blog
Logical Replication Partitioning With PostgreSQL 13

Every PostgreSQL release comes with few major feature enhancements, but what is equally interesting is that every release improves upon its past features as well.
As PostgreSQL 13 is scheduled to be released soon, it’s time to check what features and improvements the community is bringing us. One such no-noise improvement is the “Logical replication improvement for partitioning.”
Let’s understand this feature improvement with a running example.
Terminology
Two terms which are important to understand this feature are:
- Partition tables
- Logical Replication
Partition Tables
A way to split a large table into multiple physical pieces to achieved benefits like:
- Improved query performance
- Faster updates
- Faster bulk loads and deletes
- Organizing seldom used data on slow disk drives
Some of these advantages are achieved by way of partition pruning (i.e. query planner using partition definition to decide whether to scan a partition or not) and the fact that a partition is rather easier to fit in finite memory as compared to a huge table.
A table is partitioned on the basis of:
- List
- Hash
- Range

Logical Replication
As the name implies, this is a replication method in which data is replicated incrementally based on their identity (e.g. key). It is not similar to WAL or physical replication methods where data is sent byte-by-byte.
Based on a Publisher-Subscriber pattern, the source of the data needs to define a publisher while the target needs to be registered as a subscriber. The interesting use cases for this are:
- Selective replication (only some part of database)
- Simultaneous writes to two instances of database where data is getting replicated
- Replication between different operating systems (e.g. Linux and Windows)
- Fine grained security on replication of data
- Triggers execution as data arrive on the receiver side
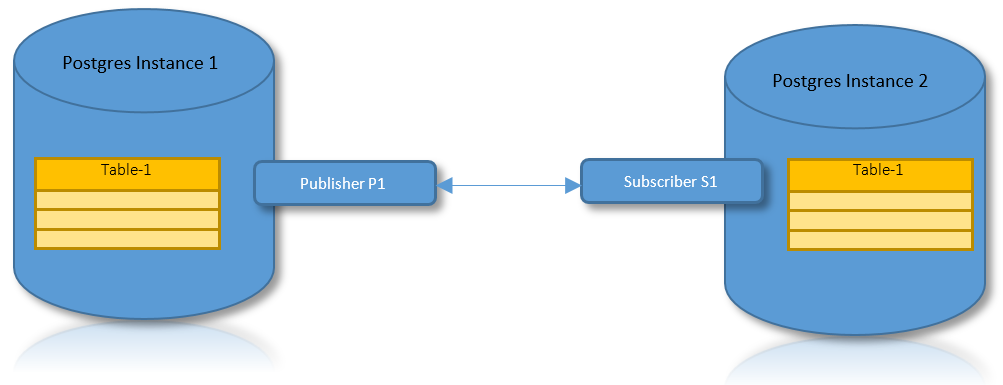
Logical Replication for Partitions
With the benefits of both logical replication and partitioning, it is a practical use case to have a scenario where a partitioned table needs to be replicated across two PostgreSQL instances.
Following are the steps to establish and highlight the improvement being done in PostgreSQL 13 in this context.
