blog
Database Performance Tuning for MariaDB

Put a Virtual DBA on Every Database Server with DBScout
Connect in minutes and optimize your database servers with guardrailed auto-fixes, severity-ranked findings, and permission-based interventions.
(Updated on 17 September 2024)
Ever since MySQL was originally forked to form MariaDB it has been widely supported and adopted quickly by a large audience in the open source database community. Originally a drop-in replacement, MariaDB has started to create distinction against MySQL, especially with the release of MariaDB 10.2.
Despite this, however, there’s still no real telltale difference between MariaDB and MySQL, as both have engines that are compatible and can run natively with one another. So don’t be surprised if the tuning of your MariaDB setup has a similar approach to one tuning MySQL.
This blog will discuss the tuning of MariaDB, specifically those systems running in a Linux environment.
MariaDB Hardware and System Optimization
MariaDB recommends that you improve your hardware in the following priority order…
Memory
Memory is the most important factor for databases as it allows you to adjust the Server System Variables. More memory means larger key and table caches, which are stored in memory so that disks can access, an order of magnitude slower, is subsequently reduced.
Keep in mind though, simply adding more memory may not result in drastic improvements if the server variables are not set to make use of the extra available memory.
Using more RAM slots on the motherboard increases the bus frequency, and there will be more latency between the RAM and the CPU. This means that using the highest RAM size per slot is preferable.
Disks
Fast disk access is critical, as ultimately it’s where the data resides. The key figure is the disk seek time (a measurement of how fast the physical disk can move to access the data) so choose disks with as low a seek time as possible. You can also add dedicated disks for temporary files and transaction logs.
Fast Ethernet
With the appropriate requirements for your internet bandwidth, fast ethernet means it can have faster response to clients requests, replication response time to read binary logs across the slaves, faster response times is also very important especially on Galera-based clusters.
CPU
Although hardware bottlenecks often fall elsewhere, faster processors allow calculations to be performed more quickly, and the results sent back to the client more quickly. Besides processor speed, the processor’s bus speed and cache size are also important factors to consider.
Setting Your Disk I/O Scheduler
I/O schedulers exist as a way to optimize disk access requests. It merges I/O requests to similar locations on the disk. This means that the disk drive doesn’t need to seek as often and improves a huge overall response time and saves disk operations. The recommended values for I/O performance are noop and deadline.
noop is useful for checking whether complex I/O scheduling decisions of other schedulers are not causing I/O performance regressions. In some cases it can be helpful for devices that do I/O scheduling themselves, as intelligent storage, or devices that do not depend on mechanical movement, like SSDs. Usually, the DEADLINE I/O scheduler is a better choice for these devices, but due to less overhead NOOP may produce better performance on certain workloads.
For deadline, it is a latency-oriented I/O scheduler. Each I/O request has got a deadline assigned. Usually, requests are stored in queues (read and write) sorted by sector numbers. The DEADLINE algorithm maintains two additional queues (read and write) where the requests are sorted by deadline. As long as no request has timed out, the “sector” queue is used. If timeouts occur, requests from the “deadline” queue are served until there are no more expired requests. Generally, the algorithm prefers reads over writes.
For PCIe devices (NVMe SSD drives), they have their own large internal queues along with fast service and do not require or benefit from setting an I/O scheduler. It is recommended to have no explicit scheduler-mode configuration parameter.
You can check your scheduler setting with:
cat /sys/block/${DEVICE}/queue/schedulerFor instance, it should look like this output:
cat /sys/block/sda/queue/scheduler
[noop] deadline cfqTo make it permanent, edit /etc/default/grub configuration file, look for the variable GRUB_CMDLINE_LINUX and add elevator just like below:
GRUB_CMDLINE_LINUX="elevator=noop"Increase Open Files Limit
To ensure good server performance, the total number of client connections, database files, and log files must not exceed the maximum file descriptor limit on the operating system (ulimit -n). Linux systems limit the number of file descriptors that any one process may open to 1,024 per process. On active database servers (especially production ones) it can easily reach the default system limit.
