blog
DevOps Considerations for Production-Ready Database Deployments

MySQL is easy to install and use, it has always been popular with developers and system administrators. On the other hand, deploying a production-ready MySQL environment for a business-critical enterprise workload is a different story. It can be a bit of a challenge, and requires in-depth knowledge of the database. In this blog post, we’ll discuss some of the steps which have to be taken before we can consider our MySQL deployment production-ready.
High Availability

If you belong to those lucky ones who can accept hours of downtime, you can stop reading here and skip to the next paragraph. For 99.999% of business-critical systems, it would not be acceptable. Therefore a production-ready deployment has to include high availability measures. Automated failover of the database instances, as well as a proxy layer which detects changes in topology and state of MySQL and routes traffic accordingly, would be a main requirement. There are numerous tools which can be used to build such environments, for instance MHA, MRM or ClusterControl.
Proxy layer
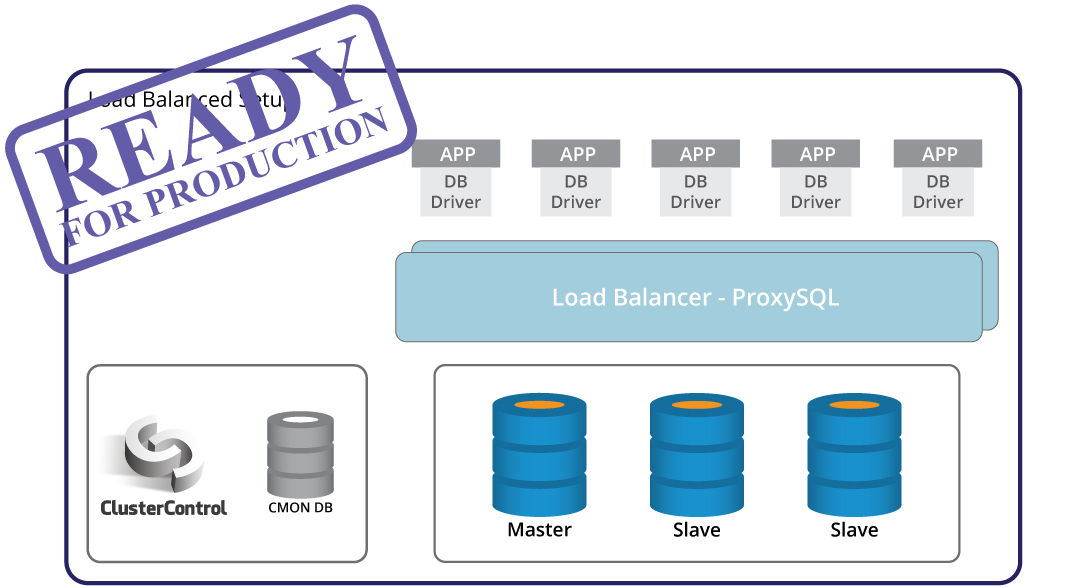
Master failure detection, automated failover and recovery – these are crucial when building a production-ready infrastructure. But on their own, it is not enough. There is still an application which will have to adapt to the topology change triggered by the failover. Of course, it is possible to code the application so it is aware of instance failures. This is a cumbersome and inflexible way of handling topology changes though. Here comes the database proxy – a middle layer between application and database. A proxy can hide the complexity of your database layer from the application – all the application does is to connect to the proxy and the proxy will take care of the rest. The proxy will route queries to a database instance, it will handle topology changes and re-route as necessary. A proxy can also be used to implement read-write split, relieving the application from one more complex case to cover. This creates another challenge – which proxy to use? How to configure it? How to monitor it? How to make it highly available, so it does not become a SPOF?
ClusterControl can assist here. It can be used to deploy different proxies to form a proxy layer: ProxySQL, HAProxy and MaxScale. It preconfigures proxies to make sure they will handle traffic correctly. It also makes it easy to implement any configuration changes if you need to customize proxy setup for your application. Read-write split can be configured using any of the proxies ClusterControl supports. ClusterControl also monitors the proxies, and will recover them in case of failures. The proxy layer can become a single point of failure, as automated recovery might not be enough – to address that, ClusterControl can deploy Keepalived and configure Virtual IP to automate failover.