Setup
Consider a two node setup for running two different instances containing partitioned table:
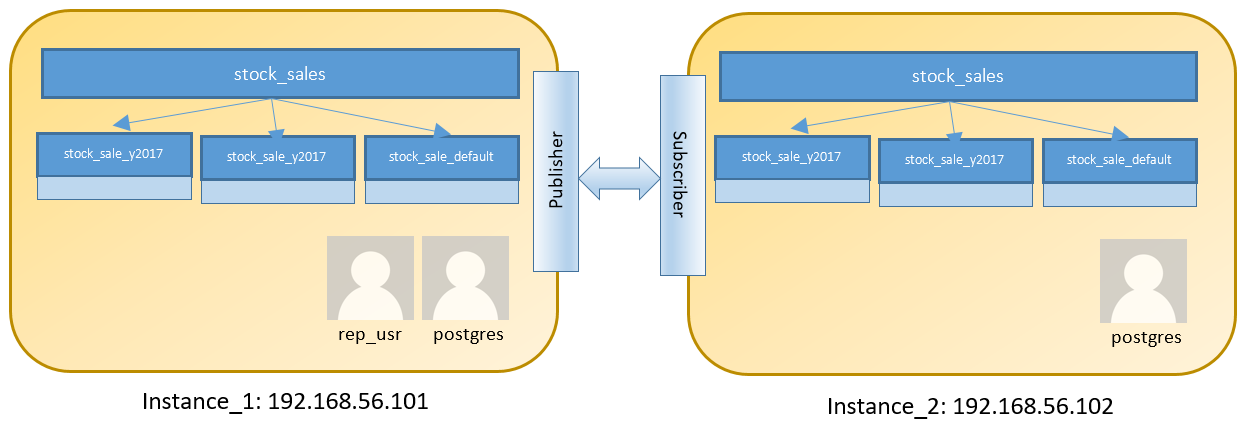
Steps on Instance_1 are as below post login on 192.168.56.101 as postgres user:
$ initdb -D ${HOME}/pgdata-1
$ echo "listen_addresses = '192.168.56.101'" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "wal_level = logical" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "host postgres all 192.168.56.102/32 md5" >> ${HOME}/pgdata-1/pg_hba.conf
$ pg_ctl -D ${HOME}/pgdata-1 -l logfile startSetting ‘wal_level’ is set specifically to ‘logical’ to indicate that logical replication will be used to replicate data from this instance. Configuration file ‘pg_hba.conf’ has also been modified to allow connections from 192.168.56.102.
# CREATE TABLE stock_sales
( sale_date date not null, unit_sold int, unit_price int )
PARTITION BY RANGE ( sale_date );
# CREATE TABLE stock_sales_y2017 PARTITION OF stock_sales
FOR VALUES FROM ('2017-01-01') TO ('2018-01-01');
# CREATE TABLE stock_sales_y2018 PARTITION OF stock_sales
FOR VALUES FROM ('2018-01-01') TO ('2019-01-01');
# CREATE TABLE stock_sales_default
PARTITION OF stock_sales DEFAULT;Although the postgres role is created by default on the Instance_1 database, a separate user should also be created who has limited access – which restricts the scope only for a given table.
# CREATE ROLE rep_usr WITH REPLICATION LOGIN PASSWORD 'rep_pwd';
# GRANT CONNECT ON DATABASE postgres TO rep_usr;
# GRANT USAGE ON SCHEMA public TO rep_usr;
# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep_usr;Almost similar setup is required on Instance_2
$ initdb -D ${HOME}/pgdata-2
$ echo "listen_addresses = '192.168.56.102'" >> ${HOME}/pgdata-2/postgresql.conf
$ pg_ctl -D ${HOME}/pgdata-2 -l logfile startIt should be noted that since Instance_2 will not be a source of data for any other node, wal_level settings as well as the pg_hba.conf file doesn’t need any extra settings. Needless to say, pg_hba.conf may need updating as per production needs.
Logical Replication doesn’t support DDL, we need to create a table structure on Instance_2 as well. Create a partitioned table using the partition creation above to create the same table structure on Instance_2 as well.
