blog
Eliminating MySQL Split-Brain in Multi-Cloud Databases

These days databases spanning across multiple clouds are quite common. They promise high availability and possibility to easily implement disaster recovery procedures. They are also a method to avoid vendor lock-in: if you design your database environment so it can operate across multiple cloud providers, most likely you are not tied to features and implementations specific to one particular provider. This makes it easier for you to add another infrastructure provider to your environment, be it another cloud or on-prem setup. Such flexibility is very important given there is fierce competition between cloud providers and migrating from one to another might be quite feasible if it would be backed by reducing expenses.
Spanning your infrastructure across multiple datacenters (from the same provider or not, it doesn’t really matter) brings serious issues to solve. How can one design the entire infrastructure in a way that the data will be safe? How to deal with challenges that you have to face while working in a multi-cloud environment? In this blog we will take a look at one, but arguably the most serious one – potential of a split-brain. What does it mean? Let’s dig a bit into what split-brain is.
What is “Split-Brain”?
Split-brain is a condition in which an environment that consists of multiple nodes suffers network partitioning and has been split into multiple segments that do not have contact with each other. The simplest case will look like this:
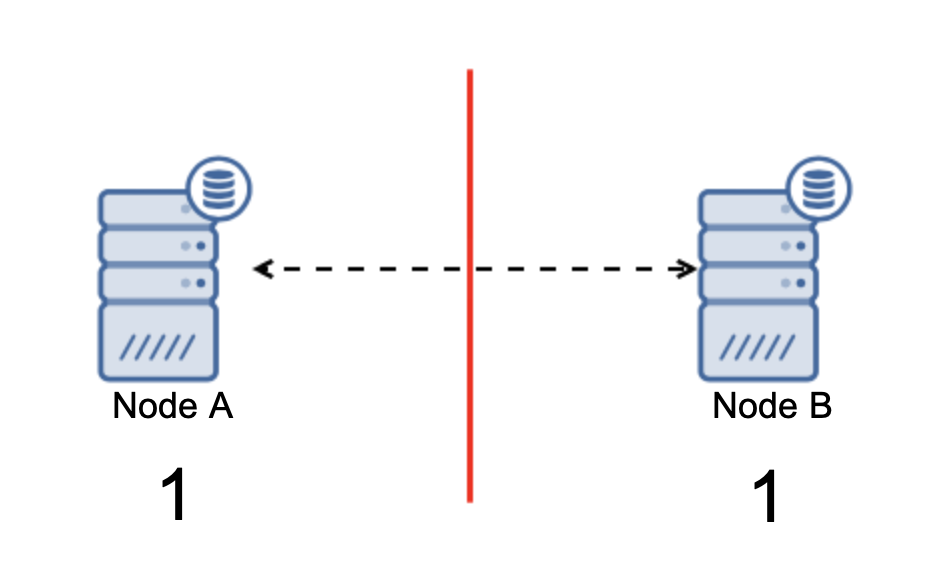
We have two nodes, A and B, connected over a network using bi-directional asynchronous replication. Then the network connection is cut between those nodes. As a result, both nodes cannot connect to each other and any changes executed on node A can’t be transmitted to node B and vice versa. Both nodes, A and B, are up and accepting connections, they just cannot exchange data. This may lead to serious issues as the application may make changes on both nodes expecting to see the full state of the database while, in fact, it operates only on a partially known data state. As a result, incorrect actions may be taken by the application, incorrect results may be presented to the user and so on. We think it’s clear that split-brain is potentially a very dangerous condition and one of the priorities would be to deal with it to some extent. What can be done about it?
How to Avoid Split-Brain
In short, it depends. The main issue to deal with is the fact that nodes are up and running but do not have connectivity between them therefore they are unaware of the state of the other node. In general, MySQL asynchronous replication does not have any sort of mechanism that would internally solve the problem of the split-brain. You can try to implement some solutions that help you to avoid split-brain but they come with limitations or they still do not fully solve the problem.
When we venture away from the asynchronous replication, things are looking differently. MySQL Group Replication and MySQL Galera Cluster are technologies that benefit from build-it cluster awareness. Both those solutions maintain the communication across nodes and ensure that the cluster is aware of the state of the nodes. They implement a quorum mechanism that governs if clusters can be operational or not.
Let’s discuss those two solutions (asynchronous replication and quorum-based clusters) in more detail.
Quorum-based Clustering
We are not going into discussing the implementation differences between MySQL Galera Cluster and MySQL Group Replication, we will focus on the basic idea behind the quorum-based approach and how it is designed to solve the problem of the split-brain in your cluster.
