blog
The hidden complexity of backup workflows in on-prem and hybrid environments

It’s the middle of the night, your most important application goes down, and your team confidently reaches for the backups. But then, disaster strikes. The backups are incomplete, out-of-date, or even corrupted. This is a common pitfall we call “hopeful backups.” The insidious nature of these “hopeful backups” lies in their deceptive simplicity: the backup process appears to run successfully, the logs show completion, and the storage reports capacity. However, without rigorous validation and testing, these seemingly successful operations are merely illusions, providing a false sense of security.
Backup essentials
Backups are far more intricate than merely duplicating your data. True mastery of backup management necessitates a rigorous approach to several critical areas, ensuring both the availability and integrity of your information in any unforeseen circumstance. This level of diligence is crucial for effective disaster recovery and business continuity.
Frequency and Retention
Establishing the most effective combination of full, incremental, and point-in-time backups is a crucial aspect of a robust data protection strategy. This involves a careful analysis of several factors to ensure data integrity, minimize recovery time objectives (RTOs), and meet recovery point objectives (RPOs) efficiently.
Full Backups
These create a complete copy of all data at a specific point in time. They are the most straightforward for restoration as they contain everything needed. However, full backups consume significant storage space and take the longest to complete, making them less frequent in many backup strategies. They are typically used as a foundational backup, often performed weekly or bi-weekly.
Incremental Backups
After an initial full backup, incremental backups only copy data that has changed since the last full or incremental backup. This dramatically reduces backup time and storage requirements. The challenge with incremental backups is that restoration can be more complex, requiring the recovery of the last full backup followed by all subsequent incremental backups in chronological order. This chain of dependencies means that if one incremental backup in the sequence is corrupted, the entire restoration process can be compromised. Incremental backups are often performed daily due to their efficiency.
Point-in-Time Backups
Essential for databases and transactional systems, this process necessitates a mix of full, incremental, and transaction-log backups. This combination allows for precise point-in-time recovery of the system’s state.
Factors to Consider for Optimal Combination
- Data Criticality: Highly critical data that cannot tolerate significant downtime or loss requires more frequent backups and potentially point-in-time solutions compared to less critical data.
- Recovery Time Objective (RTO): This defines the maximum acceptable downtime after a data loss event. Faster RTOs necessitate strategies that allow for quicker restoration, such as readily available full backups or snapshot-based recovery.
- Recovery Point Objective (RPO): This defines the maximum acceptable amount of data loss. Lower RPOs (less data loss) require more frequent backups, potentially daily incrementals, and point-in-time capabilities.
- Storage Capacity: The available storage for backups will influence the frequency of full backups and the retention policy for all backup types.
- Network Bandwidth: The speed of your network affects the time it takes to perform backups, especially full backups and transfers to off-site locations.
- Compliance Requirements: Regulatory requirements (e.g., GDPR, HIPAA) may dictate specific backup frequencies, retention periods, and encryption standards.
- Budget: The cost of backup software, hardware, and off-site storage will play a significant role in determining the feasible backup strategy.
- Data Change Rate: Applications with high data change rates will generate larger incremental backups and might benefit more from continuous data protection.
Testing Restores
In the critical realm of data management, simply scheduling backups and monitoring logs for errors is a common, yet potentially hazardous, practice. While the absence of error messages might offer a superficial sense of security, it doesn’t guarantee the fundamental objective of any backup strategy: successful data recovery. The stark reality is that the true efficacy of a backup can only be validated through a hands-on, practical restore process. Without this crucial step, organizations are operating under an assumption, rather than a confirmed fact, that their data is not only completely backed up but, more importantly, usable when disaster strikes.
To move beyond assumptions and establish genuine confidence in data recoverability, organizations must embed a rigorous restore verification program into their operational procedures. This program should, at a minimum, include automated restore drills and documented clear rollback procedures.
Two months before Black Friday, a retail company’s incremental backup chain silently malfunctioned, leading to creeping data corruption. Just three days before the major sales event, a routine monthly full backup revealed the devastating truth: the backup was incomplete, missing essential tables. This meant two months of incremental backups were corrupted or missing vital information, leaving their entire system vulnerable and historical data unreliable on the brink of their busiest season.