Backups
Even if you do not need to implement high availability, you probably still have to care about your data. Backup is a must for almost every production database. Nothing else than a backup can save you from an accidental DROP TABLE or DROP SCHEMA (well, maybe a delayed replication slave, but only for some period of time). MySQL offers multiple methods of taking backups – mysqldump, xtrabackup, different types of snapshot (some available only with particular hardware or cloud provider). It’s not easy to design the correct backup strategy, decide on which tools to use and then script whole process so it will execute correctly. It’s not rocket science either, and requires careful planning and testing. Once a backup is taken, you are not done. Are you sure the backup can be restored, and the data is not garbage? Verifying your backups is time consuming, and perhaps not the most exciting thing you will have on your todo list. But it is still important, and needs to be done regularly.
ClusterControl has extensive backup and restore functionality. It supports mysqldump for logical backup and Percona Xtrabackup for physical backup – those tools can be used in almost every environment, either cloud or on-premises. It is possible to build a backup strategy with a mixture of logical and physical backups, incremental or full, in an online fashion.
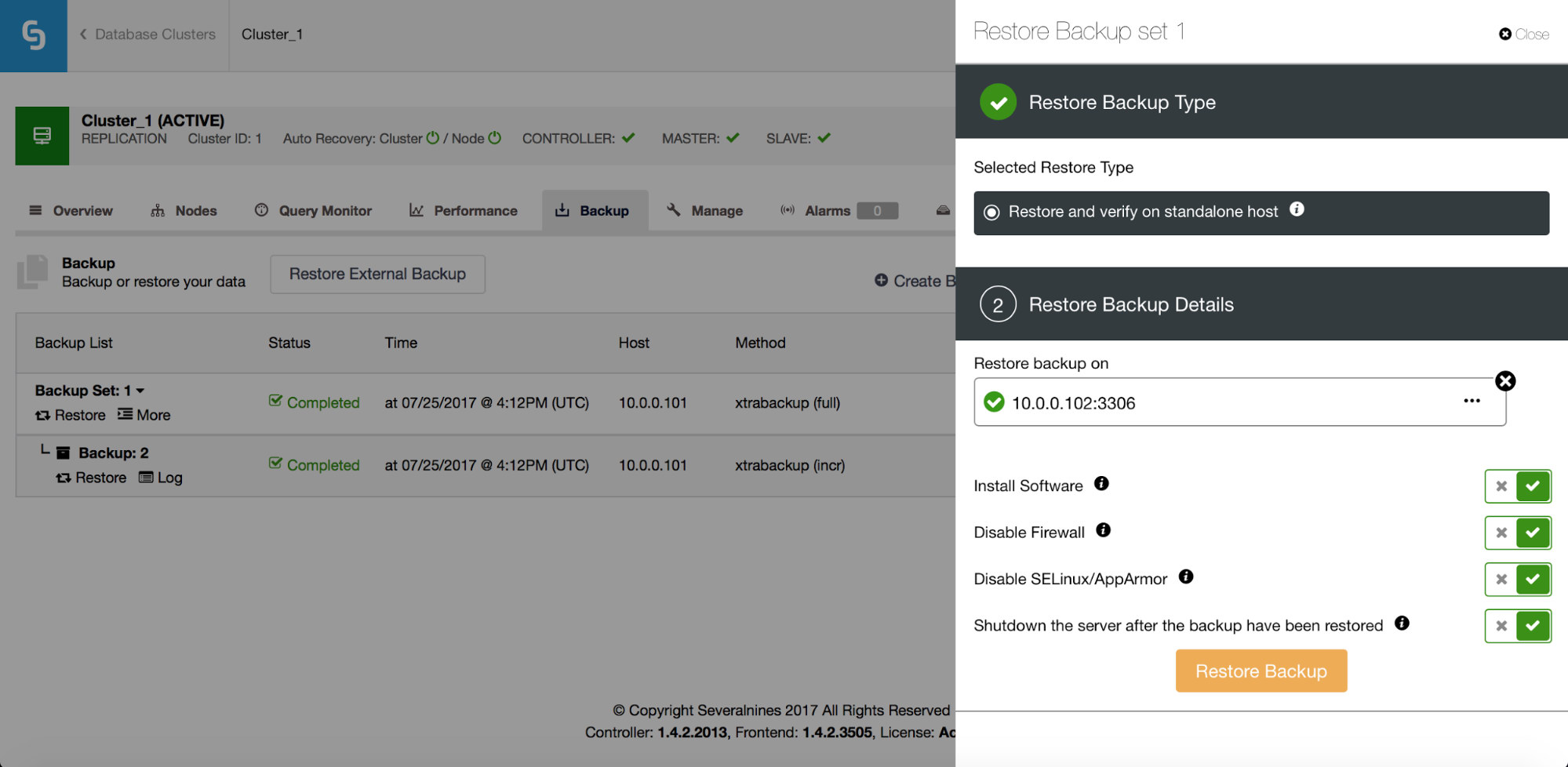
Apart from recovery, it also has options to verify a backup – for instance restore it on a separate host in order to verify if the backup process works ok or not.
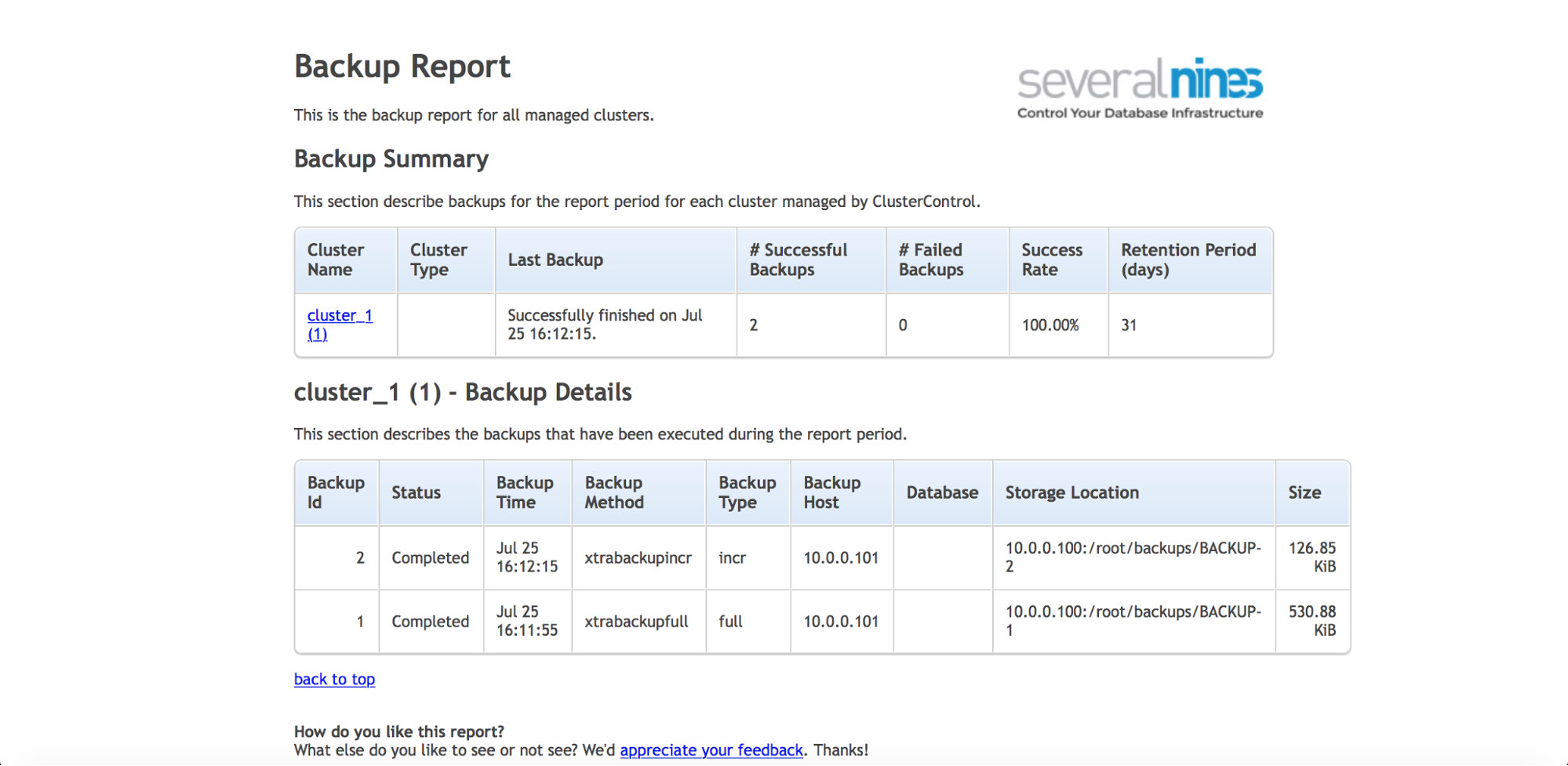
If you’d like to regularly keep an eye on the backups (and you would probably want to do this), ClusterControl has the ability to generate operational reports. The backup report helps you track executed backups, and informs if there were any issues while taking them.