The bottom line is that: cluster, to operate, requires the majority of its nodes to be available. With this requirement we can be sure that the minority can never really affect the rest of the cluster because the minority should not be able to perform any actions. This also means that, in order to be able to handle a failure of one node, a cluster should have at least three nodes. If you have two nodes only:
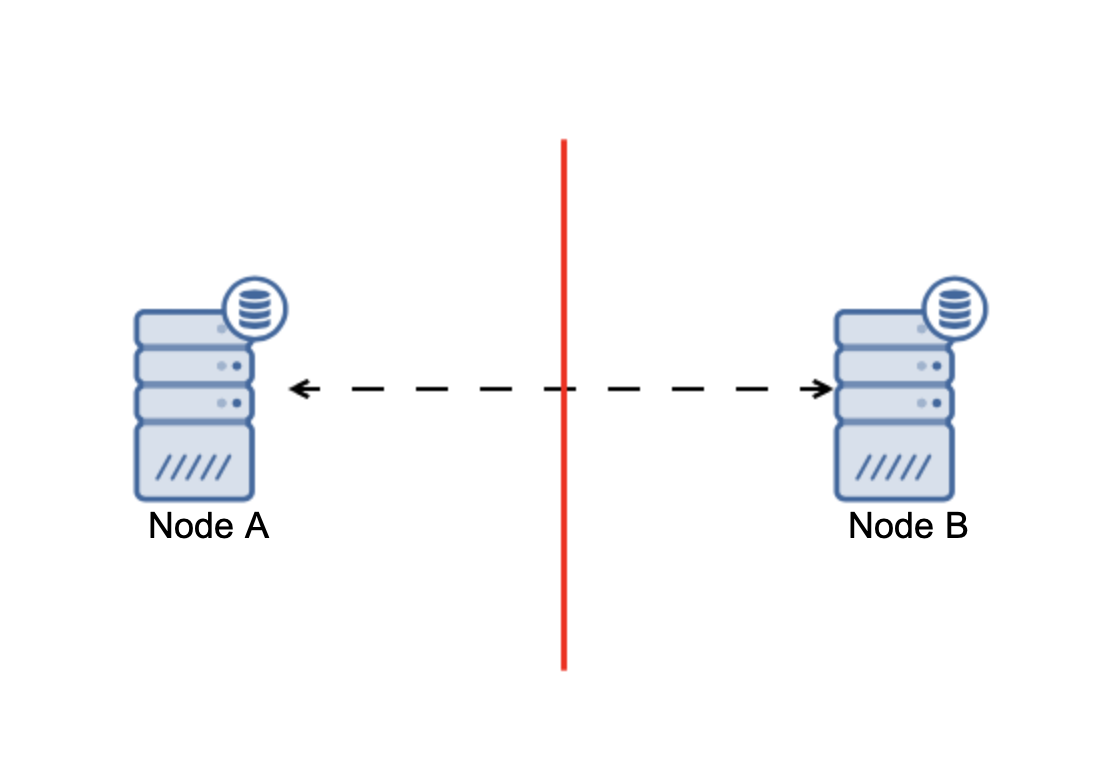
When there is a network split, you end up with two parts of the cluster, each consisting of exactly 50% of the total nodes in the cluster. Neither of these parts has a majority. If you have three nodes, though, things are different:
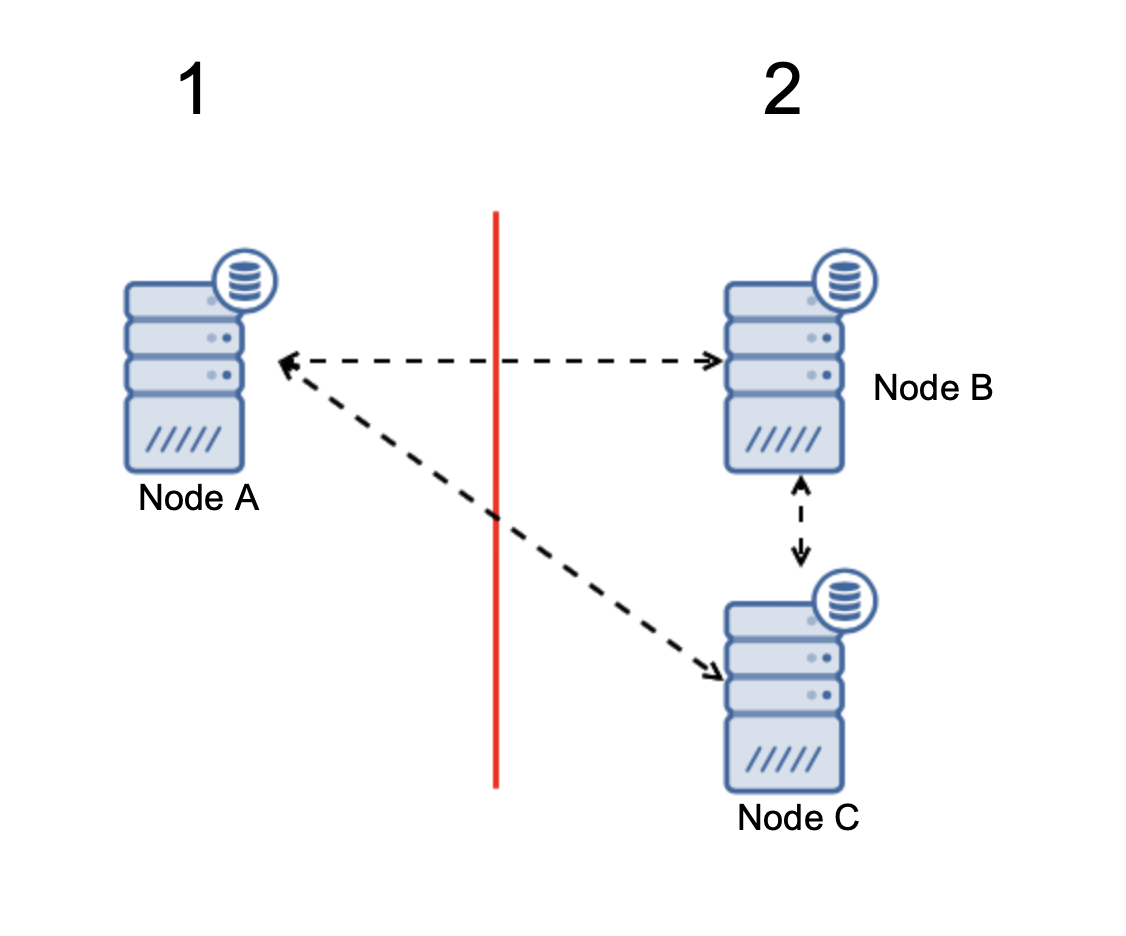
Nodes B and C have the majority: that part consists of two nodes out of three thus it can continue to operate. On the other hand, node A represents only the 33% of the nodes in the cluster thus it does not have a majority and it will cease to handle traffic to avoid the split brain.
With such implementation, split-brain is very unlikely to happen (it would have to be introduced through some weird and unexpected network states, race conditions or plainly bugs in the clustering code. While not impossible to encounter such conditions, using one of the solutions that are quorum-based is the best option to avoid the split-brain that exists at this moment.
Asynchronous Replication
While not the ideal choice when it comes to dealing with split-brain, asynchronous replication is still a viable option. There are several things you should consider before implementing a multi-cloud database with asynchronous replication.
First, failover. Asynchronous replication comes with one writer – only master should be writable and other nodes should only serve read-only traffic. The challenge is how to deal with the master failure?
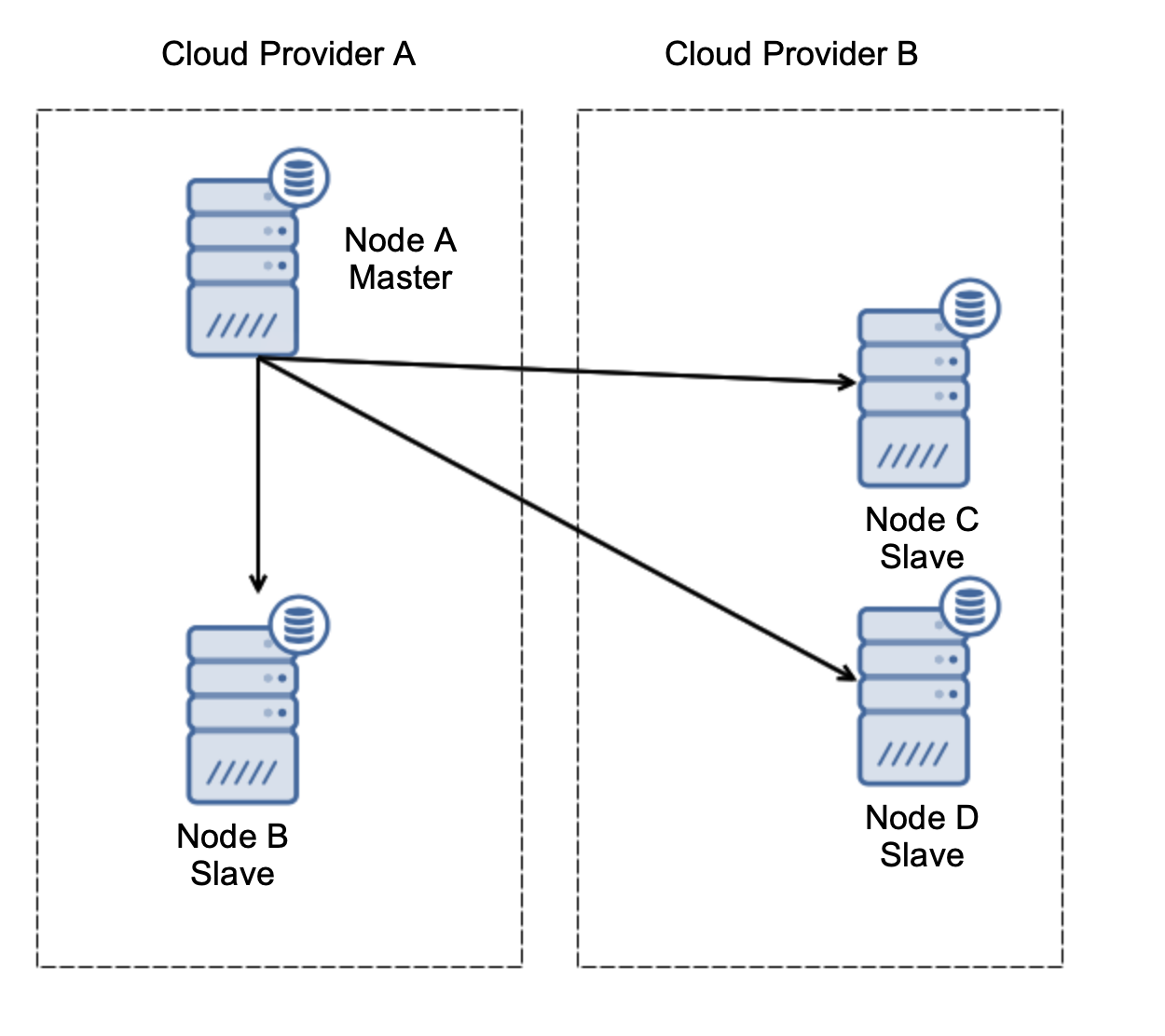
Let’s consider setup as on the diagram above. We have two cloud providers, two nodes in each. Provider A hosts also the master. What should happen if the master fails? One of the slaves should be promoted to ensure that database will continue to be operational. Ideally, it should be an automated process to reduce the time needed to bring the database to the operational state. What would happen, though, if there would be a network partitioning? How are we expected to verify the state of the cluster?
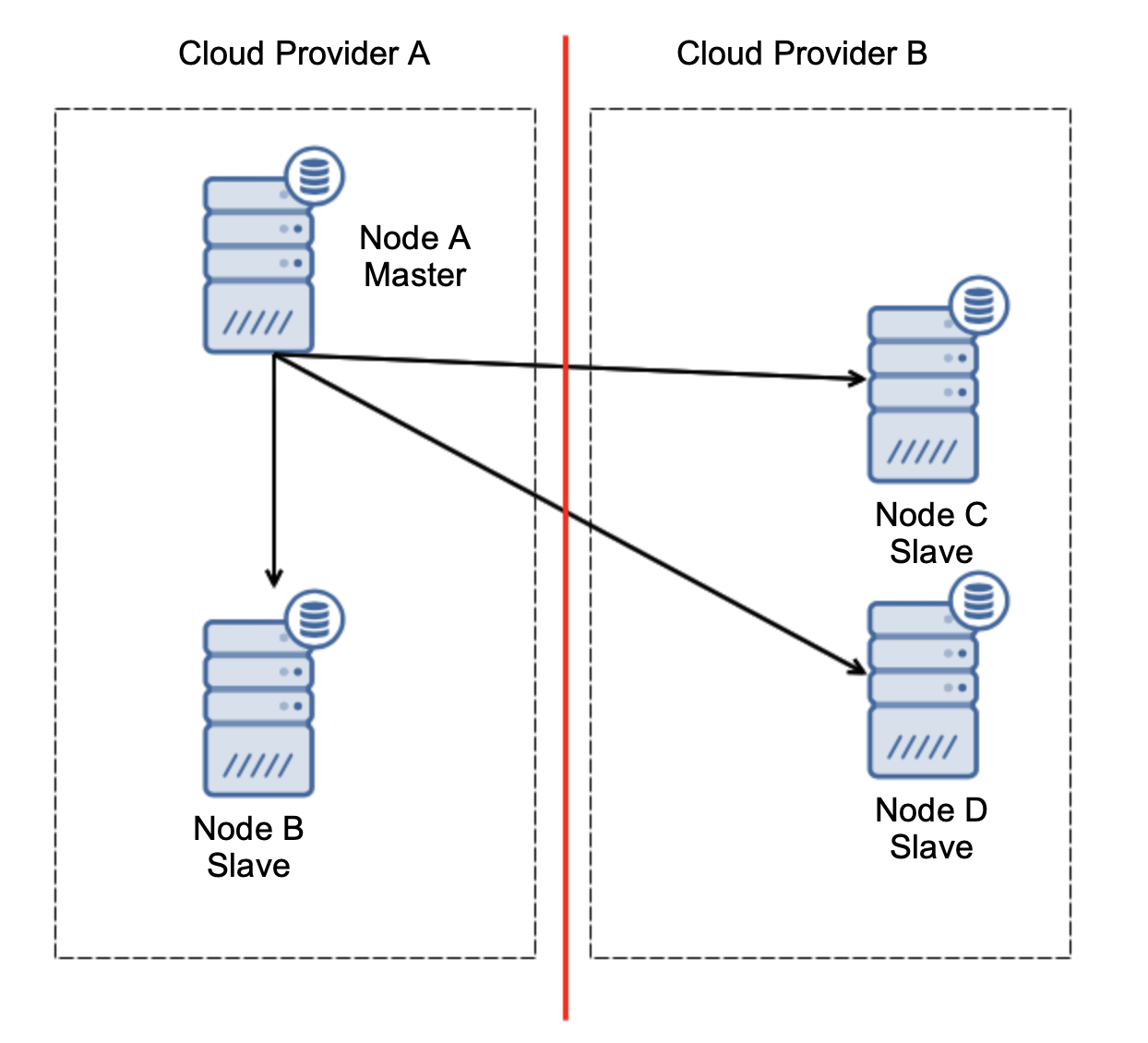
Here’s the challenge. Network connectivity is lost between two cloud providers. From the standpoint of the nodes C and D both node B and master, node A are offline. Should node C or D be promoted to become a master? But the old master is still up – it did not crash, it is just not