blog
Best Practices in Scaling Databases: Part 1

All of you have heard about scaling – your architecture should be scalable, you should be able to scale up to meet the demand, so on and so forth. What does it mean when we talk about databases? How does the scaling look like behind the scenes? This topic is vast and there is no way to cover all of the aspects. This two-blog post series is an attempt to give you an insight into the topic of database scalability.
Why do we Scale?
First, let’s take a look at what scalability is about. In short, we are talking about the ability to handle higher load by your database systems. It can be a matter of dealing with short-lived spikes in the activity, it can be a matter of dealing with a gradually increased workload in your database environment. There can be numerous reasons to consider scaling. Most of them come with their own challenges. We can spend some time going through examples of the situation where we may want to scale out.
Resource consumption Increase
This is the most generic one – your load has increased to the point where your existing resources are no longer capable to deal with it. It can be anything. CPU load has increased and your database cluster is no longer able to deliver data with reasonable and stable query execution time. Memory utilization has grown to an extent that the database is no longer CPU-bound but became I/O-bound and, as such, performance of the database nodes has been significantly reduced. Network can as well be a bootle-neck. You may be surprised to see what limits related to networking have your cloud instances assigned. In fact, this may become the most common limit you have to deal with as the network is everything in the cloud – not just the data sent between the application and the database but also storage is attached over the network. It can also be disk usage – you are just running out of disk space or, more likely, given we can have quite large disks nowadays, the database size outgrew the “manageable” size. Maintenance like schema change becomes a challenge, performance is reduced due to data size, backups are taking ages to complete. All those cases may be a valid case for a need for scale up.
Sudden increase in the workload
Another example case where scaling is required is a sudden increase in the workload. For some reason (be it marketing efforts, content going viral, emergency or similar situation) your infrastructure experiences a significant increase in the load on the database cluster. CPU load goes over the roof, disk I/O is slowing down the queries etc. Pretty much every resource that we mentioned in the previous section can be overloaded and start causing issues.
Planned operation
Third reason we’d like to highlight is the more generic one – some sort of a planned operation. It can be a planned marketing activity that you expect to bring in more traffic, Black Friday, load testing or pretty much anything that you know in advance.
Each of those reasons has its own characteristics. If you can plan in advance, you can prepare the process in detail, test it and execute it whenever you feel like it. You will most likely like to do it in a “low traffic” period, as long as something like that exists in your workloads (it doesn’t have to exist). On the other hand, sudden spikes in the load, especially if they are significant enough to impact the production, will force immediate reaction, no matter how prepared you are and how safe it is – if your services are already impacted you may as well just go for it instead of waiting.
Types of Database Scaling
There are two main types of scaling: vertical and horizontal. Both have pros and cons, both are useful in different situations. Let’s take a look at them and discuss use cases for both scenarios.
Vertical scaling
This scaling method is probably the oldest one: if your hardware is not beefy enough to deal with the workload, beef it up. We are talking here simply about adding resources to existing nodes with an intent to make them capable enough to deal with the tasks given. This has some repercussions we’d like to go over.
Advantages of vertical scaling
The most important bit is that everything stays the same. You had three nodes in a database cluster, you still have three nodes, just more capable. There is no need to redesign your environment, change how the application should access the database – everything stays precisely the same because, configuration-wise, nothing has really changed.
Another significant advantage of vertical scaling is that it can be very fast, especially in cloud environments. The whole process is, pretty much, to stop the existing node, make the change in the hardware, start the node again. For classic, on-prem setups, without any virtualization, this might be tricky – you may not have faster CPU’s available to swap, upgrading disks to larger or faster may also be time consuming, but for cloud environments, be it public or private, this can be as easy as running three commands: stop instance, upgrade instance to larger size, start instance. Virtual IP’s and re-attachable volumes make it easy to move data around between instances.
Disadvantages of vertical scaling
The main disadvantage of vertical scaling is that, simply, it has its limits. If you are running on the largest instance size available, with the fastest disk volumes, there’s not much else you can do. It is also not that easy to increase the performance of your database cluster significantly. It mostly depends on the initial instance size, but if you are already running quite performant nodes, you may not be able to achieve 10x scale-out using vertical scaling. Nodes that would be 10x faster may, simply, not exist.
Horizontal scaling
Horizontal scaling is a different beast. Instead of going up with the instance size, we stay at the same level but we expand horizontally by adding more nodes. Again, there are pros and cons of this method.
Pros of horizontal scaling
The main advantage of horizontal scaling is that, theoretically, sky’s the limit. There is no artificial hard limit of scale-out, even though limits do exist, mainly due to intra-cluster communication being bigger and bigger overhead with every new node added to the cluster.
