blog
How to Monitor PostgreSQL using Nagios

Introduction
Regardless of database technology, it is necessary to have a monitoring setup,both to detect problems and take action, or simply to know the current state of our systems.
For this purpose there are several tools, paid and free. In this blog we will focus on one in particular: Nagios Core.
What is Nagios Core?
Nagios Core is an Open Source system for monitoring hosts, networks and services. It allows to configure alerts and has different states for them. It allows the implementation of plugins, developed by the community, or even allows us to configure our own monitoring scripts.
How to Install Nagios?
The official documentation shows us how to install Nagios Core on CentOS or Ubuntu systems.
Let’s see an example of the necessary steps for the installation on CentOS 7.
Packages required
[root@Nagios ~]# yum install -y wget httpd php gcc glibc glibc-common gd gd-devel make net-snmp unzipDownload Nagios Core, Nagios Plugins and NRPE
[root@Nagios ~]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.2.tar.gz
[root@Nagios ~]# wget http://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[root@Nagios ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gzAdd Nagios User and Group
[root@Nagios ~]# useradd nagios
[root@Nagios ~]# groupadd nagcmd
[root@Nagios ~]# usermod -a -G nagcmd nagios
[root@Nagios ~]# usermod -a -G nagios,nagcmd apacheNagios Installation
[root@Nagios ~]# tar zxvf nagios-4.4.2.tar.gz
[root@Nagios ~]# cd nagios-4.4.2
[root@Nagios nagios-4.4.2]# ./configure --with-command-group=nagcmd
[root@Nagios nagios-4.4.2]# make all
[root@Nagios nagios-4.4.2]# make install
[root@Nagios nagios-4.4.2]# make install-init
[root@Nagios nagios-4.4.2]# make install-config
[root@Nagios nagios-4.4.2]# make install-commandmode
[root@Nagios nagios-4.4.2]# make install-webconf
[root@Nagios nagios-4.4.2]# cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/
[root@Nagios nagios-4.4.2]# chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
[root@Nagios nagios-4.4.2]# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgNagios Plugin and NRPE Installation
[root@Nagios ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[root@Nagios ~]# cd nagios-plugins-2.2.1
[root@Nagios nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[root@Nagios nagios-plugins-2.2.1]# make
[root@Nagios nagios-plugins-2.2.1]# make install
[root@Nagios ~]# yum install epel-release
[root@Nagios ~]# yum install nagios-plugins-nrpe
[root@Nagios ~]# tar zxvf nrpe-3.2.1.tar.gz
[root@Nagios ~]# cd nrpe-3.2.1
[root@Nagios nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[root@Nagios nrpe-3.2.1]# make all
[root@Nagios nrpe-3.2.1]# make install-pluginWe add the following line to the end of our file /usr/local/nagios/etc/objects/command.cfg to use NRPE when checking our servers:
define command{
command_name check_nrpe
command_line /usr/local/nagios/libexec/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}Nagios starts
[root@Nagios nagios-4.4.2]# systemctl start nagios
[root@Nagios nagios-4.4.2]# systemctl start httpdWeb access
We create the user to access the web interface and we can enter the site.
[root@Nagios nagios-4.4.2]# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminhttp://IP_Address/nagios/
How to Configure Nagios?
Now that we have our Nagios installed, we can continue with the configuration. For this we must go to the location corresponding to our installation, in our example /usr/local/nagios/etc.
There are several different configuration files that you’re going to need to create or edit before you start monitoring anything.
[root@Nagios etc]# ls /usr/local/nagios/etc
cgi.cfg htpasswd.users nagios.cfg objects resource.cfg- cgi.cfg: The CGI configuration file contains a number of directives that affect the operation of the CGIs. It also contains a reference to the main configuration file, so the CGIs know how you’ve configured Nagios and where your object definitions are stored.
- htpasswd.users: This file contains the users created for accessing the Nagios web interface.
- nagios.cfg: The main configuration file contains a number of directives that affect how the Nagios Core daemon operates.
- objects: When you install Nagios, several sample object configuration files are placed here. You can use these sample files to see how object inheritance works, and learn how to define your own object definitions. Objects are all the elements that are involved in the monitoring and notification logic.
- resource.cfg: This is used to specify an optional resource file that can contain macro definitions. Macros allow you to reference the information of hosts, services and other sources in your commands.
