blog
How to Deploy PostgreSQL for High Availability

Introduction
Nowadays, high availability is a requirement for many systems, no matter what technology you’re using. This is especially important for databases, as they store data that critical applications and systems rely on. The most common strategy for achieving high availability is replication. There are different ways to replicate data across multiple servers and failover traffic when, for example, a primary server stops responding.
High Availability Architecture for PostgreSQL
There are several architectures for implementing high availability in PostgreSQL, but the basic ones are Primary-Standby and Primary-Primary architectures.
Primary-Standby Architectures
Primary-Standby may be the most basic HA architecture you can set up and, oftentimes, the easiest to implement and maintain. It’s based on one Primary database with one or more Standby servers. These Standby databases will remain synchronized (or almost synchronized) with the Primary node, depending on whether the replication is synchronous or asynchronous. If the Primary server fails, the Standby server contains almost all of the Primary server’s data and can quickly be turned into the new Primary database server.
You can implement two types of Standby databases, based on the nature of the replication:
- Logical Standbys – The replication between Primary and Standby is made via SQL statements.
- Physical Standbys – The replication between Primary and Standby is made via the internal data structure modifications.
In the case of PostgreSQL, a stream of write-ahead log (WAL) records is used to keep the Standby databases synchronized. This can be synchronous or asynchronous, and the entire database server is replicated.
From version 10 on, PostgreSQL includes a built-in option to set up logical replication, which constructs a stream of logical data modifications from the information in the write-ahead log. This replication method allows the data changes from individual tables to be replicated without needing to designate a Primary server. It also allows data to flow in multiple directions.
Unfortunately, a Primary-Standby setup is not enough to effectively ensure high availability, as you also need to handle failures. To handle failures, you need to be able to detect them. Once you know there is a failure, for example, errors on the Primary node or the node not responding, you can select a standby node to replace the failed node with the least delay possible. This process must be as efficient as possible to restore full functionality to the applications. PostgreSQL itself does not include an automatic failover mechanism, so this will require some custom script or third-party tools for this automation.
After a failover happens, your application needs to be notified accordingly to start using the new Primary. You also need to evaluate the state of your architecture after failover because you can run into a situation where only the new Primary is running (e.g., you had a Primary node and only one Standby before the issue). In that case, you will need to add a Standby node to re-create the Primary-Standby setup you originally had for high availability.
Primary-Primary Architectures
Primary-Primary architecture provides a way of minimizing the impact of an error on one of the nodes, as the other node(s) can take care of all of the traffic, only potentially slightly affecting the performance but never losing functionality. Primary-Primary architecture is often used with the dual purpose of creating a high availability environment and scaling horizontally (as compared to the concept of vertical scalability where you add more resources to a server).
PostgreSQL does not yet support this architecture “natively”, so you will have to refer to third-party tools and implementations. When choosing a solution, you must keep in mind that there are a lot of projects/tools, but some of them are no longer supported anymore, while others are new and might not be battle-tested in production.
Load Balancing
Load balancers are tools that can be used to manage the traffic from your application to get the most out of your database architecture.
Not only are these tools helpful in balancing the load of your databases, but they also help applications get redirected to the available/healthy nodes and even specify ports with different roles.
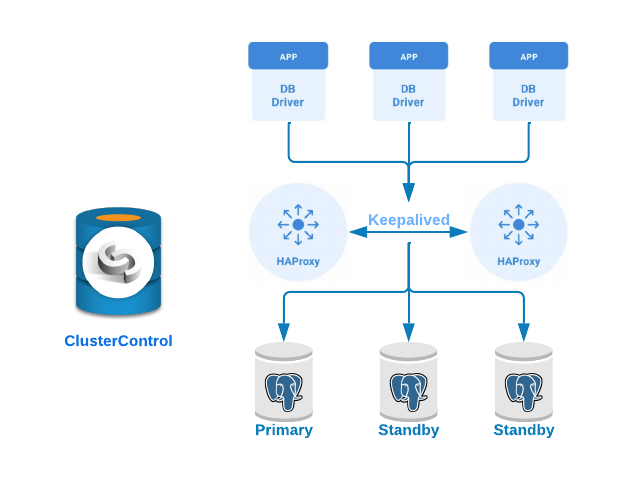
HAProxy is a load balancer that distributes traffic from one origin to one or more destinations and can define specific rules and/or protocols for this task. If any of the destinations stop responding, they are marked as offline, and the traffic is sent to the rest of the available destinations.