reachable over the network. If we would promote one of nodes located at the provider B, we’ll end up with two writable masters, two data sets and split brain:
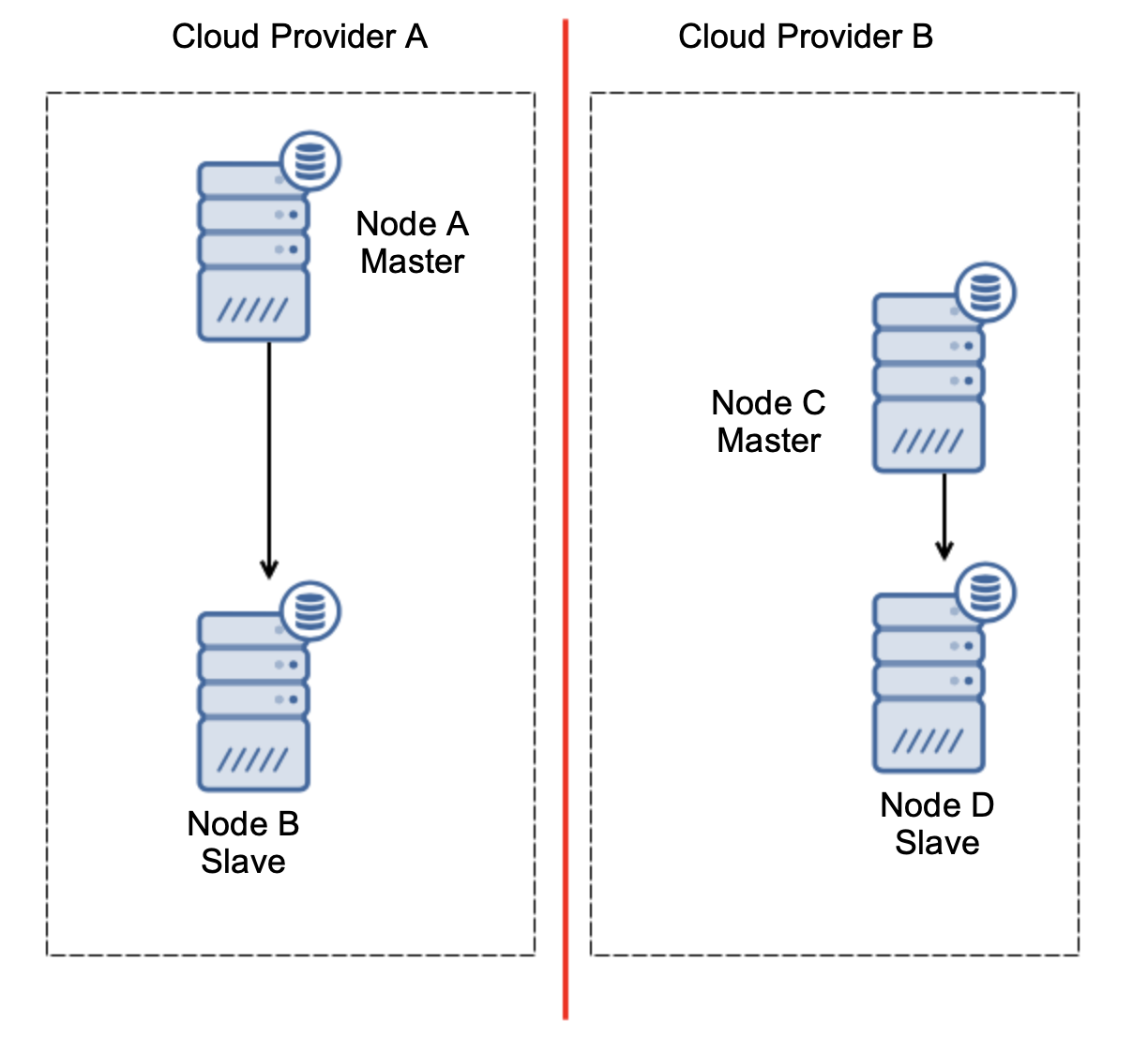
This is definitely not something that we want. There are a couple of options here. First, we can define failover rules in a way that the failover may happen only in one of the network segments, where the master is located. In our case it would mean that only node B could be automatically promoted to become a master. That way we can ensure that the automated failover will happen if the node A is down but no action will be taken if there is a network partitioning. Some of the tools that can help you handle automated failovers (like ClusterControl) support white and blacklists, allowing users to define which nodes can be considered as a candidate to failover to and which should never be used as masters.
