blog
Considerations for Administering MongoDB

Below is an excerpt from our whitepaper “MongoDB Management and Automation with ClusterControl” which can be downloaded for free.
Considerations for Administering MongoDB
Built-in Redundancy
A key feature of MongoDB is its built-in redundancy, in the form of Replication. If you have two or more data nodes, they can be configured as a replica set, in which all data written to the Primary node, is replicated in near real time to the secondary nodes,
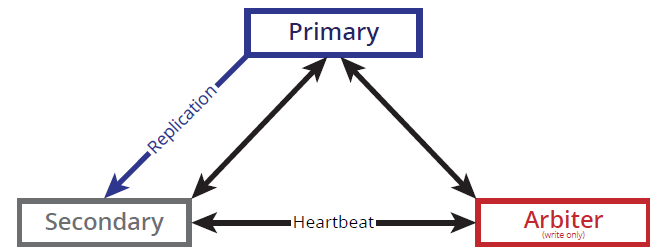
ensuring multiple copies of the data. In the case of Primary failover, the remaining nodes in the replica set conduct an election and promote the winner to be Primary, a process that typically takes 2-3 seconds, and writes to the replica set can resume. MongoDB also uses a journal for faster, safer writes to the server or replica set, and also employs a “write concern” method through which the level of write redundancy is
configured.
To manually deploy a replica set, the high-level steps are as follows:
- Allocate a single physical or virtual host for each database node, and install the MongoDB command line client on your desktop. For a redundant replica set configuration, a minimum of three nodes are required, at least two of which will be data nodes. One node in the replica set may be configured as an arbiter: this is a mongod process configured only to make up a quorum by providing a vote in the election of a Primary when required. Data is not replicated to arbiter processes.
- Install MongoDB on each node. Some Linux distributions include MongoDB Community Edition, but be aware that these may not include the latest versions. MongoDB Enterprise is available only by download from MongoDB’s website. Similar functionality to MongoDB Enterprise is also available via Percona Server for MongoDB, a drop-in replacement for MongoDB Enterprise or Community Edition.
- Configure the individual mongod.conf configuration files for your replica set, using the “replication parameter”. If you will use a key file for security, configure this now also. Note that using key file security also enables role-based authentication, so you will also need to add users and roles to use the servers. Restart the mongod process on each server.
- Ensure connectivity between nodes. You must ensure that MongoDB replica set nodes can communicate with each other on port 27017, and also that your client(s) can connect to each of the replica set nodes on the same port.
- Using the MongoDB command line client, connect to one of the servers, and run rs.initiate() to initialise your replica set, followed by rs.add() for each additional node. rs.conf() can be used to view the configuration.
While these steps are not as complex as deploying and configuring a MongoDB sharded cluster, or sharding a relational database, they can be onerous and prone to error, especially in larger environments.
Scalability
MongoDB is frequently referred to as “web scale” database software, due to its capacity for scaling horizontally. Like relational databases, it is possible to scale MongoDB vertically, simply by upgrading the physical host on which is resides with more CPU cores, more RAM, faster disks, or even increased bus speed. Vertical scaling has its limits however, both in terms of cost-benefit ratio and diminishing returns, and of technical limitation. To address this, MongoDB has an “auto-sharding” feature, that allows databases to be split across many hosts (or replica sets, for redundancy). While sharding is also possible on relational platforms, unless designed for at database inception, this requires major schema and application redesign, as well as client application redesign, making this a tedious, time-consuming, and error-prone process.
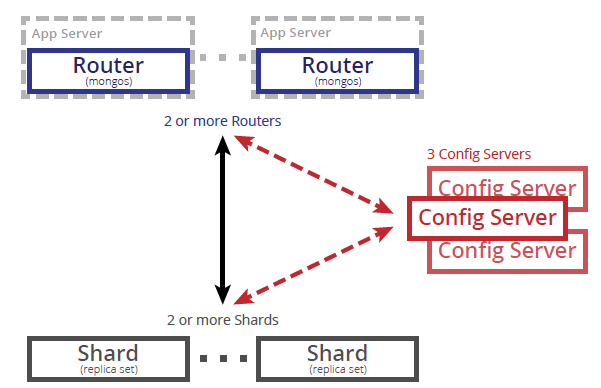
MongoDB sharding works by introducing a router process, through which clients connect to the sharded cluster, and configuration servers, which store the cluster metadata, the location in the cluster of each document. When a client submits a query to the router process, it first refers to the config servers to obtain the locations of the documents, and then obtains the query results directly from the individual servers or
replica sets (shards). Sharding is carried out on a per collection basis.