Keepalived is a service that allows you to configure a virtual IP address within an active/passive group of servers. This virtual IP address is assigned to an active server. If this server fails, the IP address is automatically migrated to the “Secondary” passive server, allowing it to continue working with the same IP address in a transparent way for the systems.
Let’s see now how to implement a Primary-Standby PostgreSQL cluster with load balancer servers and keepalived configured between them. We’ll demonstrate this using ClusterControl’s easy-to-use interface.
For this example, we will create:
- 3 PostgreSQL servers (one Primary and two Standbys).
- 2 HAProxy Load Balancers.
- Keepalived configured between the load balancer servers.
Database deployment
To deploy a database using ClusterControl, simply select the option “Deploy” and follow the instructions that appear.
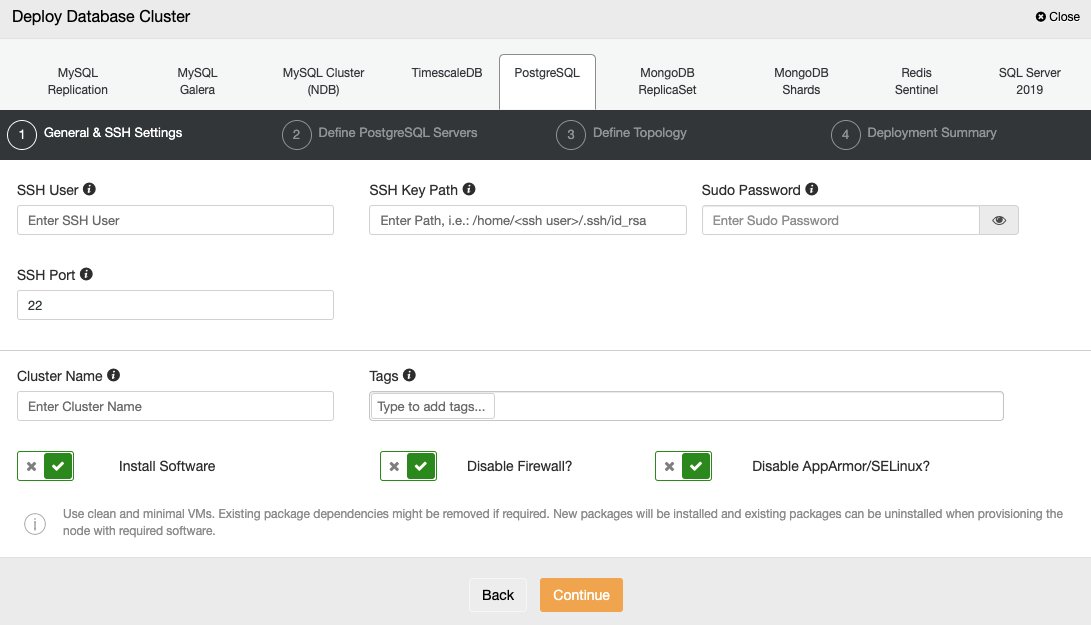
When selecting PostgreSQL, you must specify the User, Key or Password, and Port to connect by SSH to your servers. You also need the name for your new cluster and choose if you want ClusterControl to install the corresponding software and configurations for you.
