blog
Automatic Failover of MySQL Replication – New in ClusterControl 1.4

MySQL replication setups are inevitably related to failovers. Unlike multi-master clusters like Galera, there is one single writer in a whole setup – the master. If the master fails, one of the slaves will have to take its role through the process of failover. Such process is tricky and potentially, it may cause data loss. It may happen, for example, if a slave is not up to date while it is promoted. The master may also die before it is able to transfer all binlog events to at least one of its slaves.
Different people have different takes on how to perform failover. It depends on personal preferences but also on requirements of the business. There are two main options – automated failover or manual failover.
Automated failover comes in very handy if you want your environment to run 24×7, and to recover quickly from any failures. Unfortunately, this may come at a cost – in more complex failure scenarios, automated failover may not work correctly or, even worse, it may result in your data being messed up and partially missing (although one might argue that a human can also make disastrous mistakes leading to similar consequences). Those who prefer to keep close control over their database may choose to skip automated failover and use a manual process instead. Such a process takes more time, but it allows an experienced DBA to assess the state of a system and take corrective actions based on what happened.
ClusterControl already supports automated failover for master-master clusters like Galera and NDB Cluster. Now with 1.4, it also does this for MySQL replication. In this blog post, we’ll take you through the failover process, discussing how ClusterControl does it, and what can be configured by the user.
Configuring Automatic Failover
Failover in ClusterControl can be configured to be automatic or not. If you prefer to take care of failover manually, you can disable automated cluster recovery. By default, cluster recovery is enabled and automated failover is used. Once you make changes in the UI, make sure you also make them in the cmon configuration and set enable_cluster_autorecovery to ‘0’. Otherwise your settings will be overwritten when the cmon process is restarted.

Failover is initiated by ClusterControl when it detects that there is no host with read_only flag disabled. It can happen because master (which has read_only set to 0) is not available or it can be triggered by a user or some external software that changed this flag on the master. If you do manual changes to the database nodes or have software that may fiddle with the read_only settings, then you should disable automatic failover.
Also, note that failover is attempted only once. Should a failover attempt fail, then no more attempts will be made until the controller is restarted.
At the beginning of the failover procedure, ClusterControl builds a list of slaves which can be promoted to master. Most of the time, it will contain all slaves in the topology but the user has some additional control over it. There are two variables you can set in the cmon configuration:
replication_failover_whitelist
and
replication_failover_blacklist
First of them, when used, contains a list of IP’s or hostnames of slaves which should be used as potential master candidates. If this variable is set, only those hosts will be considered.
Second variable may contain list of hosts which will never be considered a master candidate. You can use it to list slaves that are used for backups or analytical queries. If the hardware varies between slaves, you may want to put here the slaves which use slower hardware.
replication_failover_whitelist takes precedence, meaning the replication_failover_blacklist is ignored if replication_failover_whitelist is set.
Once the list of slaves which may be promoted to master is ready, ClusterControl starts to compare their state, looking for the most up to date slave. Here, the handling of MariaDB and MySQL-based setups differs. For MariaDB setups, ClusterControl picks a slave which has the lowest replication lag of all slaves available. For MySQL setups, ClusterControl picks such a slave as well but then it checks for additional, missing transactions which could have been executed on some of the remaining slaves. If such a transaction is found, ClusterControl slaves the master candidate off that host in order to retrieve all missing transactions.
In case you’d like to skip this process and just use the most advanced slave, you can set the following setting in the cmon configuration:
replication_skip_apply_missing_txs=1Such process may result in a serious problem though – if an errant transaction is found, replication may be broken. What is an errant transaction? In short, it is a transaction that has been executed on a slave but it’s not coming from the master. It could have been, for example, executed locally. The problem is caused by the fact that, while using GTID, if a host, which has such errant transaction, becomes a master, all slaves will ask for this missing transaction in order to be in sync with their new master. If the errant transaction happened way in the past, it may not longer be available in binary logs. In that case, replication will break because slaves won’t be able to retrieve the missing data. If you would like to learn more about errant transactions, we have a blog post covering this topic.