Within objects, we can find templates, which can be used when creating new objects. For example, we can see that in our file /usr/local/nagios/etc/objects/templates.cfg, there is a template called linux-server, which will be used to add our servers.
define host {
name linux-server ; The name of this host template
use generic-host ; This template inherits other values from the generic-host template
check_period 24x7 ; By default, Linux hosts are checked round the clock
check_interval 5 ; Actively check the host every 5 minutes
retry_interval 1 ; Schedule host check retries at 1 minute intervals
max_check_attempts 10 ; Check each Linux host 10 times (max)
check_command check-host-alive ; Default command to check Linux hosts
notification_period workhours ; Linux admins hate to be woken up, so we only notify during the day
; Note that the notification_period variable is being overridden from
; the value that is inherited from the generic-host template!
notification_interval 120 ; Resend notifications every 2 hours
notification_options d,u,r ; Only send notifications for specific host states
contact_groups admins ; Notifications get sent to the admins by default
register 0 ; DON'T REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE!
}Using this template, our hosts will inherit the configuration without having to specify them one by one on each server that we add.
We also have predefined commands, contacts and timeperiods.
The commands will be used by Nagios for its checks, and that is what we add within the configuration file of each server to monitor it. For example, PING:
define command {
command_name check_ping
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5
}We have the possibility to create contacts or groups, and specify which alerts I want to reach which person or group.
define contact {
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Nagios Admin ; Full name of user
email nagios@localhost ; <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ******
}For our checks and alerts, we can configure in what hours and days we want to receive them. If we have a service that is not critical, we probably do not want to wake up at dawn, so it would be good to alert only in work hours to avoid this.
define timeperiod {
name workhours
timeperiod_name workhours
alias Normal Work Hours
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}Let's see now how to add alerts to our Nagios.
We are going to monitor our PostgreSQL servers, so we first add them as hosts in our objects directory. We will create 3 new files:
[root@Nagios ~]# cd /usr/local/nagios/etc/objects/
[root@Nagios objects]# vi postgres1.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres1 ; Hostname
alias PostgreSQL1 ; Alias
address 192.168.100.123 ; IP Address
}
[root@Nagios objects]# vi postgres2.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres2 ; Hostname
alias PostgreSQL2 ; Alias
address 192.168.100.124 ; IP Address
}
[root@Nagios objects]# vi postgres3.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres3 ; Hostname
alias PostgreSQL3 ; Alias
address 192.168.100.125 ; IP Address
}Then we must add them to the file nagios.cfg and here we have 2 options.
Add our hosts (cfg files) one by one using the cfg_file variable (default option) or add all the cfg files that we have inside a directory using the cfg_dir variable.
We will add the files one by one following the default strategy.
cfg_file=/usr/local/nagios/etc/objects/postgres1.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres2.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres3.cfgWith this we have our hosts monitored. Now we just have to add what services we want to monitor. For this we will use some already defined checks (check_ssh and check_ping), and we will add some basic checks of the operating system such as load and disk space, among others, using NRPE.
What is NRPE?
Nagios Remote Plugin Executor. This tool allow us to execute Nagios plugins on a remote host in as transparent a manner as possible.
In order to use it, we must install the server in each node that we want to monitor, and our Nagios will connect as a client to each one of them, executing the corresponding plugin (s).
How to install NRPE?
[root@PostgreSQL1 ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gz
[root@PostgreSQL1 ~]# wget http://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[root@PostgreSQL1 ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[root@PostgreSQL1 ~]# tar zxvf nrpe-3.2.1.tar.gz
[root@PostgreSQL1 ~]# cd nrpe-3.2.1
[root@PostgreSQL1 nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[root@PostgreSQL1 nrpe-3.2.1]# make all
[root@PostgreSQL1 nrpe-3.2.1]# make install-groups-users
[root@PostgreSQL1 nrpe-3.2.1]# make install
[root@PostgreSQL1 nrpe-3.2.1]# make install-config
[root@PostgreSQL1 nrpe-3.2.1]# make install-init
[root@PostgreSQL1 ~]# cd nagios-plugins-2.2.1
[root@PostgreSQL1 nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[root@PostgreSQL1 nagios-plugins-2.2.1]# make
[root@PostgreSQL1 nagios-plugins-2.2.1]# make install
[root@PostgreSQL1 nagios-plugins-2.2.1]# systemctl enable nrpeThen we edit the configuration file /usr/local/nagios/etc/nrpe.cfg
server_address=
allowed_hosts=127.0.0.1, And we restart the NRPE service:
[root@PostgreSQL1 ~]# systemctl restart nrpeWe can test the connection by running the following from our Nagios server:
[root@Nagios ~]# /usr/local/nagios/libexec/check_nrpe -H
NRPE v3.2.1 How to monitor PostgreSQL?
