blog
Integrating Tools to Manage PostgreSQL in Production

Managing a PostgreSQL installation involves inspection and control over a wide range of aspects in the software/infrastructure stack on which PostgreSQL runs. This must cover:
- Application tuning regarding database usage/transactions/connections
- Database code (queries, functions)
- Database system (performance, HA, backups)
- Hardware/Infrastructure (disks, CPU/Memory)
PostgreSQL core provides the database layer on which we trust our data to be stored, processed and served. It also provides all the technology for having a truly modern, efficient, reliable and secure system. But often this technology is not available as a ready to use, refined business/enterprise class product in the core PostgreSQL distribution. Instead, there are a lot of products/solutions either by the PostgreSQL community or commercial offerings that fill those needs. Those solutions come either as user-friendly refinements to the core technologies, or extensions of the core technologies or even as integration between PostgreSQL components and other components of the system. In our previous blog titled Ten Tips for Going into Production with PostgreSQL, we looked into some of those tools which can help manage a PostgreSQL installation in production. In this blog we will explore in more detail the aspects that must be covered when managing a PostgreSQL installation in production, and the most commonly used tools for that purpose. We will cover the following topics:
- Deployment
- Management
- Scaling
- Monitoring
Deployment
In the old days, people used to download and compile PostgreSQL by hand, and then configure the runtime parameters and user access control. There are still some cases where this might be needed but as systems matured and started growing, the need arose for more standardized ways to deploy and manage Postgresql. Most OS’s provide packages to install, deploy and manage PostgreSQL clusters. Debian has standardized their own system layout supporting many Postgresql versions, and many clusters per version at the same time. postgresql-common debian package provides the needed tools. For instance in order to create a new cluster (called i18n_cluster) for PostgreSQL version 10 in Debian, we may do it by giving the following commands:
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsThen refresh systemd:
$ sudo systemctl daemon-reloadand finally start and use the new cluster:
$ sudo systemctl start postgresql@10-i18n_cluster.service
$ createdb -p 5434 somei18ndb(note that Debian handles different clusters by the use of different ports 5432, 5433 and so forth)
As the need grows for more automated and massive deployments, more and more installations use automation tools like Ansible, Chef and Puppet. Besides automation and reproducibility of deployments, automation tools are great because they are a nice way to document the deployment and configuration of a cluster. On the other hand, automation has evolved to become a large field on its own, requiring skilled people to write, manage and run automated scripts. More info on PostgreSQL provisioning can be found in this blog: Become a PostgreSQL DBA: Provisioning and Deployment.
Management
Managing a live system involves tasks as: schedule backups and monitor their status, disaster recovery, configuration management, high availability management and automatic failover handling. Backing up a Postgresql cluster can be done in various ways. Low level tools:
- traditional pg_dump (logical backup)
- file system level backups (physical backup)
- pg_basebackup (physical backup)
Or higher level:
Each of those ways cover different use cases and recovery scenarios, and vary in complexity. PostgreSQL backup is tightly related to the notions of PITR, WAL archiving and replication. Through the years the procedure of taking, testing and finally (fingers crossed!) using backups with PostgreSQL has evolved to be a complex task. One may find a nice overview of the backup solutions for PostgreSQL in this blog: Top Backup Tools for PostgreSQL.
Regarding high availability and automatic failover the bare minimum that an installation must have in order to implement this is:
- A working primary
- A hot standby accepting WAL streamed from the primary
- In the event of failed primary, a method to tell the primary that it is no longer the primary (sometimes called as STONITH)
- A heartbeat mechanism to check for connectivity between the two servers and the health of the primary
- A method to perform the failover (e.g. via pg_ctl promote, or trigger file)
- An automated procedure for recreation of the old primary as a new standby: Once disruption or failure on the primary is detected then a standby must be promoted as the new primary. The old primary is no longer valid or usable. So the system must have a way to handle this state between the failover and the re-creation of the old primary server as the new standby. This state is called degenerate state, and the PostgreSQL provides a tool called pg_rewind in order to speed up the process of bringing the old primary back in sync-able state from the new primary.
