blog
How to Control Replication Failover for MySQL and MariaDB

Automated failover is pretty much a must have for many applications – uptime is taken for granted. It’s quite hard to accept that an application is down for 20 or 30 minutes because someone has to be paged to log in and investigate the situation before taking action.
In the real world, replication setups tend to grow over time to become complex, sometimes messy. And there are constraints. For instance, not every node in a setup makes a good master candidate. Maybe the hardware differs and some of the replicas have less powerful hardware as they are dedicated to handle some specific types of the workload? Maybe you are in the middle of migration to a new MySQL version and some of the slaves have already been upgraded? You’d rather not have a master in more recent version replicating to old replicas, as this can break replication. If you have two datacenters, one active and one for disaster recovery, you may prefer to pick master candidates only in the active datacenter, to keep the master close to the application hosts. Those are just example situations, where you may find yourself in need of manual intervention during the failover process. Luckily, many failover tools have an option to take control of the process by using whitelists and blacklists. In this blog post, we’d like to show you some examples how you can influence ClusterControl’s algorithm for picking master candidates.
Whitelist and Blacklist Configuration
ClusterControl gives you an option to define both whitelist and blacklist of replicas. A whitelist is a list of replicas which are intended to become master candidates. If none of them are available (either because they are down, or there are errant transactions, or there are other obstacles that prevent any of them from being promoted), failover will not be performed. In this way, you can define which hosts are available to become a master candidate. Blacklists, on the other hand, define which replicas are not suitable to become a master candidate.
Both of those lists can be defined in the cmon configuration file for a given cluster. For example, if your cluster has id of ‘1’, you want to edit ‘/etc/cmon.d/cmon_1.cnf’. For whitelist you will use ‘replication_failover_whitelist’ variable, for blacklist it will be a ‘replication_failover_blacklist’. Both accept a comma separated list of ‘host:port’.
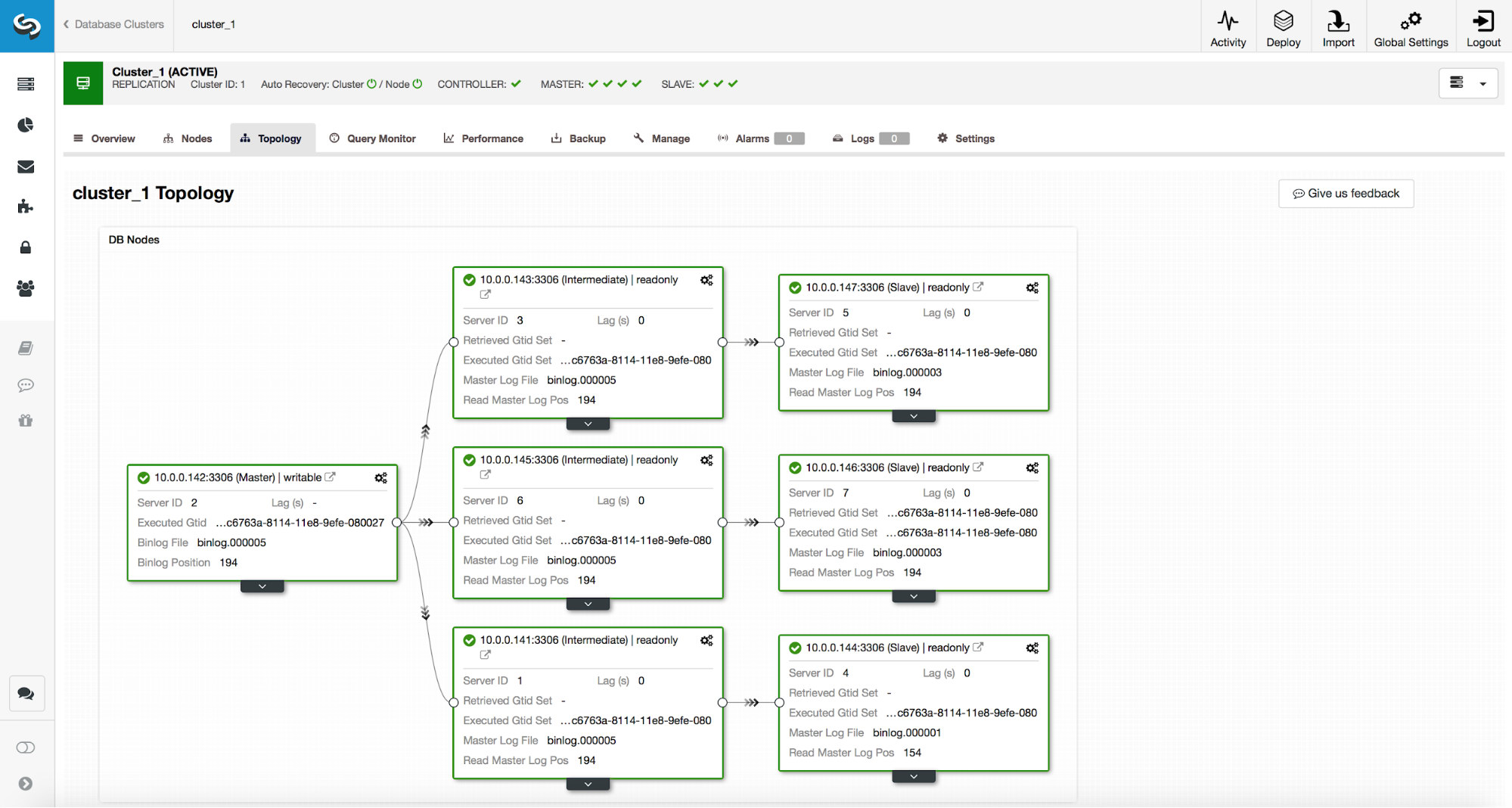
Let’s consider the following replication setup. We have an active master (10.0.0.141) which has two replicas (10.0.0.142 and 10.0.0.143), both act as intermediate masters and have one replica each (10.0.0.144 and 10.0.0.147). We also have a standby master in a separate datacenter (10.0.0.145) which has a replica (10.0.0.146). Those hosts are intended to be used in case of a disaster. Replicas 10.0.0.146 and 10.0.0.147 act as backup hosts. See below screenshot.