Another significant advantage would be that you can scale up the cluster without a need for downtime. If you want to upgrade hardware, you have to stop the instance, upgrade it and then start again. If you want to add more nodes to the cluster, all you need to do is to provision those nodes, install whatever software you need, including the database, and let it join the cluster. Optionally (depending if the cluster has internal methods to provision new nodes with the data) you may have to provision it with data on your own. Typically, though, it is an automated process.
Cons of horizontal scaling
The main problem that you have to deal with is that adding more and more nodes makes it hard to manage the whole environment. You have to be able to tell which nodes are available, such a list has to be maintained and updated with every new node created. You may need external solutions like directory service (Consul or Etcd) to keep the track of the nodes and their state. This, obviously, increases the complexity of the whole environment.
Another potential issue is that the scale-out process takes time. Adding new nodes and provisioning them with software and, especially, data requires time. How much, it depends on the hardware (mainly I/O and network throughput) and the size of the data. For large setups this may be a significant amount of time and this may be a blocker for situations where the scale-up has to happen immediately. Waiting hours to add new nodes may not be acceptable if the database cluster is impacted to the extent that operations are not being performed properly.
Scaling Prerequisites
Data replication
Before any attempt for scaling can be made, your environment must meet a couple of requirements. For starters, your application has to be able to take advantage of more than one node. If it can use just one node, your options are pretty much limited to vertical scaling. You can increase the size of such node or add some hardware resources to the bare metal server and make it more performant but that’s the best you can do: you will always be limited by the availability of more performant hardware and, eventually, you will find yourself without an option to further scale up.
On the other hand, if you have the means to utilize multiple database nodes by your application, you can benefit from horizontal scaling. Let’s stop here and discuss what is that you need to actually use multiple nodes to their full potential.
For starters, the ability to split reads from writes. Traditionally the application connects to just one node. That node is used to handle all writes and all reads executed by the application.

Adding a second node to the cluster, from the scaling standpoint, changes nothing. You have to keep in mind that, should one node fail, the other will have to handle the traffic, so at no point the sum of load across both nodes should be too high for one single node to deal with.

With three nodes available you can fully utilize two nodes. This allows us to scale out some of the read traffic: if one node has 100% capacity (and we would rather run at most at 70%), then two nodes represent 200%. Three nodes: 300%. If one node is down and if we’ll push remaining nodes almost to the limit, we can say that we are able to work with 170 – 180% of a single node capacity if the cluster is degraded. That gives us a nice 60% load on every node if all three nodes are available.
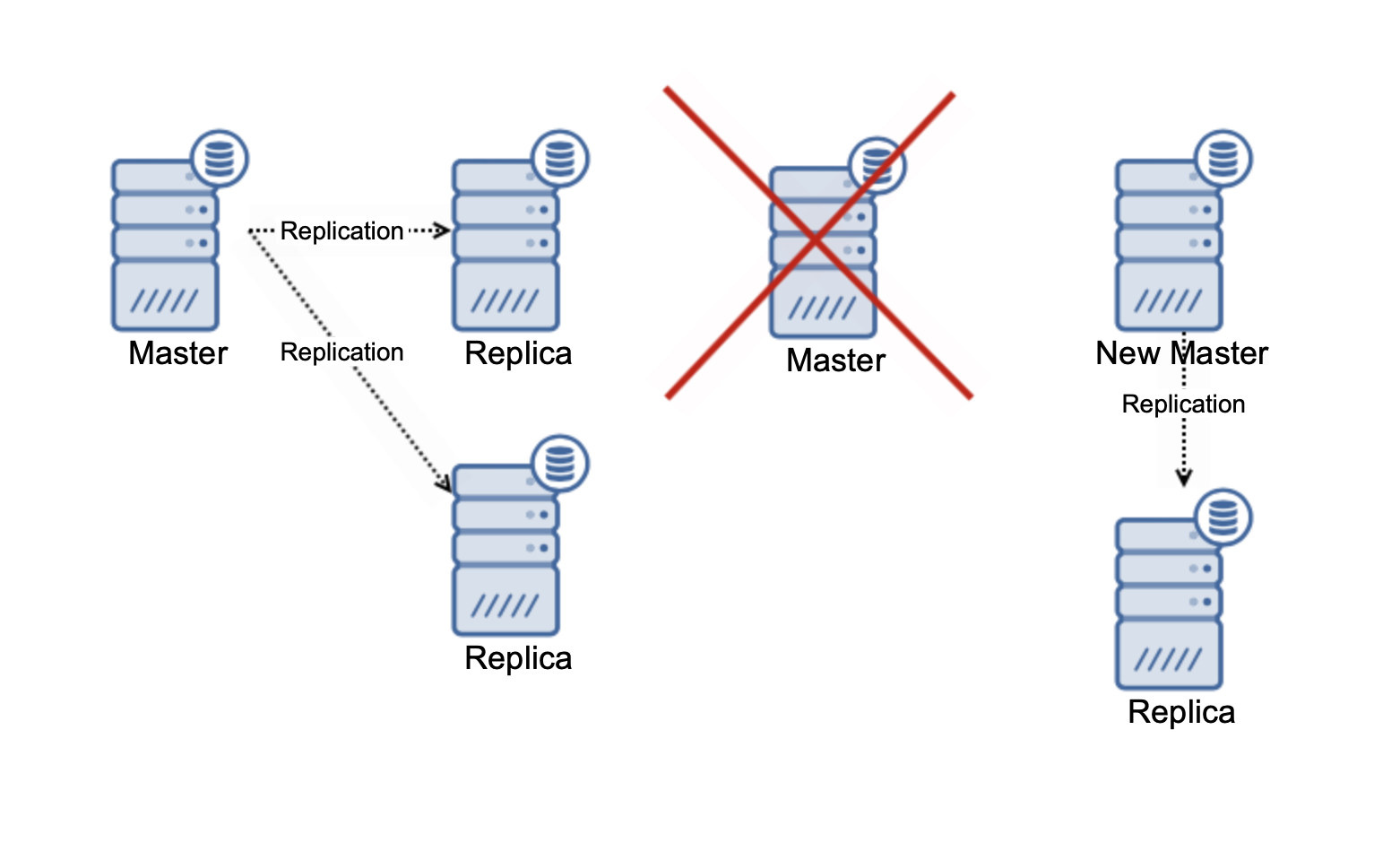
Please keep in mind that we are talking only about scaling reads at this moment. At no point in time replication can improve your write capacity. In asynchronous replication, you have only one writer (master), and for the synchronous replication, like Galera, where the dataset is shared across all nodes, every write that is happening on one node will have to be performed on the remaining nodes of the cluster.