When monitoring PostgreSQL, there are two main areas to take into account: operating system and databases.
For the operating system, NRPE has some basic checks configured such as disk space and load, among others. These checks can be enabled very easily in the following way.
In our nodes we edit the file /usr/local/nagios/etc/nrpe.cfg and go to where the following lines are:
command[check_users]=/usr/local/nagios/libexec/check_users -w 5 -c 10
command[check_load]=/usr/local/nagios/libexec/check_load -r -w 15,10,05 -c 30,25,20
command[check_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 10% -p /
command[check_zombie_procs]=/usr/local/nagios/libexec/check_procs -w 5 -c 10 -s Z
command[check_total_procs]=/usr/local/nagios/libexec/check_procs -w 150 -c 200The names in square brackets are those that we will use in our Nagios server to enable these checks.
In our Nagios, we edit the files of the 3 nodes:
/usr/local/nagios/etc/objects/postgres1.cfg
/usr/local/nagios/etc/objects/postgres2.cfg
/usr/local/nagios/etc/objects/postgres3.cfgWe add these checks that we saw previously, leaving our files as follows:
define host {
use linux-server
host_name postgres1
alias PostgreSQL1
address 192.168.100.123
}
define service {
use generic-service
host_name postgres1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service {
use generic-service
host_name postgres1
service_description SSH
check_command check_ssh
}
define service {
use generic-service
host_name postgres1
service_description Root Partition
check_command check_nrpe!check_disk
}
define service {
use generic-service
host_name postgres1
service_description Total Processes zombie
check_command check_nrpe!check_zombie_procs
}
define service {
use generic-service
host_name postgres1
service_description Total Processes
check_command check_nrpe!check_total_procs
}
define service {
use generic-service
host_name postgres1
service_description Current Load
check_command check_nrpe!check_load
}
define service {
use generic-service
host_name postgres1
service_description Current Users
check_command check_nrpe!check_users
}And we restart the nagios service:
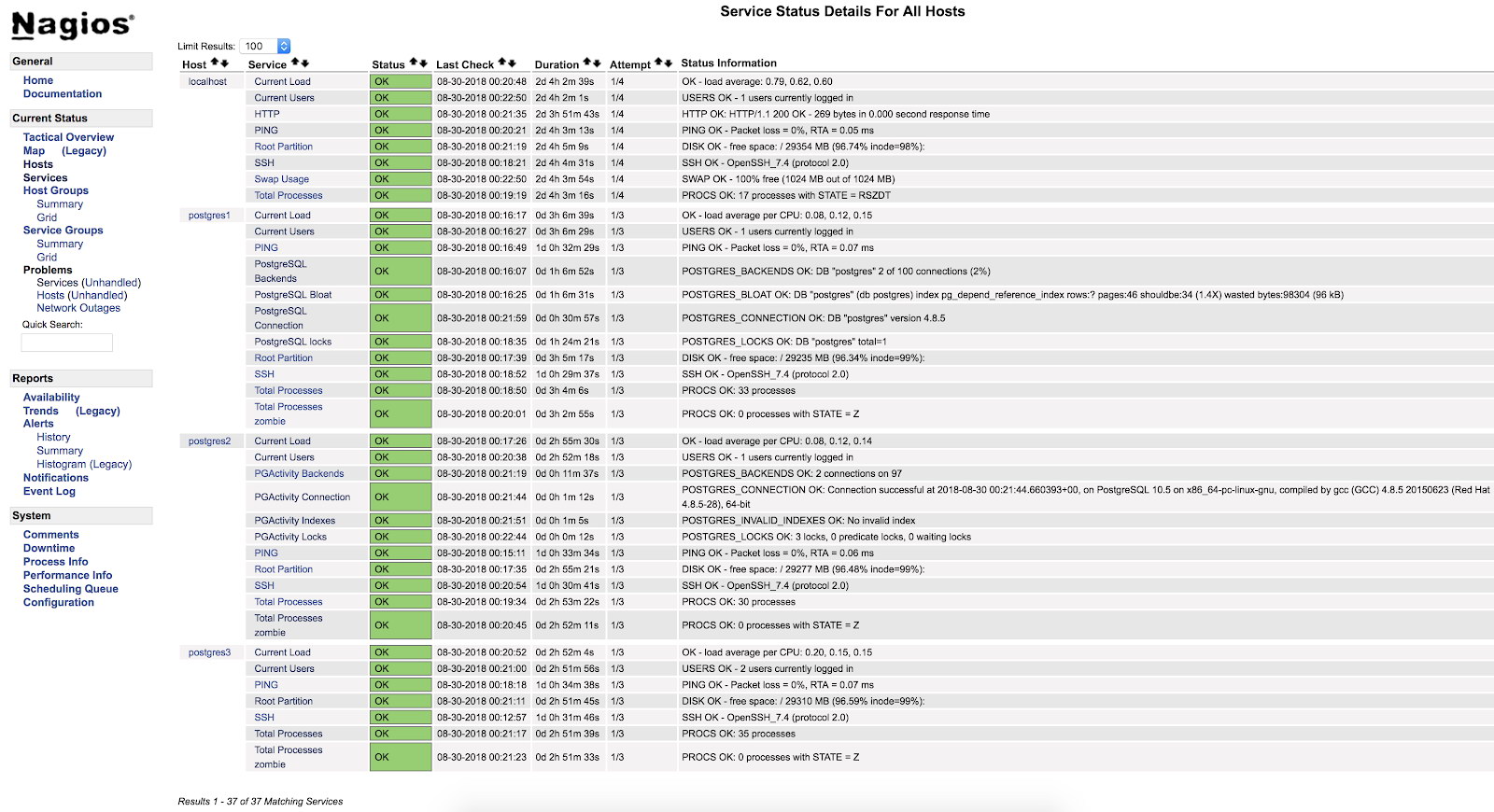
[root@Nagios ~]# systemctl start nagiosAt this point, if we go to the services section in the web interface of our Nagios, we should have something like the following:
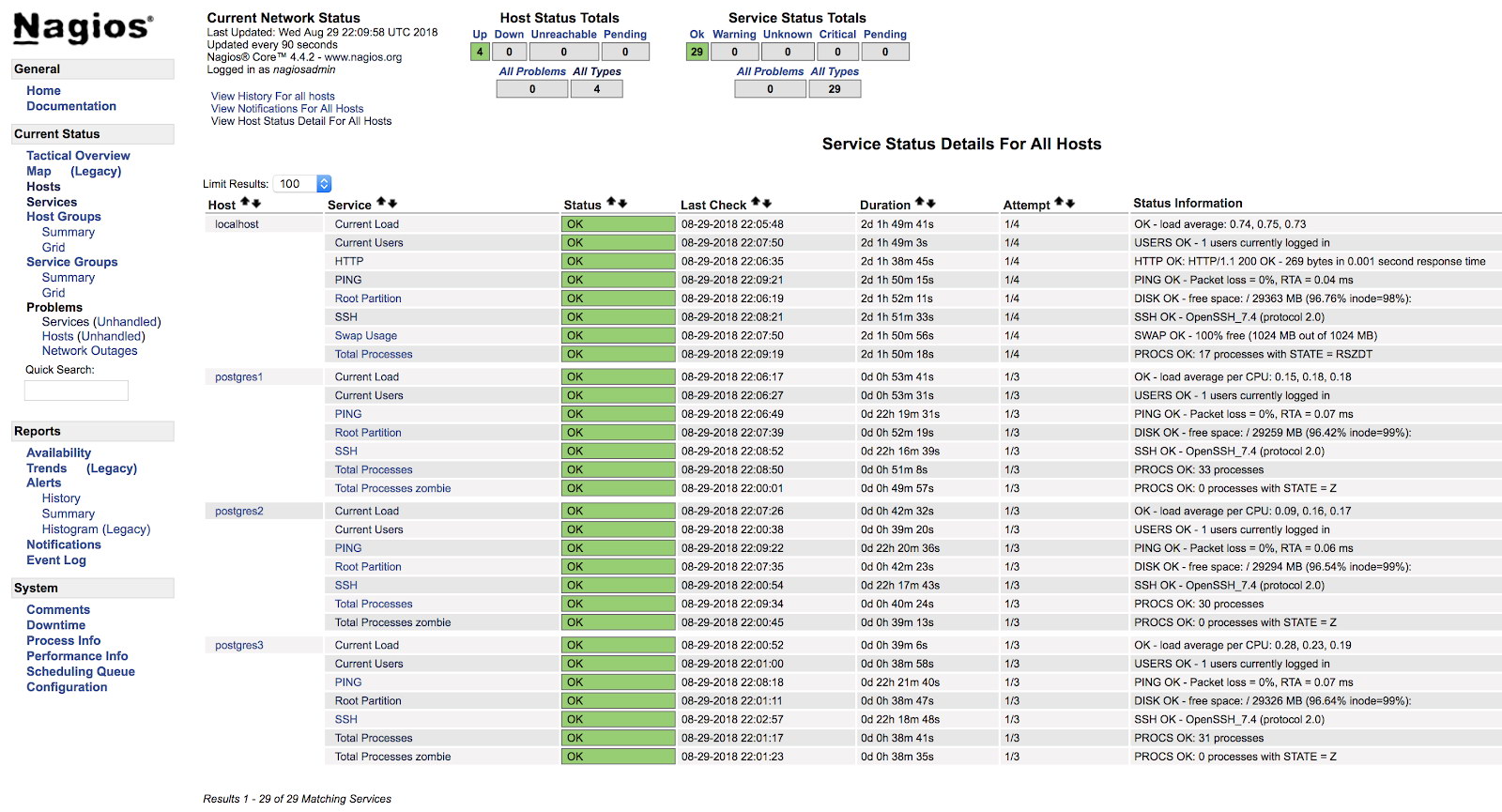
In this way we will be covering the basic checks of our server at the operating system level.