- A method to do on-demand/planned switchovers
A widely used tool that handles all the above is Repmgr. We will describe the minimal setup that will allow for a successful switchover. We start by a working PostgreSQL 10.4 primary running on FreeBSD 11.1, manually built and installed, and repmgr 4.0 also manually built and installed for this version (10.4). We will use two hosts named fbsd (192.168.1.80) and fbsdclone (192.168.1.81) with identical versions of PostgreSQL and repmgr. On the primary (initially fbsd , 192.168.1.80) we make sure the following PostgreSQL parameters are set:
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' Then we create the repmgr user (as superuser) and database:
postgres@fbsd:~ % createuser -s repmgr
postgres@fbsd:~ % createdb repmgr -O repmgrand setup host based access control in pg_hba.conf by putting the following lines on the top:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustWe make sure that we setup passwordless login for user repmgr in all nodes of the cluster, in our case fbsd and fbsdclone by setting authorized_keys in .ssh and then sharing .ssh. Then we create repmrg.conf on the primary as:
postgres@fbsd:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Then we register the primary:
postgres@fbsd:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredAnd check the status of the cluster:
postgres@fbsd:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2We now work on the standby by setting repmgr.conf as follows:
postgres@fbsdclone:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Also we make sure that the data directory specified just in the line above exists, is empty and has the correct permissions:
postgres@fbsdclone:~ % rm -fr data && mkdir data
postgres@fbsdclone:~ % chmod 700 dataWe now have to clone to our new standby:
postgres@fbsdclone:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"And start the standby:
postgres@fbsdclone:~ % pg_ctl -D data startAt this point replication should be working as expected, verify this by querying pg_stat_replication (fbsd) and pg_stat_wal_receiver (fbsdclone). Next step is to register the standby:
postgres@fbsdclone:~ % repmgr -f /etc/repmgr.conf standby registerNow we can get the status of the cluster on either the standly or the primary and verify that the standby is registered:
postgres@fbsd:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Now let’s suppose that we wish to perform a scheduled manual switchover in order e.g. to do some administration work on node fbsd. On the standby node, we run the following command:
postgres@fbsdclone:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyThe switchover has been executed successfully! Lets see what cluster show gives:
postgres@fbsdclone:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2The two servers have swapped roles! Repmgr provides repmgrd daemon which provides monitoring, automatic failover, as well as notifications/alerts. Combining repmgrd with pgbouncer, it possible to implement automatic update of the connection info of the database, thus providing fencing for the failed primary (preventing the failed node from any usage by the application) as well as providing minimal downtime for the application. In more complex schemes another idea is to combine Keepalived with HAProxy on top of pgbouncer and repmgr, in order to achieve:
- load balancing (scaling)
- high availability
Note that ClusterControl also manages failover of PostgreSQL replication setups, and integrates HAProxy and VirtualIP to automatically re-route client connections to the working master. More information can be found in this whitepaper on PostgreSQL Automation.
Scaling
As of PostgreSQL 10 (and 11) there is still no way to have multi-master replication, at least not from the core PostgreSQL. This means that only the select(read-only) activity can be scaled up. Scaling in PostgreSQL is achieved by adding more hot standbys, thus providing more resources for read-only activity. With repmgr it is easy to add new standby as we saw earlier via standby clone and standby register commands. Standbys added (or removed) must be made known to the configuration of the load-balancer. HAProxy, as mentioned above in the management topic, is a popular load balancer for PostgreSQL. Usually it is coupled with Keepalived which provides virtual IP via VRRP. A nice overview of using HAProxy and Keepalived together with PostgreSQL can be found in this article: PostgreSQL Load Balancing Using HAProxy & Keepalived.