Monitoring and Trending

No deployment is production-ready without proper monitoring of the services. You want to make sure you will be alerted if some services become unavailable so you can take an action, investigate or start recovery procedures. Of course, you also want to have trending solution too. It can’t be stressed enough how important it is to have monitoring data for assessing the state of the infrastructure or for any investigation,either post-mortem or real-time monitoring of the state of services. Metrics are not equal in importance – if you are not very familiar with a particular database product, you most likely won’t know which are the most important metrics to collect and watch. Sure, you might be able to collect everything but when it comes to reviewing data, it’s hardly possible to go through hundreds of metrics per host – you need to know which of them you should focus on.
The open source world is full of tools designed to monitor and collect metrics from different databases – most of them would require you to integrate them with your overall monitoring infrastructure, chatops platform or oncall support tools (like PagerDuty). It might also be required to install and integrate multiple components – storage (some sort of time-series database), presentation layer and data collection tools.
ClusterControl is a bit of a different approach, as it is one single product with real-time monitoring, trending, and dashboards that show the most important details. Database advisors, which can be anything from simple configuration advice, warning on thresholds or more complex rules for predictions, would generally produce comprehensive recommendations.
Ability to Scale-Up

Databases tend to grow in size, and it is not unlikely that it would grow in terms of transaction volumes or number of users. The ability to scale out or up can be critical for production. Even if you do a great job in estimating your hardware requirements at the start of the product lifecycle, you will probably have to handle a growth phase – as long as your product is successful, that is (but that’s what we all plan for, right?). You have to have the means to easily scale-up your infrastructure to cope with incoming load. For stateless services like webservers, this is fairly easy – you just need to provision more instances using the latest production image or code from your version control tool. For stateful services like databases, it’s more tricky. You have to provision new instances using your current production data, set up replication or some form of clustering between the current and the new instances. This can be a complex process and to get it right, you need to have more in-depth knowledge of the clustering or replication model chosen.
ClusterControl, as the name suggests, provides extensive support for building out clustered or replicated database setups. The methods used are battle tested through thousands of deployments. It comes with a Command Line Interface (CLI) so it can be easily integrated with configuration management systems. Please keep it in mind, though, that you might not want to make changes to your pool of databases too often – provisioning of a new instance takes time and adds some overhead in existing databases. Therefore you may want to stay on a “over-provisioned” side a little bit so you will have some time to spin up new instance before your cluster gets overloaded.
All in all, there are several steps you still have to take after initial deployment, to make sure your environment is ready for production. With the right tools, it is much easier to get there.