To increase this, edit /etc/security/limits.conf and specify or add the following:
mysql soft nofile 65535
mysql hard nofile 65535This requires a system restart. Afterwards, you can confirm by running the following:
$ ulimit -Sn
65535
$ ulimit -Hn
65535Optionally, you can set this via mysqld_safe if you are starting the mysqld process thru mysqld_safe,
[mysqld_safe]
open_files_limit=4294967295or if you are using systemd,
sudo tee /etc/systemd/system/mariadb.service.d/limitnofile.conf <Setting Swappiness on Linux for MariaDB
Linux Swap plays a big role in database systems. It acts like your spare tire in your vehicle, when nasty memory leaks interfere with your work, the machine will slow down… but in most cases will still be usable to finish its assigned task.
To apply changes to your swappiness, simply run,
sysctl -w vm.swappiness=1This happens dynamically, with no need to reboot the server. To make it persistent, edit /etc/sysctl.conf and add the line,
vm.swappiness=1It’s pretty common to set swappiness=0, but since the release of new kernels (i.e. kernels > 2.6.32-303), changes have been made so you need to set vm.swappiness=1.
Filesystem Optimizations for MariaDB
The most common file systems used in Linux environments running MariaDB are ext4 and XFS. There are also certain setups available for implementing an architecture using ZFS and BRTFS (as referenced in the MariaDB documentation).
In addition to this, most database setups do not need to record file access time. You might want to disable this when mounting the volume into the system. To do this, edit your file /etc/fstab. For example, on a volume named /dev/md2, this how it looks like:
/dev/md2 / ext4 defaults,noatime 0 0Creating an Optimal MariaDB Instance
Store Data On A Separate Volume
It is always ideal to separate your database data on a separate volume. This volume is specifically for those types of fast storage volumes such as SSD, NVMe, or PCIe cards. For example, if your entire system volume will fail, you’ll have your database volume safe and rest assured not affected in case your storage hardware will fail.
Tuneup MariaDB To Utilize Memory Efficiently
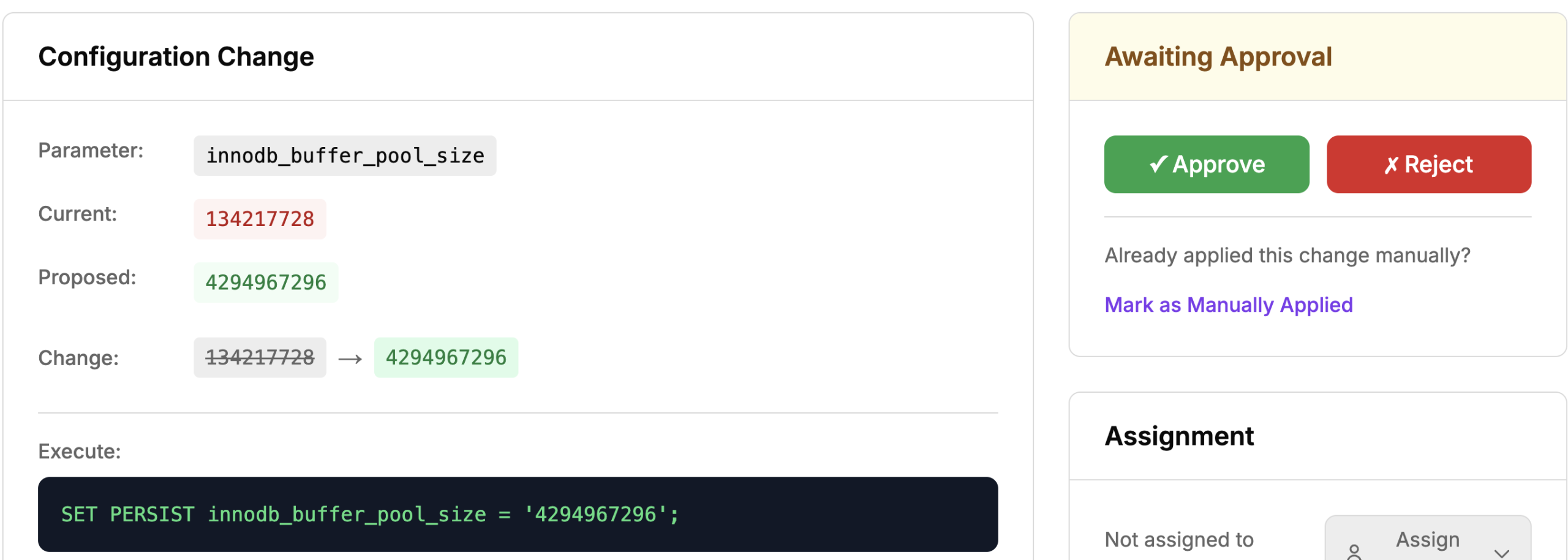
innodb_buffer_pool_size
The primary value to adjust on a database server with entirely/primarily XtraDB/InnoDB tables, can be set up to 80% of the total memory in these environments. If set to 2 GB or more, you will probably want to adjust innodb_buffer_pool_instances as well. You can set this dynamically if you are using MariaDB >= 10.2.2 version. Otherwise, it requires a server restart.