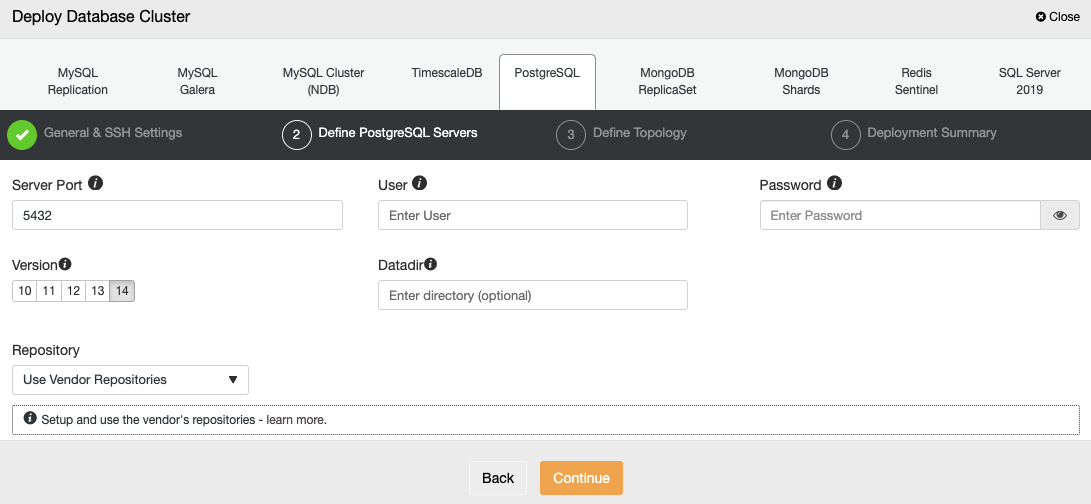
After setting up the SSH access information, you must define the database user, version, and datadir (optional). You can also specify which repository to use; the official vendor repository will be used by default.
In the next step, you need to add your servers to the cluster you will create.
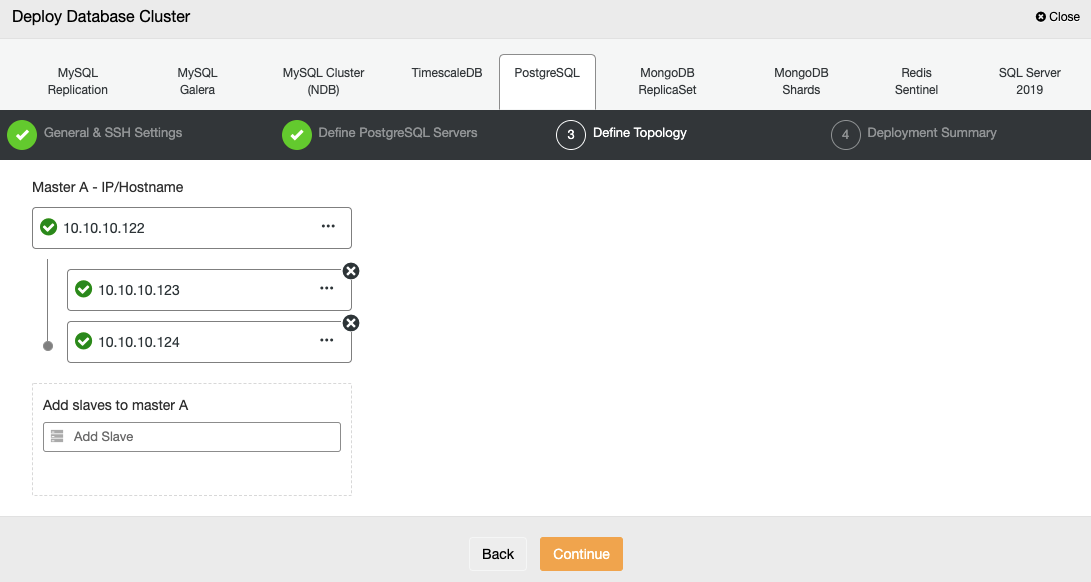
When adding your servers, you can enter IP or hostname.
In the last step, you can choose if your replication will be Synchronous or Asynchronous.
