blog
Schema Management Tips for MySQL & MariaDB

Database schema is not something that is written in stone. It is designed for a given application, but then the requirements may and usually do change. New modules and functionalities are added to the application, more data is collected, code and data model refactoring is performed. Thereby the need to modify the database schema to adapt to these changes; adding or modifying columns, creating new tables or partitioning large ones. Queries change too as developers add new ways for users to interact with the data – new queries could use new, more efficient indexes so we rush to create them in order to provide the application with the best database performance.
So, how do we best approach a schema change? What tools are useful? How to minimize the impact on a production database? What are the most common issues with schema design? What tools can help you to stay on top of your schema? In this blog post we will give you a short overview of how to do schema changes in MySQL and MariaDB. Please note that we will not discuss schema changes in the context of Galera Cluster. We already discussed Total Order Isolation, Rolling Schema Upgrades and tips to minimize impact from RSU in previous blog posts. We will also discuss tips and tricks related to schema design and how ClusterControl can help you to stay on top of all schema changes.
Types of Schema Changes
First things first. Before we dig into the topic, we have to understand how MySQL and MariaDB perform schema changes. You see, one schema change is not equal to another schema change.
You may have heard about online alters, instant alters or in-place alters. All of this is a result of work which is ongoing to minimize the impact of the schema changes on the production database. Historically, almost all schema changes were blocking. If you executed a schema change, all of the queries will start to pile up, waiting for the ALTER to complete. Obviously, this posed serious issues for production deployments. Sure, people immediately start to look for workarounds, and we will discuss them later in this blog, as even today those are still relevant. But also, work started to improve capability of MySQL to run DDL’s (Data Definition Language) without much impact to other queries.
Instant Changes
Sometimes it is not needed to touch any data in the tablespace, because all that has to be changed is the metadata. An example here will be dropping an index or renaming a column. Such operations are quick and efficient. Typically, their impact is limited. It is not without any impact, though. Sometimes it takes couple of seconds to perform the change in the metadata and such change requires a metadata lock to be acquired. This lock is on a per-table basis, and it may block other operations which are to be executed on this table. You’ll see this as “Waiting for table metadata lock” entries in the processlist.
An example of such change may be instant ADD COLUMN, introduced in MariaDB 10.3 and MySQL 8.0. It gives the possibility to execute this quite popular schema change without any delay. Both MariaDB and Oracle decided to include code from Tencent Game which allows to instantly add a new column to the table. This is under some specific conditions; column has to be added as the last one, full text indexes cannot exist in the table, row format cannot be compressed – you can find more information on how instant add column works in MariaDB documentation. For MySQL, the only official reference can be found on mysqlserverteam.com blog, although a bug exists to update the official documentation.
In Place Changes
Some of the changes require modification of the data in the tablespace. Such modifications can be performed on the data itself, and there’s no need to create a temporary table with a new data structure. Such changes, typically (although not always) allow other queries touching the table to be executed while the schema change is running. An example of such operation is to add a new secondary index to the table. This operation will take some time to perform but will allow DML’s to be executed.
Table Rebuild
If it is not possible to make a change in place, InnoDB will create a temporary table with the new, desired structure. It will then copy existing data to the new table. This operation is the most expensive one and it is likely (although it doesn’t always happen) to lock the DML’s. As a result, such schema change is very tricky to execute on a large table on a standalone server, without help of external tools – typically you cannot afford to have your database locked for long minutes or even hours. An example of such operation would be to change the column data type, for example from INT to VARCHAR.
Schema Changes and Replication
Ok, so we know that InnoDB allow online schema changes and if we consult MySQL documentation, we will see that the majority of the schema changes (at least among the most common ones) can be performed online. What is the reason behind dedicating hours of development to create online schema change tools like gh-ost? We can accept that pt-online-schema-change is a remnant of the old, bad times but gh-ost is a new software.
The answer is complex. There are two main issues.
For starters, once you start a schema change, you do not have control over it. You can abort it but you cannot pause it. You cannot throttle it. As you can imagine, rebuilding the table is an expensive operation and even if InnoDB allows DML’s to be executed, additional I/O workload from the DDL affects all other queries and there’s no way to limit this impact to a level that is acceptable to the application.