tmp_memory_table_size/max_heap_table_size
For tmp_memory_table_size (tmp_table_size), if you’re dealing with large temporary tables, setting this higher provides performance gains as it will be stored in the memory. This is common on queries that are heavily using GROUP BY, UNION, or sub-queries. Although if max_heap_table_size is smaller, the lower limit will apply. If a table exceeds the limit, MariaDB converts it to a MyISAM or Aria table. You can see if it’s necessary to increase by comparing the status variables Created_tmp_disk_tables and Created_tmp_tables to see how many temporary tables out of the total created needed to be converted to disk. Often complex GROUP BY queries are responsible for exceeding the limit.
While max_heap_table_size, this is the maximum size for user-created MEMORY tables. The value set on this variable is only applicable for the newly created or re-created tables and not the existing ones. The smaller of max_heap_table_size and tmp_table_size also limits internal in-memory tables. When the maximum size is reached, any further attempts to insert data will receive a “table … is full” error. Temporary tables created with CREATE TEMPORARY will not be converted to Aria, as occurs with internal temporary tables, but will also receive a table full error.
innodb_log_file_size
Large memories with high-speed processing and fast I/O disk aren’t new and has its reasonable price as it recommends. If you are preferring more performance gains especially during and handling your InnoDB transactions, setting the variable innodb_log_file_size to a larger value such as 5Gib or even 10GiB is reasonable. Increasing means that the larger transactions can run without needing to perform disk I/O before committing.
join_buffer_size
In some cases, your queries tend to lack use of proper indexing or simply, there are instances that you need this query to run. Not unless it’s going to be heavily called or invoked from the client perspective, setting this variable is best on a session level. Increase it to get faster full joins when adding indexes is not possible, although be aware of memory issues, since joins will always allocate the minimum size.
Set Your max_allowed_packet
MariaDB has the same nature as MySQL when handling packets. It splits data into packets and the client must be aware of the max_allowed_packet variable value. The server will have a buffer to store the body with a maximum size corresponding to this max_allowed_packet value. If the client sends more data than max_allowed_packet size, the socket will be closed. The max_allowed_packet directive defines the maximum size of packet that can be sent.
Setting this value too low can cause a query to stop and close its client connection which is pretty common to receive errors like ER_NET_PACKET_TOO_LARGE or Lost connection to MySQL server during query. Ideally, especially on most application demands today, you can start setting this to 512MiB. If it’s a low-demand type of application, just use the default value and set this variable only via session when needed if the data to be sent or received is too large than the default value (16MiB since MariaDB 10.2.4). In certain workloads that demand on large packets to be processed, then you need to adjust his higher according to your needs especially when on replication. If max_allowed_packet is too small on the slave, this also causes the slave to stop the I/O thread.
Using Threadpool
In some cases, this tuning might not be necessary or recommended for you. Threadpools are most efficient in situations where queries are relatively short and the load is CPU bound (OLTP workloads). If the workload is not CPU bound, you might still want to limit the number of threads to save memory for the database memory buffers.
Using threadpool is an ideal solution especially if your system is experiencing context switching and you are finding ways to reduce this and maintain a lower number of threads than the number of clients. However, this number should also not be too low, since we also want to make maximum use of the available CPUs. Therefore there should be, ideally, a single active thread for each CPU on the machine.
