blog
PostgreSQL Replication for Disaster Recovery

With Disaster Recovery, we aim to set up systems to handle anything that could go wrong with our database. What happens if the database crashes? What if a developer accidently truncates a table? What if we find out some data was deleted last week but we didn’t notice it until today? These things happen, and having a solid plan and system in place will make the DBA look like a hero when everyone else’s hearts have already stopped when a disaster rears its ugly head.
Any database that has any sort of value should have a way to implement one or more Disaster Recovery options. PostgreSQL has a very solid replication system built in, and is flexible enough to be set up in many configurations to aid with Disaster Recovery, should anything go wrong. We’ll focus on scenarios like questioned above, how to set up our Disaster Recovery options, and the benefits of each solution.
High Availability
With streaming replication in PostgreSQL, High Availability is simple to set up and maintain. The goal is to provide a failover site that can be promoted to master if the main database goes down for any reason, such as hardware failure, software failure, or even network outage. Hosting a replica on another host is great, but hosting it in another data center is even better.
For specifics for setting up streaming replication, Severalnines has a detailed deep dive available here. The official PostgreSQL Streaming Replication Documentation has detailed information on the streaming replication protocol and how it all works.
A standard setup will look like this, a master database accepting read / write connections, with a replica database receiving all WAL activity in near real-time, replaying all data change activity locally.
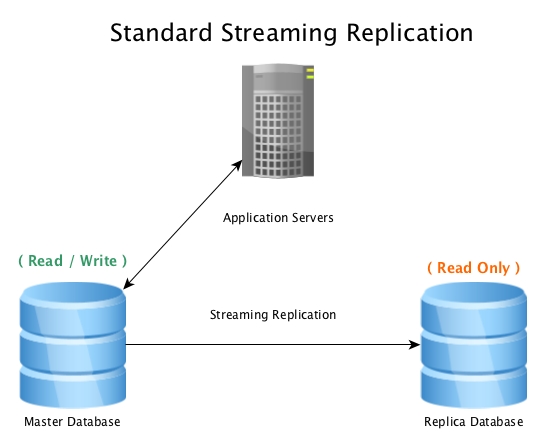
When the master database becomes unusable, a failover procedure is initiated to bring it offline, and promote the replica database to master, then pointing all connections to the newly promoted host. This can be done by either reconfiguring a load balancer, application configuration, IP aliases, or other clever ways to redirect the traffic.
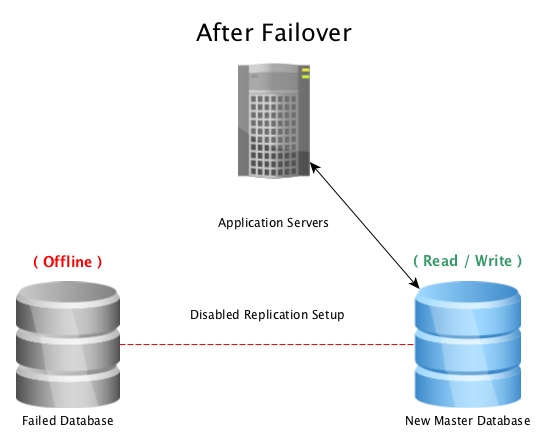
When disaster hits a master database (such as a hard drive failure, power outage, or anything that prevents the master from working as intended) , failing over to a hot standby is the quickest way to stay online serving queries to applications or customers without serious downtime. The race is then on to either fix the failed database host, or bring a new replica online to maintain the safety net of having a standby ready to go. Having multiple standbys will ensure that the window after a disastrous failure is also ready for a secondary failure, however unlikely it may seem.
Note: When failing over to a streaming replica, it will pick up where the previous master left off, so this helps with keeping the database online, but not recovering accidentally lost data.