Of course, we don’t want to see replication breaking, therefore ClusterControl, by default, checks for any errant transactions before it promotes a master candidate to become a master. If such problem is detected, the master switch is aborted and ClusterControl lets the user fix the problem manually. The blog post we mentioned above explains how you can manually fix issues with errant transactions.
If you want to be 100% certain that ClusterControl will promote a new master even if some issues are detected, you can do that using the replication_stop_on_error=0 setting in cmon configuration. Of course, as we discussed, it may lead to problems with replication – slaves may start asking for a binary log event which is not available anymore. To handle such cases we added experimental support for slave rebuilding. If you set replication_auto_rebuild_slave=1 in the cmon configuration and if your slave is marked as down with the following error in MySQL:
Got fatal error 1236 from master when reading data from binary log: ‘The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.’
ClusterControl will attempt to rebuild the slave using data from the master. Such a setting may not always be appropriate as the rebuilding process will induce an increased load on the master. It may also be that your dataset is very large and a regular rebuild is not an option – that’s why this behavior is disabled by default.
Once we ensure that no errant transactions exist and we are good to go, there is still one more issue we need to handle somehow – it may happen that all slaves are lagging behind the master.
As you probably know, replication in MySQL works in a rather simple way. The master stores writes in binary logs. The slave’s I/O thread connects to the master and pulls any binary log events it is missing. It then stores them in the form of relay logs. The SQL thread parses them and applies events. Slave lag is a condition in which SQL thread (or threads) cannot cope with the number of events, and is unable to apply them as soon as they are pulled from the master by the I/O thread. Such situation may happen no matter what type of replication you are using. Even if you use semi-sync replication, it can only guarantee that all events from the master are stored on one of slaves in the relay log. It doesn’t say anything about applying those events to a slave.
The problem here is that, if a slave is promoted to master, relay logs will be wiped out. If a slave is lagging and hasn’t applied all transactions, it will lose data – events that are not yet applied from relay logs will be lost forever.
There is no one-size-fits-all way of solving this situation. ClusterControl gives users control over how it should be done, maintaining safe defaults. It is done in cmon configuration using the following setting:
replication_failover_wait_to_apply_timeout
By default it takes a value of ‘-1’, which means that failover won’t happen if a master candidate is lagging. ClusterControl will wait indefinitely for it to apply all missing transactions from its relay logs. This is safe, but, if for some reason, the most up-to-date slave is lagging badly, failover may takes hours to complete. On the other side of the spectrum is setting it to ‘0’ – it means that failover happens immediately, no matter if the master candidate is lagging or not. You can also go the middle way and set it to some value. This will set a time in seconds, during which ClusterControl will wait for a master candidate to apply missing transactions from its relay logs. Failover happens after the defined time or when the master candidate will catch up on replication – whichever happens first. This may be a good choice if your application has specific requirements regarding downtime and you have to elect a new master within a short time window.
When using MySQL replication along with proxies like ProxySQL, ClusterControl can help you build an environment in which the failover process is barely noticeable by the application. Below we’ll show how the failover process may look like in a typical replication setup – one master with two slaves. We will use ProxySQL to detect topology changes and route traffic to the correct hosts.
First, we’ll start our “application” – sysbench:
root@ip-172-30-4-48:~# while true ; do sysbench --test=/root/sysbench/sysbench/tests/db/oltp.lua --num-threads=2 --max-requests=0 --max-time=0 --mysql-host=172.30.4.48 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=6033 --oltp-tables-count=32 --report-interval=1 --oltp-skip-trx=on --oltp-table-size=100000 run ; doneIt will connect to ProxySQL (port 6033) and use it to distribute traffic between master and slaves. We simulate default behavior of autocommit=1 in MySQL by disabling transactions for Sysbench.
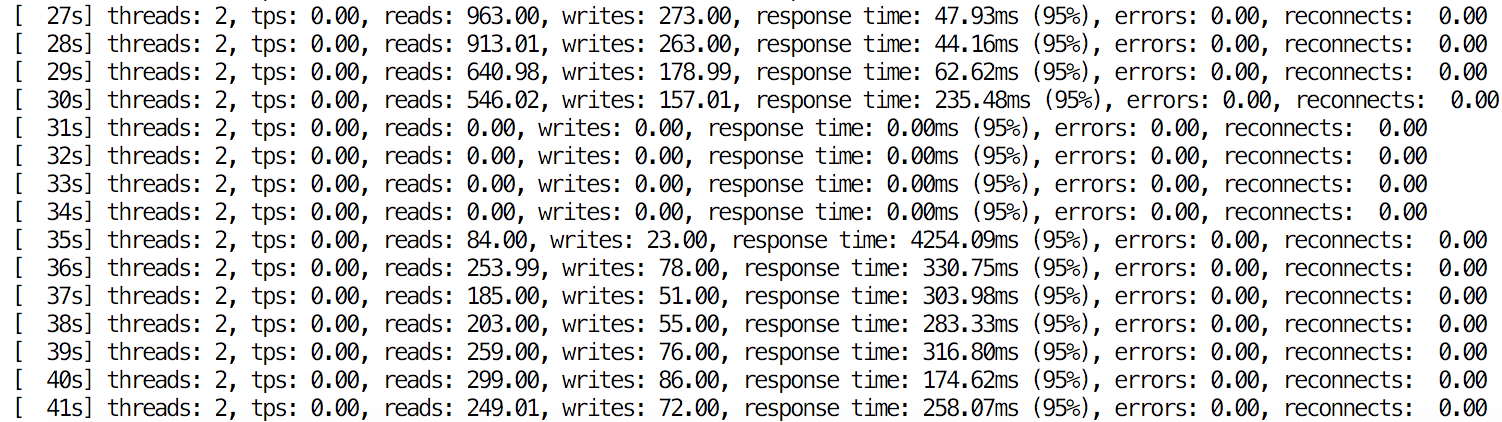
Once we induce some lag, we kill our master:
root@ip-172-30-4-112:~# killall -9 mysqld mysqld_safeClusterControl starts failover.
ID:79574 [13:18:34]: Failover to a new Master.At first, it verifies state of replication on all nodes in the cluster. Among other things, ClusterControl looks for the most up to date slave in the topology and picks it as master candidate.
ID:79575 [13:18:34]: Checking 172.30.4.99:3306
ID:79576 [13:18:34]: ioerrno=2003 io running 0 on 172.30.4.99:3306
ID:79577 [13:18:34]: Checking 172.30.4.4:3306
ID:79578 [13:18:34]: ioerrno=2003 io running 0 on 172.30.4.4:3306
ID:79579 [13:18:34]: Checking 172.30.4.112:3306
ID:79580 [13:18:34]: 172.30.4.112:3306: is not connected. Checking if this is the failed master.
ID:79581 [13:18:34]: 172.30.4.99:3306: Checking if slave can be used as a candidate.
ID:79582 [13:18:34]: Adding 172.30.4.99:3306 to slave list
ID:79583 [13:18:34]: 172.30.4.4:3306: Checking if slave can be used as a candidate.
ID:79584 [13:18:34]: Adding 172.30.4.4:3306 to slave list
ID:79585 [13:18:34]: 172.30.4.4:3306: Slave lag is 4 seconds.
ID:79586 [13:18:34]: 172.30.4.99:3306: Slave lag is 20 seconds >= 4 seconds, not a possible candidate.
ID:79587 [13:18:34]: 172.30.4.4:3306 elected as the new Master.As a next step, required grants are added.
ID:79588 [13:18:34]: 172.30.4.4:3306: Creating user 'rpl_user'@'172.30.4.99.
ID:79589 [13:18:34]: 172.30.4.4:3306: Granting REPLICATION SLAVE 'rpl_user'@'172.30.4.99'.
ID:79590 [13:18:34]: 172.30.4.99:3306: Creating user 'rpl_user'@'172.30.4.4.
ID:79591 [13:18:34]: 172.30.4.99:3306: Granting REPLICATION SLAVE 'rpl_user'@'172.30.4.4'.
ID:79592 [13:18:34]: 172.30.4.99:3306: Setting read_only=ON
ID:79593 [13:18:34]: 172.30.4.4:3306: Setting read_only=ONThen, it’s time to ensure no errant transactions are found, which could prevent the whole failover process from happening.
