blog
pg_restore Alternatives – PostgreSQL Backup and Automatic Recovery with ClusterControl

While there are various ways to recover your PostgreSQL database, one of the most convenient approaches to restore your data from a logical backup. Logical backups play a significant role for Disaster and Recovery Planning (DRP). Logical backups are backups taken, for example using pg_dump or pg_dumpall, which generate SQL statements to obtain all table data that is written to a binary file.
It is also recommended to run periodic logical backups in case your physical backups fail or are unavailable. For PostgreSQL, restoring can be problematic if you are unsure of what tools to use. The backup tool pg_dump is commonly paired with the restoration tool pg_restore.
pg_dump and pg_restore act in tandem if disaster occurs and you need to recover your data. While they serve the primary purpose of dump and restore, it does require you to perform some extra tasks when you need to recover your cluster and do a failover (if your active primary or master dies due to hardware failure or VM system corruption). You’ll end up to find and utilize third party tools which can handle failover or automatic cluster recovery.
In this blog, we’ll take a look at how pg_restore works and compare it to how ClusterControl handles backup and restore of your data in case disaster happens.
Mechanisms of pg_restore
pg_restore is useful when obtaining the following tasks:
- paired with pg_dump for generating SQL generated files containing data, access roles, database and table definitions
- restore a PostgreSQL database from an archive created by pg_dump in one of the non-plain-text formats.
- It will issue the commands necessary to reconstruct the database to the state it was in at the time it was saved.
- has the capability to be selective or even to reorder the items prior to being restored based on the archive file
- The archive files are designed to be portable across architectures.
- pg_restore can operate in two modes.
- If a database name is specified, pg_restore connects to that database and restores archive contents directly into the database.
- or, a script containing the SQL commands necessary to rebuild the database is created and written to a file or standard output. Its script output has equivalence to the format generated by pg_dump
- Some of the options controlling the output are therefore analogous to pg_dump options.
Once you have restored the data, it’s best and advisable to run ANALYZE on each restored table so the optimizer has useful statistics. Although it acquires READ LOCK, you might have to run this during a low traffic or during your maintenance period.
Advantages of pg_restore
pg_dump and pg_restore in tandem has capabilities which are convenient for a DBA to utilize.
- pg_dump and pg_restore has the capability to run in parallel by specifying the -j option. Using the -j/–jobs
allows you to specify how many running jobs in parallel can run especially for loading data, creating indexes, or create constraints using multiple concurrent jobs. - It’s quiet handy to use, you can selectively dump or load specific database or tables
- It allows and provides a user flexibility on what particular database, schema, or reorder the procedures to be executed based on the list. You can even generate and load the sequence of SQL loosely like prevent acls or privilege in accordance to your needs. There are plenty of options to suit your needs.
- It provides you capability to generate SQL files just like pg_dump from an archive. This is very convenient if you want to load to another database or host to provision a separate environment.
- It’s easy to understand based on the generated sequence of SQL procedures.
- It’s a convenient way to load data in a replication environment. You don’t need your replica to be restaged since the statements are SQL which were replicated down to the standby and recovery nodes.
Limitations of pg_restore
For logical backups, the obvious limitations of pg_restore along with pg_dump is the performance and speed when utilizing the tools. It might be handy when you want to provision a test or development database environment and load your data, but it’s not applicable when your data set is huge. PostgreSQL has to dump your data one by one or execute and apply your data sequentially by the database engine. Although you can make this loosely flexible to speed up like specifying -j or using –single-transaction to avoid impact to your database, loading using SQL still has to be parsed by the engine.
Additionally, the PostgreSQL documentation states the following limitations, with our additions as we observed these tools (pg_dump and pg_restore):
- When restoring data to a pre-existing table and the option –disable-triggers is used, pg_restore emits commands to disable triggers on user tables before inserting the data, then emits commands to re-enable them after the data has been inserted. If the restore is stopped in the middle, the system catalogs might be left in the wrong state.