Second, even more serious issue, is replication. If you execute a non-blocking operation, which requires a table rebuild, it will indeed not lock DML’s but this is true only on the master. Let’s assume such DDL took 30 minutes to complete – ALTER speed depends on the hardware but it is fairly common to see such execution times on tables of 20GB size range. It is then replicated to all slaves and, from the moment DDL starts on those slaves, replication will wait for it to complete. It does not matter if you use MySQL or MariaDB, or if you have multi-threaded replication. Slaves will lag – they will wait those 30 minutes for the DDL to complete before the commence applying the remaining binlog events. As you can imagine, 30 minutes of lag (sometimes even 30 seconds will be not acceptable – it all depends on the application) is something which makes impossible to use those slaves for scale-out. Of course, there are workarounds – you can perform schema changes from the bottom to the top of the replication chain but this seriously limits your options. Especially if you use row-based replication, you can only execute compatible schema changes this way. Couple of examples of limitations of row-based replication; you cannot drop any column which is not the last one, you cannot add a column into a position other than the last one. You cannot also change column type (for example, INT -> VARCHAR).
As you can see, replication adds complexity into how you can perform schema changes. Operations which are non-blocking on the standalone host become blocking while executed on slaves. Let’s take a look at couple of methods you can use to minimize the impact of schema changes.
Online Schema Change Tools
As we mentioned earlier, there are tools, which are intended to perform schema changes. The most popular ones are pt-online-schema-change created by Percona and gh-ost, created by GitHub. In a series of blog posts we compared them and discussed how gh-ost can be used to perform schema changes and how you can throttle and reconfigure an undergoing migration. Here we will not go into details, but we would still like to mention some of the most important aspects of using those tools. For starters, a schema change executed through pt-osc or gh-ost will happen on all database nodes at once. There is no delay whatsoever in terms of when the change will be applied. This makes it possible to use those tools even for schema changes that are incompatible with row-based replication. The exact mechanisms about how those tools track changes on the table is different (triggers in pt-osc vs. binlog parsing in gh-ost) but the main idea is the same – a new table is created with the desired schema and existing data is copied from the old table. In the meantime, DML’s are tracked (one way or the other) and applied to the new table. Once all the data is migrated, tables are renamed and the new table replaces the old one. This is atomic operation so it is not visible to the application. Both tools have an option to throttle the load and pause the operations. Gh-ost can stop all of the activity, pt-osc only can stop the process of copying data between old and new table – triggers will stay active and they will continue duplicating data, which adds some overhead. Due to the rename table, both tools have some limitations regarding foreign keys – not supported by gh-ost, partially supported by pt-osc either through regular ALTER, which may cause replication lag (not feasible if the child table is large) or by dropping the old table before renaming the new one – it’s dangerous as there’s no way to rollback if, for some reason, data wasn’t copied to the new table correctly. Triggers are also tricky to support.
They are not supported in gh-ost, pt-osc in MySQL 5.7 and newer has limited support for tables with existing triggers. Other important limitations for online schema change tools is that unique or primary key has to exist in the table. It is used to identify rows to copy between old and new tables. Those tools are also much slower than direct ALTER – a change which takes hours while running ALTER may take days when performed using pt-osc or gh-ost.
On the other hand, as we mentioned, as long as the requirements are satisfied and limitations won’t come into play, you can run all schema changes utilizing one of the tools. All will happen at the same time on all hosts thus you don’t have to worry about compatibility. You have also some level of control over how the process is executed (less in pt-osc, much more in gh-ost).
You can reduce the impact of the schema change, you can pause them and let them run only under supervision, you can test the change before actually performing it. You can have them track replication lag and pause should an impact be detected. This makes those tools a really great addition to the DBA’s arsenal while working with MySQL replication.