Hybrid Backup Complexity
Many organizations protect data using a dual approach:
- Local Backups: For rapid recovery (low RTO) from minor data loss or system failures, daily on-premises backups ensure quick restoration and business continuity.
- Cloud Replication: For durability and off-site safety, data is replicated to the cloud. This provides enhanced resilience via redundant infrastructure and safeguards against catastrophic local events with a geographically dispersed copy.
Beyond this, Cross-Region Disaster Recovery (DR) Storage offers even greater resilience by replicating data to an entirely separate geographical region, protecting against widespread regional failures. However, this introduces challenges:
- Network Latency: Impacts replication speed and restore times.
- Operational Overhead: Increases management complexity and data consistency efforts.
- Cost Implications: Higher data egress and storage fees.
In hybrid environments, a lack of central oversight often results from reliance on scripts or disparate tools. This can lead to blind spots, where failures may go unnoticed.
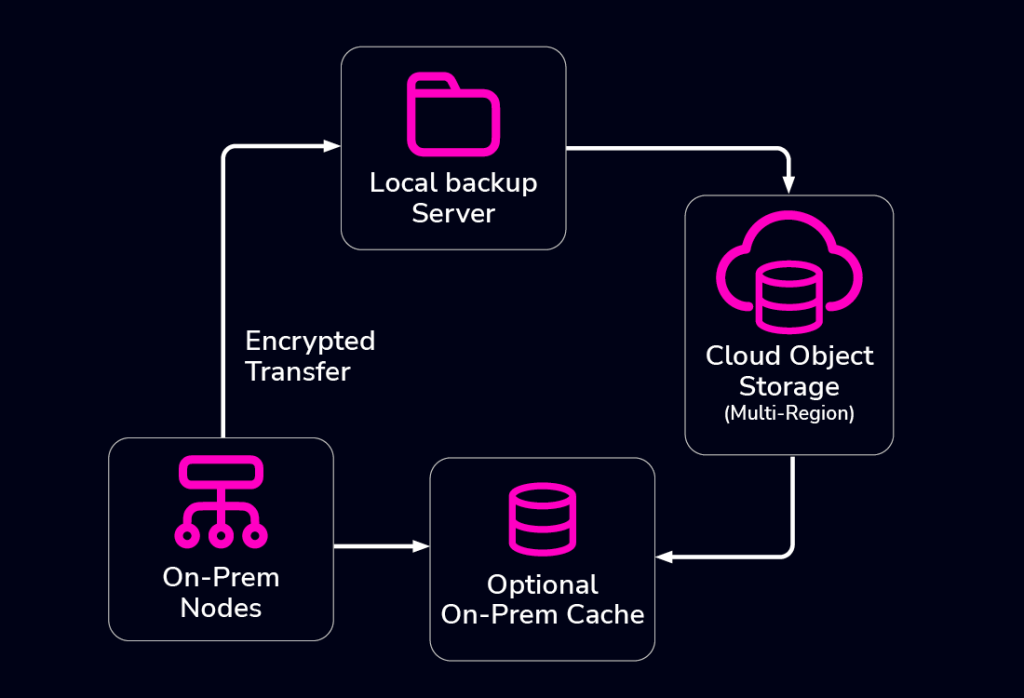
ClusterControl Backup Automation
Key Features
Central Dashboard: Unified view of backup status, history, and alerts—eliminating guesswork. ClusterControl streamlines and automates database cluster backup operations, providing:
- Scheduled Backups: Configure comprehensive policies for full, incremental, and point-in-time snapshots across all nodes.
- Encryption & Compression: Native support for data compression and encryption before transmission.
- Restore Validation: Automated dry-run restores and checksum verification to guarantee data integrity.
- Central Dashboard: A unified view of backup status, history, and alerts, removing all uncertainty.