- pg_restore cannot restore large objects selectively; for instance, only those for a specific table. If an archive contains large objects, then all large objects will be restored, or none of them if they are excluded via -L, -t, or other options.
- Both tools are expected to generate a huge amount of size (files, directory, or tar archive) especially for a huge database.
- For pg_dump, when dumping a single table or as plain text, pg_dump does not handle large objects. Large objects must be dumped with the entire database using one of the non-text archive formats.
- If you have tar archives generated by these tools, take note that tar archives are limited to a size less than 8 GB. This is an inherent limitation of the tar file format. Therefore this format cannot be used if the textual representation of a table exceeds that size. The total size of a tar archive and any of the other output formats is not limited, except possibly by the operating system.
Using pg_restore
Using pg_restore is quite handy and easy to utilize. Since it is paired in tandem with pg_dump, both these tools work sufficiently well as long as the target output suits the other. For example, the following pg_dump won’t be useful for pg_restore,
[root@testnode14 ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: This result will be a psql compatible which looks like as follows:
[root@testnode14 ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;But this will fail for pg_restore as there’s no plain format to follow:
[root@testnode14 ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[root@testnode14 ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerNow, let’s go to more useful terms for pg_restore.
pg_restore: Drop and Restore
Consider a simple usage of pg_restore which you have drop a database, e.g.
postgres=# drop database maxtest;
DROP DATABASE
postgres=# l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)Restoring it with pg_restore it very simple,
[root@testnode14 ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump The -C/–create here states that create the database once it’s encountered in the header. The -d postgres points to the postgres database but it doesn’t mean it will create the tables to postgres database. It requires that the database has to exist. If -C is not specified, table(s) and records will be stored to that database referenced with -d argument.
Restoring Selectively By Table
Restoring a table with pg_restore is easy and simple. For example, you have two tables namely “b” and “d” tables. Let’s say you run the following pg_dump command below,
[root@testnode14 ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:Where the contents of this directory will look like as follows,
[root@testnode14 ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..If you want to restore a table (namely “d” in this example),
[root@testnode14 ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/Shall have,
paultest=# dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore: Copying Database Tables to a Different Database
You may even copy the contents of your existing database and have it on your target database. For example, I have the following databases,
paultest=# l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)The paultest database is an empty database while we’re going to copy what’s inside maxtest database,
maxtest=# dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)To copy it, we need to dump the data from maxtest database as follows,
[root@testnode14 ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: Then load or restore it as follows,
Now, we got data on paultest database and the tables have been stored accordingly.
postgres=# l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Generate a SQL file With Re-ordering
I have seen a lot of usage with pg_restore but it seems that this feature is not usually showcased. I found this approach very interesting as it allows you to order based on what you don’t want to include and then generate an SQL file from the order you want to proceed.
For example, we’ll use the sample pgdump_data.tar we have generated earlier and create a list. To do this, run the following command:
[root@testnode14 ~]# pg_restore -l pgdump_data.tar > my.listThis will generate a file as shown below:
[root@testnode14 ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresNow, let’s re-order it or shall we say I have removed the creation of SEQUENCE and also the creation of the constraint. This would look like as follows,
To generate the file in SQL format, just do the following:
[root@testnode14 ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar Now, the file /tmp/selective_data.out will be a SQL generated file and this is readable if you use psql, but not pg_restore. What's great about this is you can generate an SQL file in accordance to your template on which data only can be restored from an existing archive or backup taken using pg_dump with the help of pg_restore.
PostgreSQL Restore with ClusterControl
ClusterControl does not utilize pg_restore or pg_dump as part of it’s featureset. We use pg_dumpall to generate logical backups and, unfortunately, the output is not compatible with pg_restore.
There are several other ways to generate a backup in PostgreSQL as seen below.
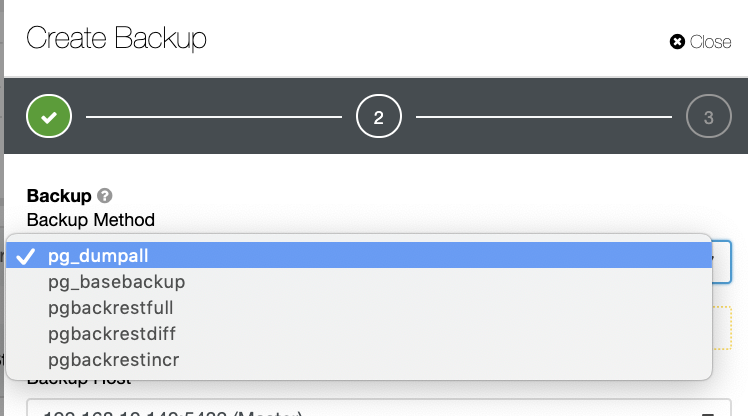
There's no such mechanism where you can selectively store a table, a database, or copy from one database to another database.
ClusterControl does support Point-in-Time Recovery (PITR), but this doesn't allow you to manage data restore as flexible as with pg_restore. For all the list of backup methods, only pg_basebackup and pgbackrest are PITR capable.
How ClusterControl handles restore is that it has the capability to recover a failed cluster as long as Auto Recovery is enabled as shown below.

Once the master fails, the slave can automatically recover the cluster as ClusterControl performs the failover (which is done automatically). For the data recovery part, your only option is to have a cluster-wide recovery which means it's coming from a full backup. There's no capability to selectively restore on the target database or table you only wanted to restore. If you want to do that, restore the full backup, it's easy to do this with ClusterControl. You can go to the Backup tabs just as shown below,
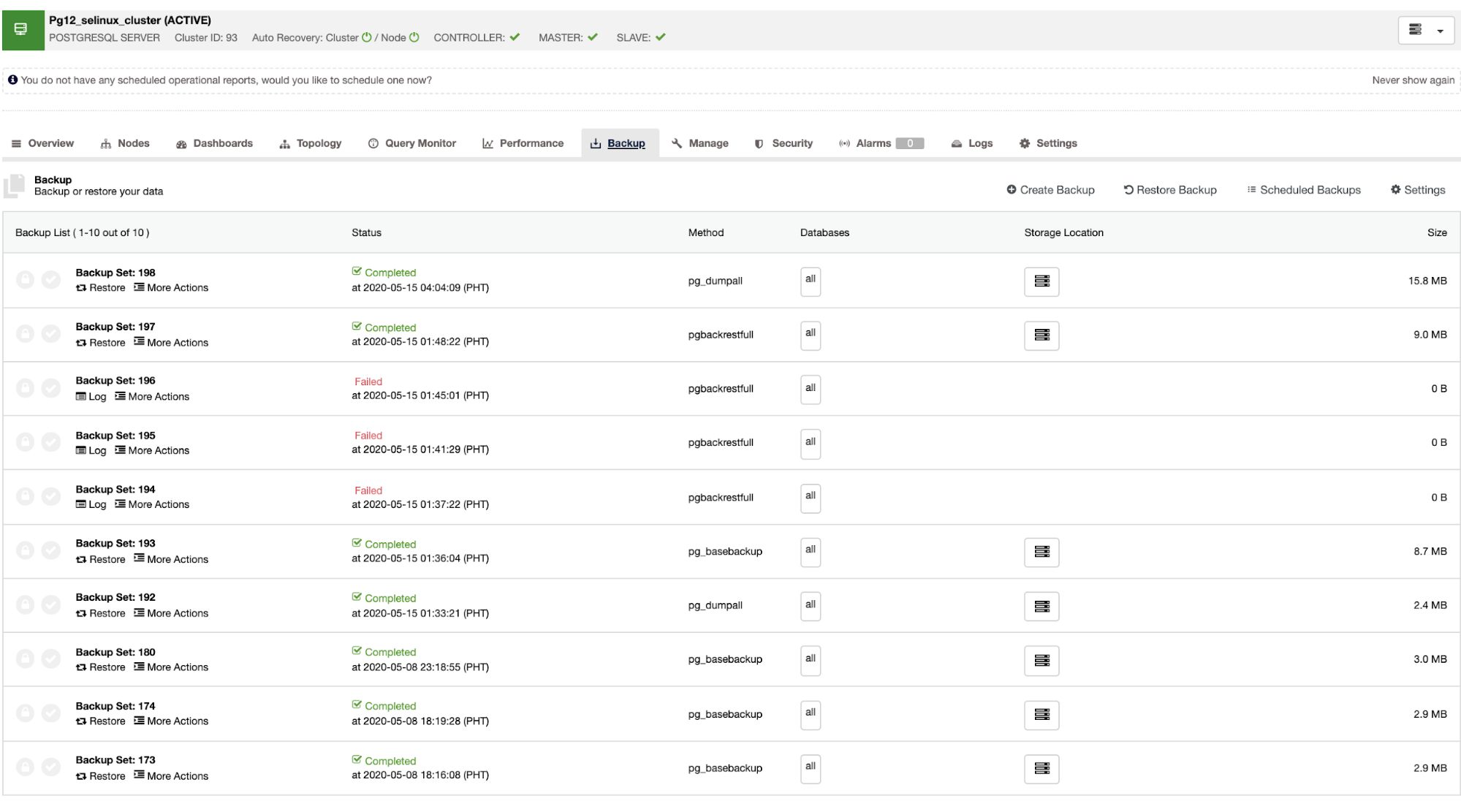
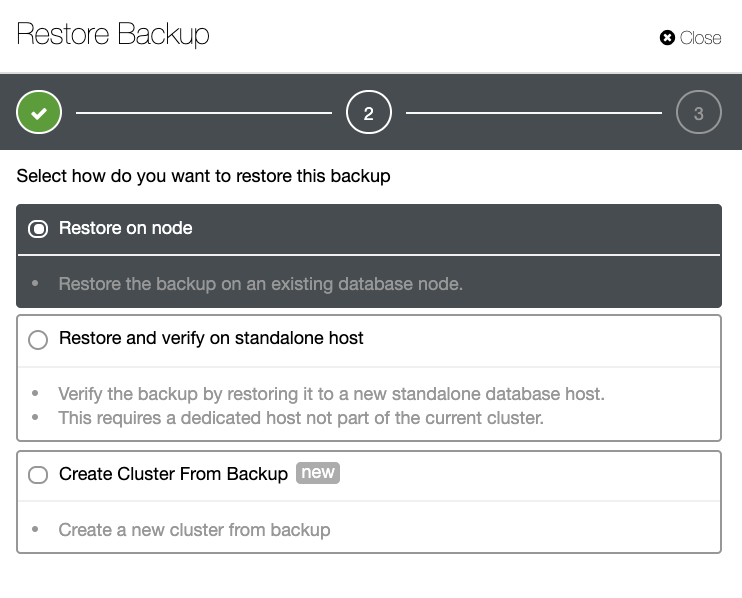
You'll have a full list of successful and failed backups. Then restoring it can be done by choosing the target backup and clicking the "Restore" button. This will allow you to restore on an existing node registered within ClusterControl, or verify on a stand alone node, or create a cluster from the backup.
Conclusion
Using pg_dump and pg_restore simplifies the backup/dump and restore approach. However, for a large-scale database environment, this might not be an ideal component for disaster recovery. For a minimal selection and restoring procedure, using the combination of pg_dump and pg_restore provides you the power to dump and load your data according to your needs.
For production environments (especially for enterprise architectures) you might use the ClusterControl approach to create a backup and restore with automatic recovery.
A combination of approaches is also a good approach. This helps you lower your RTO and RPO and at the same time leverage on the most flexible way to restore your data when needed.