Another option would be to implement some sort of a “topology awareness” solution. For example, one could try to check the master state using external services like load balancers.
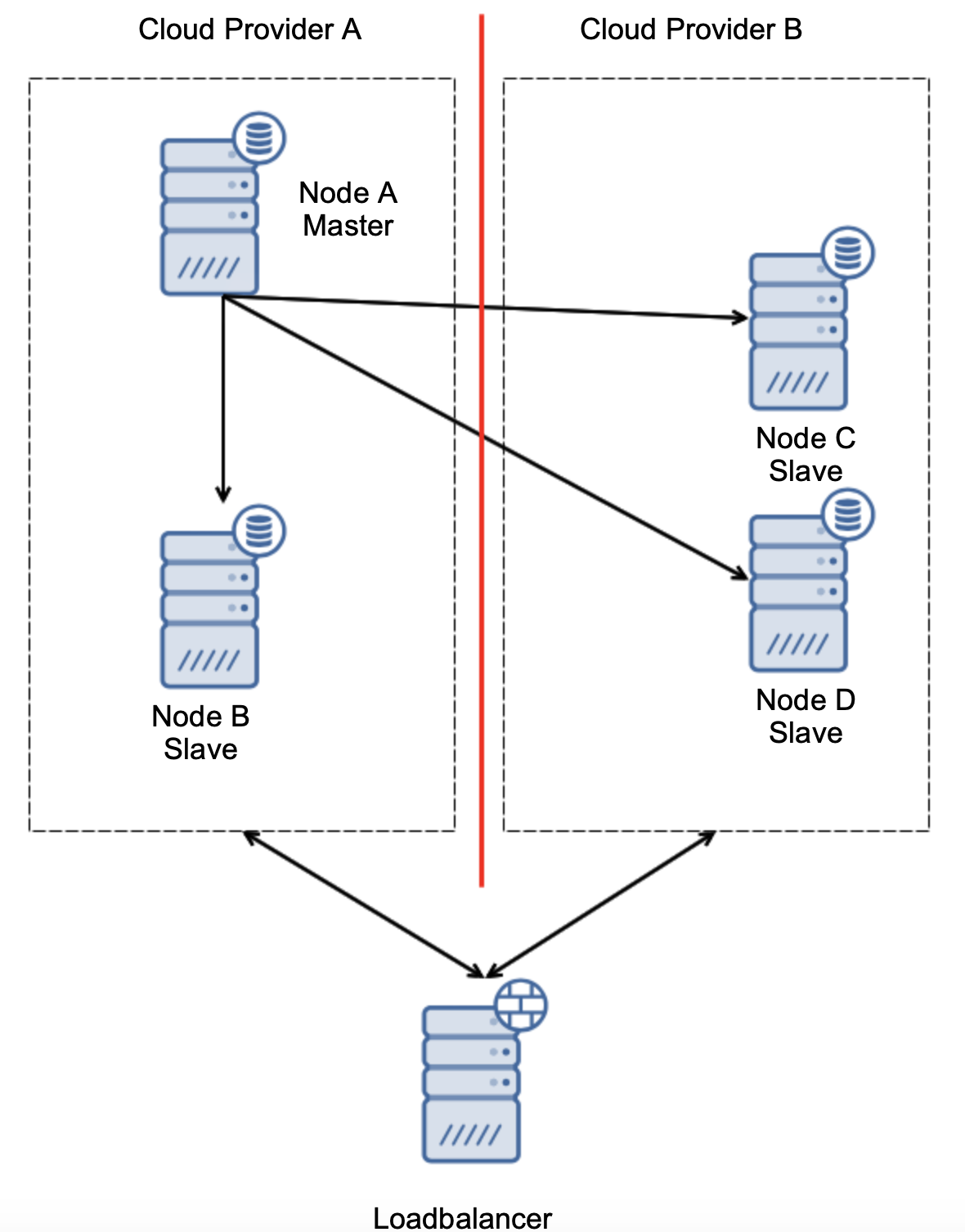
If the failover automation could check the state of the topology as seen by the load balancer, it might be that the load balancer, located in a third location, can actually reach to both datacenters and make it clear that nodes in the cloud provider A are not down, they just cannot be reached from the cloud provider B. Such an additional layer of checks is implemented in ClusterControl.