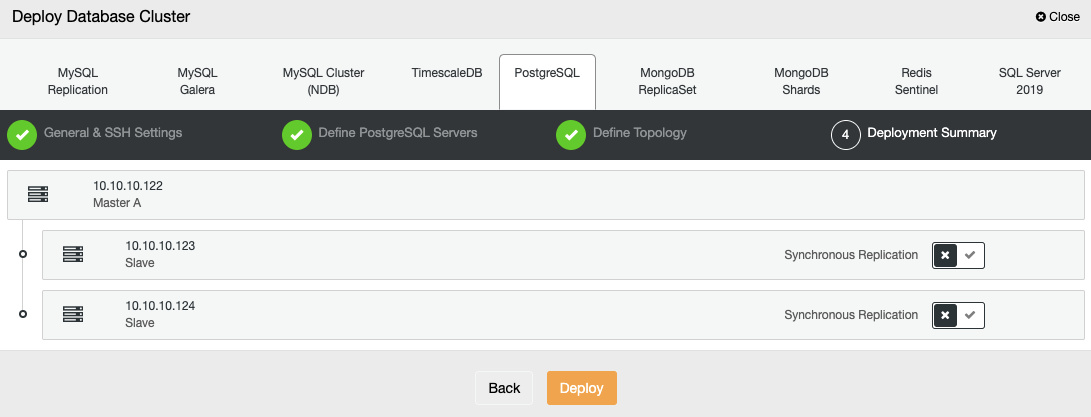
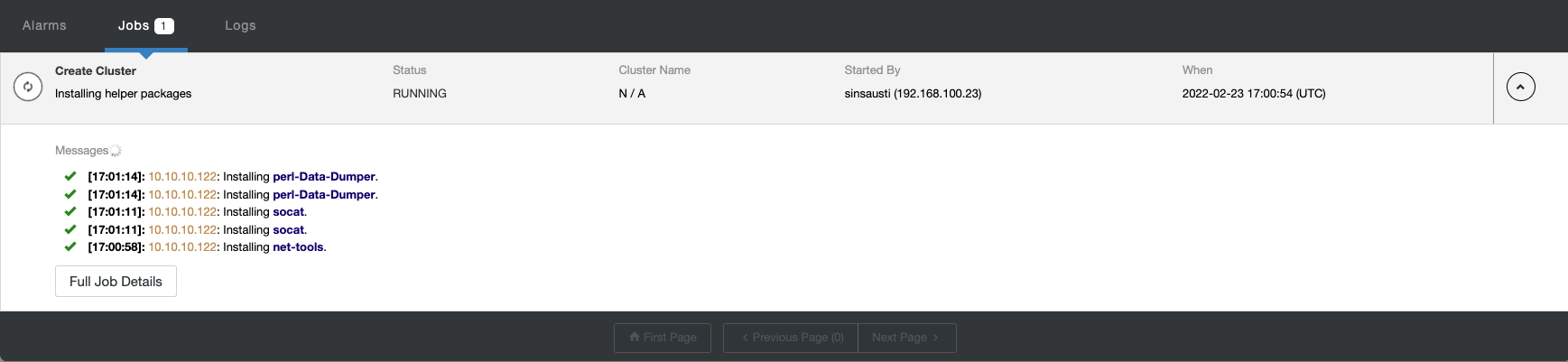
You can monitor the status of the creation of your new cluster from the ClusterControl activity monitor.
Once the task is finished, you can see your cluster in the main ClusterControl screen.
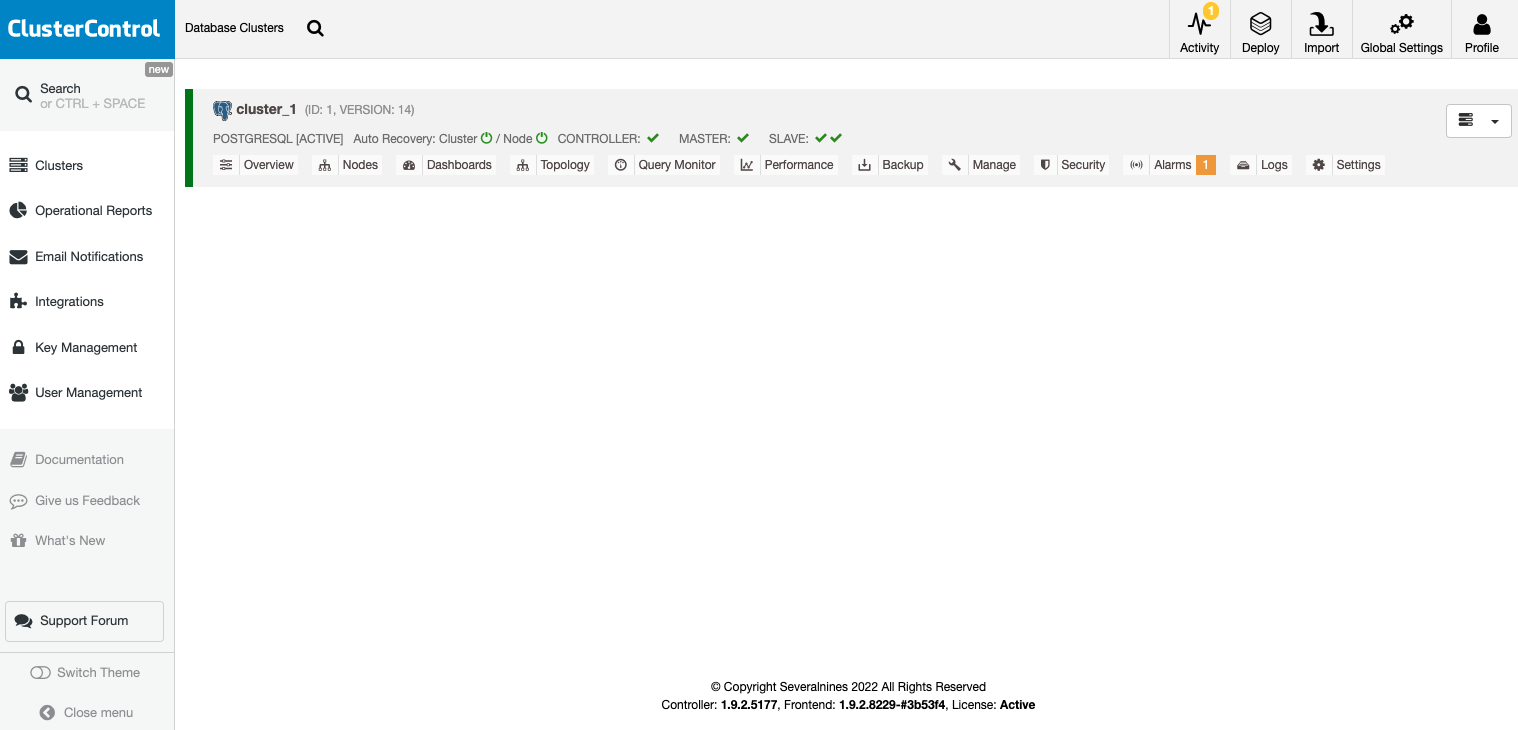
