blog
Eliminating PostgreSQL Split-Brain in Multi-Cloud Databases

Using a multi-cloud or multi-datacenter environment is useful for geo-distributed topologies or even for a disaster recovery plan, and actually, it is becoming more popular nowadays, therefore the concept of split-brain is also becoming more important as the risk of having it increase in this kind of scenario. You must prevent a split-brain to avoid potential data loss or data inconsistency, which could be a big problem for the business.
In this blog, we will see what a split-brain is, and how ClusterControl can help you to avoid this important issue.
What is Split-Brain?
In the PostgreSQL world, split-brain occurs when more than one primary node is available at the same time (without any third-party tool to have a multi-master environment) that allows the application to write in both nodes. In this case, you’ll have different information on each node, which generates data inconsistency in the cluster. Fixing this issue could be hard as you must merge data, something that sometimes is not possible.
PostgreSQL Split-Brain in a Multi-Cloud Topology
Let’s suppose you have the following multi-cloud topology for PostgreSQL (which is a pretty common topology nowadays):
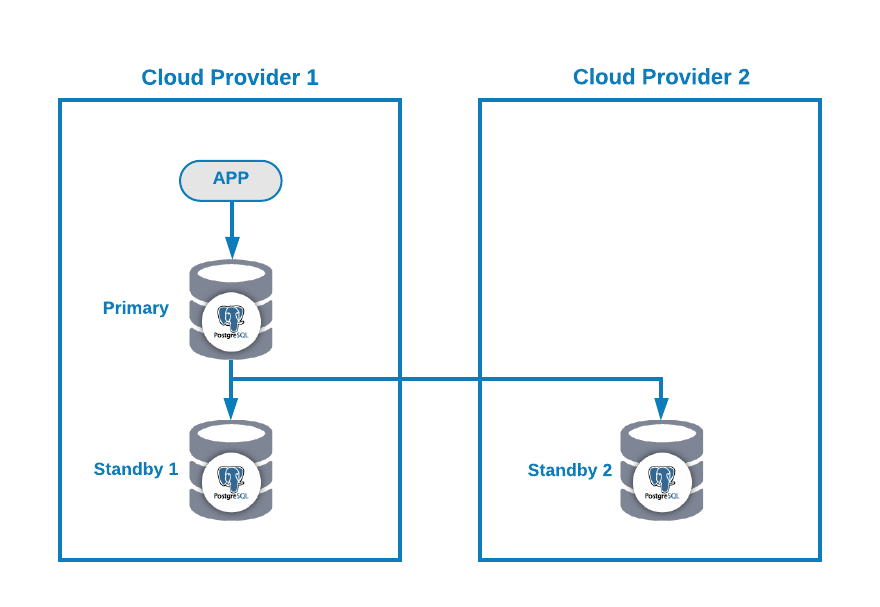
Of course, you can improve this environment by, for example, adding an Application Server in the Cloud Provider 2, but in this case, let’s use this basic configuration.
If your primary node is down, one of the standby nodes should be promoted as a new primary and you should change the IP address in your application to use this new primary node.
There are different ways to make this in an automatic way. For example, you can use a virtual IP address assigned to your primary node and monitor it. If it fails, promote one of the standby nodes and migrate the virtual IP address to this new primary node, so you don’t need to change anything in your application, and this can be made using your own script or tool.
At the moment, you don’t have any issue, but… if your old primary node comes back, you must make sure you won’t have two primary nodes in the same cluster at the same time.
The most common methods to avoid this situation are:
- STONITH: Shoot The Other Node In The Head.
- SMITH: Shoot Myself In The Head.
PostgreSQL doesn’t provide any way to automate this process. You must make it on your own.
How to Avoid Split-Brain in PostgreSQL with ClusterControl
Now, let’s see how ClusterControl can help you with this task.
First, you can use it to deploy or import your PostgreSQL Multi-Cloud environment in an easy way as you can see in this blog post.
Then, you can improve your topology by adding a Load Balancer (HAProxy), which you can also do using ClusterControl following this blog. So, you will have something like this:
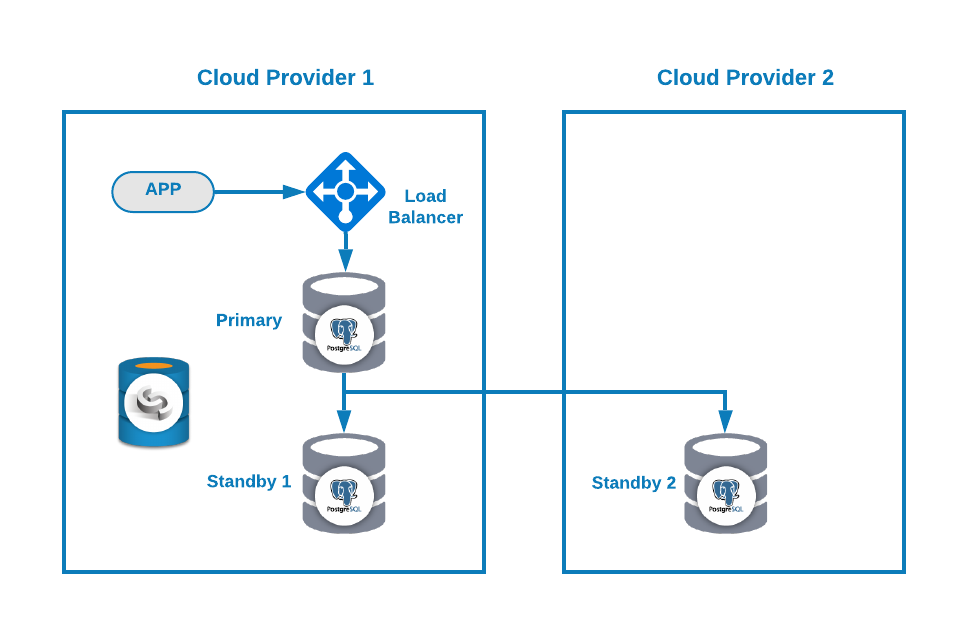
ClusterControl has an auto-failover feature that detects master failures and promotes a standby node with the most current data as a new primary. It also fails over the rest of the standby nodes to replicate from the new primary node.
HAProxy is configured by ClusterControl with two different ports by default, one read-write and one read-only. In the read-write port, you have your primary node as online and the rest of your nodes as offline, and in the read-only port, you have both the primary and the standby nodes online. In this way, you can balance the reading traffic between your nodes but you make sure that at the time of writing, the read-write port will be used, writing in the primary node that is the server that is online.
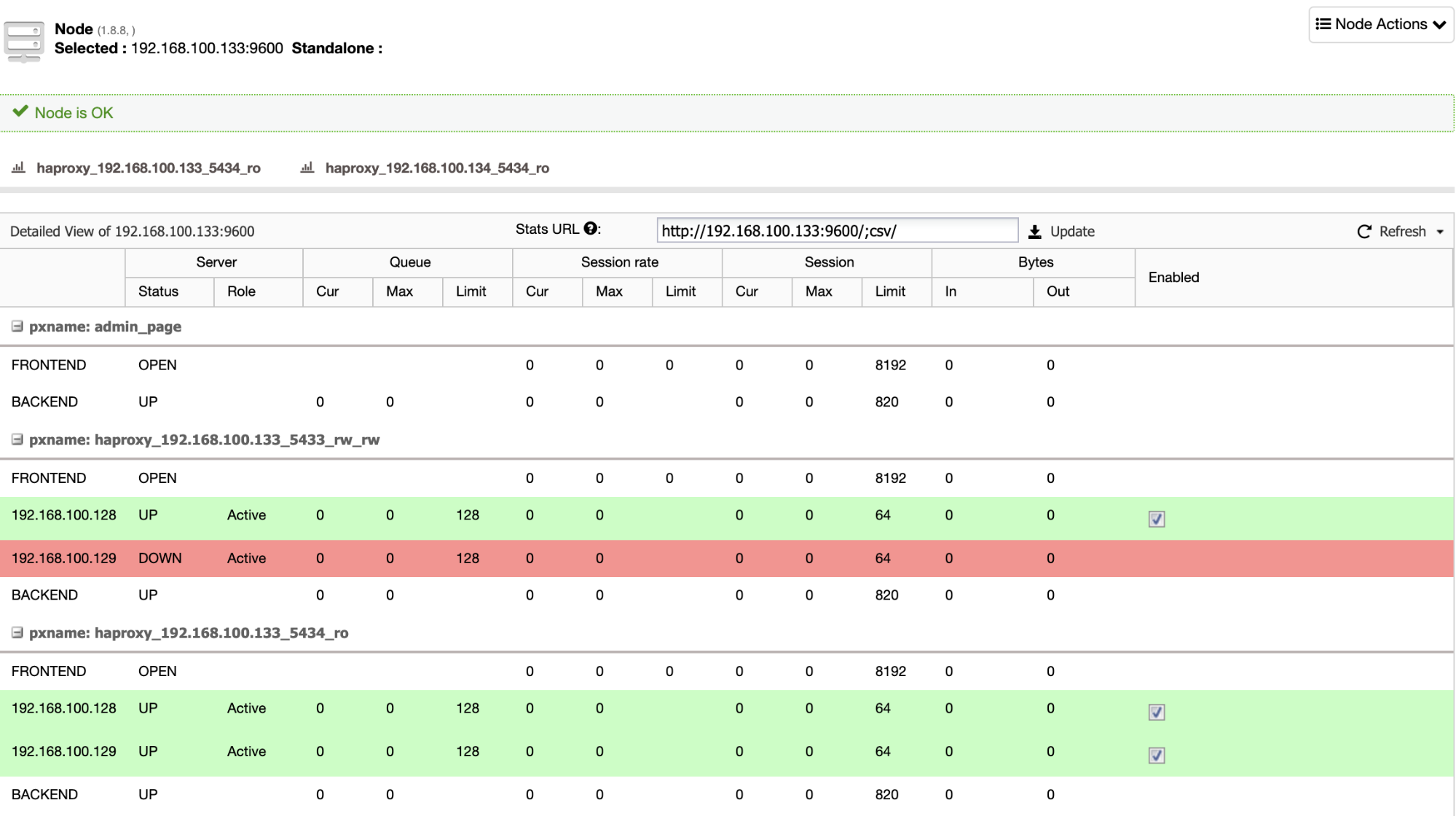
When HAProxy detects that one of your nodes, either primary or standby, is not accessible, it automatically marks it as offline and does not take it into account for sending traffic to it. This check is done by health check scripts that are configured by ClusterControl at the time of deployment. These check whether the instances are up, whether they are undergoing recovery, or are read-only.
If your old primary node comes back, ClusterControl will also avoid starting it, to prevent a potential split-brain in case you have a direct connection that is not using the Load Balancer, but you can add it to the cluster as a standby node in an automatic or manual way using the ClusterControl UI or CLI, then you can promote it to have the same topology that you had running before the issue.
Conclusion
Having the “Autorecovery” option ON, ClusterControl will perform this automatic failover as well as notify you of the problem. In this way, your systems can recover in seconds without your intervention and you will avoid a split-brain in a PostgreSQL Multi-Cloud environment.
You can also improve your High Availability environment by adding more ClusterControl nodes using the CMON HA feature described in this blog.