We have many more checks that we can add and we can even create our own checks (we'll see an example later).
Now let's see how to monitor our PostgreSQL database engine using two of the main plugins designed for this task.
Check_postgres
One of the most popular plugins for checking PostgreSQL is check_postgres from Bucardo.
Let's see how to install it and how to use it with our PostgreSQL database.
Packages required
[root@PostgreSQL1 ~]# yum install perl-develInstallation
[root@PostgreSQL1 ~]# wget http://bucardo.org/downloads/check_postgres.tar.gz
[root@PostgreSQL1 ~]# tar zxvf check_postgres.tar.gz
[root@PostgreSQL1 ~]# cp check_postgres-2.23.0/check_postgres.pl /usr/local/nagios/libexec/
[root@PostgreSQL1 ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres.pl
[root@PostgreSQL1 ~]# cd /usr/local/nagios/libexec/
[root@PostgreSQL1 libexec]# perl /usr/local/nagios/libexec/check_postgres.pl --symlinksThis last command creates the links to use all the functions of this check, such as check_postgres_connection, check_postgres_last_vacuum or check_postgres_replication_slots among others.
[root@PostgreSQL1 libexec]# ls |grep postgres
check_postgres.pl
check_postgres_archive_ready
check_postgres_autovac_freeze
check_postgres_backends
check_postgres_bloat
check_postgres_checkpoint
check_postgres_cluster_id
check_postgres_commitratio
check_postgres_connection
check_postgres_custom_query
check_postgres_database_size
check_postgres_dbstats
check_postgres_disabled_triggers
check_postgres_disk_space
…We add in our NRPE configuration file (/usr/local/nagios/etc/nrpe.cfg) the line to execute the check we want to use:
command[check_postgres_locks]=/usr/local/nagios/libexec/check_postgres_locks -w 2 -c 3
command[check_postgres_bloat]=/usr/local/nagios/libexec/check_postgres_bloat -w='100 M' -c='200 M'
command[check_postgres_connection]=/usr/local/nagios/libexec/check_postgres_connection --db=postgres
command[check_postgres_backends]=/usr/local/nagios/libexec/check_postgres_backends -w=70 -c=100In our example we added 4 basic checks for PostgreSQL. We will monitor Locks, Bloat, Connection and Backends.
In the file corresponding to our database in the Nagios server (/usr/local/nagios/etc/objects/postgres1.cfg), we add the following entries:
define service {
use generic-service
host_name postgres1
service_description PostgreSQL locks
check_command check_nrpe!check_postgres_locks
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Bloat
check_command check_nrpe!check_postgres_bloat
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Connection
check_command check_nrpe!check_postgres_connection
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Backends
check_command check_nrpe!check_postgres_backends
}And after restarting both services (NRPE and Nagios) on both servers, we can see our alerts configured.