Rolling Schema Changes
Typically, a DBA will use one of the online schema change tools. But as we discussed earlier, under some circumstances, they cannot be used and a direct alter is the only viable option. If we are talking about standalone MySQL, you have no choice – if the change is non-blocking, that’s good. If it is not, well, there’s nothing you can do about it. But then, not that many people run MySQL as single instances, right? How about replication? As we discussed earlier, direct alter on the master is not feasible – most of the cases it will cause lag on the slave and this may not be acceptable. What can be done, though, is to execute the change in a rolling fashion. You can start with slaves and, once the change is applied on all of them, promote one of the slaves as a new master, demote the old master to a slave and execute the change on it. Sure, the change has to be compatible but, to tell the truth, the most common cases where you cannot use online schema changes is because of a lack of primary or unique key. For all other cases, there is some sort of workaround, especially in pt-online-schema-change as gh-ost has more hard limitations. It is a workaround you would call “so so” or “far from ideal”, but it will do the job if you have no other option to pick from. What is also important, most of the limitations can be avoided if you monitor your schema and catch the issues before the table grows. Even if someone creates a table without a primary key, it is not a problem to run a direct alter which takes half a second or less, as the table is almost empty.
If it will grow, this will become a serious problem but it is up to the DBA to catch this kind of issues before they actually start to create problems. We will cover some tips and tricks on how to make sure you will catch such issues on time. We will also share generic tips on how to design your schemas.
Tips and Tricks
Schema Design
As we showed in this post, online schema change tools are quite important when working with a replication setup therefore it is quite important to make sure your schema is designed in such a way that it will not limit your options for performing schema changes. There are three important aspects. First, primary or unique key has to exist – you need to make sure there are no tables without a primary key in your database. You should monitor this on a regular basis, otherwise it may become a serious problem in the future. Second, you should seriously consider if using foreign keys is a good idea. Sure, they have their uses but they also add overhead to your database and they can make it problematic to use online schema change tools. Relations can be enforced by the application. Even if it means more work, it still may be a better idea than to start using foreign keys and be severely limited to which types of schema changes can be performed. Third, triggers. Same story as with foreign keys. They are a nice feature to have, but they can become a burden. You need to seriously consider if the gains from using them outweight the limitations they pose.
Tracking Schema Changes
Schema change management is not only about running schema changes. You also have to stay on top of your schema structure, especially if you are not the only one doing the changes.
ClusterControl provides users with tools to track some of the most common schema design issues. It can help you to track tables which do not have primary keys:
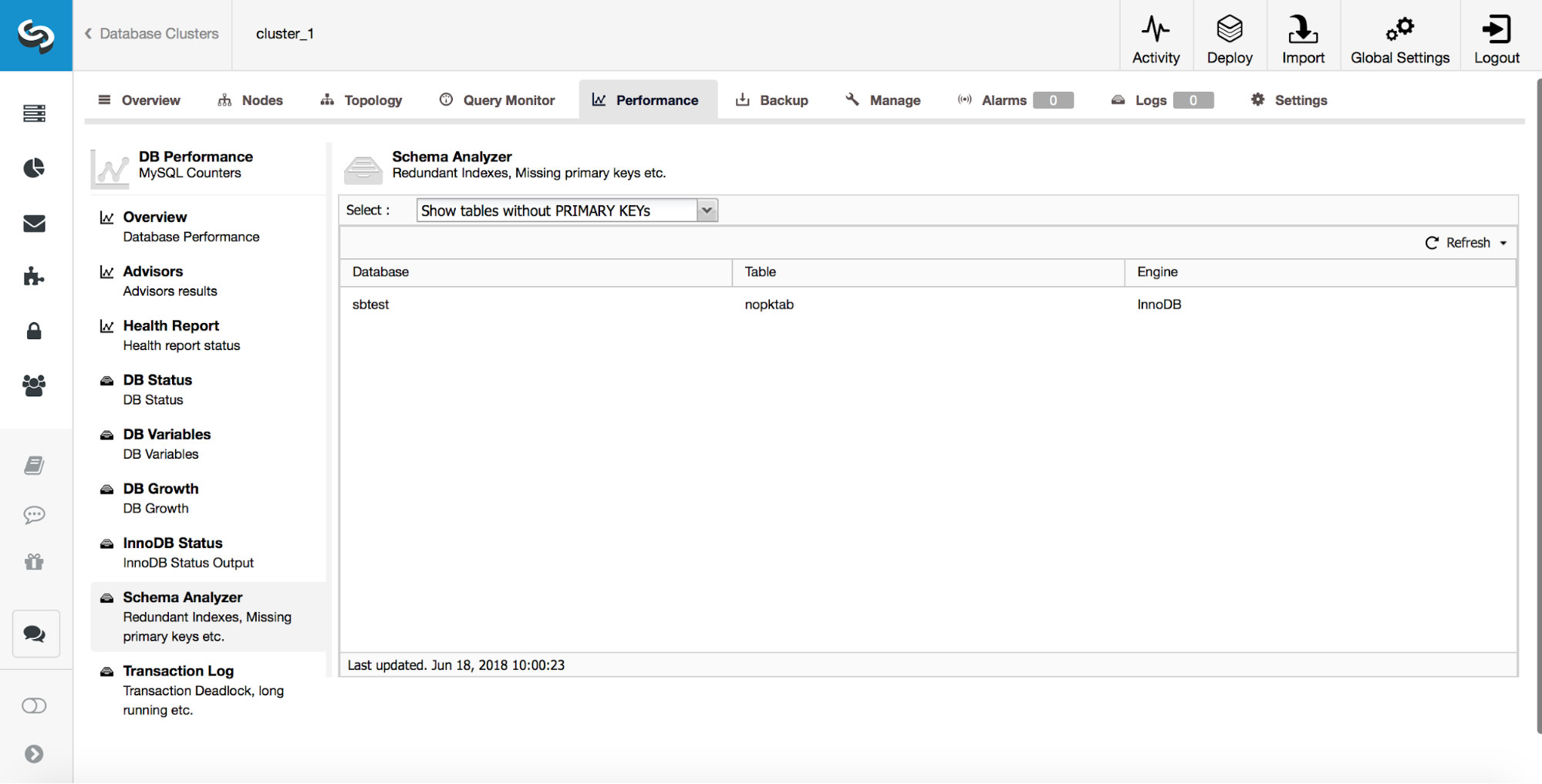
As we discussed earlier, catching such tables early is very important as primary keys have to be added using direct alter.
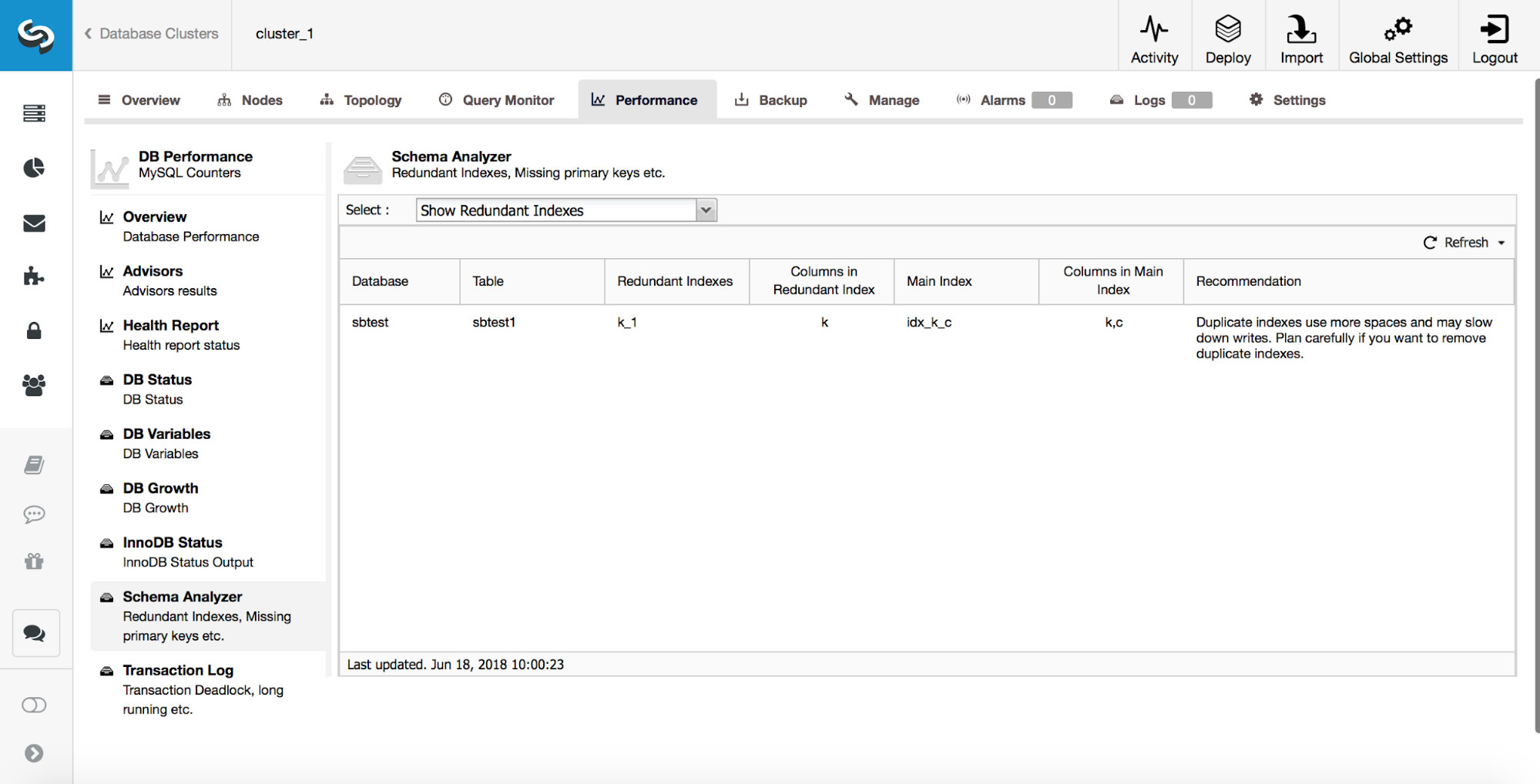
ClusterControl can also help you track duplicate indexes. Typically, you don’t want to have multiple indexes which are redundant. In the example above, you can see that there is an index on (k, c) and there’s also an index on (k). Any query which can use index created on column ‘k’ can also use a composite index created on columns (k, c). There are cases where it is beneficial to keep redundant indexes but you have to approach it on case by case basis. Starting from MySQL 8.0, it is possible to quickly test if an index is really needed or not. You can make a redundant index ‘invisible’ by running:
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 INVISIBLE;This will make MySQL ignore that index and, through monitoring, you can check if there was any negative impact on the performance of the database. If everything works as planned for some time (couple of days or even weeks), you can plan on removing the redundant index. In case you detected something is not right, you can always re-enable this index by running:
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 VISIBLE;Those operations are instant and the index is there all the time, and is still maintained – it’s only that it will not be taken into consideration by the optimizer. Thanks to this option, removing indexes in MySQL 8.0 will be much safer operation. In the previous versions, re-adding a wrongly removed index could take hours if not days on large tables.
ClusterControl can also let you know about MyISAM tables.