In a three node Galera cluster, if you write one row, you in fact write three rows, one for every node. Adding more nodes or replicas won’t make a difference. Instead of writing the same row on three nodes you’ll write it on five. This is why splitting your writes in a multi-master cluster, where the data set is shared across all nodes (there are multi-master clusters where data is sharded, for example MySQL NDB Cluster – here the write scalability story is totally different), doesn’t make too much sense. It adds overhead of dealing with potential write conflicts across all nodes while it is not really changing anything regarding the total write capacity.
Loadbalancing and read/write split
The ability to split reads from writes is a must if you want to scale your reads in asynchronous replication setups. You have to be able to send write traffic to one node and then send the reads to all nodes in the replication topology. As we mentioned earlier, this functionality is also quite useful in the multi-master clusters as it allows us to remove the write conflicts that may happen if you attempt to distribute the writes across multiple nodes in the cluster. How can we perform the read/write split? There are several methods you can use to do it. Let’s dig into this topic for a bit.
Application level R/W split
The most simple scenario, the least frequent as well: your application is able to be configured which nodes should receive writes and which nodes should receive reads. This functionality can be configured in a couple of ways, most simple being the hardcoded list of the nodes but it also could be something along the lines of dynamic node inventory updated by background threads. The main problem with this approach is that the whole logic has to be written as a part of the application. With a hardcoded list of nodes, the simplest scenario would require changes to the application code for every change in the replication topology. On the other hand, more advanced solutions like implementing a service discovery would be more complex to maintain in the long run.
R/W split in connector
Another option would be to use a connector to perform a read/write split. Not all of them have this option, but some do. An example would be php-mysqlnd or Connector/J. How it is integrated into the application, it may differ based on the connector itself. In some cases configuration has to be done in the application, in some cases it has to be done in a separate configuration file for the connector. The advantage of this approach is that even if you have to extend your application, most of the new code is ready to use and maintained by external sources. It makes it easier to deal with such setup and you have to write less code (if any).
R/W split in loadbalancer
Finally, one of the best solutions: loadbalancers. The idea is simple – pass your data through a loadbalancer that will be able to distinguish between reads and writes and send them to a proper location. This is a great improvement from the usability standpoint as we can separate database discovery and query routing from the application. The only thing the application has to do is send the database traffic to a single endpoint that consists of a hostname and a port. The rest happens in the background. Loadbalancers are working to route the queries to a backend database nodes. Loadbalancers can also do replication topology discovery or you can implement a proper service inventory using etcd or consul and update it through your infrastructure orchestration tools like Ansible.
Wrapping up
This concludes the first part of this blog. In part two, we will discuss the challenges we are facing when scaling the database tier. We will also discuss some ways in which we can scale out our database clusters.