You can set the thread_pool_max_threads, thread_pool_min_threads for the maximum and the minimum number of threads. Unlike MySQL, this is only present in MariaDB.
Set the variable thread_handling which determines how the server handles threads for client connections. In addition to threads for client connections, this also applies to certain internal server threads, such as Galera slave threads.
Tune Your Table Cache + max_connections
If you are facing occasional occurrences in the processlist about Opening tables and Closing tables statuses, it can signify that you need to increase your table cache. You can monitor this also via the mysql client prompt by running SHOW GLOBAL STATUS LIKE ‘Open%table%'</span>; and monitor the status variables.
For max_connections, if you are application requires a lot of concurrent connections, you can start setting this to 500.
For table_open_cache, it shall be the total number of your tables but it’s best you add more depending on the type of queries you serve since temporary tables shall be cached as well. For example, if you have 500 tables, it would be reasonable you start with 1500.
While your table_open_cache_instances, start setting it to 8. This can improve scalability by reducing contention among sessions, the open tables cache can be partitioned into several smaller cache instances of size table_open_cache / table_open_cache_instances.
For InnoDB, table_definition_cache acts as a soft limit for the number of open table instances in the InnoDB data dictionary cache. The value to be defined will set the number of table definitions that can be stored in the definition cache. If you use a large number of tables, you can create a large table definition cache to speed up opening of tables. The table definition cache takes less space and does not use file descriptors, unlike the normal table cache. The minimum value is 400. The default value is based on the following formula, capped to a limit of 2000:
MIN(400 + table_open_cache / 2, 2000)If the number of open table instances exceeds the table_definition_cache setting, the LRU mechanism begins to mark table instances for eviction and eventually removes them from the data dictionary cache. The limit helps address situations in which significant amounts of memory would be used to cache rarely used table instances until the next server restart. The number of table instances with cached metadata could be higher than the limit defined by table_definition_cache, because parent and child table instances with foreign key relationships are not placed on the LRU list and are not subject to eviction from memory.
Unlike the table_open_cache, the table_definition_cache doesn’t use file descriptors, and is much smaller.
Dealing with Query Cache
Preferably, we recommend to disable query cache in all of your MariaDB setup. You need to ensure that query_cache_type=OFF and query_cache_size=0 to complete disable query cache. Unlike MySQL, MariaDB is still completely supporting query cache and do not have any plans on withdrawing its support to use query cache. There are some people claiming that query cache still provides performance benefits for them. However, this post from Percona The MySQL query cache: Worst enemy or best friend reveals that query cache, if enabled, results to have an overhead and shows to have a bad server performance.
If you intend to use query cache, make sure that you monitor your query cache by running SHOW GLOBAL STATUS LIKE ‘Qcache%'</span>;. Qcache_inserts contains the number of queries added to the query cache, Qcache_hits contains the number of queries that have made use of the query cache, while Qcache_lowmem_prunes contains the number of queries that were dropped from the cache due to lack of memory. While in due time, using and enabling query cache may become fragmented. A high Qcache_free_blocks relative to Qcache_total_blocks may indicate fragmentation. To defragment it, run FLUSH QUERY CACHE. This will defragment the query cache without dropping any queries.
Always Monitor Your Servers
It is highly important that you properly monitor your MariaDB nodes. Common monitoring tools out there (like Nagios, Zabbix, or PMM) are available if you tend to prefer free and open-source tools. For corporate and fully-packed tools we suggest you give ClusterControl a try, as it does not only provide monitoring, but it also offers performance advisors, alerts and alarms which helps you improve your system performance and stay up-to-date with the current trends as you engage with the Support team. Database monitoring with ClusterControl is free and part of the Community Edition.
Conclusion
Tuning your MariaDB setup is almost the same approach as MySQL, but with some disparities, as it differs in some of its approaches and versions that it does support. MariaDB is now a different entity in the database world and has quickly gained the trust by the community without any FUD. They have their own reasons why it has to be implemented this way so it’s very important we know how to tune this and optimize your MariaDB server(s).



