blog
How to manage large databases effectively

One of the biggest concerns when managing a database is the size and complexity of its data. As the size of the database increases, you need to have a plan in place for how to deal with availability, backups, incoming traffic, and the overall impact of growth.
Of course, you also need to keep in mind that eventually, for one reason or another, the database is likely to fail. So you’ll need to ensure there’s a robust failover process too.
Everything needs to be planned properly, so that you’re able to respond if you’re ever faced with sudden, massive growth – whether that happens in an anticipated or unanticipated manner.
After all, the main goal of planning is to avoid unwanted disasters.
There are best practices for scaling databases that you can follow when the time comes. But a large database can provide some additional operational challenges.
With this in mind, let’s take a look at how to efficiently plan and manage large databases.
Data size matters
The size of the database has a significant impact on both its performance and its management methodology. For example, how the data is processed and stored will contribute to how the database should be managed, and this applies to both data in transit and at rest.
For many large organizations, data is gold, and growth in data could have a drastic effect on the processes that are in place.
Therefore, it’s vital to have a clear plan on how you will handle growing data in a database.
In my experience working with databases, I’ve witnessed customers start to have issues dealing with performance penalties and managing extreme data growth. For example backup and restoration, and then data retrieval are among the top concerns.
When these issues surface, questions arise whether to normalize the tables vs denormalizing the tables.
Normalized tables vs denormalized tables
Normalizing tables helps you to maintain data integrity, reduces redundancy, and makes it easy to organize the data into a more efficient way to manage, analyze, and extract.
When you work with normalized tables, you can see efficiency gains – especially when analyzing the data flow and retrieving data via SQL statements or working with programming languages such as C/C++, Java, Go, Ruby, PHP, or Python interfaces with the MySQL Connectors.
Although, concerns do exist with normalized tables. The approach can result in performance penalties and slow queries due to the number of required joins when retrieving the data.
In comparison, with denormalized tables optimization relies on the index or the primary key to store data into the buffer. This allows for quicker retrieval than performing multiple disk seeks. Denormalized tables require no joins, but there is a sacrifice when it comes to data integrity, and the database size tends to get bigger and bigger.
When your database is large, consider having a DDL (Data Definition Language) for your database table in MySQL/MariaDB.
If you want to add a primary or unique key for your table, that requires a table rebuild. Similarly, changing a column data type also requires a table rebuild as the only algorithm applicable is ALGORITHM=COPY.
If you’re doing this in your production environment, it can be challenging. Double the challenge if your table is huge. Imagine a million or a billion numbers of rows.
You cannot apply an ALTER TABLE statement directly to your table. That can block all incoming traffic that shall need to access the table currently you are applying to the DDL.
This can be mitigated by using pt-online-schema-change or the great gh-ost. Nevertheless, it requires monitoring and maintenance while doing the process of DDL.
Sharding and partitioning
With sharding and partitioning, you’re able to segregate or segment the data according to its logical identity. For example, by segregating based on date, alphabetical order, country, state, or primary key based on the given range.
This helps keep your database to a manageable size.
You can then maintain the size of your database so that it never exceeds the limit of what’s manageable to your team or your organization.
Databases that use sharding and partitioning are easy to scale, when necessary, and they are also more easily managed when a disaster occurs.
However, you do need to consider the capacity resources of your server and your engineering team. For example, you cannot work effectively with a huge volume of data if you have few engineers.
If you’re working with a thousand databases containing large numbers of data sets, this places a huge demand on time. Access to the right skills and expertise is a must to manage such a scenario.
It’s not always straightforward to find and keep the talent required. But you can leverage third party services that offer managed services, paid consultation, or support for such engineering work to be catered.
Character sets and collation
Character sets and collations affect data storage and performance, especially on the given character set and collations selected. Each character set and collation has its own purpose and requires space for storage. This can get reasonably large in size depending on the type of charset and collation you choose.