Logical Replication Setup
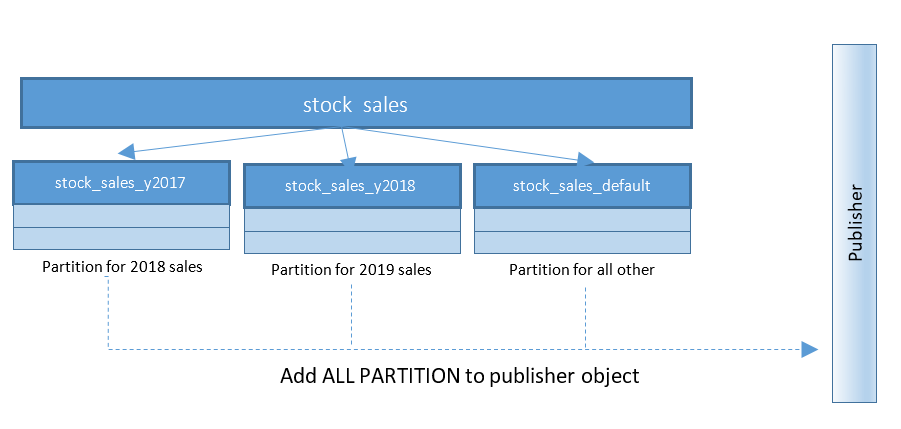
Logical replication setup becomes much easier with PostgreSQL 13. Up till PostgreSQL 12 the structure was like below:
With PostgreSQL 13, publication of partitions becomes much easier. Refer to the diagram below and compare with previous diagram:
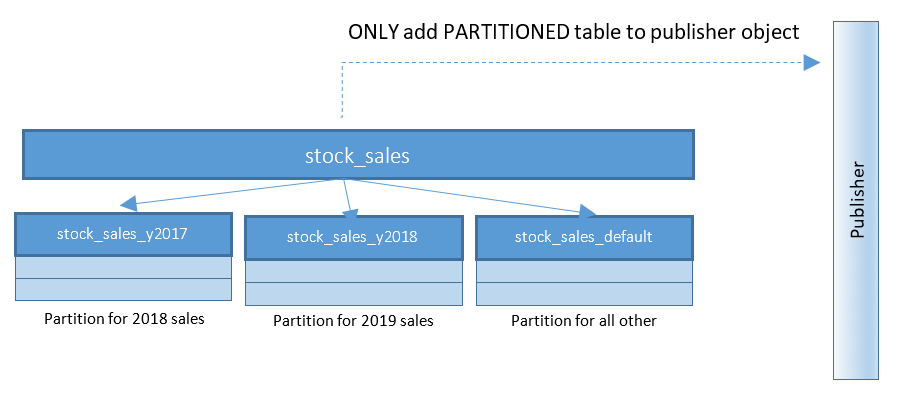
With setups raging with 100’s and 1000’s of partitioned tables – this small change simplifies things to a large extent.
In PostgreSQL 13, the statements to create such a publication will be:
CREATE PUBLICATION rep_part_pub FOR TABLE stock_sales
WITH (publish_via_partition_root);Configuration parameter publish_via_partition_root is new in PostgreSQL 13, which allows the recipient node to have a slightly different leaf hierarchy. Mere publication creation on partitioned tables in PostgreSQL 12, will return error statements like below:
ERROR: "stock_sales" is a partitioned table
DETAIL: Adding partitioned tables to publications is not supported.
HINT: You can add the table partitions individually.Ignoring the limitations of PostgreSQL 12, and proceeding with our hands on of this feature on PostgreSQL 13, we have to establish subscriber on Instance_2 with following statements:
CREATE SUBSCRIPTION rep_part_sub CONNECTION 'host=192.168.56.101 port=5432 user=rep_usr password=rep_pwd dbname=postgres' PUBLICATION rep_part_pub;Checking if it Really Works
We are pretty much done with the whole setup, but let’s run a couple of tests to see if things are working.
On the Instance_1, insert multiple rows ensuring that they spawn into multiple partitions:
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2017-09-20', 12, 151);# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2018-07-01', 22, 176);
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2016-02-02', 10, 1721);Check the data on Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721Now let’s check if logical replication works even if the leaf nodes are not the same on the recipient side.
Add another partition on Instance_1 and insert record:
# CREATE TABLE stock_sales_y2019
PARTITION OF stock_sales
FOR VALUES FROM ('2019-01-01') to ('2020-01-01');
# INSERT INTO stock_sales VALUES(‘2019-06-01’, 73, 174 );Check the data on Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721
2019-06-01 | 73 | 174Other Partitioning Features in PostgreSQL 13
There are also other improvements in PostgreSQL 13 which are related to partitioning, namely:
- Improvements in Join between partitioned tables
- Partitioned tables now support BEFORE row-level triggers
Conclusion
I will definitely check the aforementioned two upcoming features in my next set of blogs. Till then food for thought – with the combined power of partitioning and logical replication, is PostgreSQL sailing closer towards a master-master setup?