Once your cluster is created, you can perform several tasks, like adding a load balancer (HAProxy) or a new replica.
Load Balancer Deployment
To perform a load balancer deployment, select the “Add Load Balancer” option in the cluster actions and fill in the requested information.
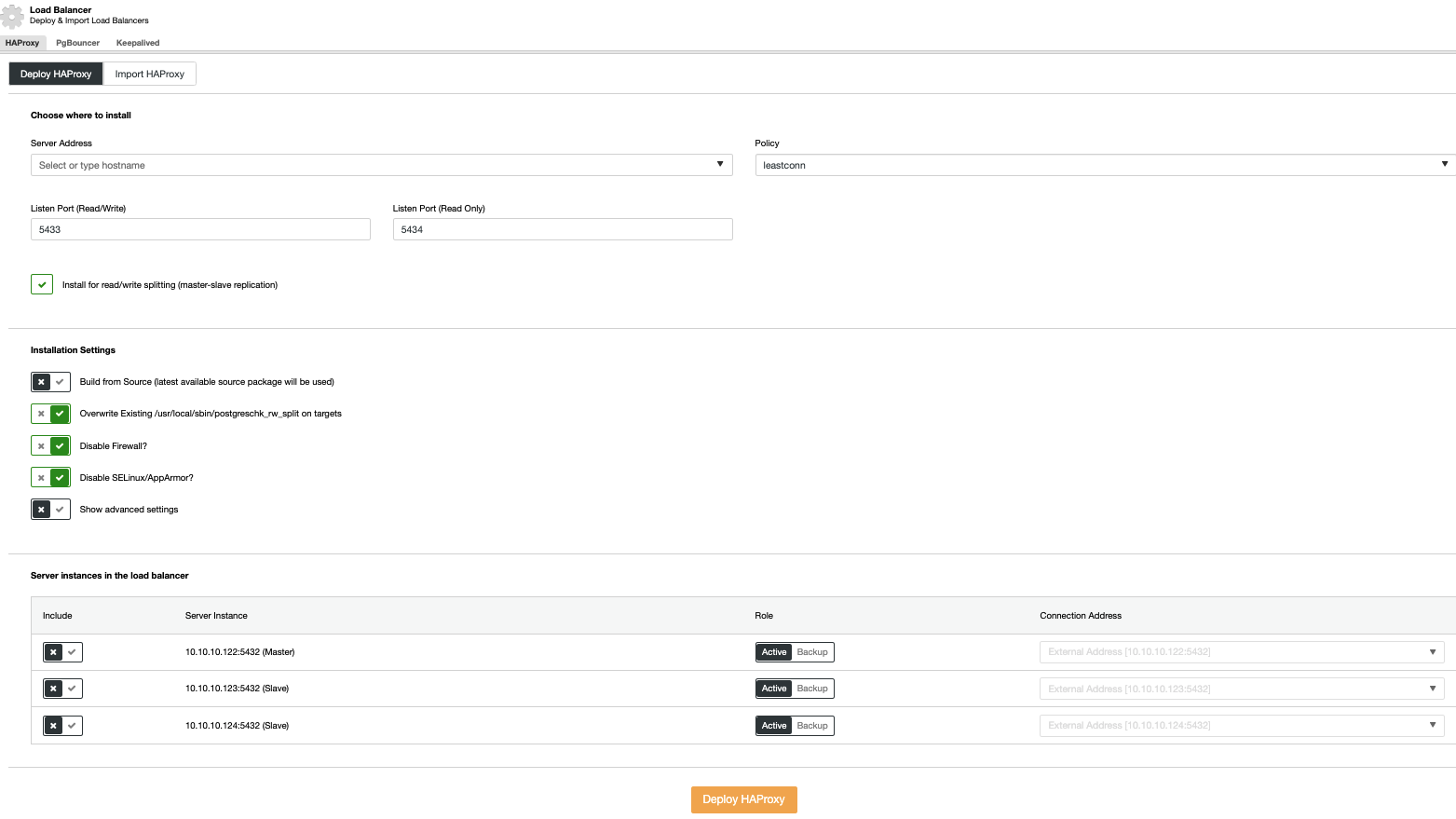
You only need to add the IP address or Hostname, Port, Policy, and the nodes you will configure in your load balancers.