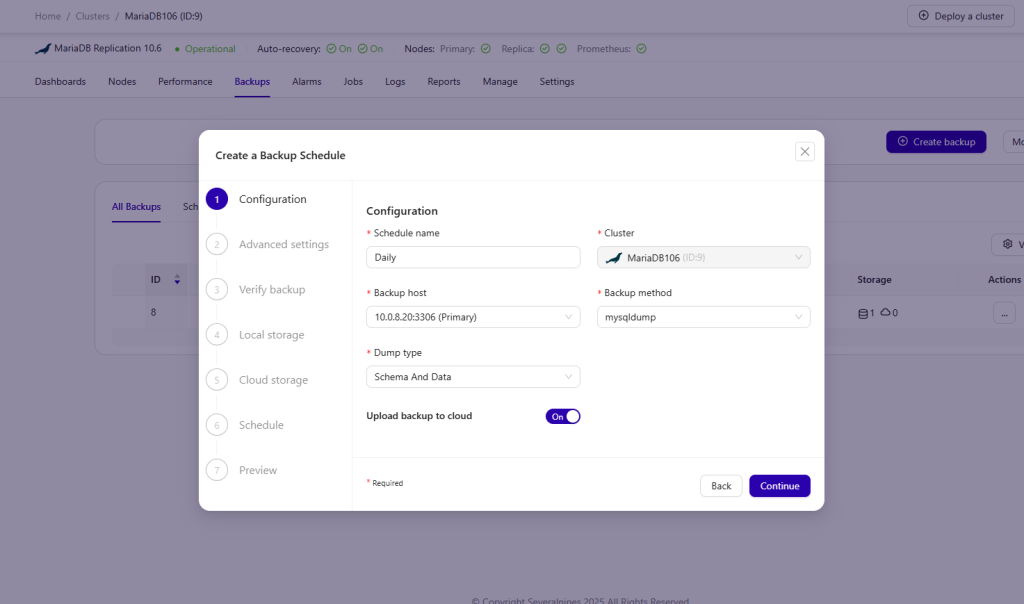
DIY Script Pitfalls
Many organizations initially gravitate towards do-it-yourself (DIY) backup scripts, viewing them as a cost-effective and flexible solution. However, this seemingly straightforward approach often conceals a multitude of complexities and potential pitfalls that can lead to significant challenges down the line. While DIY scripts offer a high degree of customization and control, their implementation and ongoing management demand a deeper understanding of underlying systems and a robust strategy for maintenance and error handling.
A cloud provider’s minor API change to their SDK caused an operations team’s Perl script to stop working. This went unnoticed for six months until an audit revealed a week’s worth of missed backups.
Wrapping up
The true value of a backup lies in the speed and reliability of its restoration. In the intricate landscape of on-premise and hybrid environments, fragmented solutions and unmonitored scripts can mask critical failures until a crisis hits. ClusterControl offers a centralized backup solution that mitigates these risks by providing:
- Granular scheduling for full, incremental, and log backups
- Built-in encryption, compression, and validation
- Centralized monitoring and proactive alerts
Regularly conduct restore drills using ClusterControl. This allows you to validate your backups, measure your recovery time objective, and ensure your data protection strategy is genuinely effective when it matters most. Try it out yourself by downloading ClusterControl for free using the instructions below.
Install ClusterControl in 10-minutes. Free 30-day Enterprise trial included!
Script Installation Instructions
The installer script is the simplest way to get ClusterControl up and running. Run it on your chosen host, and it will take care of installing all required packages and dependencies.
Offline environments are supported as well. See the Offline Installation guide for more details.
On the ClusterControl server, run the following commands:
wget https://severalnines.com/downloads/cmon/install-cc
chmod +x install-ccWith your install script ready, run the command below. Replace S9S_CMON_PASSWORD and S9S_ROOT_PASSWORD placeholders with your choice password, or remove the environment variables from the command to interactively set the passwords. If you have multiple network interface cards, assign one IP address for the HOST variable in the command using HOST=<ip_address>.
S9S_CMON_PASSWORD=<your_password> S9S_ROOT_PASSWORD=<your_password> HOST=<ip_address> ./install-cc # as root or sudo userAfter the installation is complete, open a web browser, navigate to https://<ClusterControl_host>/, and create the first admin user by entering a username (note that “admin” is reserved) and a password on the welcome page. Once you’re in, you can deploy a new database cluster or import an existing one.
The installer script supports a range of environment variables for advanced setup. You can define them using export or by prefixing the install command.
See the list of supported variables and example use cases to tailor your installation.
Other Installation Options
Helm Chart
Deploy ClusterControl on Kubernetes using our official Helm chart.
Ansible Role
Automate installation and configuration using our Ansible playbooks.
Puppet Module
Manage your ClusterControl deployment with the Puppet module.
ClusterControl on Marketplaces
Prefer to launch ClusterControl directly from the cloud? It’s available on these platforms:



