blog
HA for MySQL and MariaDB – Comparing Master-Master Replication to Galera Cluster

Galera replication is relatively new if compared to MySQL replication, which is natively supported since MySQL v3.23. Although MySQL replication is designed for master-slave unidirectional replication, it can be configured as an active master-master setup with bidirectional replication. While it is easy to set up, and some use cases might benefit from this “hack”, there are a number of caveats. On the other hand, Galera cluster is a different type of technology to learn and manage. Is it worth it?
In this blog post, we are going to compare master-master replication to Galera cluster.
Replication Concepts
Before we jump into the comparison, let’s explain the basic concepts behind these two replication mechanisms.
Generally, any modification to the MySQL database generates an event in binary format. This event is transported to the other nodes depending on the replication method chosen – MySQL replication (native) or Galera replication (patched with wsrep API).
MySQL Replication
The following diagrams illustrates the data flow of a successful transaction from one node to another when using MySQL replication:
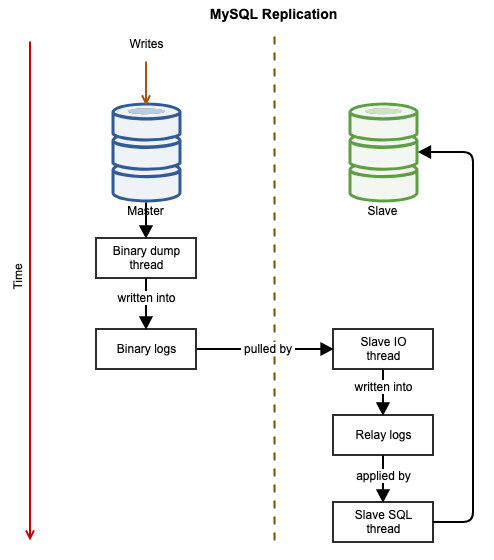
The binary event is written into the master’s binary log. The slave(s) via slave_IO_thread will pull the binary events from master’s binary log and replicate them into its relay log. The slave_SQL_thread will then apply the event from the relay log asynchronously. Due to the asynchronous nature of replication, the slave server is not guaranteed to have the data when the master performs the change.
Ideally, MySQL replication will have the slave to be configured as a read-only server by setting read_only=ON or super_read_only=ON. This is a precaution to protect the slave from accidental writes which can lead to data inconsistency or failure during master failover (e.g., errant transactions). However, in a master-master active-active replication setup, read-only has to be disabled on the other master to allow writes to be processed simultaneously. The primary master must be configured to replicate from the secondary master by using the CHANGE MASTER statement to enable circular replication.
Galera Replication
The following diagrams illustrates the data replication flow of a successful transaction from one node to another for Galera Cluster:
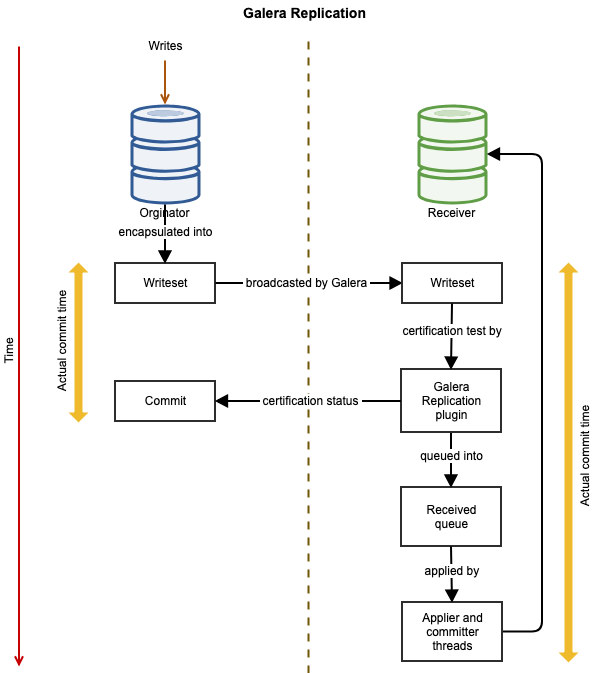
The event is encapsulated in a writeset and broadcasted from the originator node to the other nodes in the cluster by using Galera replication. The writeset undergoes certification on every Galera node and if it passes, the applier threads will apply the writeset asynchronously. This means that the slave server will eventually become consistent, after agreement of all participating nodes in global total ordering. It is logically synchronous, but the actual writing and committing to the tablespace happens independently, and thus asynchronously on each node with a guarantee for the change to propagate on all nodes.
Avoiding Primary Key Collision
In order to deploy MySQL replication in master-master setup, one has to adjust the auto increment value to avoid primary key collision for INSERT between two or more replicating masters. This allows the primary key value on masters to interleave each other and prevent the same auto increment number being used twice on either of the node. This behaviour must be configured manually, depending on the number of masters in the replication setup. The value of auto_increment_increment equals to the number of replicating masters and the auto_increment_offset must be unique between them. For example, the following lines should exist inside the corresponding my.cnf:
Master1:
log-slave-updates
auto_increment_increment=2
auto_increment_offset=1Master2:
log-slave-updates
auto_increment_increment=2
auto_increment_offset=2Likewise, Galera Cluster uses this same trick to avoid primary key collisions by controlling the auto increment value and offset automatically with wsrep_auto_increment_control variable. If set to 1 (the default), will automatically adjust the auto_increment_increment and auto_increment_offset variables according to the size of the cluster, and when the cluster size changes. This avoids replication conflicts due to auto_increment. In a master-slave environment, this variable can be set to OFF.
The consequence of this configuration is the auto increment value will not be in sequential order, as shown in the following table of a three-node Galera Cluster:
| Node | auto_increment_increment | auto_increment_offset | Auto increment value |
|---|---|---|---|
| Node 1 | 3 | 1 | 1, 4, 7, 10, 13, 16… |
| Node 2 | 3 | 2 | 2, 5, 8, 11, 14, 17… |
| Node 3 | 3 | 3 | 3, 6, 9, 12, 15, 18… |
If an application performs insert operations on the following nodes in the following order:
- Node1, Node3, Node2, Node3, Node3, Node1, Node3 ..
Then the primary key value that will be stored in the table will be:
- 1, 6, 8, 9, 12, 13, 15 ..
Simply said, when using master-master replication (MySQL replication or Galera), your application must be able to tolerate non-sequential auto-increment values in its dataset.
For ClusterControl users, take note that it supports deployment of MySQL master-master replication with a limit of two masters per replication cluster, only for active-passive setup. Therefore, ClusterControl does not deliberately configure the masters with auto_increment_increment and auto_increment_offset variables.
Data Consistency
Galera Cluster comes with its flow-control mechanism, where each node in the cluster must keep up when replicating, or otherwise all other nodes will have to slow down to allow the slowest node to catch up. This basically minimizes the probability of slave lag, although it might still happen but not as significant as in MySQL replication. By default, Galera allows nodes to be at least 16 transactions behind in applying through variable gcs.fc_limit. If you want to do critical reads (a SELECT that must return most up to date information), you probably want to use session variable, wsrep_sync_wait.
Galera Cluster on the other hand comes with a safeguard to data inconsistency whereby a node will get evicted from the cluster if it fails to apply any writeset for whatever reasons. For example, when a Galera node fails to apply writeset due to internal error by the underlying storage engine (MySQL/MariaDB), the node will pull itself out from the cluster with the following error:
150305 16:13:14 [ERROR] WSREP: Failed to apply trx 1 4 times
150305 16:13:14 [ERROR] WSREP: Node consistency compromized, aborting..To fix the data consistency, the offending node has to be re-synced before it is allowed to join the cluster. This can be done manually or by wiping out the data directory to trigger snapshot state transfer (full syncing from a donor).
MySQL master-master replication does not enforce data consistency protection and a slave is allowed to diverge e.g, replicate a subset of data or lag behind, which makes the slave inconsistent with the master. It is designed to replicate data in one flow – from master down to the slaves. Data consistency checks have to be performed manually or via external tools like Percona Toolkit pt-table-checksum or mysql-replication-check.
Conflict Resolution
Generally, master-master (or multi-master, or bi-directional) replication allows more than one member in the cluster to process writes. With MySQL replication, in case of replication conflict, the slave’s SQL thread simply stops applying the next query until the conflict is resolved, either by manually skipping the replication event, fixing the offending rows or resyncing the slave. Simply said, there is no automatic conflict resolution support for MySQL replication.
Galera Cluster provides a better alternative by retrying the offending transaction during replication. By using wsrep_retry_autocommit variable, one can instruct Galera to automatically retry a failed transaction due to cluster-wide conflicts, before returning an error to the client. If set to 0, no retries will be attempted, while a value of 1 (the default) or more specifies the number of retries attempted. This can be useful to assist applications using autocommit to avoid deadlocks.
Node Consensus and Failover
Galera uses Group Communication System (GCS) to check node consensus and availability between cluster members. If a node is unhealthy, it will be automatically evicted from the cluster after gmcast.peer_timeout value, default to 3 seconds. A healthy Galera node in “Synced” state is deemed as a reliable node to serve reads and writes, while others are not. This design greatly simplifies health check procedures from the upper tiers (load balancer or application).
In MySQL replication, a master does not care about its slave(s), while a slave only has consensus with its sole master via the slave_IO_thread process when replicating the binary events from master’s binary log. If a master goes down, this will break the replication and an attempt to re-establish the link will be made every slave_net_timeout (default to 60 seconds). From the application or load balancer perspective, the health check procedures for replication slave must at least involve checking the following state:
- Seconds_Behind_Master
- Slave_IO_Running
- Slave_SQL_Running
- read_only variable
- super_read_only variable (MySQL 5.7.8 and later)
In terms of failover, generally, master-master replication and Galera nodes are equal. They hold the same data set (albeit you can replicate a subset of data in MySQL replication, but that’s uncommon for master-master) and share the same role as masters, capable of handling reads and writes simultaneously. Therefore, there is actually no failover from the database point-of-view due to this equilibrium. Only from the application side that would require failover to skip the unoperational nodes. Keep in mind that because MySQL replication is asynchronous, it is possible that not all of the changes done on the master will have propagated to the other master.
Node Provisioning
The process of bringing a node into sync with the cluster before replication starts, is known as provisioning. In MySQL replication, provisioning a new node is a manual process. One has to take a backup of the master and restore it over to the new node before setting up the replication link. For an existing replication node, if the master’s binary logs have been rotated (based on expire_logs_days, default to 0 means no automatic removal), you may have to re-provision the node using this procedure. There are also external tools like Percona Toolkit pt-table-sync and ClusterControl to help you out on this. ClusterControl supports resyncing a slave with just two clicks. You have options to resync by taking a backup from the active master or an existing backup.
In Galera, there are two ways of doing this – incremental state transfer (IST) or state snapshot transfer (SST). IST process is the preferred method where only the missing transactions transfer from a donor’s cache. SST process is similar to taking a full backup from the donor, it is usually pretty resource intensive. Galera will automatically determine which syncing process to trigger based on the joiner’s state. In most cases, if a node fails to join a cluster, simply wipe out the MySQL datadir of the problematic node and start the MySQL service. Galera provisioning process is much simpler, it comes very handy when scaling out your cluster or re-introducing a problematic node back into the cluster.
Loosely Coupled vs Tightly Coupled
MySQL replication works very well even across slower connections, and with connections that are not continuous. It can also be used across different hardware, environment and operating systems. Most storage engines support it, including MyISAM, Aria, MEMORY and ARCHIVE. This loosely coupled setup allows MySQL master-master replication to work well in a mixed environment with less restriction.
Galera nodes are tightly-coupled, where the replication performance is as fast as the slowest node. Galera uses a flow control mechanism to control replication flow among members and eliminate any slave lag. The replication can be all fast or all slow on every node and is adjusted automatically by Galera. Thus, it’s recommended to use uniform hardware specs for all Galera nodes, especially with respect to CPU, RAM, disk subsystem, network interface card and network latency between nodes in the cluster.
Conclusions
In summary, Galera Cluster is superior if compared to MySQL master-master replication due to its synchronous replication support with strong consistency, plus more advanced features like automatic membership control, automatic node provisioning and multi-threaded slaves. Ultimately, this depends on how the application interacts with the database server. Some legacy applications built for a standalone database server may not work well on a clustered setup.
To simplify our points above, the following reasons justify when to use MySQL master-master replication:
- Things that are not supported by Galera:
- Replication for non-InnoDB/XtraDB tables like MyISAM, Aria, MEMORY or ARCHIVE.
- XA transactions.
- Statement-based replication between masters (e.g, when bandwidth is very expensive).
- Relying on explicit locking like LOCK TABLES statement.
- The general query log and the slow query log must be directed to a table, instead of a file.
- Loosely coupled setup where the hardware specs, software version and connection speed are significantly different on every master.
- When you already have a MySQL replication chain and you want to add another active/backup master for redundancy to speed up failover and recovery time in case if one of the master is unavailable.
- If your application can’t be modified to work around Galera Cluster limitations and having a MySQL-aware load balancer like ProxySQL or MaxScale is not an option.
Reasons to pick Galera Cluster over MySQL master-master replication:
- Ability to safely write to multiple masters.
- Data consistency automatically managed (and guaranteed) across databases.
- New database nodes easily introduced and synced.
- Failures or inconsistencies automatically detected.
- In general, more advanced and robust high availability features.



