blog
How to Automate Database Failover with ClusterControl

Recovery Time Objective (RTO) is the time period within which a service must be restored to avoid unacceptable consequences. By calculating how long it can take to recover from a database failure, we can know what the level of preparation required. If RTO is a few minutes, then significant investment in failover is required. An RTO of 36 hours requires a significantly lower investment. This is where failover automation comes in.
In our previous blogs, we have discussed failover for MongoDB, MySQL/MariaDB/Percona, PostgreSQL or TimeScaleDB. To sum it up, “Failover” is the ability of a system to continue functioning even if some failure occurs. It suggests that the functions of the system are assumed by secondary components if the primary components fail. Failover is a natural part of any high availability system, and in some cases, it even has to be automated. Manual failovers take just too long, but there are cases where automation will not work well – for instance in case of a split brain where database replication is broken and the two ‘halves’ keep receiving updates, effectively leading to diverging data sets and inconsistency.
We previously wrote about the guiding principles behind ClusterControl automatic failover procedures. Where possible, automated failover provides efficiency as it enables quick recovery from failures. In this blog, we’ll look at how to achieve automatic failover in a master-slave (or primary-standby) replication setup using ClusterControl.
Technology Stack Requirements
A stack can be assembled from Open Source Software components, and there are a number of options available – some more appropriate than others depending on failover characteristics and also level of expertise available for managing and maintaining the solution. Hardware and networking are also important aspects.
Software
There are lots of options available in the open source ecosystem that you can use to implement failover. For MySQL, you can take advantage of MHA, MMM, Maxscale/MRM, mysqlfailover, or Orchestrator. This previous blog compares MaxScale to MHA to Maxscale/MRM. PostgreSQL has repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II, or stolon. These different high availability options were covered previously. MongoDB has replica sets with support for automated failover.
ClusterControl provides automatic failover functionality for MySQL, MariaDB, PostgreSQL and MongoDB, which we will cover further down. Worth to note that it also has functionality to automatically recover broken nodes or clusters.
Hardware
Automatic failover is typically performed by a separate daemon server that is setup on its own hardware – separate from the database nodes. It is monitoring the status of the databases, and uses the information to make decisions on how to react in case of failure.
Commodity servers can work fine, unless the server is monitoring a huge number of instances. Typically, system checks and health analysis are lightweight in terms of processing. However, if you have a large number of nodes to check, large CPU and memory is a must especially when checks have to be queued up as it tries to ping and collect information from servers. The nodes being monitored and supervised might stall sometimes due to network issues, high load, or at worse case, they might be down due to a hardware failure or some VM host corruption. So the server that runs the health and system checks shall be able to withstand such stalls, as chances are that processing of queues can go up as responses to each of the nodes monitored can take time until verified that it’s no longer available or a timeout has been reached.
For cloud-based environments, there are services that offer automatic failover. For instance, Amazon RDS uses DRBD to replicate storage to a standby node. Or if you are storing your volumes in EBS, these are replicated in multiple zones.
Network
Automated failover software often relies on agents that are setup on the database nodes. The agent harvests information locally from the database instance and sends it to the server, whenever requested.
In terms of network requirements, make sure that you have good bandwidth and a stable network connection. Checks need to be done frequently, and missed heartbeats because of an unstable network may lead to the failover software to (wrongly) deduce that a node is down.
ClusterControl does not require any agent installed on the database nodes, as it will SSH into each database node at regular intervals and perform a number of checks.
Automated Failover with ClusterControl
ClusterControl offers the ability to perform manual as well as automated failovers. Let’s see how this can be done.