ID:79594 [13:18:34]: Checking for errant transactions.
ID:79595 [13:18:34]: 172.30.4.99:3306: Skipping, same as slave 172.30.4.99:3306
ID:79596 [13:18:34]: 172.30.4.99:3306: Comparing to 172.30.4.4:3306, master_uuid = 'e4864640-baff-11e6-8eae-1212bbde1380'
ID:79597 [13:18:34]: 172.30.4.4:3306: Checking for errant transactions.
ID:79598 [13:18:34]: 172.30.4.112:3306: Skipping, same as master 172.30.4.112:3306
ID:79599 [13:18:35]: 172.30.4.4:3306: Comparing to 172.30.4.99:3306, master_uuid = 'e4864640-baff-11e6-8eae-1212bbde1380'
ID:79600 [13:18:35]: 172.30.4.99:3306: Checking for errant transactions.
ID:79601 [13:18:35]: 172.30.4.4:3306: Skipping, same as slave 172.30.4.4:3306
ID:79602 [13:18:35]: 172.30.4.112:3306: Skipping, same as master 172.30.4.112:3306
ID:79603 [13:18:35]: No errant transactions found.During the last preparation step, missing transactions are being applied on the master candidate – we want it to fully catch up on the replication before we proceed with failover. In our case, to ensure that failover will happen even if slave is badly lagging, we enforced 600 second limit – slave will try to replay any missing transactions from its relay logs but if it will take more than 600 seconds, we will force a failover.
ID:79604 [13:18:35]: 172.30.4.4:3306: preparing candidate.
ID:79605 [13:18:35]: 172.30.4.4:3306: Checking if there the candidate has relay log to apply.
ID:79606 [13:18:35]: 172.30.4.4:3306: waiting up to 600 seconds before timing out.
ID:79608 [13:18:37]: 172.30.4.4:3306: Applied 391 transactions
ID:79609 [13:18:37]: 172.30.4.4:3306: Executing 'SELECT WAIT_UNTIL_SQL_THREAD_AFTER_GTIDS('e4864640-baff-11e6-8eae-1212bbde1380:16340-23420', 5)' (waited 5 out of maximally 600 seconds).
ID:79610 [13:18:37]: 172.30.4.4:3306: Applied 0 transactions
ID:79611 [13:18:37]: 172.30.4.99:3306: No missing transactions found.
ID:79612 [13:18:37]: 172.30.4.4:3306: Up to date with temporary master 172.30.4.99:3306
ID:79613 [13:18:37]: 172.30.4.4:3306: Completed preparations of candidate.Finally, failover happens. From the application’s standpoint, the impact was minimal – the process took less than 5 seconds, during which the application had to wait for queries to execute. Of course, it depends on multiple factors – the main one is replication lag as the failover process, by default, requires the slave to be up-to-date. Catching up can take quite some time if the slave is lagging behind heavily.
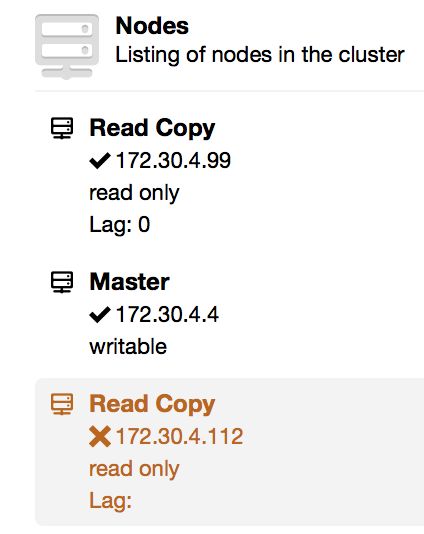
At the end, we have a new replication topology. A new master has been elected and the second slave has been reslaved. The old master, on the other hand, is stopped. This is intentional as we want the user to be able to investigate the state of the old master before performing any further changes (e.g., slaving it off a new master or rebuilding it).
We hope this mechanism will be useful in maintaining high availability of replication setups. If you have any feedback on it, let us know as we’d love to hear from you.