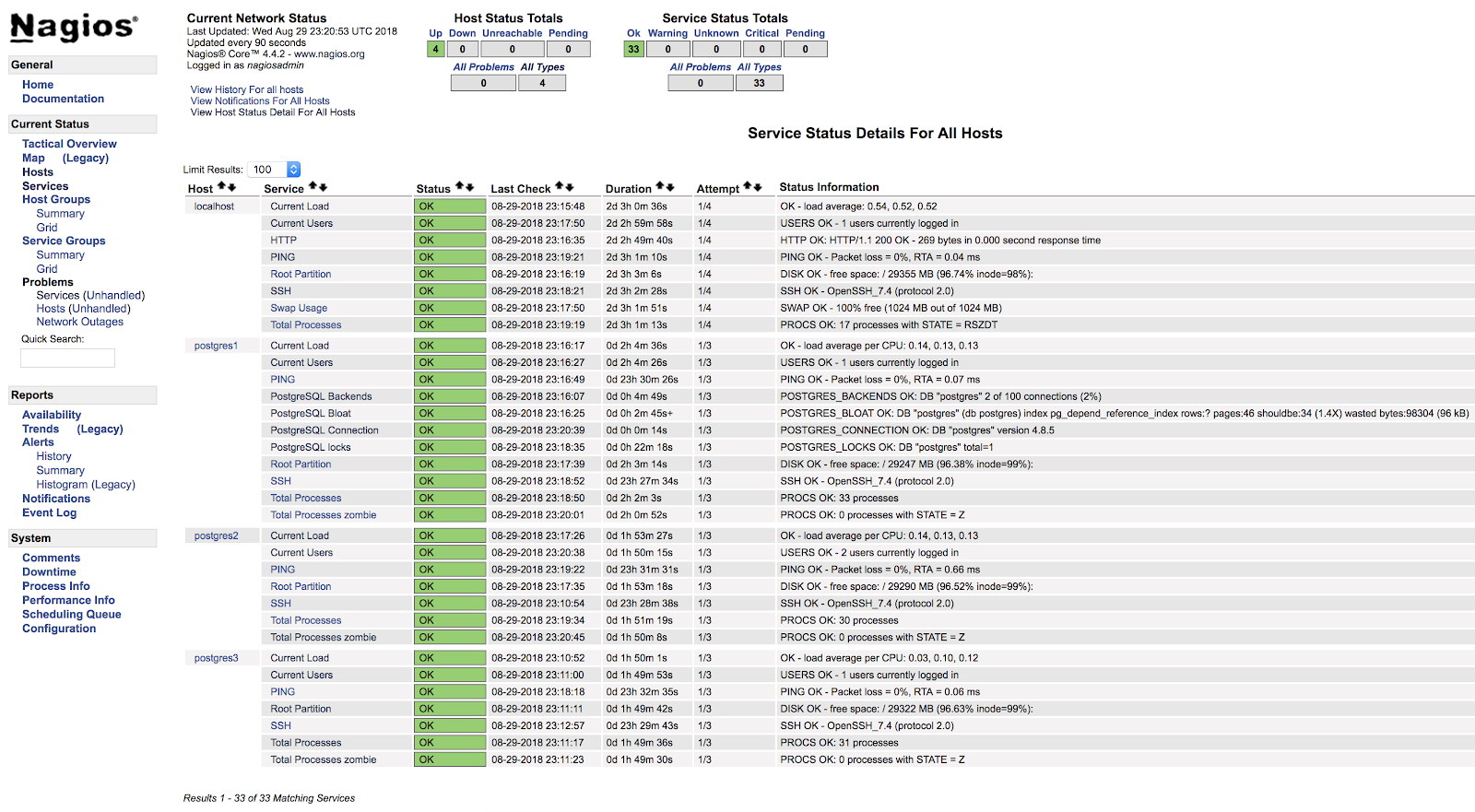
In the official documentation of the check_postgres plugin, you can find information on what else to monitor and how to do it.
Check_pgactivity
Now it's the turn for check_pgactivity, also popular for monitoring our PostgreSQL database.
Installation
[root@PostgreSQL2 ~]# wget https://github.com/OPMDG/check_pgactivity/releases/download/REL2_3/check_pgactivity-2.3.tgz
[root@PostgreSQL2 ~]# tar zxvf check_pgactivity-2.3.tgz
[root@PostgreSQL2 ~]# cp check_pgactivity-2.3check_pgactivity /usr/local/nagios/libexec/check_pgactivity
[root@PostgreSQL2 ~]# chown nagios.nagios /usr/local/nagios/libexec/check_pgactivityWe add in our NRPE configuration file (/usr/local/nagios/etc/nrpe.cfg) the line to execute the check we want to use:
command[check_pgactivity_backends]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s backends -w 70 -c 100
command[check_pgactivity_connection]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s connection
command[check_pgactivity_indexes]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s invalid_indexes
command[check_pgactivity_locks]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s locks -w 5 -c 10In our example we will add 4 basic checks for PostgreSQL. We will monitor Backends, Connection, Invalid Indexes and locks.
