blog
Tips for Storing Your TimescaleDB Backups in the Cloud

Daniel Keys Moran says “You can have data without information, but you cannot have information without data”. Data is the key asset in every organization, if you lose the data then you lose information. This, in turn, may lead to bad business decisions or even the business not being able to operate. Having a Disaster Recovery Plan for your data is a must, and the cloud can be particularly helpful here. By leveraging cloud storage, you do not need to prepare storage for storing your backup data, or spend money upfront on expensive storage systems. Amazon S3 and Google Cloud Storage are great options as they are reliable, inexpensive, and durable.
We previously wrote about storing your PostgreSQL backups on AWS, and also on GCP. So let’s look at some tips for storing backups of your TimescaleDB data to AWS S3 and Cloud Storage.
Preparing Your AWS S3 Bucket
AWS provides a simple web interface for managing data in AWS S3. The term bucket is similar to a “directory” in the traditional terms of filesystem storage, it is a logical container for objects.
Creating a new bucket in S3 is easy, you can go directly to the S3 menu, and create a new bucket as shown below:
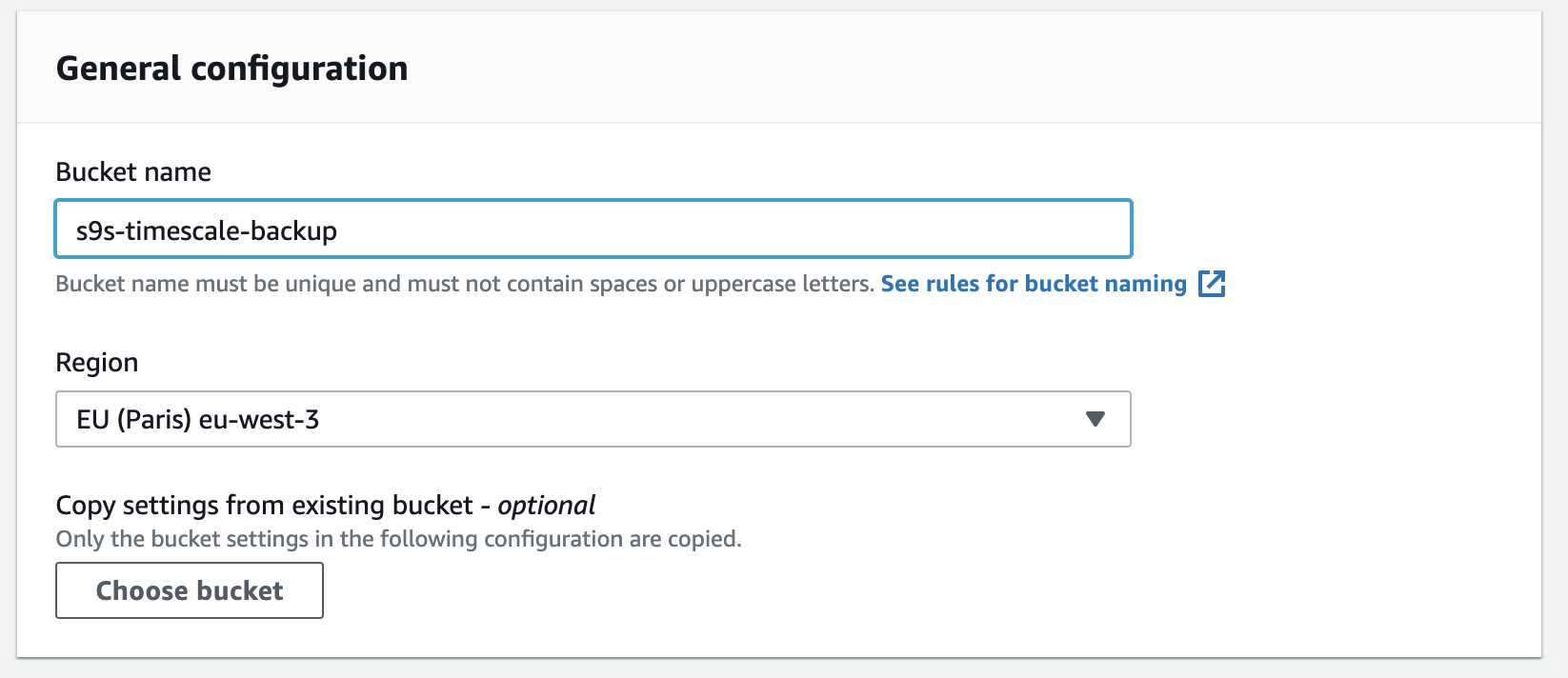
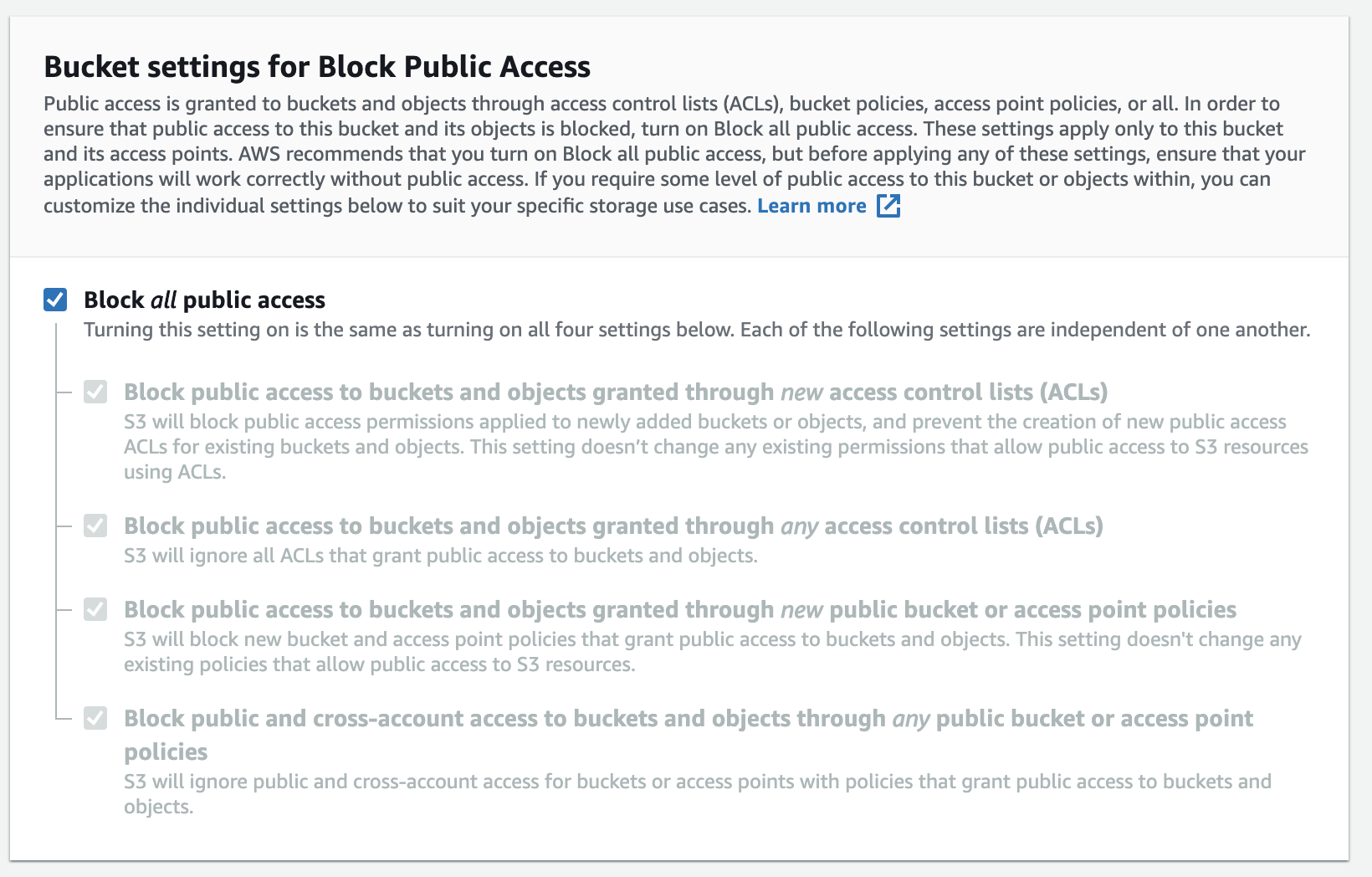
You need to fill the bucket-name, the name is globally unique on AWS as the namespace is shared across all AWS accounts. You can restrict access to the bucket from the Internet, or you can publish it with ACL restrictions. Encryption is an important practice in securing your backup data.