A critically important parameter here, for performance purposes, is the “shard key”, an indexed field or compound field that exists in each document in a collection. It is this that defines the write distribution across shards of a collection. As such, a poorly-chosen shard key can have a very detrimental effect on performance. For example, a purely time-series based shard key may result in all writes going to a single node for extended periods of time. However, a hashed shard key, while evenly distributing writes across shards, may impact read performance as a result set is retrieved from many nodes.
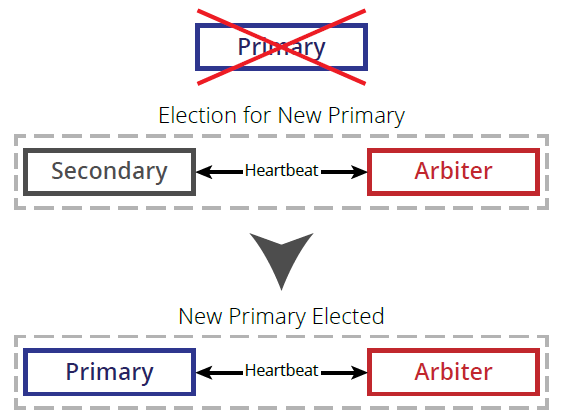
Arbiters
A MongoDB arbiter is a mongod process that has been configured not to act as a data node, but to provide only the function of voting when a replica set Primary is to be elected, to break ties and guard against a split vote. An arbiter may not become Primary, as it does not hold a copy of the data or accept writes. While it is possible to have more than one arbiter in a replica set, it is generally not recommended.
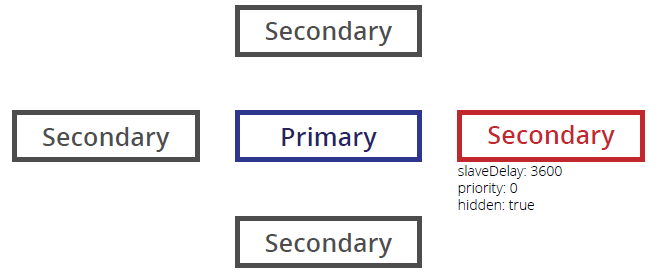
Delayed Replica Set Members
Delayed replica set members add an additional level of redundancy, maintaining a state that is a fixed number of seconds behind the Primary. As delayed members are a “rolling backup” or a running “historical” snapshot of the data set, they can help to recover from various types of human error.
Delayed members are “hidden” replica set members, invisible to client applications, and so cannot be queried directly. They also may not become Primary during normal operations, and must be reconfigured manually in the case that they are to be used to recover from error.
Backups
Backing up a replica set or sharded cluster is carried out via the “mongodump“ command line utility. When used with the –oplog parameter, this creates a dump of the database that includes an oplog, to create a point-in-time snapshot of the state of a mongod instance. Using mongorestore with the –replayOplog parameter, you can then fully restore the data state at the time the backup completed, avoiding inconsistency.
For more advanced backup requirements, a third party tool called “mongodbconsistent-backup” – also command line based – is available that provides fully consistent backups of sharded clusters, a complex procedure, given that sharded databases are distributed across multiple hosts.
Monitoring
There are a number of commercial tools, both official and unofficial, available on the market for monitoring MongoDB. These tools, in general, are single product management utilities, focusing on MongoDB exclusively. Many focus only on certain specific aspects, such as collection management in an existing MongoDB architecture, or on backups, or on deployment. Without proper planning, this can lead to a situation where a proliferation of additional tools must be deployed and managed in your environment.
The command line tools provided with MongoDB, “mongotop” and “mongostat” can provided a detailed view of your environments performance, and can be used to diagnose issues. In addition, MongoDB’s “mongo” command line client can also run “rs.status()” – or in a sharded cluster “sh.status() – to view the status of replica sets or clusters and their member hosts. The “db.stats()” command returns a document that addresses storage use and data volumes, and their are equivalents for collections, as well as other calls to access many internal metrics.
Synopsis
This has been a brief synopsis of considerations for administering MongoDB. Even at such a high level though, it should immediately be obvious that while it is possible to administer a replica set or sharded cluster from the command line using available tools, this does not scale in an environment with many replica sets or with a large production sharded cluster. In medium to large environments comprising many hosts
and databases, it quickly becomes unfeasible to manage everything with command line tools and scripts. While internal tools and scripts can be developed to deploy and maintain the environment, this adds the burden of managing new development, revision control systems, and processes. A simple upgrade of a database server may become a complex process if tooling changes are required to support new database
server versions.
But without internal tools and scripts, how do we automate and manage MongoDB clusters? Download the whitepaper to learn how!