Finally, whatever the tool you use to implement automated failover, it may also be designed so it is quorum-aware. Then, with three nodes across three locations, you can easily tell which part of the infrastructure should be kept alive and which should not.
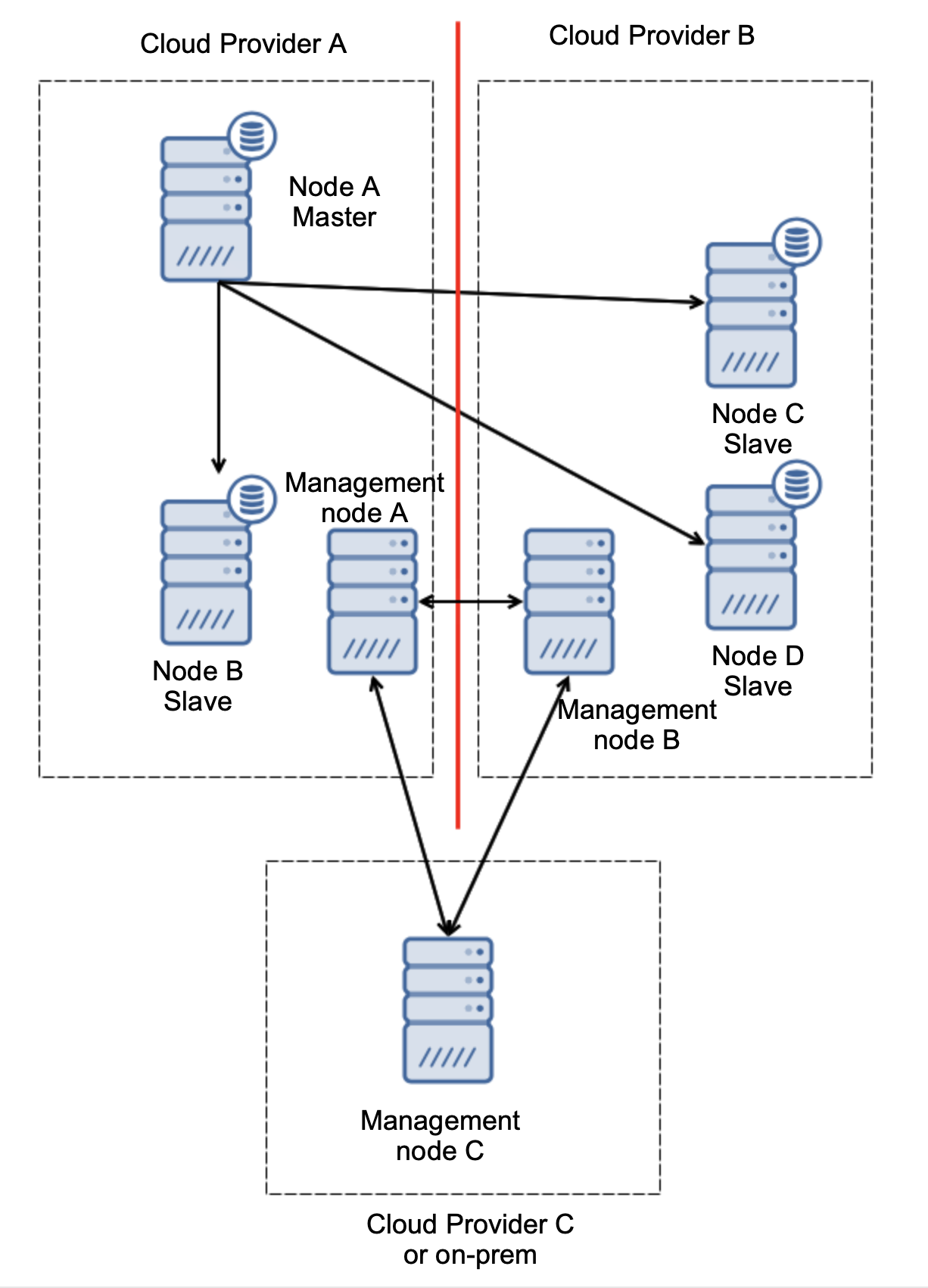
Here, we can clearly see that the issue is related only to the connectivity between providers A and B. Management node C will act as a relay and, as a result, no failover should be started. On the other hand, if one datacenter is fully cut off:
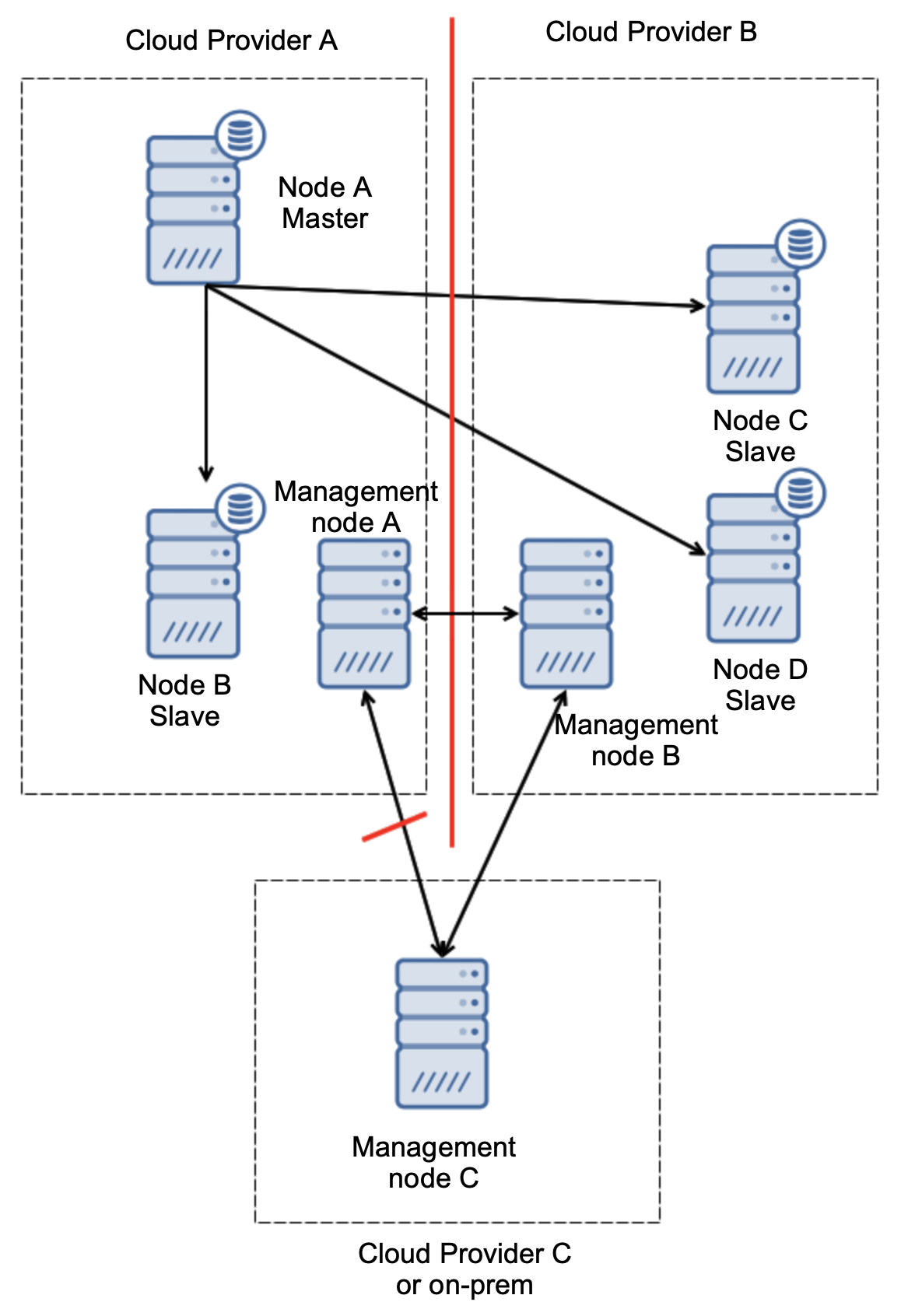
It’s also pretty clear what happened. Management node A will report it cannot reach out to the majority of the cluster while management nodes B and C will form the majority. It is possible to build upon this and, for example, write scripts that will manage the topology according to the state of the management node. That could mean that the scripts executed in cloud provider A would detect that management node A does not form the majority and they will stop all database nodes to ensure no writes would happen in the partitioned cloud provider.
ClusterControl, when deployed in High Availability mode can be treated as the management nodes we used in our examples. Three ClusterControl nodes, on top of the RAFT protocol, can help you to determine if a given network segment is partitioned or not.
Conclusion
We hope this blog post gives you some idea about split-brain scenarios that may happen for MySQL deployments spanning across multiple cloud platforms.