Preparing your Google Cloud Storage Bucket
To configure cloud storage in GCP, you can go to the Storage category, and choose the Storage -> Create Bucket. Fill the bucket name, similar to Amazon S3, and the bucket name is also globally unique in GCP.
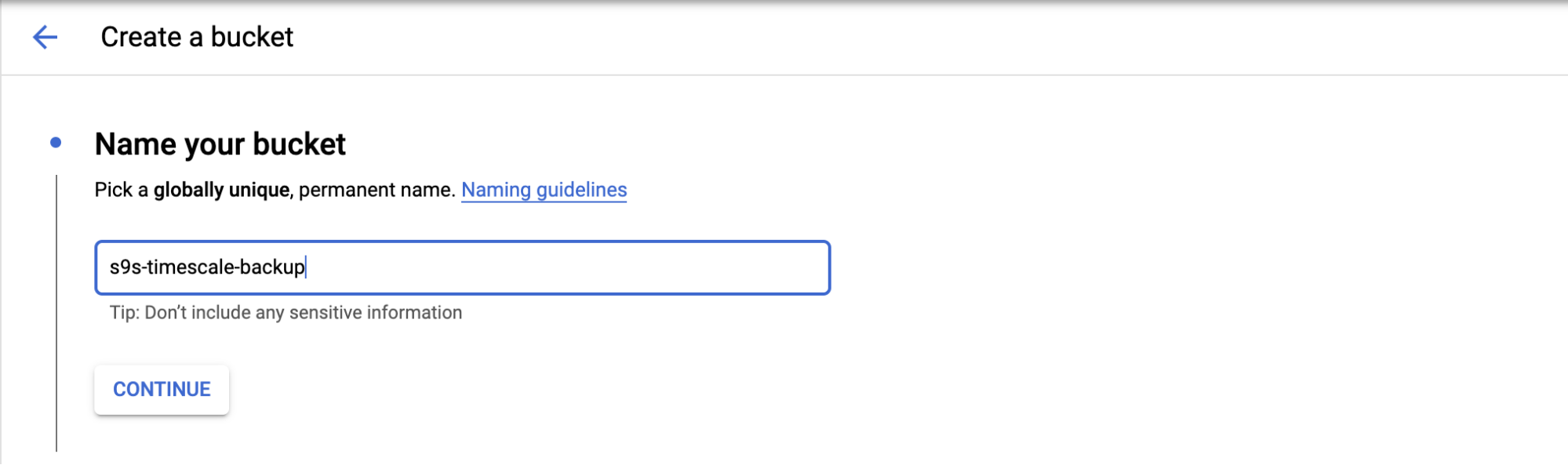
Choose where you will store your backup, there are three types of location; you can store in a single Region, Dual-Region, or Multi-Region.
Choose the type of storage class for your bucket, there are four categories which are; Standard, Nearline, Coldline, and Archive. Each category has criteria on how you can retrieve the data, and also the cost.

There are some advanced settings related to the encryption for the buckets, retention policy and access control.
Configure cloud storage utility
AWS CLI is an interface provided by AWS for interacting with AWS services such as S3, EC2, security groups, VPC, etc. through the command line. You can configure the AWS CLI on the node where the backup files reside before you transfer the files to S3. You can follow the installation procedure for AWS CLI here.
You can check your AWS CLI version by running below command:
root@n8:~# /usr/local/bin/aws --version
aws-cli/2.1.7 Python/3.7.3 Linux/4.15.0-91-generic exe/x86_64.ubuntu.18 prompt/offAfter that, you need to configure the Access Key and Secret Key from the server as below:
root@n8:~# aws configure
AWS Access Key ID [None]: AKIAREF*******AMKYUY
AWS Secret Access Key [None]: 4C6Cjb1zAIMRfYy******1T16DNXE0QJ3gEb
Default region name [None]: ap-southeast-1
Default output format [None]:Then you are ready to run and transfer the backup to your bucket.
