blog
Integrations & Services Available from MongoDB for the Cloud

MongoDB is a document data store that has been around for over a decade. In the last few years, MongoDB has evolved into a mature product that features enterprise-grade options like scalability, security, and resilience. However, with the demanding cloud movement that wasn’t good enough.
Cloud resources, such as virtual machines, containers, serverless compute resources, and databases are currently in high demand. These days many software solutions can be spun-up in a fraction of the time it used to take to deploy onto one’s own hardware. It started a trend and changed the markets expectations at the same time.
But the quality of an online service is not limited to deployment alone. Often users need additional services, integrations, or extra features that help them to do their work. Cloud offerings can still be very limited and may cause more issues than what you can gain from the automation and remote infrastructure.
So what is MongoDB Inc.’s approach this common problem?
The answer was MongoDB Atlas, which brings internal extensions as a part of a larger cloud/automation platform. With the addition of third-party components, MongoDB has flourished. In today’s blog, we are going to see what they have developer and how it can help you to address your data processing needs.
The items we will explore today are…
- MongoDB Charts
- MongoDB Stich
- MongoDB Kubernetes Integrations with Ops Manager
- MongoDB Cloud migration
- Fulltext Search
- MongoDB Data Lake (beta)
MongoDB Charts
MongoDB Charts is one of the services accessible through the MongoDB Atlas platform. It simply provides an easy way to visualize your data living inside MongoDB. You don’t need to move your data to a different repository or write your own code as MongoDB Charts was designed to work with data documents and make it easy to visualize your data.
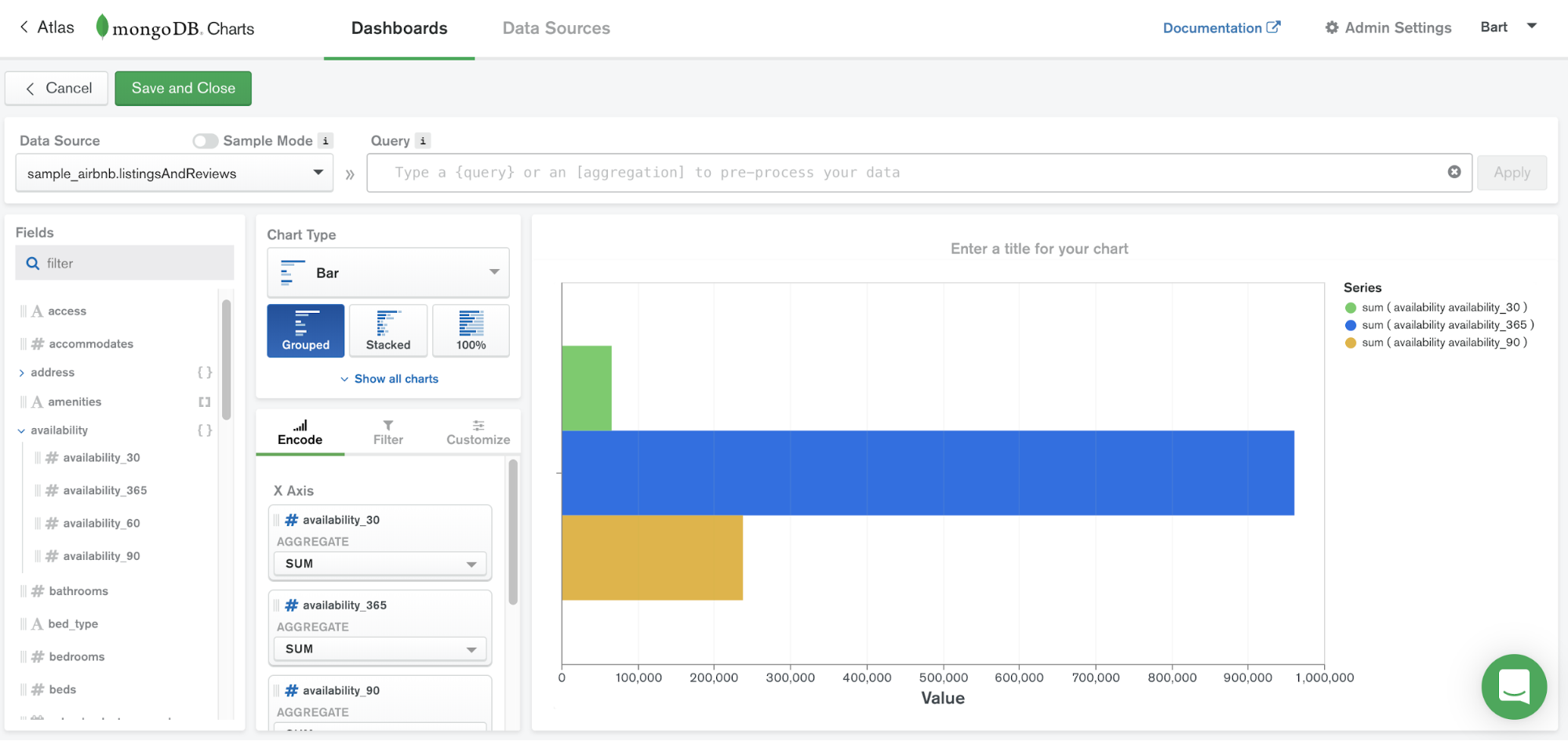
MongoDB Charts makes communicating your data a straightforward process by providing built-in tools to easily share and collaborate on visualizations. Data visualization is a key component to providing a clear understanding of your data, highlighting correlations between variables and making it easy to discern patterns and trends within your dataset.