If you have tables that require other characters sets and collations due to character encoding, your database will be impacted from the increase in the size and length of the columns in your tables.
This affects how to manage your database effectively.
You will need to take note of the character set and collations to be used so that you understand the character types processed by your application.
LATIN character sets usually suffice for alphanumeric characters to be stored and processed.
However, if your data requires additional character sets and collations, then sharding and partitioning helps to at least mitigate and limit the bloating in your database server.
Also keep in mind that managing very large data sets on a single database server can affect efficiency, especially for backup purposes, disaster and recovery, or data recovery as well in case of data corruption or data loss.
Database complexity affects performance
Database size is not the only element that can cause performance penalties. Complexity is also a factor. Complexity, in this case, means that the content of your database consists of mathematical equations, coordinates, or numerical and financial records.
The level of complexity spikes even more when these records are mixed with queries that aggressively use the mathematical functions native to the database.
For example, take a look at the SQL (MySQL/MariaDB compatible) query below.
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
What if this query is applied on a table ranging from a million rows?
There is a huge possibility that this query would stall the server, and it could be resource intensive causing danger to the stability of your production database cluster.
Involved columns tend to be indexed to optimize and make this query performant. However, adding indexes to the referenced columns for optimal performance doesn’t guarantee the efficiency of managing your large databases.
To reduce this type of complexity, try to avoid rigorous usage of complex mathematical equations and aggressive usage of the built-in computational capabilities.
This work can be operated and transported through backend programming languages instead of using the database.
If you have complex computations, then why not store these equations in the database, retrieve the queries, and then organize the data into a structure that’s easier to analyze or debug when needed.
Are you using the right database engine?
Data structure affects the performance of the database server. This is based on the combination of the query given and the records that are read or retrieved from the table.
The database engines within MySQL/MariaDB support InnoDB and MyISAM which use B-Trees. Meanwhile NDB or Memory database engines use Hash Mapping.
These data structures have asymptotic notation, which expresses the performance of the algorithms used by these data structures. In computer science, this is known as Big O notation which describes the performance or complexity of an algorithm.
Given that InnoDB and MyISAM use B-Trees, it uses O(log n) for search. Whereas, Hash Tables or Hash Maps use O(n). Both share the average and worst case for its performance with its notation.
Both the data structure of the engine and the query to be applied, based on the target data to be retrieved, affects the performance of your database server.
For example, hash tables cannot do range retrieval, whereas B-Trees is very efficient for doing these types of searches and also it can handle large amounts of data.
In short, you need to use the right engine for the data you store.
To make the right decision, you need to identify:
- The types and volumes of data that you’ll be managing
- The type of queries you’ll apply to retrieve data
- The type of logic that will transform the data into business logic
When dealing with thousands of databases, good performance results from using the right engine to handle the queries you will run and the data that you want to store and retrieve.
For this, you need to predetermine and analyze your requirements and choose the right database environment.
Appropriate tools to manage large databases
Simply put, it’s difficult to manage a very large database without a solid platform that you can rely upon. Even with highly skilled database engineers, the database server you are using will always be open to human error.
One mistake when making any changes to your configuration parameters and variables might result in a drastic change, causing the server’s performance to degrade.
For example, performing backup to a very large database can be challenging at times.
There are occurrences when the backup might fail for some strange reasons. Commonly, it’s down to queries that stall the server where the backup is running, and cause it to fail.
But there will be other failures that require you to investigate the cause.
There are tools you can use to automate such as Chef, Puppet, Ansible, Terraform, or SaltStack. These can be used to perform certain tasks more quickly.
Meanwhile, other third-party tools can be used to help you with monitoring and providing high quality graph images.
Alert and alarm notification systems are also very important to notify you about issues that can occur, whether it’s a minor warning or a critical problem.
Using ClusterControl to create an on-demand backup with Xtrabackup
ClusterControl enables you to manage a large number of databases or sharded environments. It has been rigorously tested and installed thousands of times and provides alarms and notifications to the DBAs, engineers, or DevOps team in charge of database operations.