Keepalived Deployment
To perform a keepalived deployment, select the cluster, go to the “Manage” menu and “Load Balancer” section, and then select the “Keepalived” option.
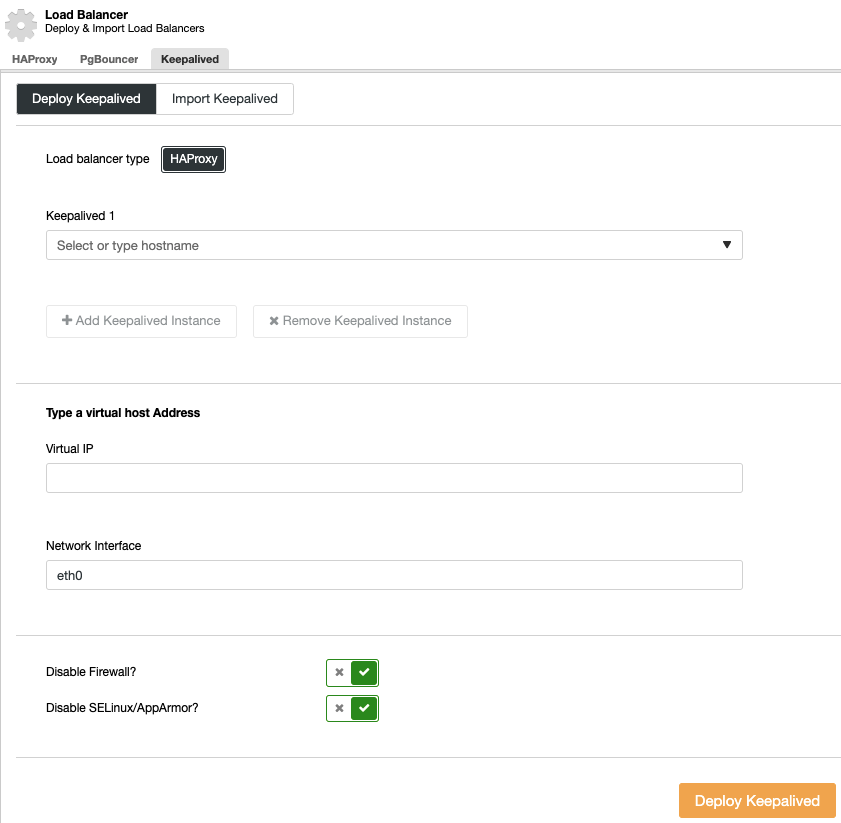
You must select the load balancer servers and the virtual IP address for your high availability environment.