Here are some key features which you can use in the Charts.
Aggregation
Aggregation framework is an operational process that manipulates documents in different stages, processes them in accordance with the provided criteria, and then returns the computed results. Values from multiple documents are grouped together, on which more operations can be performed to return matching results.
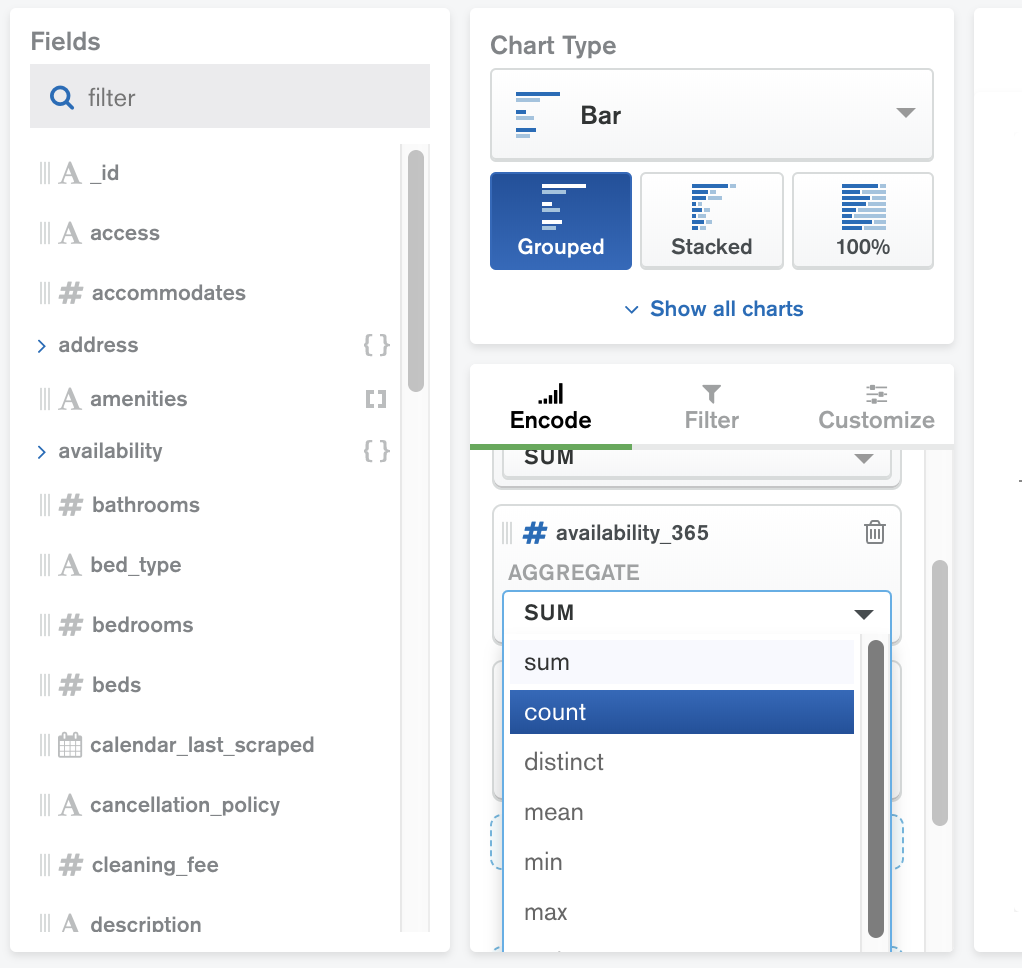
MongoDB Charts provides built-in aggregation functionality. Aggregation allows you to process your collection data by a variety of metrics and perform calculations such as mean and standard deviation.
Charts provide seamless integration with MongoDB Atlas. You can link MongoDB Charts to Atlas projects and quickly get started visualizing your Atlas cluster data.
Document Data Handling
MongoDB Charts natively understands the benefits of the Document Data Model. It manages document-based data, including fixed objects and arrays. Using a nested data structure provides the flexibility to structure your data as it fits for your application while still maintaining visualization capabilities.
MongoDB Charts provides built-in aggregation functionality which allows you to process your collection data using a variety of metrics. It’s intuitive enough for non-developers to use, allowing for self-service data analysis which makes it a great tool for data analytics teams.
MongoDB Stitch
Have you heard about serverless architecture?