Point In Time Recovery
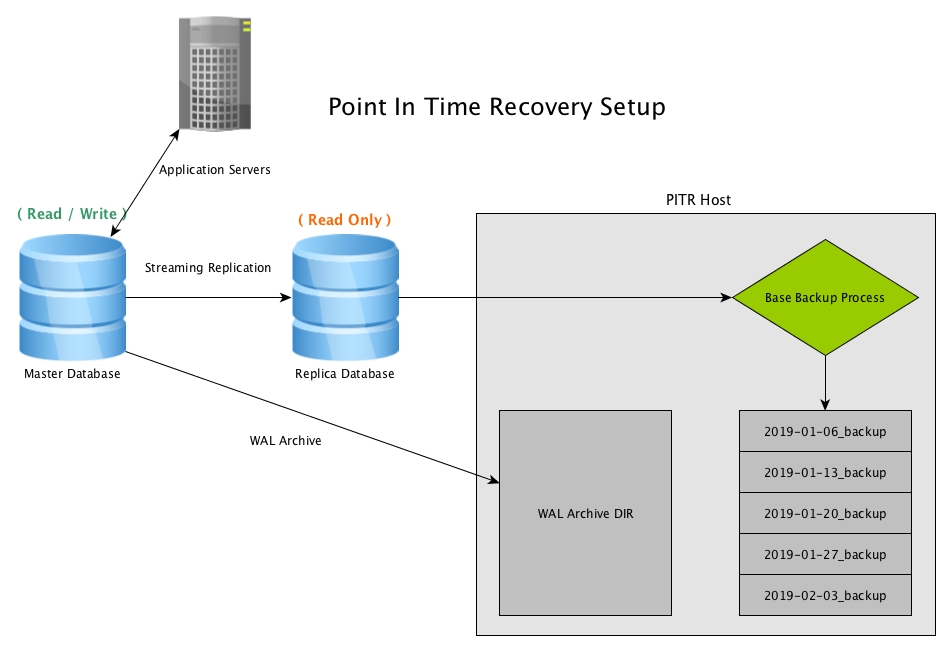
Another Disaster Recovery option is Point in TIme Recovery (PITR). With PITR, a copy of the database can be brought back at any point in time we want, so long as we have a base backup from before that time, and all WAL segments needed up till that time.
A Point In Time Recovery option isn’t as quickly brought online as a Hot Standby, however the main benefit is being able to recover a database snapshot before a big event such as a deleted table, bad data being inserted, or even unexplainable data corruption. Anything that would destroy data in such a way where we would want to get a copy before that destruction, PITR saves the day.
Point in Time Recovery works by creating periodic snapshots of the database, usually by use of the program pg_basebackup, and keeping archived copies of all WAL files generated by the master
Point In Time Recovery Setup
Setup requires a few configuration options set on the master, some of which are good to go with default values on the current latest version, PostgreSQL 11. In this example, we’ll be copying the 16MB file directly to our remote PITR host using rsync, and compressing them on the other side with a cron job.
WAL Archiving
Master postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p postgres@pitrseveralnines:/mnt/db/wal_archive/%f'NOTE: The setting archive_command can be many things, the overall goal is to send all archived WAL files away to another host for safety purposes. If we lose any WAL files, PITR past the lost WAL file becomes impossible. Let your programming creativity go crazy, but make sure it’s reliable.
[Optional] Compress the archived WAL files:
Every setup will vary somewhat, but unless the database in question is very light in data updates, the buildup of 16MB files will fill up drive space fairly quickly. An easy compression script, set up through cron, could look like below.
compress_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]NOTE: During any recovery method, any compressed files will need to be decompressed later. Some administrators opt to only compress files after they are X number of days old, keeping overall space low, but also keeping more recent WAL files ready for recovery without extra work. Choose the best option for the databases in question to maximize your recovery speed.
Base Backups
One of the key components to a PITR backup is the base backup, and the frequency of base backups. These can be hourly, daily, weekly, monthly, but chose the best option based on recovery needs as well as the traffic of the database data churn. If we have weekly backups every Sunday, and we need to recover all the way to Saturday afternoon, then we bring the previous Sunday’s base backup online with all the WAL files between that backup and Saturday afternoon. If this recovery process takes 10 hours to process, this is likely undesirably too long, Daily base backups will reduce that recovery time, since the base backup would be from that morning, but also increase the amount of work on the host for the base backup itself.
If a week long recovery of WAL files takes just a few minutes, because the database sees low churn, then weekly backups are fine. The same data will exist in the end, but how fast you’re able to access it is the key.
In our example, we’ll set up a weekly base backup, and since we are using Streaming Replication for High Availability, as well as reducing the load on the master, we’ll be creating the base backup off of the replica database.