Keepalived uses the virtual IP address and migrates it from one load balancer to another in case of failure, so your systems can continue to function normally.
If you followed the previous steps, you should have the following topology:
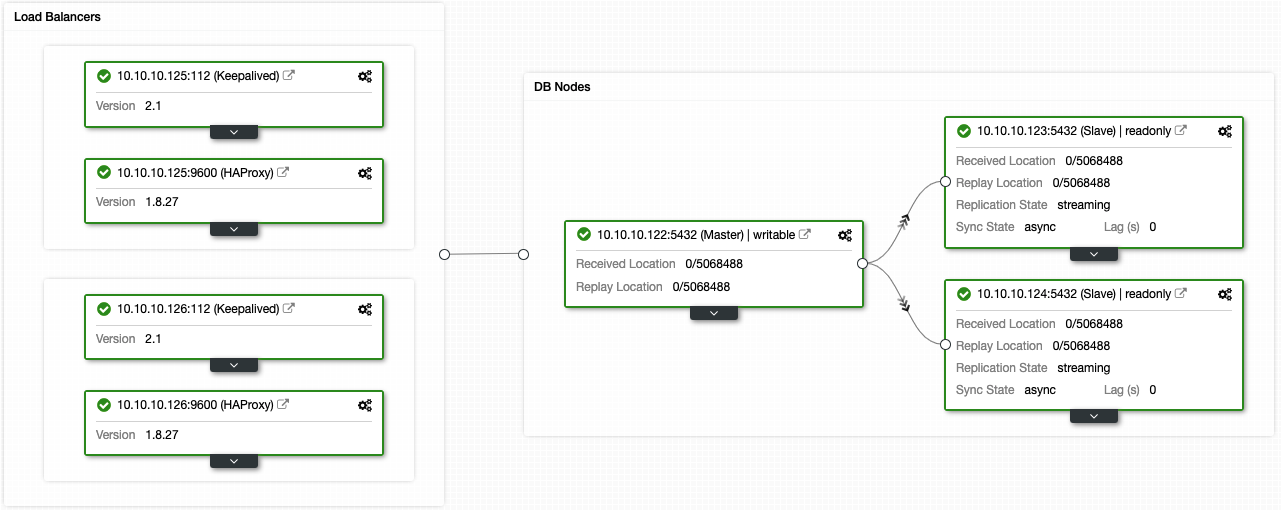
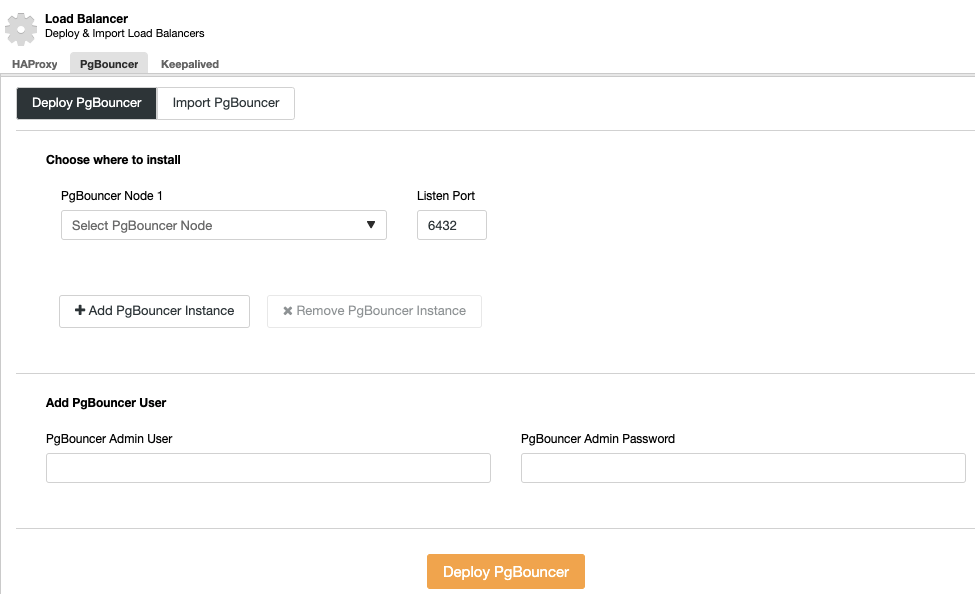
You can improve this high availability environment by adding a connection pooler like PgBouncer. It is not a must but could be helpful to improve performance and handle active connections in case of failure, and the best thing is, you can also deploy it by using ClusterControl.
