blog
MySQL Replication Failover – Maxscale vs MHA: Part One

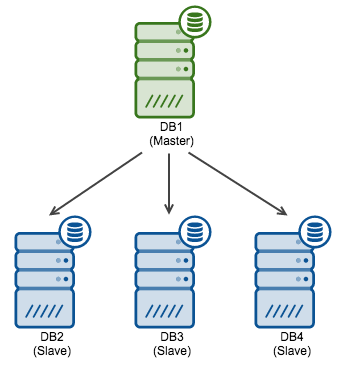
In our MySQL replication tutorial we have covered different aspects of replication including master failover by performing a slave promotion using ClusterControl. The slave promotion will turn a slave into the new master, and re-attach the remaining slaves in the topology under the new master. Keep in mind that ClusterControl will not perform an automated slave promotion in the current version. We do have a helper to find the most advanced slave (Cluster drop down: Find Most Advanced Slave) to determine the best candidate slave.
Another thing to keep in mind is that, as of time of writing, ClusterControl only supports replication topologies using MySQL GTID. You can add your existing MariaDB based replication topology to ClusterControl but promoting slaves can only be performed manually via command line. Supporting MariaDB GTID and automated failover are the top features on our wishlist for ClusterControl 1.3.
In case you do wish to perform slave promotion on MariaDB or wish to add automated failover in your replication topology, there are several options to choose from. At this moment the most commonly used products for automated failover are MySQL Master HA (aka MHA), Percona Replication Manager, but also newer options like Orchestrator and MaxScale + MariaDB Replication Manager have become available lately. In this post, we will focus on MySQL Master HA (MHA) and in our second part we will cover MaxScale + MariaDB Replication Manager.
MySQL Master-HA
MySQL Master-HA (MHA) was created by Yoshinori Matsunobu when he still worked for DeNA. The goal was to have a better and more reliable failover mechanism for MySQL replication with the shortest downtime as possible. MHA has been written in Perl and is not very actively developed anymore, but it is actively maintained. Bugs do get fixed and pull requests on the Github repositories get merged frequently. When MHA was created, it set the bar really high: it supports all replication methods (statement and row based replication) and acts as a binlog server as well to ensure all slaves become equally advanced.
Configuration
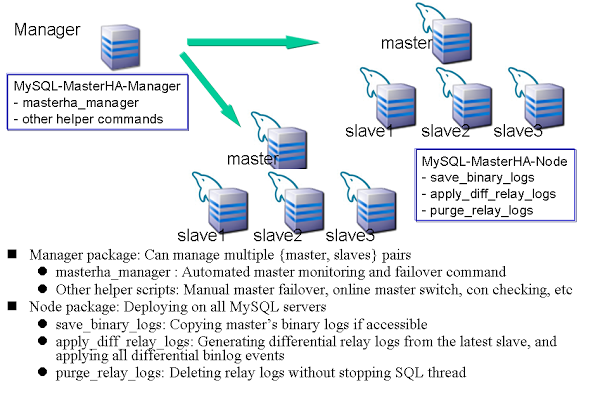
MHA consists out of two components: the MHA Manager and MHA Node. The Manager is the software that manages the failover, takes decisions on when and where to failover to while the Node software is a local agent that will monitor your MySQL instance and allow the Manager to copy relay logs from the slaves.
Configuring the MHA Manager includes creating a list of the MHA nodes and preferably assigning roles to each of these nodes. The roles can be either candidate_master or no_master. Assigning the role candidate_master means this node is considered a safe host to become the new master. Obviously you can have multiple candidate_master nodes defined. Setting the role to no_master will ensure MHA will never promote this host to a master. A good use case for this would be a delayed slave or a slave on lower spec hardware.
Failover procedure
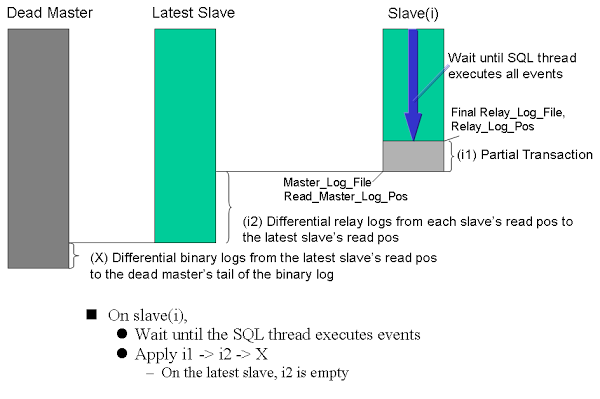
The MHA failover procedure is a quite advanced procedure. The MHA Manager watches over the master and slaves, and continuously keeps track of their status. When one of the slaves fails, it should be excluded from the potential candidate masters set in the configuration. When the master fails you can run a pre-failover script, for instance to remove a virtual ip. Then the most advanced candidate master gets elected and its relay logs will be sent over to the manager. After this the slave will be promoted to master. Then the other hosts will be made equal by applying the retrieved relay logs and apply the delta in parallel to all slaves and attached to the new master. After this MHA will run post-failover scripts, send an email to the sysops and then exit. The exit is a deliberate choice as this prevents data loss and instability due to flapping.
Passwordless SSH
To enable MHA to copy the binary logs, test connectivity and promote a slave, a passwordless SSH user is needed. The MHA Node package also needs to be able to connect via SSH to the other slaves to distribute the binary logs. So all MHA nodes need to be able to connect to each other.
GTID
To ensure all transactions get applied to the new slaves, MHA scans the binlog for every host until the point where it applied the last transaction and then applies the delta. This works with both GTID implementations and masters without GTID as well.
Another option when using GTID is that you can define (external) binlog servers. If a binlog server has been defined and during failover, the binlog server is the most advanced, it will copy the binary logs from there.
Secondary manager node
MHA also supports a secondary Manager node for the failover procedure just in case there is network partitioning and the MHA primary server can’t see the master while the secondary can. In this case there will be no failover as the master is apparently not down. In case the second MHA Manager node cannot be reached, MHA will assume there is a complete network failure and will not failover.
Quick slave promotion
MHA is able to be 100% certain the master is down within 9-12 seconds and then a few seconds to send and apply the relay logs to the new master. This means the total failover time is about 10-30 seconds in total.
Conclusion
MHA has a very advanced replication failover mechanism with a rich feature set to cover a lot of different use cases. It can handle all replication methods with or without GTID and ensure all hosts are equal after performing the failover. The product is relatively mature after five years of existence but at the same time newer hybrid replication topologies arrive, like Galera masters with asynchronous slaves, and the question is whether these will be fully supported in the long run.
In our second part, we will cover the combination of MaxScale + MariaDB Replication Manager to provide automatic failover in MySQL replication.