$ aws s3 cp “/mnt/backups/BACKUP-1/full-backup-20201201.tar.gz” s3://s9s-timescale-backup/You can create a shell script for the above command and configure a scheduler for running daily.
GCP provides GSUtil Tool, which lets you access Cloud Storage through the command line. The installation procedure for GSUtil can be found here. After the installation, you can run gcloud init to configure the access to the GCP.
root@n8:~# gcloud initIt will prompt you for login to the Google Cloud by accessing URL and adding the authentication code.
After all configured, you can run the backup transfer to the Cloud Storage by running the following:
root@n8:~# gsutil cp /mnt/backups/BACKUP-1/full-backup-20201201.tar.gz gs://s9s-timescale-backup/Manage Your Backup with ClusterControl
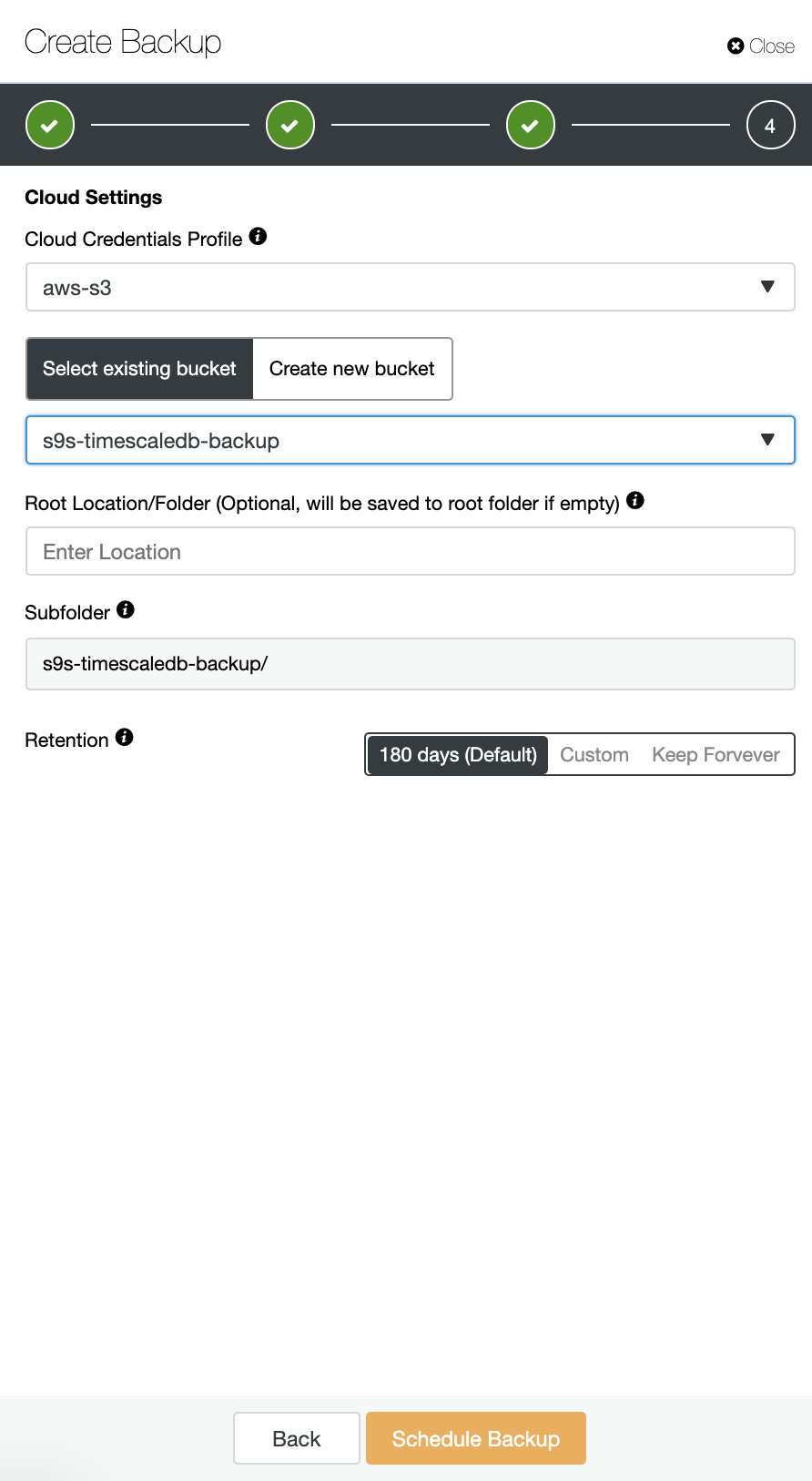
ClusterControl supports uploading your TimeScaleDB backups to the cloud. Currently we support Amazon AWS, Google Cloud Platform, and Microsoft Azure. To configure your TimescaleDB backup to the cloud is very straightforward, you can go to the Backup in your TimescaleDB cluster and Create Backup as shown below:
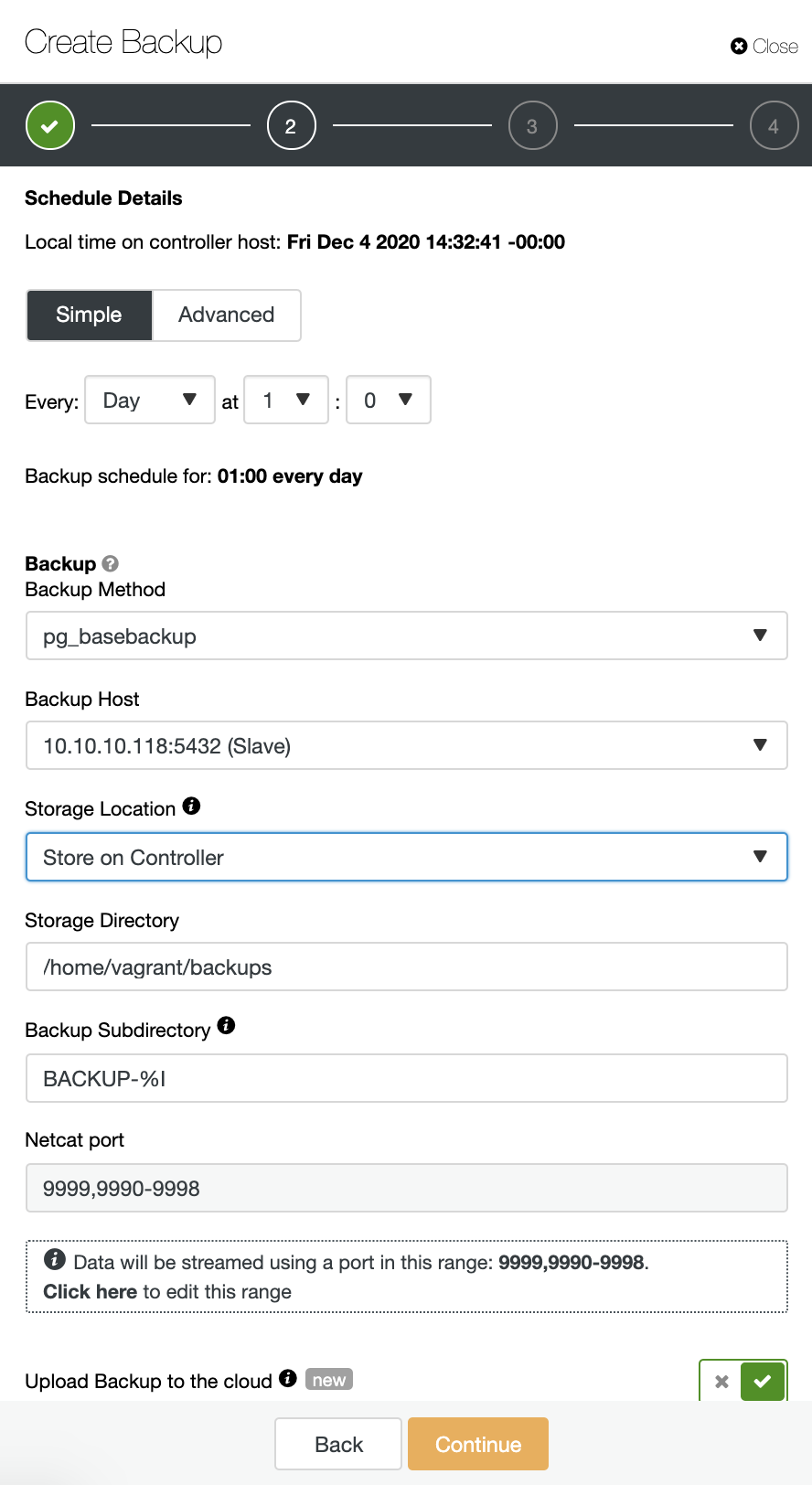
Enable the “Upload Backup to the cloud” option, and continue. It will prompt you to choose the cloud provider and fill the access and secret keys. In this case, I use AWS S3 as a backup provider in the cloud.