ClusterControl also automates the performance of backup and restore. Even with large databases, it can be efficient and easy to manage since the platform provides scheduling and also has options to upload it to the cloud (AWS, Google Cloud, and Azure).
There’s also a backup verification and a lot of options such as encryption and compression.
For example, let’s run through the three simple steps to create an on-demand backup with Xtrabackup using ClusterControl.
1. Create your backup
First step, choose the cluster you want to create a backup for.
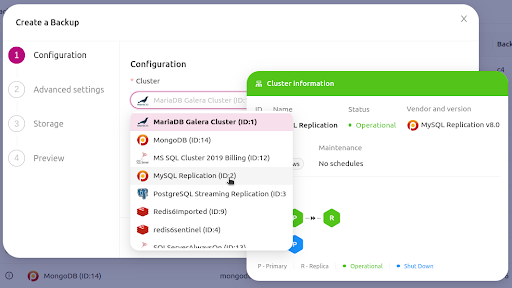
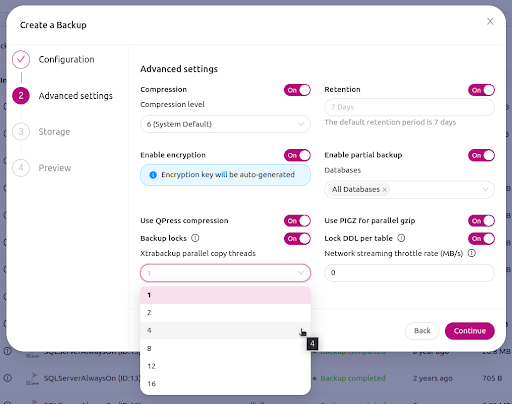
You will then have multiple options to set when creating a backup.
Among the available options you can set the retention days of your backup, whether the backup requires encryption, and how many Xtrabackup parallel threads are required for copying.
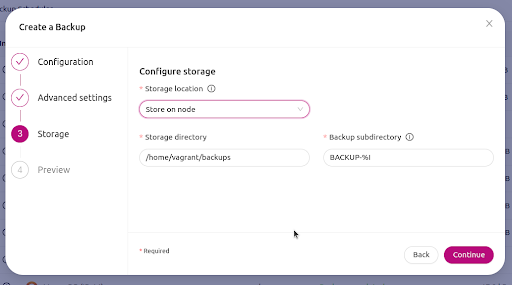
Choose where your backup will be stored
Next, you can choose where your backup will be stored.
You can select to store it on the same node the backup was taken from, or it can be stored in the ClusterControl host.
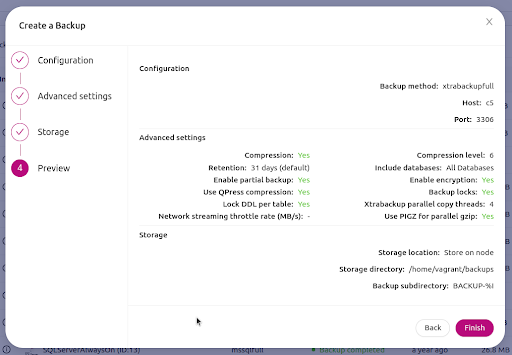
Preview your backup and finish
Lastly, you will have a preview of your backup recipe settings.
Once you are set, just hit the Finish button to proceed with creating the backup via on-demand.
Conclusion
It’s not easy to manage large databases, but it can be done efficiently. You need to have a thorough understanding of your requirements and a plan for how you will respond to growth.
Using the right tools for automation, or even subscribing to managed services, helps drastically. Otherwise, you will need a sizable, experienced, and highly skilled team of engineers to keep things running smoothly.
Stay on top of all things database management by subscribing to our newsletter below.
Follow us on LinkedIn and Twitter for more great content in the coming weeks. Stay tuned!