ClusterControl Failover
Suppose the “Autorecovery” option is ON in your ClusterControl server. In case of a Primary failure, ClusterControl will promote the most advanced Standby (if it’s not on the blacklist) to Primary, as well as notify you of the problem. It will also failover the rest of the Standby nodes to replicate from the new Primary.
HAProxy is configured by default with two different ports; read-write and read-only ports.
In your read-write port, you have your Primary server as online and the rest of your nodes as offline, and in the read-only port, you have both Primary and Standbys online.
When HAProxy detects that one of your nodes, either Primary or Standby, is not accessible, it automatically marks it as offline. It does not take it into account for sending traffic to it. Detection is performed by health check scripts that ClusterControl configures at the time of deployment. These check whether the instances are up, whether they are undergoing recovery, or are read-only.
When ClusterControl promotes a Standby to Primary, your HAProxy marks the old Primary as offline for both ports and puts the promoted node online in the read-write port.
If your active HAProxy, which has assigned the Virtual IP address to which your systems connect, fails, Keepalived migrates this IP address to your passive HAProxy automatically. This means that your systems are then able to continue to function normally.
In this way, your systems continue to operate as expected and without your manual intervention.
Considerations
If you manage to recover your old failed Primary node, it will NOT be re-introduced automatically to the cluster by default. You need to do it manually. One reason for this is that if your replica was delayed at the time of the failure, and ClusterControl adds the old Primary to the cluster, it would mean loss of information or data inconsistency across the nodes. You might also want to analyze the issue in detail. If ClusterControl just re-introduced the failed node into the cluster, you would possibly lose diagnostic information.
Also, if failover fails, no further attempts are made. Manual intervention is required to analyze the problem and perform the corresponding actions. This is to avoid the situation where ClusterControl, as the high availability manager, tries to promote the next Standby and the next one. There might be a problem, and you will need to check this.
Security
One important thing you cannot forget before going into production with your high availability environment is to ensure its security.
Several security aspects to consider include encryption, role management, and access restriction by IP address, which we have covered in-depth in a previous blog.
In your PostgreSQL database, you have the pg_hba.conf file, which handles the client authentication. You can limit the type of connection, source IP address or network, which database you can connect to, and with which users. Therefore, this file is a critical piece for PostgreSQL security.
You can configure your PostgreSQL database from the postgresql.conf file, so it only listens on a specific network interface and a different port than the default one (5432), thus avoiding basic connection attempts from unwanted sources.
Proper user management, either using secure passwords or limiting access and privileges, is another vital piece of your security settings. It’s recommended that you assign the least amount of privileges possible to all users and specify, if possible, the source of the connection.
You can also enable data encryption, either in transit or at rest, avoiding access to information to unauthorized persons.
An audit log is helpful for understanding what is happening or has happened in your database. PostgreSQL allows you to configure several parameters for logging or even use the pgAudit extension for this task.
Last but not least, it’s recommended to keep your database and servers up to date with the latest patches to avoid security risks. For this, ClusterControl allows you to generate operational reports to verify if you have available updates and even help you update your database servers.
Conclusion
High availability deployments can seem difficult to achieve, particularly when it comes to understanding the different architectures and necessary components to configure them correctly.
If you’re managing HA manually, be sure to check out Performing Replication Topology Changes for PostgreSQL. Many will look for tools like ClusterControl to help manage deployment, load balancers, failover, security, and more for a complete high availability environment. You can download ClusterControl for free for 30 days to see how it can ease the burden of managing a high availability database infrastructure.
However you choose to manage your high availability PostgreSQL databases, be sure to follow us on Twitter or LinkedIn, or subscribe to our newsletter to get the latest updates and best practices for managing your database setups.