Failover in ClusterControl can be configured to be automatic or not. If you prefer to take care of failover manually, you can disable automated cluster recovery. When doing a manual failover, you can go to Cluster → Topology in ClusterControl. See the screenshot below:
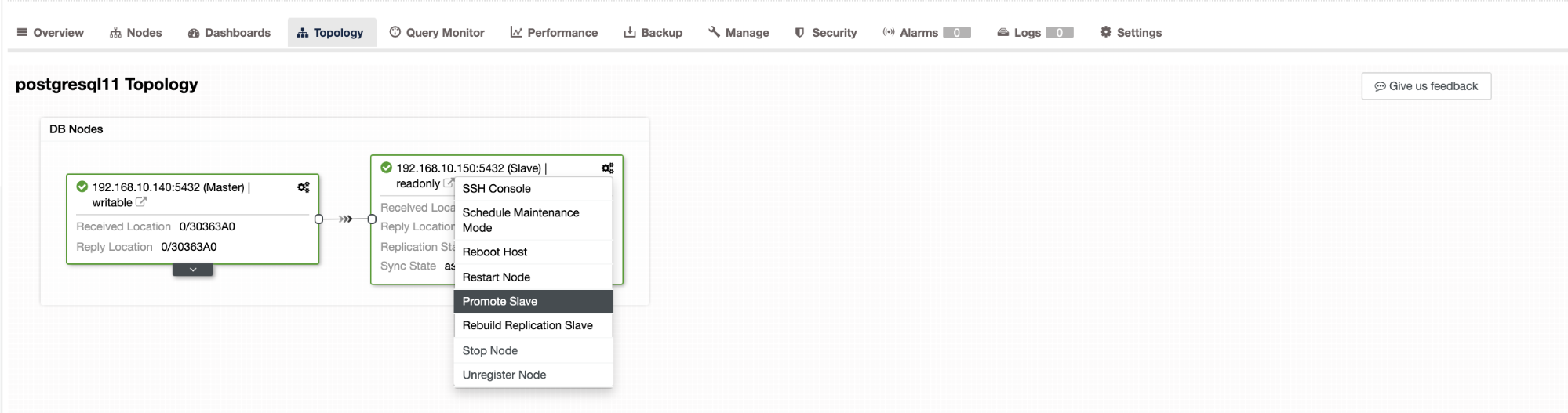
By default, cluster recovery is enabled and automated failover is used. Once you make changes in the UI, the runtime configuration is changed. If you would like the setting to survive a restart of the controller, thenmake sure you also make the change in the cmon configuration, i.e. /etc/cmon.d/cmon_

In MySQL/MariaDB/Percona server, automatic failover is initiated by ClusterControl when it detects that there is no host with read_only flag disabled. It can happen because master (which has read_only set to 0) is not available or it can be triggered by a user or some external software that changed this flag on the master. If you do manual changes to the database nodes or have software that may fiddle with the read_only settings, then you should disable automatic failover. ClusterControl’s automated failover is attempted only once, therefore, a failed failover will not be followed again by a subsequent failover – not until cmon is restarted.
For PostgreSQL, ClusterControl will pick the most advanced slave, using for this purpose the pg_current_xlog_location (PostgreSQL 9+) or pg_current_wal_lsn (PostgreSQL 10+) depending on the version of our database. ClusterControl also performs several checks over the failover process, in order to avoid some common mistakes. One example is that if we manage to recover our old failed master, it will “not” be reintroduced automatically to the cluster, neither as a master nor as a slave. We need to do it manually. This will avoid the possibility of data loss or inconsistency in the case that our slave (that we promoted) was delayed at the time of the failure. We might also want to analyze the issue in detail before re-introducing it to the replication setup, so we would want to preserve diagnostic information.
Also, if failover fails, no further attempts are made (this applies to both PostgreSQL and MySQL-based clusters), manual intervention is required to analyze the problem and perform the corresponding actions. This is to avoid the situation where ClusterControl, which handles the automatic failover, tries to promote the next slave and the next one. There might be a problem, and we do not want to make things worse by attempting multiple failovers.
ClusterControl offers whitelisting and blacklisting of a set of servers that you want to participate in the failover, or exclude as candidate.
For MySQL-type clusters, ClusterControl builds a list of slaves which can be promoted to master. Most of the time, it will contain all slaves in the topology but the user has some additional control over it. There are two variables you can set in the cmon configuration:
replication_failover_whitelistand
replication_failover_blacklistFor the configuration variable replication_failover_whitelist, it contains a list of IP’s or hostnames of slaves which should be used as potential master candidates. If this variable is set, only those hosts will be considered. For variable replication_failover_blacklist, it contains list of hosts which will never be considered a master candidate. You can use it to list slaves that are used for backups or analytical queries. If the hardware varies between slaves, you may want to put here the slaves which use slower hardware.
replication_failover_whitelist takes precedence, meaning the replication_failover_blacklist is ignored if replication_failover_whitelist is set.
Once the list of slaves which may be promoted to master is ready, ClusterControl starts to compare their state, looking for the most up to date slave. Here, the handling of MariaDB and MySQL-based setups differs. For MariaDB setups, ClusterControl picks a slave which has the lowest replication lag of all slaves available. For MySQL setups, ClusterControl picks such a slave as well but then it checks for additional, missing transactions which could have been executed on some of the remaining slaves. If such a transaction is found, ClusterControl slaves the master candidate off that host in order to retrieve all missing transactions. You can skip this process and just use the most advanced slave by setting variable replication_skip_apply_missing_txs in your CMON configuration:
e.g.
replication_skip_apply_missing_txs=1Check our documentation here for more information with variables.
