blog
Building High Availability PostgreSQL Clusters with Patroni and Other Integrated Approaches

In modern application stacks, downtime is a direct threat to business continuity, customer trust, and revenue. Regardless of whether it is an e-commerce platform, a fintech application, or a critical internal system, the expectation is 24/7 availability, underscoring the critical importance of High Availability (HA) and automated failover mechanisms within PostgreSQL clusters. HA ensures that database services remain operational even in the event of individual node failures, while automated failover minimizes human intervention and recovery time by promptly promoting a standby node to primary status upon failure.
Without automation, organizations are susceptible to extended outages that can lead to lost transactions, compliance violations, and reputational damage. Conversely, a meticulously configured PG HA cluster utilizing tools such as Patroni, repmgr, or PgAutoFailover can detect node failures in real time, initiate failover within seconds, and sustain application availability with minimal disruption. Ultimately, investmenting in an automated failover strategy transcends mere technical resilience; it is integral to safeguarding financial stability, ensuring customer satisfaction, and preserving trust in an perpetually online environment.
In this post, we will review Patroni’s architecture and functionality, as well as its operational challenges and how incorporating ClusterControl (CC) into its workflow, or even replacing it with CC, can help ensure a more robust and efficient operational posture — let’s begin.
Introducing Patroni and its architecture
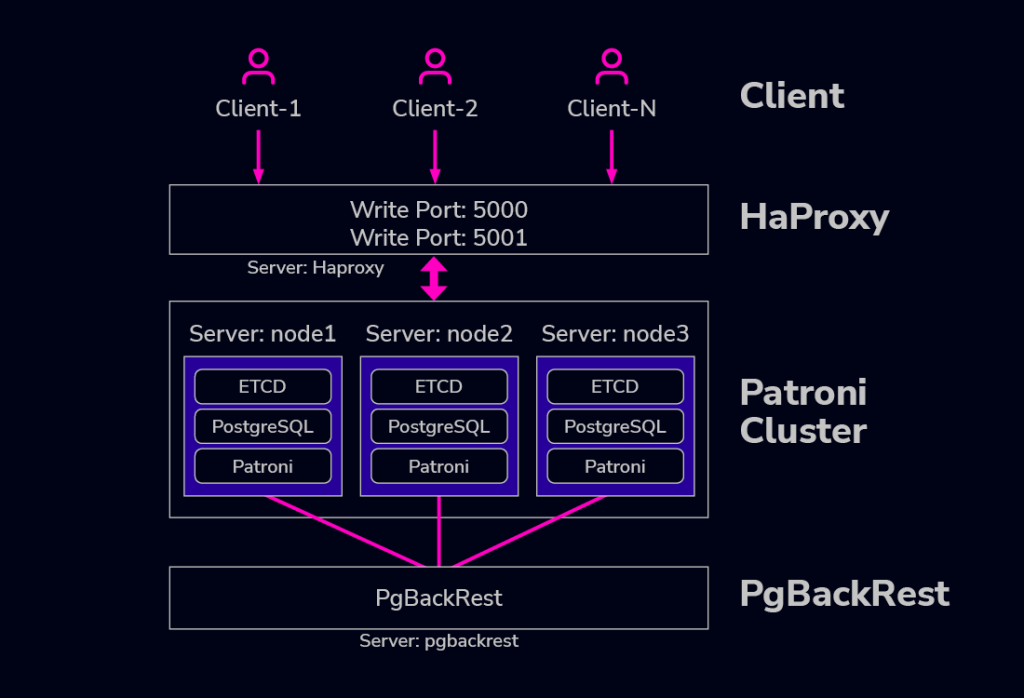
Patroni is a powerful open-source solution that forms the core of many highly available PostgreSQL clusters. It intelligently manages automatic failover and replication through a distributed consensus model. Its unique strength lies in its architecture, which leverages a distributed key-value store, such as etcd, Consul, or ZooKeeper, as the definitive source for cluster state and leader election.
Instead of direct inter-node communication, Patroni utilizes the Distributed Configuration Store (DCS) to coordinate leadership. The active primary node maintains a lease with the DCS, while standby nodes continuously monitor this lease for changes. Should the primary become unresponsive, a new leader is automatically elected based on predefined criteria like replication lag and node health.
Patroni’s behavior is entirely driven by YAML-based configuration files. These files declaratively define all aspects, including PostgreSQL connection parameters, replication settings, failover strategies, and DCS endpoints. This declarative approach simplifies version control, auditing, and cluster behavior adjustments without requiring code modifications.
In essence, Patroni’s DCS-driven coordination and YAML-based configuration provide a robust and adaptable framework for creating self-healing, highly available PostgreSQL clusters suitable for production environments.
Patroni’s operational considerations and challenges
As a popular open-source solution for PostgreSQL HA, Patroni offers transparency, community support, and cost savings. Flexible and reliable, it integrates with various consensus stores and load balancers using YAML for configuration and is widely adopted across industries.