Monitoring
An overview of what to monitor in PostgreSQL can be found in this article: Key Things to Monitor in PostgreSQL – Analyzing Your Workload. There are many tools that can provide system and postgresql monitoring via plugins. Some tools cover the area of presenting graphical chart of historic values (munin), other tools cover the area of monitoring live data and providing live alerts (nagios), while some tools cover both areas (zabbix). A list of such tools for PostgreSQL can be found here: https://wiki.postgresql.org/wiki/Monitoring. A popular tool for offline (log file based) monitoring is pgBadger. pgBadger is a Perl script which works by parsing the PostgreSQL log (which usually covers the activity of one day), extracting information, computing statistics and finally producing a fancy html page presenting the results. pgBadger is not restrictive on the log_line_prefix setting, it may adapt to your already existing format. For instance if you have set in your postgresql.conf something like:
log_line_prefix = '%r [%p] %c %m %a %u@%d line:%l 'then the pgbadger command to parse the log file and produce the results may look like:
./pgbadger --prefix='%r [%p] %c %m %a %u@%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadger provides reports for:
- Overview stats (mostly SQL traffic)
- Connections (per second, per database/user/host)
- Sessions (number, session times, per database/user/host/application)
- Checkpoints (buffers, wal files, activity)
- Temp files usage
- Vacuum/Analyze activity (per table, tuples/pages removed)
- Locks
- Queries (by type/database/user/host/application, duration by user)
- Top (Queries: slowest, time consuming, more frequent, normalized slowest)
- Events (Errors, Warnings, Fatals,etc)
The screen showing the sessions looks like:
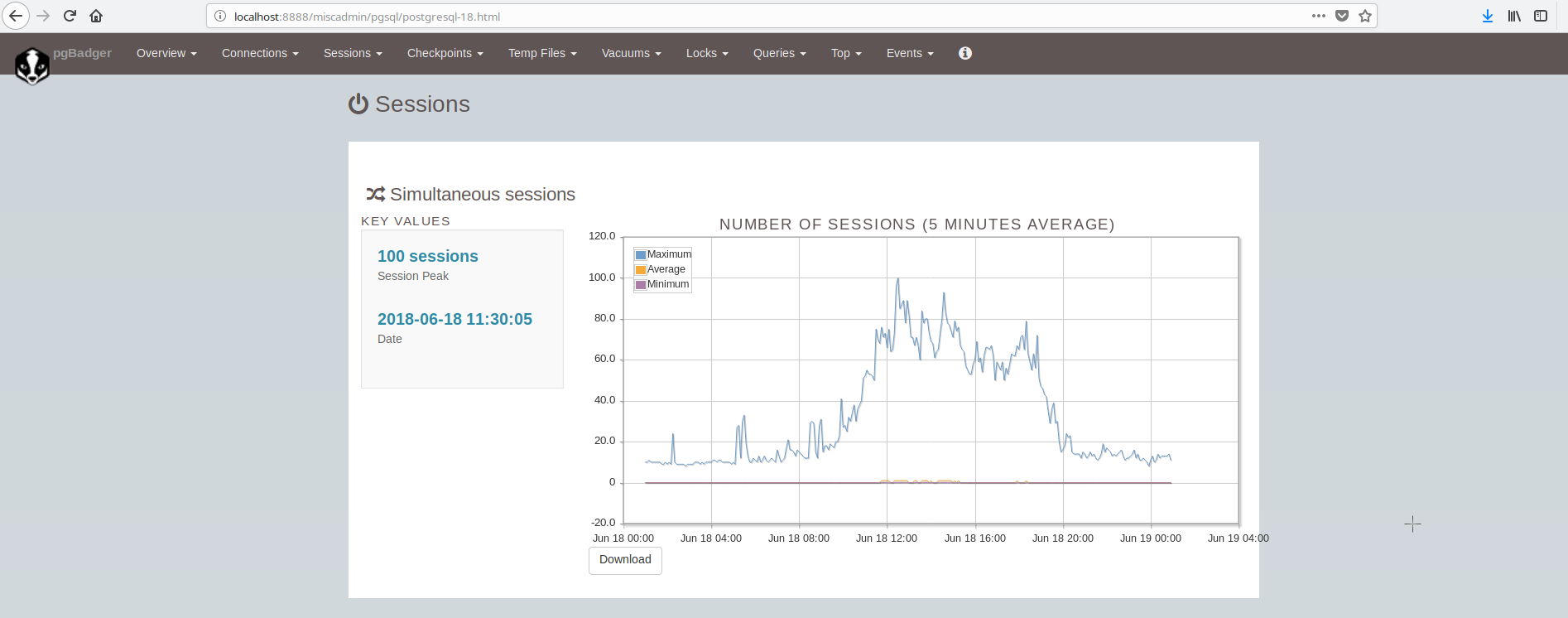
As we can conclude, the average PostgreSQL installation has to integrate and take care of many tools in order to have a modern reliable and fast infrastructure and this is fairly complex to achieve, unless there are large teams involved in postgresql and system administration. A fine suite that does all of the above and more is ClusterControl.