Caveat is that you must only set this if you know what you are doing, as there might be errant transactions. These might cause replication to break, as well as data inconsistency across the cluster. If the errant transaction happened way in the past, it may no longer available in binary logs. In that case, replication will break because slaves won’t be able to retrieve the missing data. Therefore, ClusterControl, by default, checks for any errant transactions before it promotes a master candidate to become a master. If such problem is detected, the master switch is aborted and ClusterControl lets the user fix the problem manually.
If you want to be 100% certain that ClusterControl will promote a new master even if some issues are detected, you can do that using the replication_stop_on_error variable. See below:
e.g.
replication_stop_on_error=0Set this variable in your cmon configuration file. As mentioned earlier, it may lead to problems with replication as slaves may start asking for a binary log event which is not available anymore. To handle such cases we added experimental support for slave rebuilding. If you set the variable
replication_auto_rebuild_slave=1in the cmon configuration and if your slave is marked as down with the following error in MySQL:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControl will attempt to rebuild the slave using data from the master. Such a setting may not always be appropriate as the rebuilding process will induce an increased load on the master. It may also be that your dataset is very large and a regular rebuild is not an option – that’s why this behavior is disabled by default.
Once we ensure that no errant transaction exists and we are good to go, there is still one more issue we need to handle somehow – it may happen that all slaves are lagging behind the master.
As you probably know, replication in MySQL works in a rather simple way. The master stores writes in binary logs. The slave’s I/O thread connects to the master and pulls any binary log events it is missing. It then stores them in the form of relay logs. The SQL thread parses them and applies events. Slave lag is a condition in which SQL thread (or threads) cannot cope with the number of events, and is unable to apply them as soon as they are pulled from the master by the I/O thread. Such situation may happen no matter what type of replication you are using. Even if you use semi-sync replication, it can only guarantee that all events from the master are stored on one of slaves in the relay log. It doesn’t say anything about applying those events to a slave.
The problem here is that, if a slave is promoted to master, relay logs will be wiped out. If a slave is lagging and hasn’t applied all transactions, it will lose data – events that are not yet applied from relay logs will be lost forever.
There is no one-size-fits-all way of solving this situation. ClusterControl gives users control over how it should be done, maintaining safe defaults. It is done in cmon configuration using the following setting:
replication_failover_wait_to_apply_timeout=-1By default it takes a value of ‘-1’, which means that failover won’t happen immediately if a master candidate is lagging, so it is set to wait forever unless the candidate has caught up. ClusterControl will wait indefinitely for it to apply all missing transactions from its relay logs. This is safe, but, if for some reason, the most up-to-date slave is lagging badly, failover may take hours to complete. On the other side of the spectrum is setting it to ‘0’ – it means that failover happens immediately, no matter if the master candidate is lagging or not. You can also go the middle way and set it to some value. This will set a time in seconds, for example 30 seconds so set the variable to,
replication_failover_wait_to_apply_timeout=30When set to > 0, ClusterControl will wait for a master candidate to apply missing transactions from its relay logs until value is met (which is 30 seconds in the example). Failover happens after the defined time or when the master candidate will catch up on replication, whichever happens first. This may be a good choice if your application has specific requirements regarding downtime and you have to elect a new master within a short time window.
For more details about how ClusterControl works with automatic failover in PostgreSQL and MySQL, checkout our previous blogs titled “Failover for PostgreSQL Replication 101” and “Automatic failover of MySQL Replication – New in ClusterControl 1.4“.
Conclusion
Automated Failover is a valuable feature, especially for businesses that require 24/7 operations with minimal downtime. The business must define how much control is given up to the automation process during unplanned outages. A high availability solution like ClusterControl offers a customizable level of interaction in failover processing. For some organizations, automated failover may not be an option, even though the user interaction during failover can eat time and impact RTO. The assumption is that it is too risky in case automated failover does not work correctly or, even worse, it results in data being messed up and partially missing (although one might argue that a human can also make disastrous mistakes leading to similar consequences). Those who prefer to keep close control over their database may choose to skip automated failover and use a manual process instead. Such a process takes more time, but it allows an experienced admin to assess the state of a system and take corrective actions based on what happened.