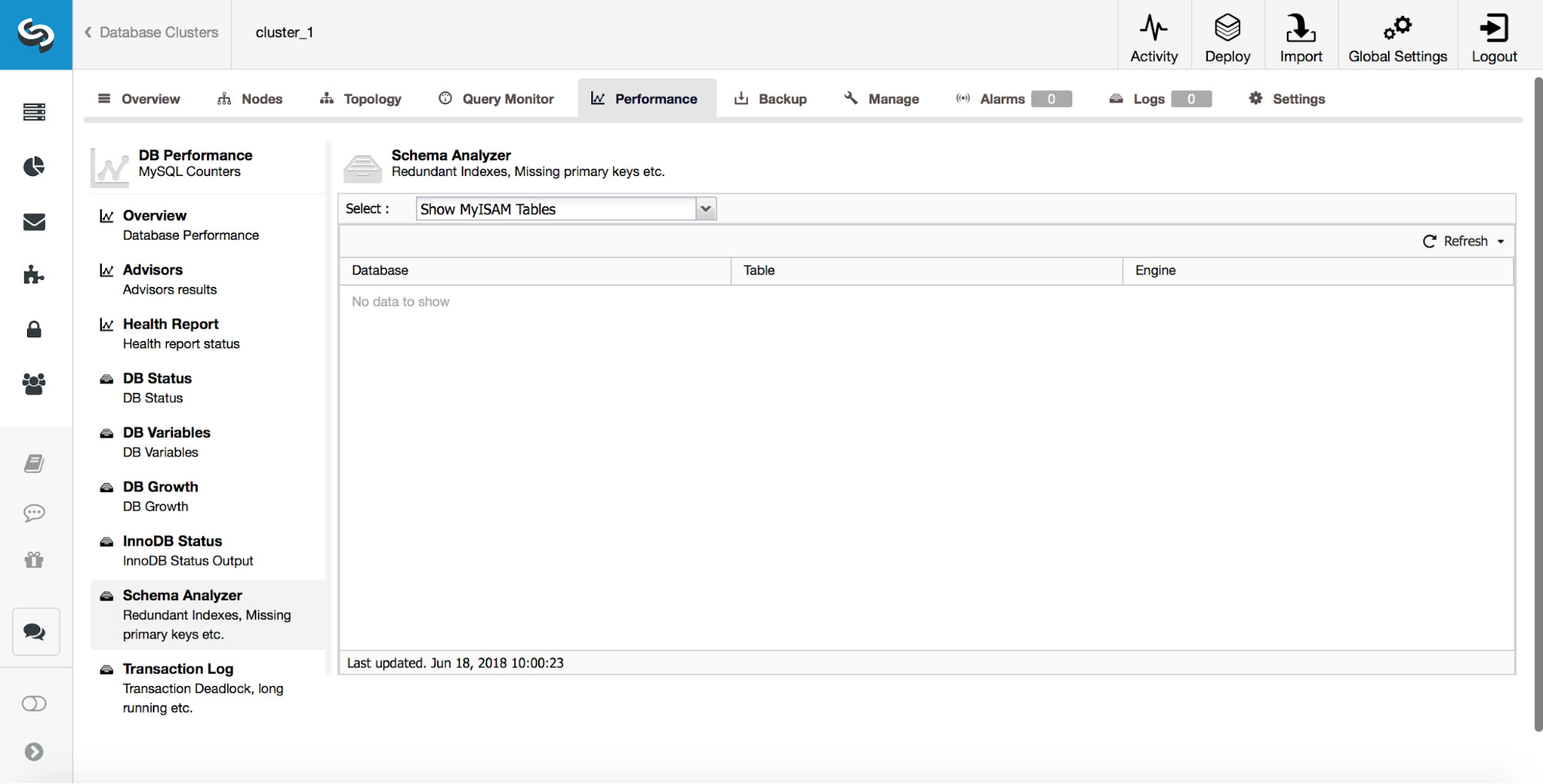
While MyISAM still may have its uses, you have to keep in mind that it is not a transactional storage engine. As such, it can easily introduce data inconsistency between nodes in a replication setup.
Another very useful feature of ClusterControl is one of the operational reports – a Schema Change Report.
In an ideal world, a DBA reviews, approves and implements all of the schema changes. Unfortunately, this is not always the case. Such review process just does not go well with agile development. In addition to that, Developer-to-DBA ratio typically is quite high which can also become a problem as DBA’s would struggle not to become a bottleneck. That’s why it is not uncommon to see schema changes performed outside of the DBA’s knowledge. Yet, the DBA is usually the one responsible for the database’s performance and stability. Thanks to the Schema Change Report, they can now keep track of the schema changes.