While Patroni is a powerful tool for PostgreSQL high availability, it comes with challenges: chief among them is its reliance on a Distributed Configuration Store (DCS) like etcd or Consul for leader election and cluster coordination. Managing and maintaining the DCS adds complexity, especially for teams unfamiliar with distributed systems.
Operating Patroni in production also requires a solid grasp of PostgreSQL replication, failover logic, and system reliability. Without this expertise, troubleshooting issues like DCS failures or split-brain scenarios can be difficult and risky.
Integrating Patroni with ClusterControl requires careful consideration, as both systems possess their own distinct failover logic and cluster management capabilities. Patroni’s native leader election and failover mechanisms, which rely on Distributed Configuration Stores (DCS) like etcd or Consul, can clash with ClusterControl’s parallel operations. This dual management can result in conflicting decisions and unpredictable cluster behavior.
ClusterControl provides a consolidated platform for monitoring Patroni-based PostgreSQL clusters. It delivers extensive monitoring of operating system and database metrics, database workload, and queries, complemented by strong alerting functionalities.
N.B. To prevent ClusterControl from initiating actions based on database conditions, it is essential to disable Auto Recovery for both clusters and nodes.
Integrating Patroni and ClusterControl for PostgreSQL HA Operational Excellence
Operational excellence in PostgreSQL extends beyond mere failover automation, encompassing crucial aspects such as visibility, scalability, and swift recovery from failures. The integration of Patroni and ClusterControl provides a robust solution for managing PostgreSQL clusters, prioritizing high availability, observability, and scalability. Let’s delve into how each component contributes to achieving excellence across key operational domains.
Failover & Switchover
Patroni ensures continuity in mission-critical applications by automating failover through a DCS-driven consensus mechanism. It eliminates manual intervention and reduces downtime by promoting the most up-to-date standby node as the new primary if the current primary becomes unreachable or fails health checks. This automated node promotion, facilitated by the DCS (e.g., etcd, Consul) based on health and replication status reported by each node, ensures quick recovery and minimal data loss.
In addition to failover, Patroni supports manual switchover, the ability to promote a standby node in a controlled way during maintenance windows or planned infrastructure changes. Switchover is essential for reducing operational risk during patching, scaling, or load-balancer configuration updates. It ensures that transitions are safe and predictable without compromising uptime.
ClusterControl provides a visual interface for monitoring Patroni-based clusters, allowing users to track node states, manually initiate failovers or switchovers, and review logs and cluster events. Furthermore, ClusterControl can entirely replace Patroni’s native failover mechanisms, eliminating the need for an external Distributed Consensus Store (DCS). This approach simplifies High Availability (HA) deployments and offers administrators precise control over failover execution.
Performance & Scaling
Patroni is designed with built-in support for streaming replication, which allows for the creation of multiple standby nodes that function as read replicas. These replicas remain synchronized with the primary node and are valuable for offloading read queries, thereby facilitating workload scaling without overburdening the primary.
N.B. Patroni does not natively manage query routing or read load balancing; these functions require external tools such as HAProxy or PgBouncer to facilitate read-write splitting and connection management.
ClusterControl optimizes replica utilization through continuous monitoring of replication lag, node performance, and overall system health. Administrators gain comprehensive visibility into key metrics like query throughput, I/O utilization, and replication delay across all nodes. This detailed insight facilitates more effective load balancing and prevents the routing of read operations to outdated replicas.
Furthermore, ClusterControl offers auto-scaling capabilities, automatically provisioning additional read replicas in response to traffic surges or when capacity thresholds are exceeded, ensuring the database layer scales smoothly with increasing demand.
Troubleshooting & Best Practices
Network partitions pose a significant challenge in distributed systems. Patroni addresses the risk of split-brain scenarios by closely linking leadership to the acquisition of a DCS lease. A node that loses connectivity to the DCS will proactively demote itself, even if it perceives the primary to have failed. This mechanism guarantees that only one node functions as the primary at any given time. Consequently, the DCS becomes a central point of coordination, making its availability paramount. To build resilient Patroni clusters, it is crucial to deploy and monitor the DCS with its own high-availability configuration.
Effective troubleshooting of HA events or performance bottlenecks necessitates centralized logging, which ClusterControl provides through consolidated logging, metrics dashboards, and historical query statistics. This simplifies root cause analysis (RCA) by allowing administrators to trace anomalies across various layers, including PostgreSQL logs, failover triggers, system performance, and configuration changes, all from a unified interface. Furthermore, ClusterControl’s alerting and audit trails empower teams to identify and address issues proactively, minimizing user impact.
Wrapping up
Combining Patroni’s powerful failover logic with ClusterControl’s comprehensive management platform enables PostgreSQL environments to meet high standards of availability, scalability, and operational insight. Whether using them together or adopting ClusterControl as a standalone HA solution, organizations gain a flexible, production-ready foundation for PostgreSQL that supports business continuity, simplifies operations, and empowers DevOps teams to focus on innovation rather than firefighting.



