blog
Which Time-Series Database is Better: TimescaleDB vs InfluxDB

Time-series databases, as the name suggests, are designed to store data that changes with time. This can be any kind of data which was collected over time. It might be metrics collected from some systems, and actually, all trending systems are examples of the time-series data.
We have different types of time-series databases, which ones should we use?
In this blog, we’ll see what are the main differences between two of the main options, TimescaleDB and InfluxDB.
InfluxDB
InfluxDB has been created by InfluxData. It is a custom, open-source, NoSQL time-series database written in Go. The datastore provides a SQL-like language to query the data, called InfluxQL, which makes it easy for the developers to integrate into their applications. It also has a new custom query language called Flux, this language may make some tasks easier, but there is always a learning curve when adopting a custom query language.
This is a Flux query example:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()In this database, each measurement has a timestamp, and an associated set of tags and set of fields. The field represents the actual measurement reading values, while the tag represents the metadata to describe the measurements. The field data types are limited to floats, ints, strings, and booleans, and cannot be changed without rewriting the data. The tag values are indexed. They are represented as strings, and cannot be updated.
InfluxDB is quite easy to get started, as you don’t have to worry about creating schemas or indexes. However, it is quite rigid and limited, with no ability to create additional indexes, indexes on continuous fields, update metadata after the fact, enforce data validation, etc.
It is not schemaless. There is an underlying schema that is auto-created from the input data.
InfluxDB has to implement from scratch several tools for fault-tolerance, like replication, high availability, and backup/restore, and it is responsible for its on-disk reliability. We’re limited to using these tools and many of these features, like HA, is only available in the enterprise version.
The InfluxDB backup tool can perform a full or incremental backup, and it can be used for point-in-time-recovery.
InfluxDB also offers significantly better on-disk compression than PostgreSQL and TimescaleDB.
TimescaleDB
TimescaleDB is an open-source time-series database optimized for fast ingest and complex queries that supports full SQL. It’s based on PostgreSQL and it offers the best of NoSQL and Relational worlds for Time-series data.
This is a TimescaleDB query example:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';TimescaleDB, as a PostgreSQL extension, is a relational database. This allows to have a short learning curve for new users, and to inherit tools like pg_dump or pg_backup for backing up, and high availability tools, which is an advantage in front of other time-series databases. It also supports streaming replication as the primary method of replication, which can be used in a high availability setup. In terms of failover and backups, you can automate this process by using an external system like ClusterControl.
In TimescaleDB, each time-series measurement is recorded in its own row, with a time field followed by any number of other fields, which can be floats, ints, strings, booleans, arrays, JSON blobs, geospatial dimensions, date/time/timestamps, currencies, binary data, and more.
You can create indexes on any field (standard indexes) or multiple fields (composite indexes), or on expressions like functions, or even limit an index to a subset of rows (partial index). Any of these fields can be used as a foreign key to secondary tables, which can then store additional metadata.
In this way, you need to choose a schema, and decide which indexes you’ll need for your system.
Performance
If we talk about performance, we can check the great TimescaleDB comparison blog. There you have a detailed comparison for performance between both databases with charts and metrics. Let’s see some of the most important information from this blog.
Inserts
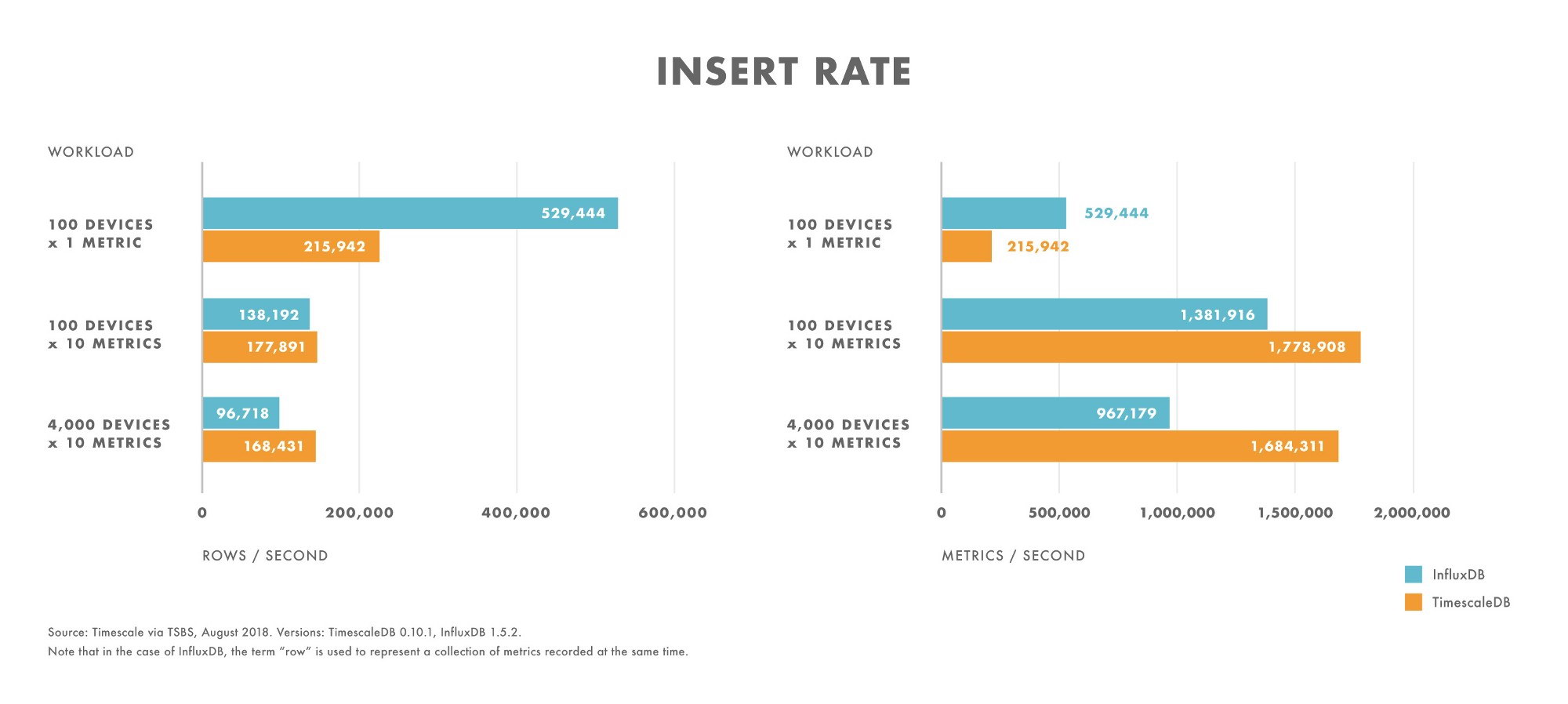
- For workloads with very low cardinality (e.g., 100 devices), InfluxDB outperforms TimescaleDB.
- As cardinality increases, InfluxDB insert performance drops off faster than on TimescaleDB.
- For workloads with moderate to high cardinality (e.g., 100 devices sending 10 metrics), TimescaleDB outperforms InfluxDB.

Read latency
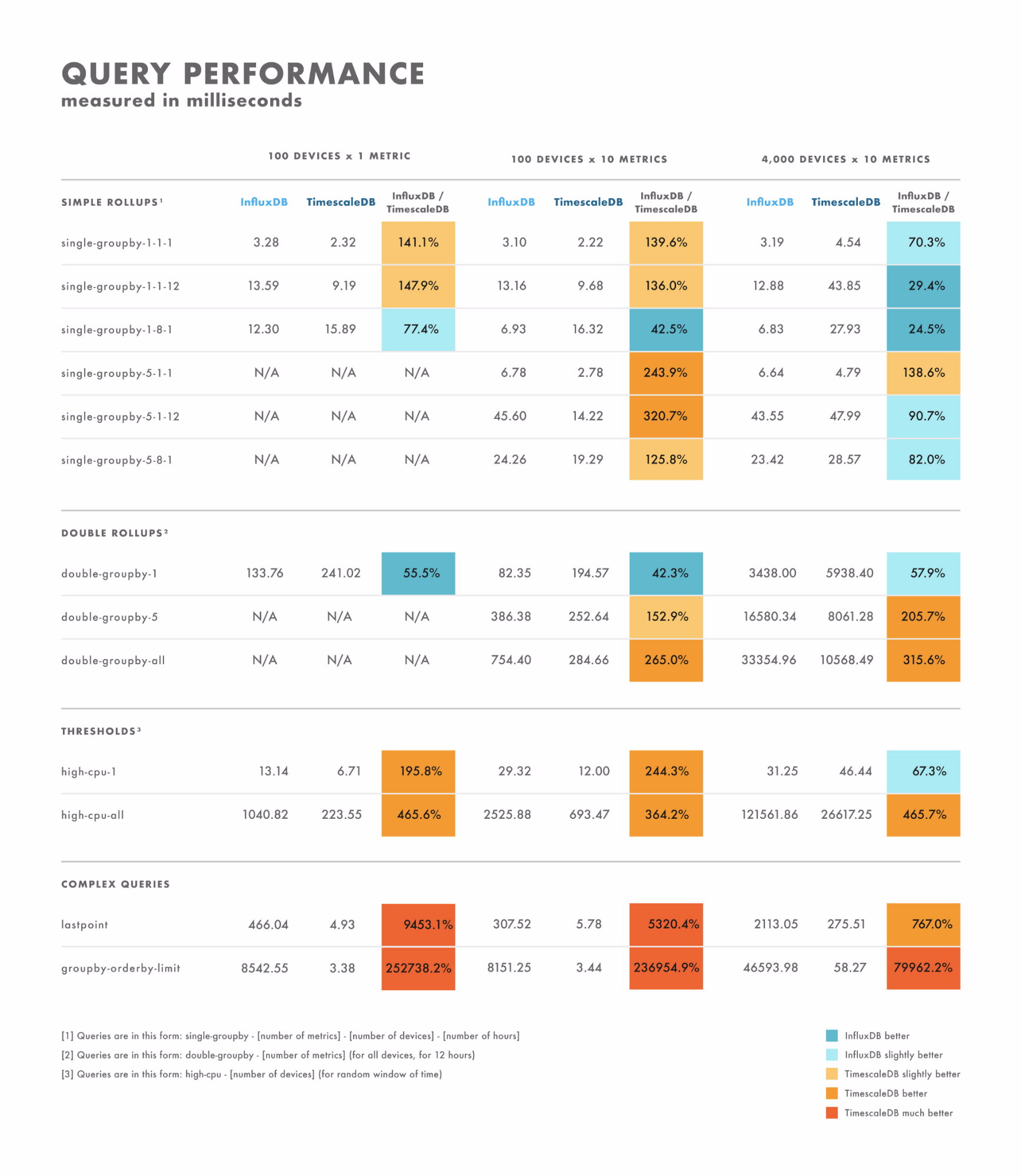
- For simple queries, the results vary quite a bit: there are some where one database is clearly better than the other, while others depend on the cardinality of your dataset. The difference here is often in the range of single-digit to double-digit milliseconds.
- For complex queries, TimescaleDB vastly outperforms InfluxDB, and supports a broader range of query types. The difference here is often in the range of seconds to tens of seconds.
- With that in mind, the best way to properly test is to benchmark using the queries you plan to execute.
Stability issues
- InfluxDB has stability and performance issues at high (100K+) cardinalities.
Conclusion
If your data fits in the InfluxDB data model, and you don’t expect to change in the future, then you should consider using InfluxDB as this model is easier to get started with, and like most databases that use a column-oriented approach, offers better on-disk compression than PostgreSQL and TimescaleDB.
However, the relational model is more versatile and offers more functionality, flexibility, and control that the InfluxDB model. This is especially important as your application evolves. And when planning your system you should consider both its current and future needs.
In this blog, we could see a short comparison between TimescaleDB and InfluxDB, and we could say TimescaleDB as a PostgreSQL extension, looks pretty mature and feature-rich as it inherits a lot from PostgreSQL. But you can take your own decision based on the pros and cons mentioned earlier in this blog, and make sure you benchmark your own workload. Good luck in this new time-series database world!