At first some configuration is needed. In a configuration file for a given cluster (/etc/cmon.d/cmon_X.cnf), you have to define on which host ClusterControl should track the changes and which schemas should be checked.
schema_change_detection_address=10.0.0.126
schema_change_detection_databases=sbtestOnce that’s done, you can schedule a report to be executed on a regular basis. An example output may be like below:
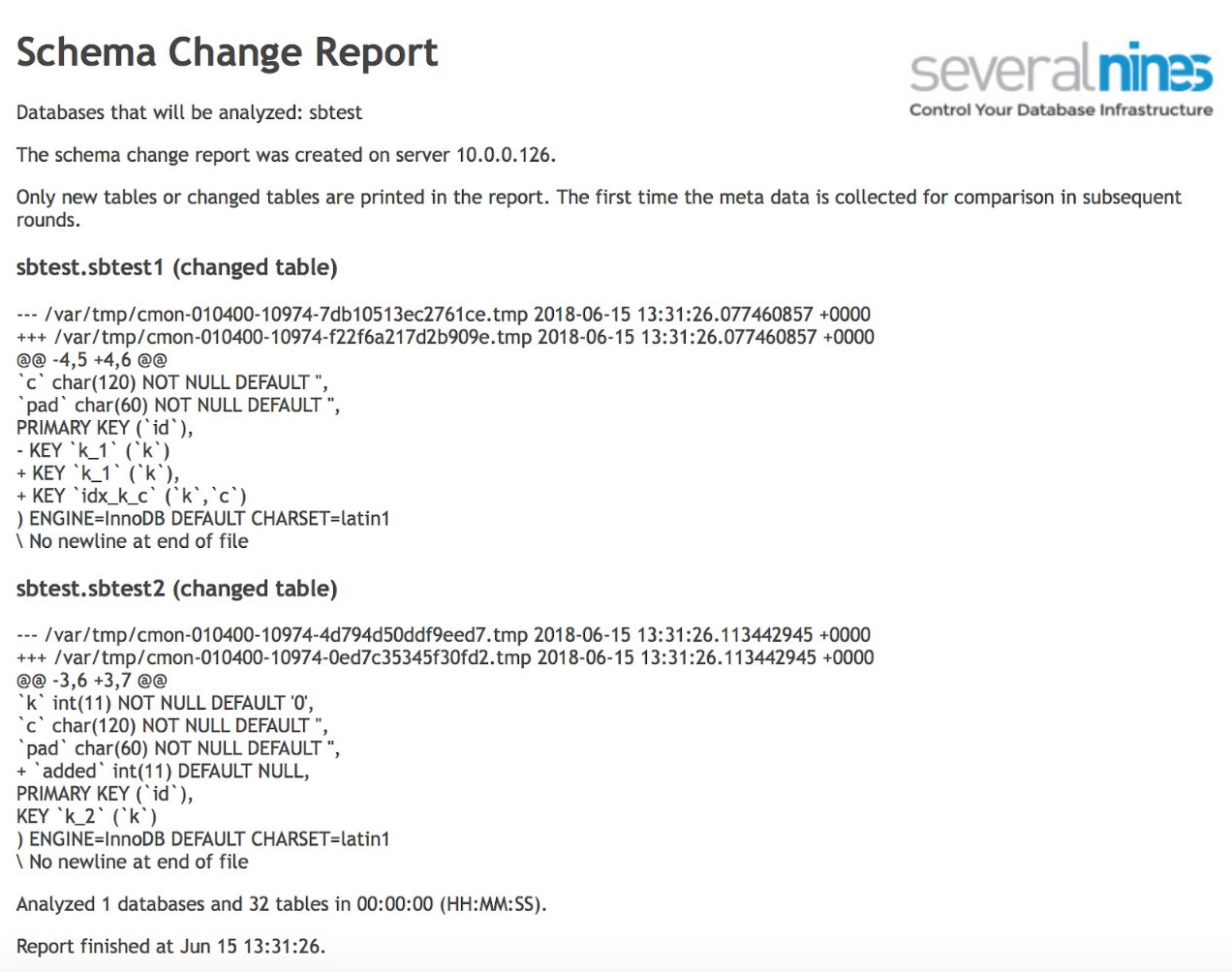
As you can see, two tables have changed since the previous run of the report. In the first one, a new composite index has been created on columns (k, c). In the second table, a column was added.
In the subsequent run we got information about new table, which was created without any index or primary key. Using this kind of info, we can easily act when it is needed and solve the issues before they actually start to become blockers.