In the file corresponding to our database in the Nagios server (/usr/local/nagios/etc/objects/postgres2.cfg), we add the following entries:
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Backends
check_command check_nrpe!check_pgactivity_backends
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Connection
check_command check_nrpe!check_pgactivity_connection
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Indexes
check_command check_nrpe!check_pgactivity_indexes
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Locks
check_command check_nrpe!check_pgactivity_locks
}And after restarting both services (NRPE and Nagios) on both servers, we can see our alerts configured.
Check Error Log
One of the most important checks, or the most important one, is to check our error log.
Here we can find different types of errors such as FATAL or deadlock, and it is a good starting point to analyze any problem we have in our database.
To check our error log, we will create our own monitoring script and integrate it into our Nagios (this is just an example, this script will be basic and has plenty of room for improvement).
Script
We will create the file /usr/local/nagios/libexec/check_postgres_log.sh on our PostgreSQL3 server.
[root@PostgreSQL3 ~]# vi /usr/local/nagios/libexec/check_postgres_log.sh
#!/bin/bash
#Variables
LOG="/var/log/postgresql-$(date +%a).log"
CURRENT_DATE=$(date +'%Y-%m-%d %H')
ERROR=$(grep "$CURRENT_DATE" $LOG | grep "FATAL" | wc -l)
#States
STATE_CRITICAL=2
STATE_OK=0
#Check
if [ $ERROR -ne 0 ]; then
echo "CRITICAL - Check PostgreSQL Log File - $ERROR Error Found"
exit $STATE_CRITICAL
else
echo "OK - PostgreSQL without errors"
exit $STATE_OK
fiThe important thing of the script is to correctly create the outputs corresponding to each state. These outputs are read by Nagios and each number corresponds to a state:
0=OK
1=WARNING
2=CRITICAL
3=UNKNOWNIn our example we will only use 2 states, OK and CRITICAL, since we are only interested in knowing if there are errors of the FATAL type in our error log in the current hour.
The text that we use before our exit will be shown by the web interface of our Nagios, so it should be as clear as possible to use this as a guide to the problem.
Once we have finished our monitoring script, we will proceed to give it execution permissions, assign it to the user nagios and add it to our database server NRPE as well as to our Nagios:
[root@PostgreSQL3 ~]# chmod +x /usr/local/nagios/libexec/check_postgres_log.sh
[root@PostgreSQL3 ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres_log.sh