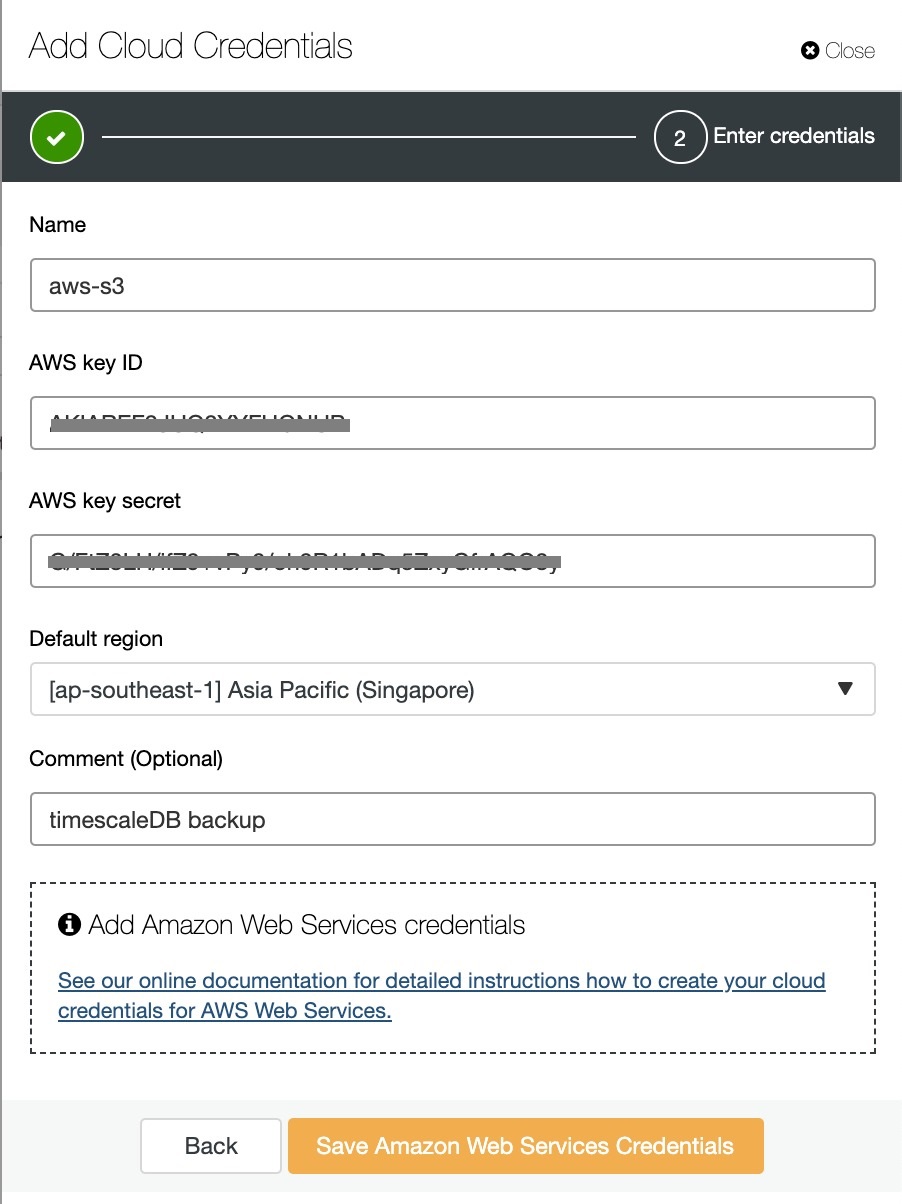
And finally, choose the bucket that had been created previously. You can configure retention of the backup and Schedule Backup as below: