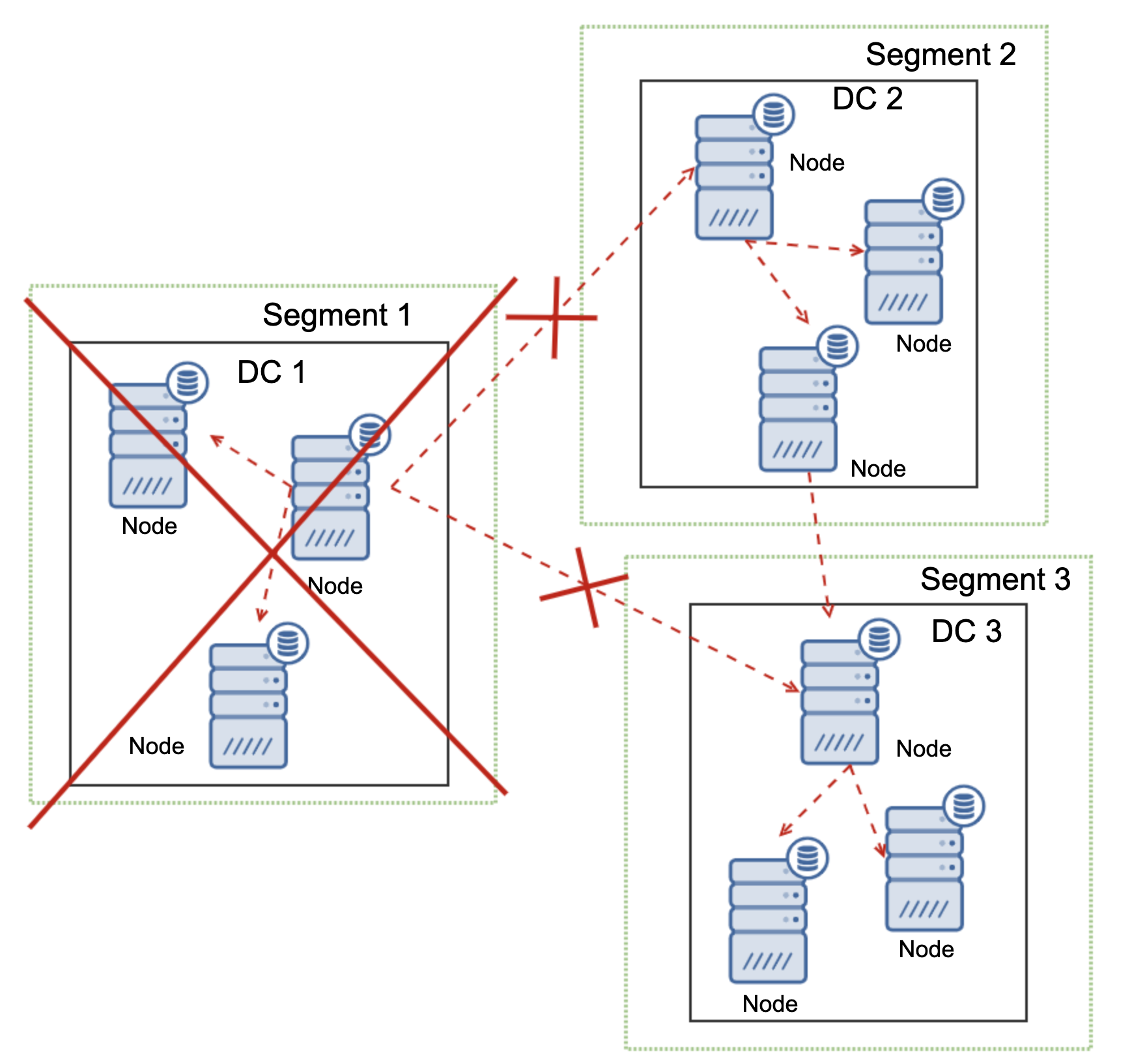
This is also true on a larger scale. The DC1 got all of its communication cut off. As a result, whole datacenter has been removed from the cluster and neither of its nodes will serve the traffic. The rest of the cluster maintained majority (6 out of 9 nodes are available) and it reconfigured itself to keep the connection between DC 2 and DC3. In the diagram above we assumed the write hits the node in DC2 but please keep in mind that Galera is capable of running with multiple writers.
MySQL Replication does not have any kind of cluster awareness, making it problematic to handle network issues. It cannot shut down itself upon losing connection with other nodes. There is no easy way of preventing old master to show up after the network split.
The only possibilities are limited to the proxy layer or even higher. You have to design a system, which would try to understand the state of the cluster and take necessary actions. One possible way is to use cluster-aware tools like Orchestrator and then run scripts that would check the state of the Orchestrator RAFT cluster and, based on this state, take required actions on the database layer. This is far from ideal because any action taken on a layer higher than the database, adds additional latency: it makes possible so the issue shows up and data consistency is compromised before correct action can be taken. Galera, on the other hand, takes actions on the database level, ensuring the fastest reaction possible.