With Serverless, you compose your application into individual, autonomous functions. Each function is hosted by the serverless provider and can be scaled automatically as function call frequency increases or decreases. This turns out to be a very cost-effective way of paying for computing resources. You only pay for the times that your functions get called, rather than paying to have your application always on and waiting for requests on so many different instances.
MongoDB Stitch is a different kind of MongoDB service taking only what’s most useful in the cloud infrastructure environments. It is a serverless platform that enables developers to build applications without having to set up server infrastructure. Stitch is made on top of MongoDB Atlas, automatically integrating the connection to your database. You can connect to Stitch through the Stitch Client SDKs, which are open for many of the platforms that you develop.
MongoDB Kubernetes Integrations with Ops Manager
Ops Manager is a management platform for MongoDB Clusters that you run on your own infrastructure. The capabilities of Ops Manager include monitoring, alerting, disaster recovery, scaling, deploying, and upgrading of Replica Sets and sharded clusters, and other MongoDB products. In 2018 MongoDB introduced beta integration with Kubernetes.
The MongoDB Enterprise Operator is compatible with Kubernetes v1.11 and above. It has been tested against Openshift 3.11. This Operator requires Ops Manager or Cloud Manager. In this document, when we refer to “Ops Manager”, you may substitute “Cloud Manager”. The functionality is the same.
The installation is fairly simple and requires
- Installing the MongoDB Enterprise Operator. This could be done via helm or YAML file.
- Gather Ops Manager properties.
- Create and apply a Kubernetes ConfigMap file
- Create the Kubernetes secret object which will store the Ops Manager API Key
In this basic example we are going to use YAML file:
kubectl apply -f crds.yaml
kubectl apply -f https://raw.githubusercontent.com/mongodb/mongodb-enterprise-kubernetes/master/mongodb-enterprise.yamlThe next step is to obtain the following information that we are going to use in ConfigMap File. All that can be found in the ops manager.
- Base URL. Base Url is the URL of your Ops Manager or Cloud Manager.
- Project Id. The id of an Ops Manager Project which the Kubernetes Operator will deploy into.
- User. An existing Ops Manager username
- Public API Key. Used by the Kubernetes Operator to connect to the Ops Manager REST API endpoint
Now that we have acquired the necessary Ops Manager configuration information we need to create a Kubernetes ConfigMap file for the Kubernetes. For exercise purposes we can call this file project.yaml.
apiVersion: v1
kind: ConfigMap
metadata:
name:<>
namespace: mongodb
data:
projectId:<>
baseUrl: <> The next step is to create ConfigMap to Kubernetes and secret file
kubectl apply -f my-project.yaml
kubectl -n mongodb create secret generic <> --from-literal="user=<>" --from-literal="publicApiKey=<>" Once we have we can deploy our first cluster
apiVersion: mongodb.com/v1
kind: MongoDbReplicaSet
metadata:
name: <>
namespace: mongodb
spec:
members: 3
version: 4.2.0
persistent: false
project: <>
credentials: <> For more detailed instructions please visit the MongoDB documentation.
MongoDB Cloud migration
The Atlas Live Migration Service can migrate your data from your existing environment whether it’s on AWS, Azure, GCP, or on-prem to MongoDB Atlas, the global cloud database for MongoDB.
The migration is done via a dedicated replication service. Atlas Live Migration process streams data through a MongoDB-controlled application server.
Live migration works by keeping a cluster in MongoDB Atlas in sync with your source database. During this process, your application can continue to read and write from your source database. Since the process watches upcoming changes, all will be replicated, and the migration can be done online. You decide when to change the application connection setting and do cutover. To do the process less prone Atlas provides Validate option which checks whitelist IP access, SSL configuration, CA, etc.
Full-Text Search
Full-text search is another service cloud service provided by MongoDB and is available only in MongoDB Atlas. Non-Atlas MongoDB deployments can use text indexing. Atlas Full-Text Search is built on Open Source Apache Lucene. Lucene is a powerful text search library. Lucene has a custom query syntax for querying its indexes. It’s a foundation of popular systems such as Elasticsearch and Apache Solr. It allows creating an index for full-text search, it’s searching, saving and reading. It’s fully integrated into Atlas MongoDB so there are no additional systems or infrastructure to provision or manage.
MongoDB Data Lake (beta)
The last MongoDB cloud feature we would like to mention in MongoDB Data Lake. It’s fairly new service addressing the popular concept of data lakes. A data lake is a vast pool of raw data, the purpose for which is not yet defined. Instead of placing data in a purpose-built data store, you move it into a data lake in its original format. This eliminates the upfront costs of data ingestion, like transformation. Once data is placed into the.
Using Atlas Data Lake to ingest your S3 data into Atlas clusters allows you to query data stored in your AWS S3 buckets using the Mongo Shell, MongoDB Compass, and any MongoDB driver.
There are some limitations though. The following features do not work yet like monitoring Data Lakes with Atlas monitoring tools, single S3 AWS account support, IP whitelist and AWS account and AWS security groups limitations or no possibility to add indexes.



