blog
Using Sysbench to Generate Test Data for Sharded Table in MySQL

Sysbench is a great tool to generate test data and perform MySQL OLTP benchmarks. Commonly, one would do a prepare-run-cleanup cycle when performing benchmark using Sysbench. By default, the table generated by Sysbench is a standard non-partition base table. This behavior can be extended, of course, but you have to know how to write it in the LUA script.
In this blog post, we are going to show how to generate test data for a partitioned table in MySQL using Sysbench. This can be used as a playground for us to dive further into the cause-effect of table partitioning, data distribution and query routing.
Single-server Table Partitioning
Single-server partitioning simply means all table’s partitions reside on the same MySQL server/instance. When creating the table structure, we will define all of the partitions at once. This kind of partitioning is good if you have data that loses its usefulness over time and can be easily removed from a partitioned table by dropping the partition (or partitions) containing only that data.
Create the Sysbench schema:
mysql> CREATE SCHEMA sbtest;Create the sysbench database user:
mysql> CREATE USER 'sbtest'@'%' IDENTIFIED BY 'passw0rd';
mysql> GRANT ALL PRIVILEGES ON sbtest.* TO 'sbtest'@'%';In Sysbench, one would use the –prepare command to prepare the MySQL server with schema structures and generates rows of data. We have to skip this part and define the table structure manually.
Create a partitioned table. In this example, we are going to create only one table called sbtest1 and it will be partitioned by a column named “k”, which is basically a ranged integer between 0 to 1,000,000 (based on the –table-size option that we are going to use in the insert-only operation later on):
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p1 VALUES LESS THAN (499999),
PARTITION p2 VALUES LESS THAN MAXVALUE
);We are going to have 2 partitions – The first partition is called p1 and will store data where the value in column “k” is lower than 499,999 and the second partition, p2, will store the remaining values. We also create a primary key that contains both important columns – “id” is for row identifier and “k” is the partition key. In partitioning, a primary key must include all columns in the table’s partitioning function (where we use “k” in the range partition function).
Verify the partitions are there:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest2'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest | sbtest1 | p1 | 0 |
| sbtest | sbtest1 | p2 | 0 |
+--------------+------------+----------------+------------+We can then start a Sysbench insert-only operation as below:
$ sysbench
/usr/share/sysbench/oltp_insert.lua
--report-interval=2
--threads=4
--rate=20
--time=9999
--db-driver=mysql
--mysql-host=192.168.11.131
--mysql-port=3306
--mysql-user=sbtest
--mysql-db=sbtest
--mysql-password=passw0rd
--tables=1
--table-size=1000000
runWatch the table partitions grow as Sysbench runs:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest2'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest | sbtest1 | p1 | 1021 |
| sbtest | sbtest1 | p2 | 1644 |
+--------------+------------+----------------+------------+If we count the total number of rows using the COUNT function, it will correspond to the total number of rows reported by the partitions:
mysql> SELECT COUNT(id) FROM sbtest1;
+-----------+
| count(id) |
+-----------+
| 2665 |
+-----------+That’s it. We have a single-server table partitioning ready that we can play around with.
Multi-server Table Partitioning
In multi-server partitioning, we are going to use multiple MySQL servers to physically store a subset of data of a particular table (sbtest1), as shown in the following diagram:
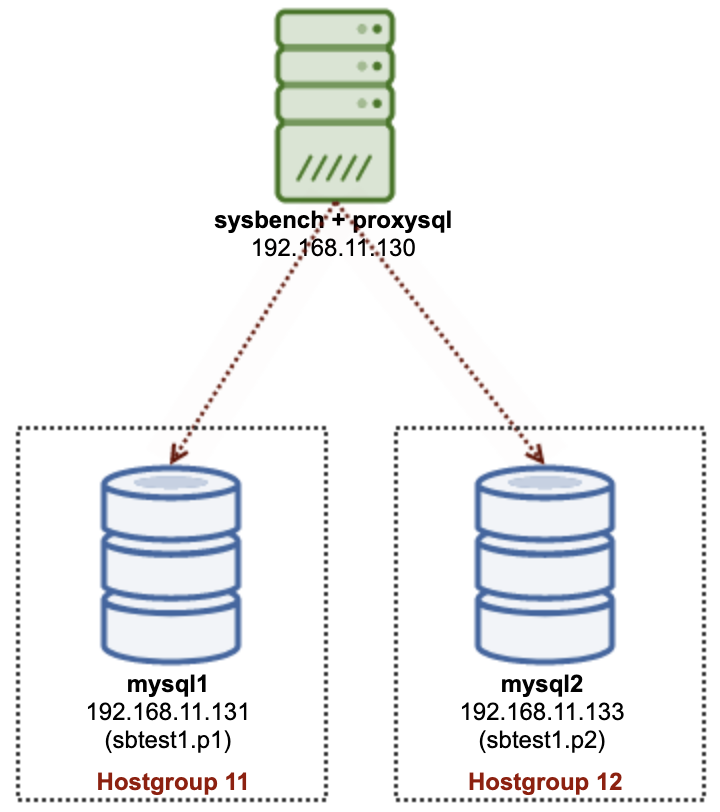
We are going to deploy 2 independent MySQL nodes – mysql1 and mysql2. The sbtest1 table will be partitioned on these two nodes and we will call this partition + host combination a shard. Sysbench is running remotely on the third server, mimicking the application tier. Since Sysbench is not partition-aware, we need to have a database driver or router to route the database queries to the right shard. We will use ProxySQL to achieve this purpose.
Let’s create another new database called sbtest3 for this purpose:
mysql> CREATE SCHEMA sbtest3;
mysql> USE sbtest3;Grant the right privileges to the sbtest database user:
mysql> CREATE USER 'sbtest'@'%' IDENTIFIED BY 'passw0rd';
mysql> GRANT ALL PRIVILEGES ON sbtest3.* TO 'sbtest'@'%';On mysql1, create the first partition of the table:
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p1 VALUES LESS THAN (499999)
);Unlike standalone partitioning, we only define the condition for partition p1 in the table to store all rows with column “k” values ranging from 0 to 499,999.
On mysql2, create another partitioned table:
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p2 VALUES LESS THAN MAXVALUE
);On the second server, it should hold the data of the second partition by storing the remaining of the anticipated values of column “k”.
Our table structure is now ready to be populated with test data.
Before we can run the Sysbench insert-only operation, we need to install a ProxySQL server as the query router and act as the gateway for our MySQL shards. Multi-server sharding requires database connections coming from the applications to be routed to the correct shard. Otherwise, you would see the following error:
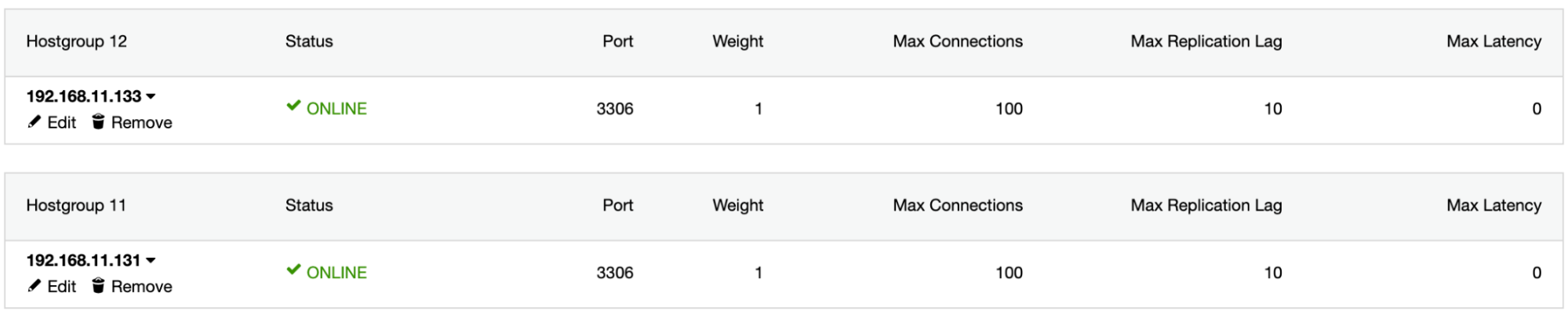
1526 (Table has no partition for value 503599)Install ProxySQL using ClusterControl, add the sbtest database user into ProxySQL, add both MySQL servers into the ProxySQL and configure mysql1 as hostgroup 11 and mysql2 as hostgroup 12:
Next, we need to work on how the query should be routed. A sample of INSERT query that will be performed by Sysbench will look something like this:
INSERT INTO sbtest1 (id, k, c, pad)
VALUES (0, 503502, '88816935247-23939908973-66486617366-05744537902-39238746973-63226063145-55370375476-52424898049-93208870738-99260097520', '36669559817-75903498871-26800752374-15613997245-76119597989')So we are going to use the following regular expression to filter the INSERT query for “k” => 500000, to meet the partitioning condition:
^INSERT INTO sbtest1 (id, k, c, pad) VALUES ([0-9]d*, ([5-9]{1,}[0-9]{5}|[1-9]{1,}[0-9]{6,}).*The above expression simply tries to filter the following:
-
[0-9]d* – We are expecting an auto-increment integer here, thus, we match against any integer.
-
[5-9]{1,}[0-9]{5} – The value matches any integer from 5 as the first digit, and 0-9 on the last 5 digits, to match the range value from 500,000 to 999,999.
-
[1-9]{1,}[0-9]{6,} – The value matches any integer from 1-9 as the first digit, and 0-9 on the last 6 or bigger digits, to match the value from 1,000,000 and bigger.
We will create two similar query rules. The first query rule is the negation of the above regular expression. We give this rule ID 51 and the destination hostgroup should be hostgroup 11 to match column “k” < 500,000 and forward the queries to the first partition. It should look like this:
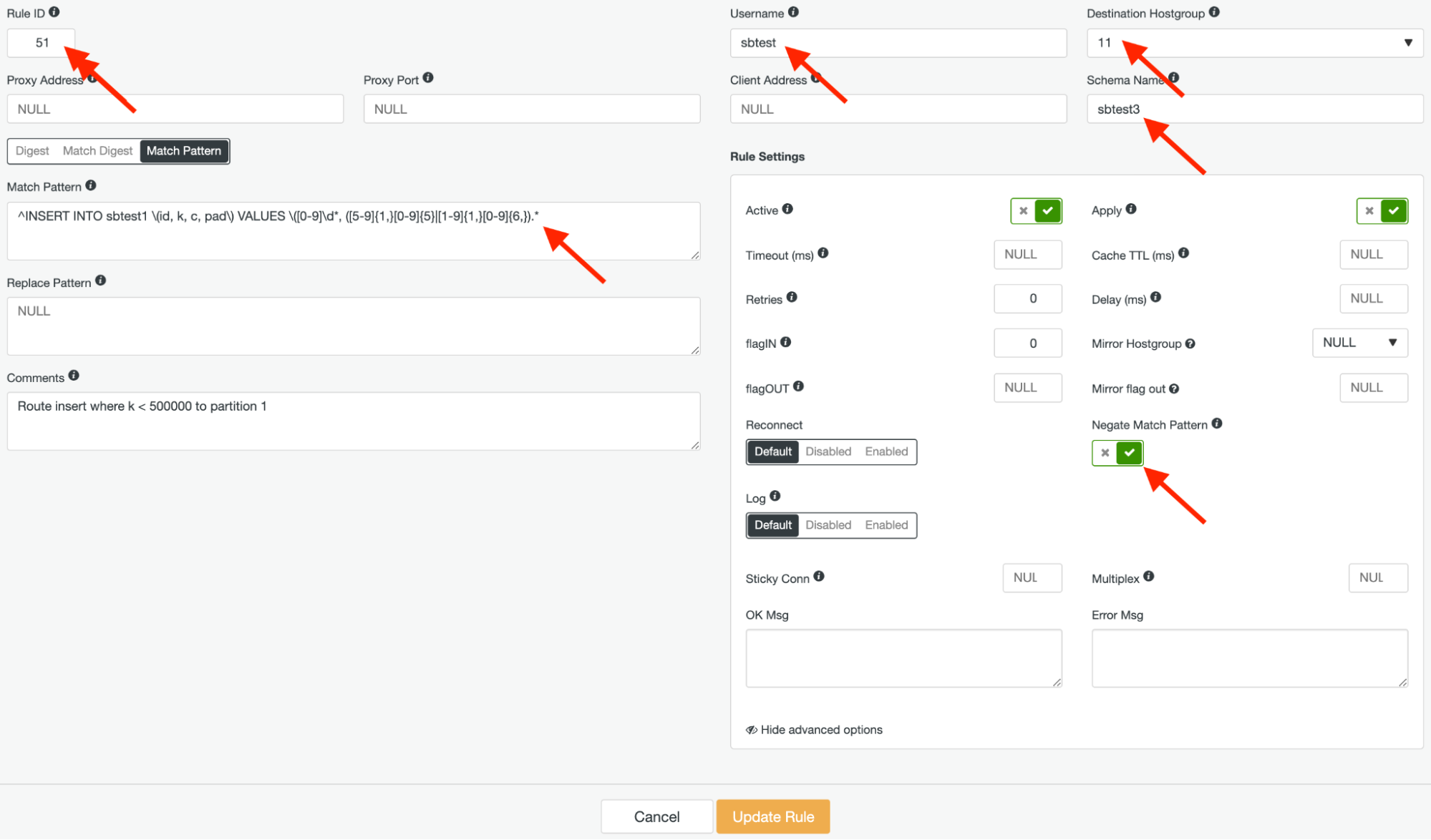
Pay attention to the “Negate Match Pattern” in the above screenshot. That option is critical for the proper routing of this query rule.
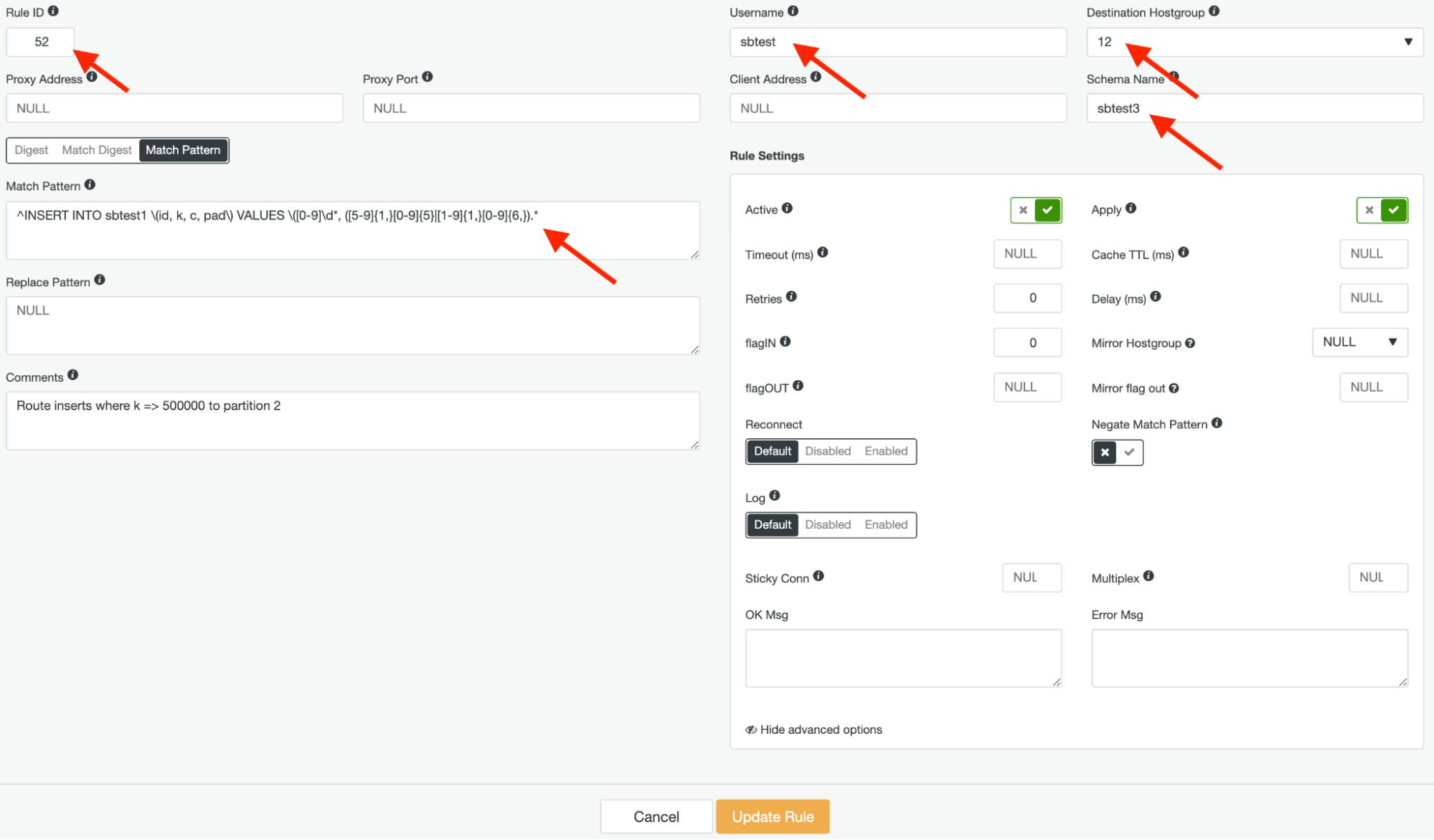
Next, create another query rule with rule ID 52, using the same regular expression and the destination hostgroup should be 12, but this time, leave the “Negate Match Pattern” as false, as shown below:
We can then start an insert-only operation using Sysbench to generate test data. The MySQL access-related information should be the ProxySQL host (192.168.11.130 on port 6033):
$ sysbench
/usr/share/sysbench/oltp_insert.lua
--report-interval=2
--threads=4
--rate=20
--time=9999
--db-driver=mysql
--mysql-host=192.168.11.130
--mysql-port=6033
--mysql-user=sbtest
--mysql-db=sbtest3
--mysql-password=passw0rd
--tables=1
--table-size=1000000
runIf you don’t see any error, it means ProxySQL has routed our queries to the correct shard/partition. You should see the query rule hits is increasing while the Sysbench process is running:
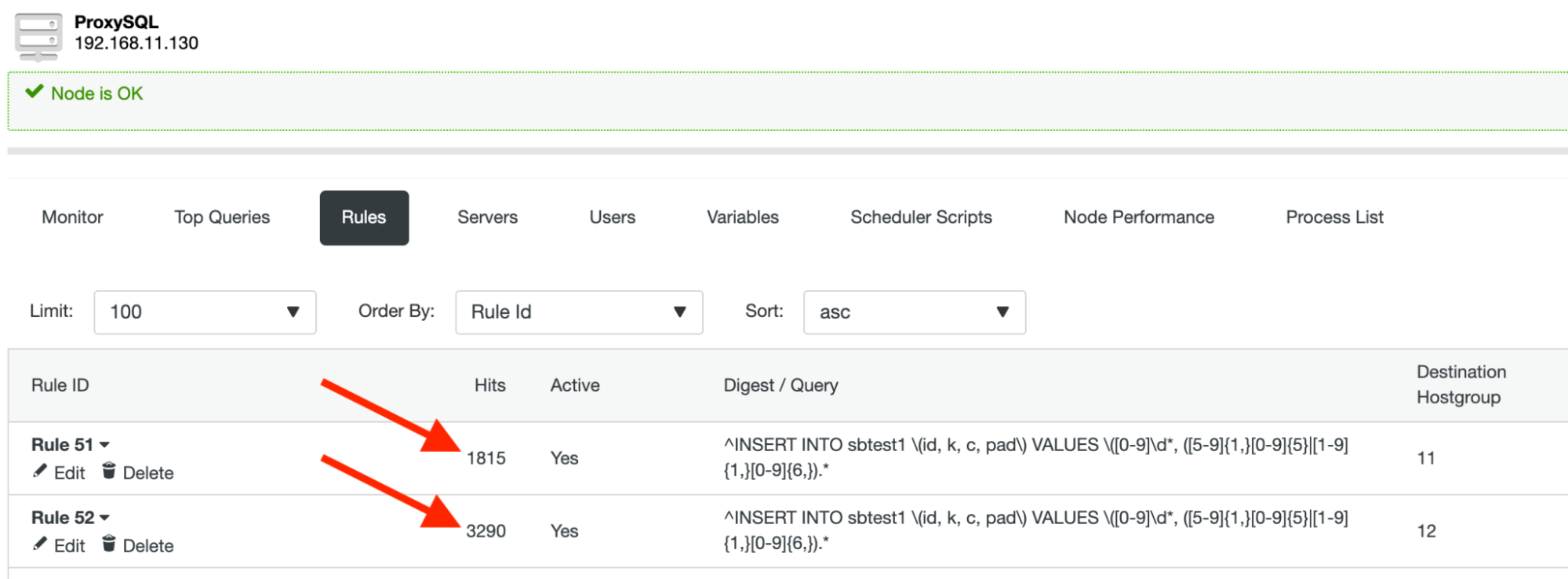
Under the Top Queries section, we can see the summary of the query routing:
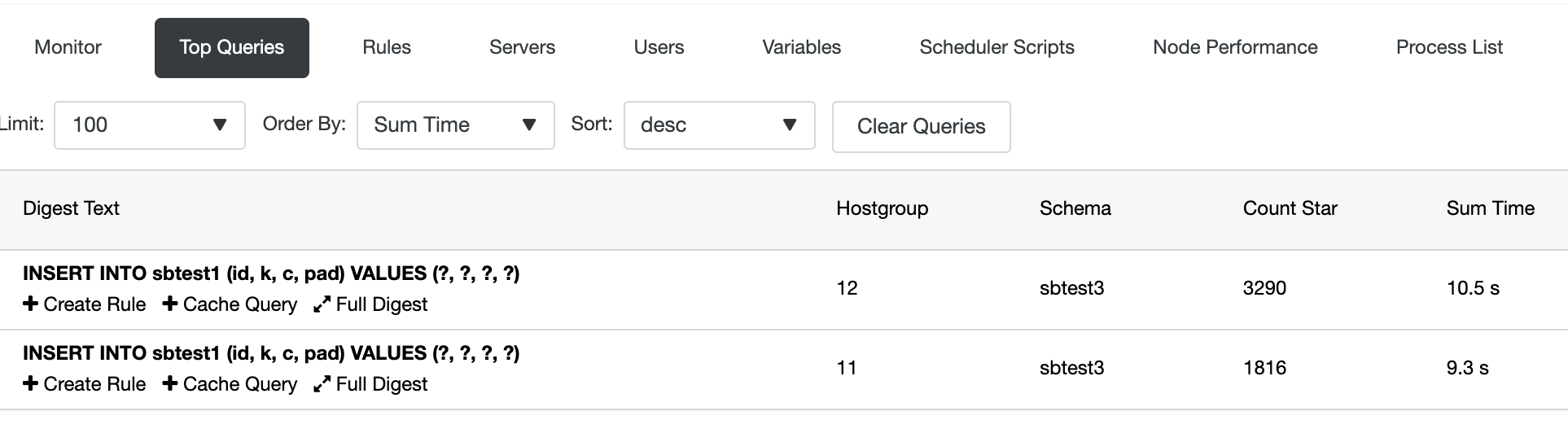
To double-check, login to mysql1 to look for the first partition and check the minimum and maximum value of column ‘k’ on table sbtest1:
mysql> USE sbtest3;
mysql> SELECT min(k), max(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 232185 | 499998 |
+--------+--------+Looks great. The maximum value of column “k” does not exceed the limit of 499,999. Let’s check the number of rows it stores for this partition:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest3'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest3 | sbtest1 | p1 | 1815 |
+--------------+------------+----------------+------------+Now let’s check the other MySQL server (mysql2):
mysql> USE sbtest3;
mysql> SELECT min(k), max(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 500003 | 794952 |
+--------+--------+Let’s check the number of rows it stores for this partition:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest3'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest3 | sbtest1 | p2 | 3247 |
+--------------+------------+----------------+------------+Superb! We have a sharded MySQL test setup with proper data partitioning using Sysbench for us to play around with. Happy benchmarking!



