blog
PostgreSQL Replication Best Practices – Part 1

Using replication for your PostgreSQL databases could be useful not only to have a high availability and fault tolerant environment but also to improve the performance on your system by balancing the traffic between the standby nodes. In this first part of the two-part blog, we are going to see some concepts related to the PostgreSQL replication.
Replications Methods in PostgreSQL
There are different methods for replicating data in PostgreSQL, but here we will focus on the two main methods: Streaming Replication and Logical Replication.
Streaming Replication
PostgreSQL Streaming Replication, the most common PostgreSQL Replication, is a physical replication that replicates the changes on a byte-by-byte level, creating an identical copy of the database in another server. It is based on the log shipping method. The WAL records are directly moved from one database server into another to be applied. We can say that it is a kind of continuous PITR.
This WAL transfer is performed in two different ways, by transferring WAL records one file (WAL segment) at a time (file-based log shipping) and by transferring WAL records (a WAL file is composed of WAL records) on the fly (record based log shipping), between a primary server and one or more than on standby servers, without waiting for the WAL file to be filled.
In practice, a process called WAL receiver, running on the standby server, will connect to the primary server using a TCP/IP connection. In the primary server, another process exists, named WAL sender, and is in charge of sending the WAL registries to the standby server as they happen.
A basic streaming replication can be represented as following:
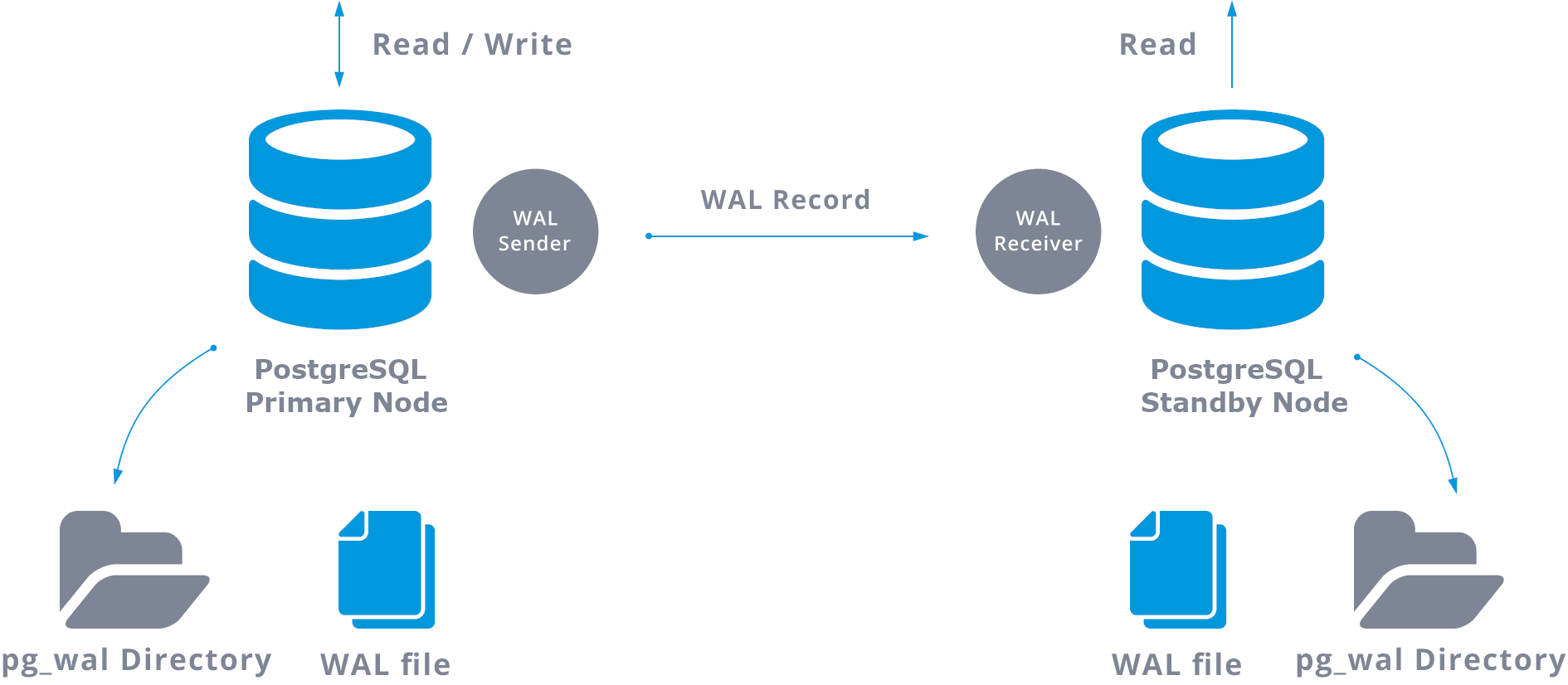
When configuring streaming replication, you have the option to enable WAL archiving. This is not mandatory, but is extremely important for robust replication setup, as it is necessary to avoid the main server to recycle old WAL files that have not yet being applied to the standby server. If this occurs you will need to recreate the replica from scratch.
Logical Replication
PostgreSQL Logical Replication is a method of replicating data objects and their changes, based upon their replication identity (usually a primary key). It is based on a publish and subscribe mode, where one or more subscribers subscribe to one or more publications on a publisher node.
A publication is a set of changes generated from a table or a group of tables. The node where a publication is defined is referred to as publisher. A subscription is the downstream side of logical replication. The node where a subscription is defined is referred to as the subscriber, and it defines the connection to another database and set of publications (one or more) to which it wants to subscribe. Subscribers pull data from the publications they subscribe to.
Logical replication is built with an architecture similar to physical streaming replication. It is implemented by “walsender” and “apply” processes. The walsender process starts logical decoding of the WAL and loads the standard logical decoding plugin. The plugin transforms the changes read from WAL to the logical replication protocol and filters the data according to the publication specification. The data is then continuously transferred using the streaming replication protocol to the apply worker, which maps the data to local tables and applies the individual changes as they are received, in a correct transactional order.
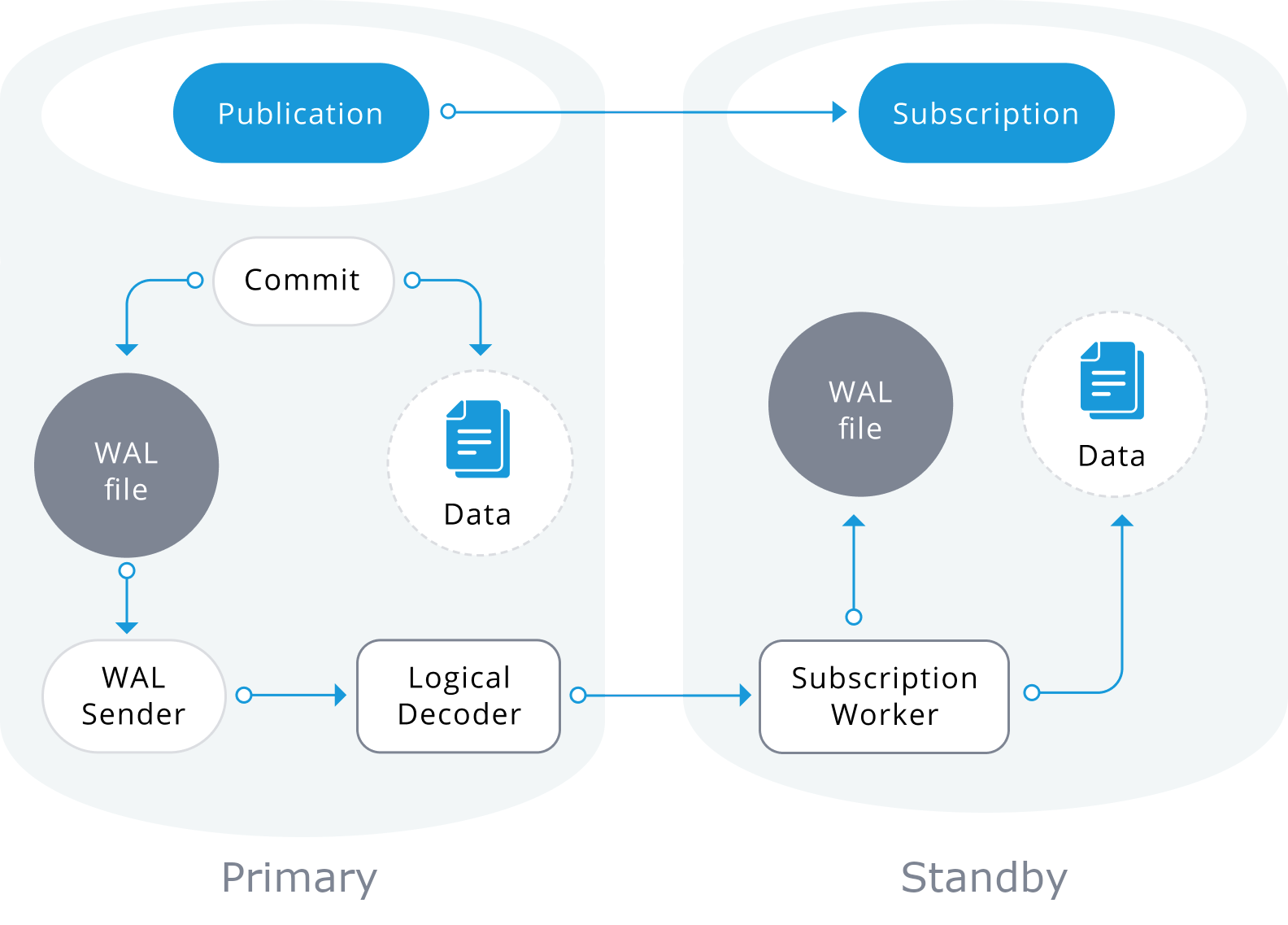
Logical replication starts by taking a snapshot of the data on the publisher database and copying that to the subscriber. The initial data in the existing subscribed tables are snapshotted and copied in a parallel instance of a special kind of apply process. This process will create its own temporary replication slot and copy the existing data. Once the existing data is copied, the worker enters synchronization mode, which ensures that the table is brought up to a synchronized state with the main apply process by streaming any changes that happened during the initial data copy using standard logical replication. Once the synchronization is done, the control of the replication of the table is given back to the main apply process where the replication continues as normal. The changes on the publisher are sent to the subscriber as they occur in real-time.
Replication Modes in PostgreSQL
The replication in PostgreSQL can be synchronous or asynchronous.
Asynchronous Replication
It is the default mode. Here it is possible to have some transactions committed in the primary node which have not yet been replicated to the standby server. This means there is the possibility of some potential data loss. This delay in the commit process is supposed to be very small if the standby server is powerful enough to keep up with the load. If this small data loss risk is not acceptable in the company, you can use synchronous replication instead.
Synchronous Replication
Each commit of a write transaction will wait until the confirmation that the commit has been written to the write-ahead log on disk of both the primary and standby server. This method minimizes the possibility of data loss. For data loss to occur you would need both the primary and the standby to fail at the same time.
The disadvantage of this method is the same for all synchronous methods as with this method the response time for each write transaction increases. This is due to the need to wait until all the confirmations that the transaction was committed. Luckily, read-only transactions will not be affected by this but; only the write transactions.
High Availability for PostgreSQL Replication
High availability is a requirement for many systems, no matter what technology we use, and there are different approaches to achieve this using different tools.
Load Balancing
Load balancers are tools that can be used to manage the traffic from your application to get the most out of your database architecture. Not only is it useful for balancing the load of our databases, it also helps applications get redirected to the available/healthy nodes and even specify ports with different roles.
HAProxy is a load balancer that distributes traffic from one origin to one or more destinations and can define specific rules and/or protocols for this task. If any of the destinations stops responding, it is marked as offline, and the traffic is sent to the rest of the available destinations. Having only one Load Balancer node will generate a Single Point of Failure, so to avoid this, you should deploy at least two HAProxy nodes and configure Keepalived between them.
Keepalived is a service that allows us to configure a virtual IP within an active/passive group of servers. This virtual IP is assigned to an active server. If this server fails, the IP is automatically migrated to the “Secondary” passive server, allowing it to continue working with the same IP in a transparent way for the systems.
Improving Performance On PostgreSQL Replication
Performance is always important in any system. You will need to make good use of the available resources to ensure the best response time possible and there are different ways to do this. Every connection to a database consumes resources so one of the ways to improve performance on your PostgreSQL database is by having a good connection pooler between your application and the database servers.
Connection Poolers
A connection pooling is a method of creating a pool of connections and reuse them, avoiding opening new connections to the database all the time, which will increase the performance of your applications considerably. PgBouncer is a popular connection pooler designed for PostgreSQL.
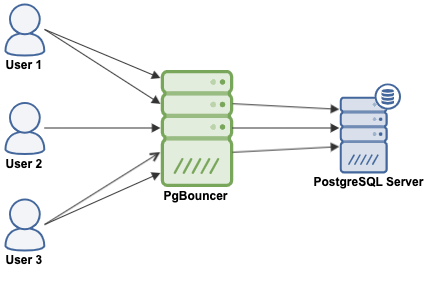
PgBouncer acts as a PostgreSQL server, so you just need to access your database using the PgBouncer information (IP Address/Hostname and Port), and PgBouncer will create a connection to the PostgreSQL server, or it will reuse one if it exists.
When PgBouncer receives a connection, it performs the authentication, which depends on the method specified in the configuration file. PgBouncer supports all the authentication mechanisms that the PostgreSQL server supports. After this, PgBouncer checks for a cached connection, with the same username+database combination. If a cached connection is found, it returns the connection to the client, if not, it creates a new connection. Depending on the PgBouncer configuration and the number of active connections, it could be possible that the new connection is queued until it can be created, or even aborted.
With all these mentioned concepts, in the second part of this blog, we will see how you can combine them to have a good replication environment in PostgreSQL.