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h -p -U replication -D $backup_dir -Ft -z NOTE: The pg_basebackup command assumes this host is set up for passwordless access for user ‘replication’ on the master, which can be done either by ‘trust’ in pg_hba for this PITR backup host, password in the .pgpass file, or other more secure ways. Keep security in mind when setting up backups.
PITR Recovery Scenario
Setting up Point In Time Recovery is only part of the job, having to recover data is the other part. With good luck, this may never have to happen, however it’s highly suggested to periodically do a restoration of a PITR backup to validate that the system does work, and to make sure the process is known / scripted correctly.
In our test scenario, we’ll choose a point in time to recover to and initiate the recovery process. For example: Friday morning, a developer pushes a new code change to production without going through a code review, and it destroys a bunch of important customer data. Since our Hot Standby is always in sync with the master, failing over to it wouldn’t fix anything, as it would be the same data. PITR backups is what will save us.
The code push went in at 11 AM, so we need to restore the database to just before that time, 10:59 AM we decide, and luckily we do daily backups so we have a backup from midnight this morning. Since we don’t know what all was destroyed, we also decide to do a full restore of this database on our PITR host, and bring it online as the master, as it has the same hardware specifications as the master, just in case this scenario happened.
Shutdown The Master
Since we decided to restore fully from a backup and promote it to master, there’s no need to keep this online. We shut it down, but keep it around in case we need to grab anything from it later, just in case.
Set Up Base Backup For Recovery
Next, on our PITR host, we fetch our most recent base backup from before the event, which is backup ‘2018-12-21_backup’.
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/With this, the base backup, as well as the WAL files provided by pg_basebackup are ready to go, if we bring it online now, it will recover to the point the backup took place, but we want to recover all of the WAL transactions between midnight and 11:59 AM, so we set up our recovery.conf file.
Create recovery.conf
Since this backup actually came from a streaming replica, there is likely already a recovery.conf file with replica settings. We will overwrite it with new settings. A detailed information list for all different options are available on PostgreSQL’s documentation here.
Being careful with the WAL files, the restore command will copy the compressed files it needs to the restore directory, uncompress them, then move to where PostgreSQL needs them for recovery. The original WAL files will remain where they are in case needed for any other reasons.
New recovery.conf:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Start The Recovery Process
Now that everything is set up, we will start the process for recovery. When this happens, it’s a good idea to tail the database log to make sure it’s restoring as intended.
Start the DB:
pg_ctl -D /var/lib/pgsql/11/data startTail the logs:
There will be many log entries showing the database is recovering from archive files, and at a certain point, it will show a line saying “recovery stopping before commit of transaction …”
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07At this point, the recovery process has ingested all WAL files, but is also in need of review before it comes online as a master. In this example, the log notes that the next transaction after the recovery target time of 11:59:00 was 11:59:01, and it was not recovered. To Verify, log in to the database and take a look, the running database should be a snapshot as of 11:59 exactly.
When everything looks good, time to promote the recovery as a master.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Now, the database is online, recovered to the point we decided, and accepting read / write connections as a master node. Ensure all configuration parameters are correct and ready for production.
The database is online, but the recovery process is not done yet! Now that this PITR backup is online as the master, a new standby and PITR setup should be set up, until then this new master may be online and serving applications, but it’s not safe from another disaster until that’s all set up again.
Other Point In Time Recovery Scenarios
Bringing back a PITR backup for a whole database is an extreme case, but there are other scenarios where only a subset of data is missing, corrupt, or bad. In these cases, we can get creative with our recovery options. Without bringing the master offline and replacing it with a backup, we can bring a PITR backup online to the exact time we want on another host (or another port if space isn’t an issue), and export the recovered data from the backup directly into the master database. This could be used to recover a handful of rows, a handful of tables, or any configuration of data needed.
With streaming replication and Point In Time Recovery, PostgreSQL gives us great flexibility on making sure we can recover any data we need, as long as we have standby hosts ready to go as a master, or backups ready to recover. A good Disaster Recovery option can be further expanded with other backup options, more replica nodes, multiple backup sites across different data centers and continents, periodic pg_dumps on another replica, etc.
These options can add up, but the real question is ‘how valuable is the data, and how much are you willing to spend to get it back?’. Many cases the loss of the data is the end of a business, so good Disaster Recovery options should be in place to prevent the worst from happening.