[root@PostgreSQL3 ~]# vi /usr/local/nagios/etc/nrpe.cfg
command[check_postgres_log]=/usr/local/nagios/libexec/check_postgres_log.sh
[root@Nagios ~]# vi /usr/local/nagios/etc/objects/postgres3.cfg
define service {
use generic-service ; Name of service template to use
host_name postgres3
service_description PostgreSQL LOG
check_command check_nrpe!check_postgres_log
}Restart NRPE and Nagios. Then we can see our check in the Nagios interface:
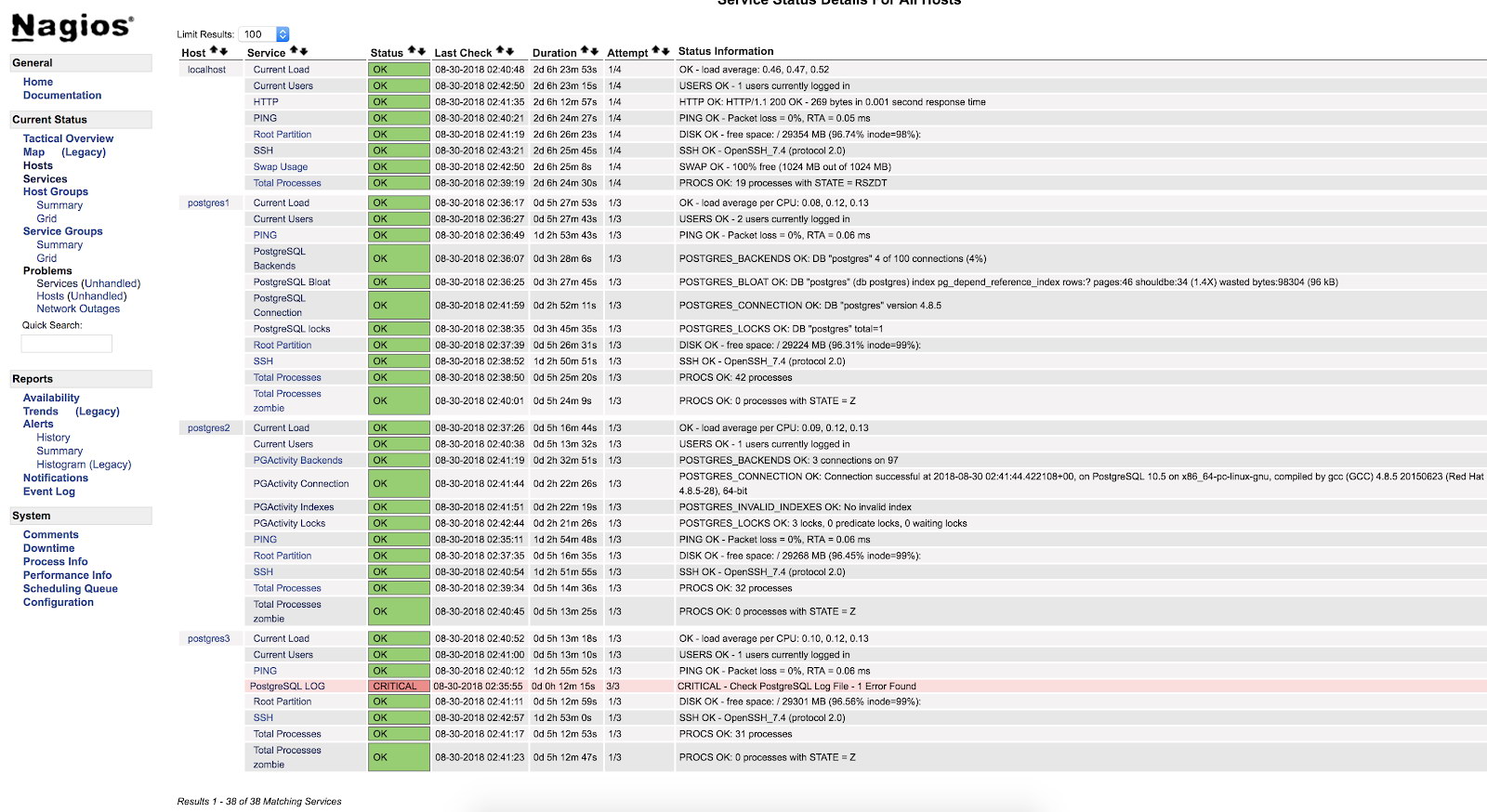
As we can see it is in a CRITICAL state, so if we go to the log, we can see the following:
2018-08-30 02:29:49.531 UTC [22162] FATAL: Peer authentication failed for user "postgres"
2018-08-30 02:29:49.531 UTC [22162] DETAIL: Connection matched pg_hba.conf line 83: "local all all peer"For more information about what we can monitor in our PostgreSQL database, I recommend you check our performance and monitoring blogs or this Postgres Performance webinar.
Safety and Performance
When configuring any monitoring, either using plugins or our own script, we must be very careful with 2 very important things - safety and performance.
When we assign the necessary permissions for monitoring, we must be as restrictive as possible, limiting access only locally or from our monitoring server, using secure keys, encrypting traffic, allowing the connection to the minimum necessary for monitoring to work.
With respect to performance, monitoring is necessary, but it is also necessary to use it safely for our systems.
We must be careful not to generate unreasonably high disk access, or run queries that negatively affect the performance of our database.
If we have many transactions per second generating gigabytes of logs, and we keep looking for errors continuously, it is probably not the best for our database. So we must keep a balance between what we monitor, how often and the impact on performance.
Conclusion
There are multiple ways to implement monitoring, or to configure it. We can get to do it as complex or as simple as we want. The objective of this blog was to introduce you in the monitoring of PostgreSQL using one of the most used open source tools. We have also seen that the configuration is very flexible and can be tailored to different needs.
And do not forget that we can always rely on the community, so I leave some links that could be of great help.
Support forum: https://support.nagios.com/forum/
Known issues: https://github.com/NagiosEnterprises/nagioscore/issues
Nagios Plugins: https://exchange.nagios.org/directory/Plugins
Nagios Plugin for ClusterControl: https://severalnines.com/blog/nagios-plugin-clustercontrol