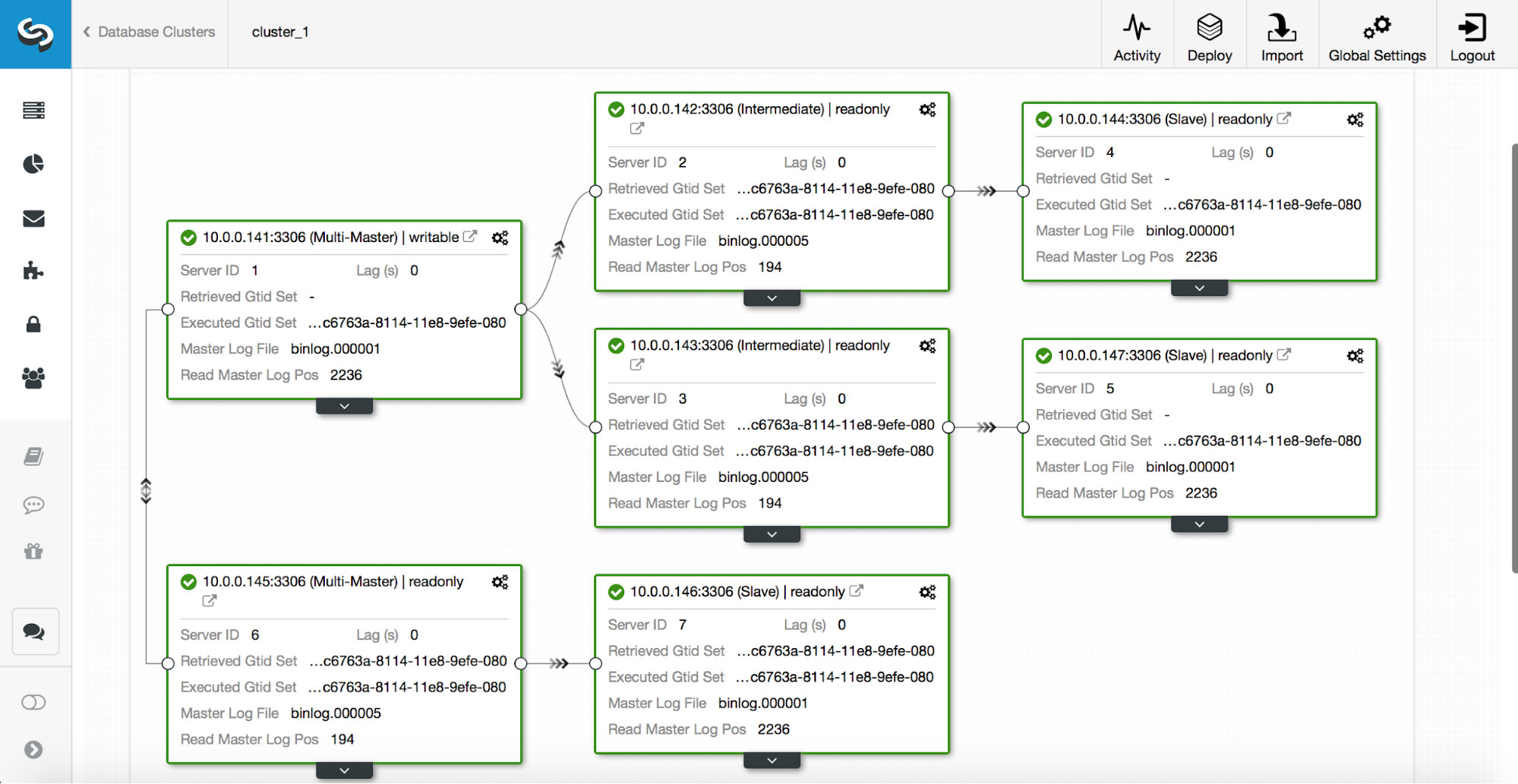
Given that the second datacenter is only intended for disaster recovery, we don’t want any of those hosts to be promoted as master. In the worst case scenario, we will take manual action. The second datacenter’s infrastructure is not scaled to the size of the production datacenter (there are three replicas less in the DR datacenter), so manual actions are needed anyway before we can promote a host in the DR datacenter. We also would not like for a backup replica (10.0.0.147) to be promoted. Neither we want a third replica in the chain to be picked up as a master (even though it could be done with GTID).
Whitelist Configuration
We can configure either whitelist or a blacklist to make sure that failover will be handled to our liking. In this particular setup, using whitelist may be more suitable – we will define which hosts can be used for failover and if someone adds a new host to the setup, it will not be taken under consideration as master candidate until someone will manually decide it is ok to use it and add it to the whitelist. If we used blacklist, adding a new replica somewhere in the chain could mean that such replica could theoretically be automatically used for failover unless someone explicitly says it cannot be used. Let’s stay on the safe side and define a whitelist in our cluster configuration file (in this case it is /etc/cmon.d/cmon_1.cnf as we have just one cluster):
replication_failover_whitelist=10.0.0.141:3306,10.0.0.142:3306,10.0.0.143:3306We have to make sure that the cmon process has been restarted to apply changes:
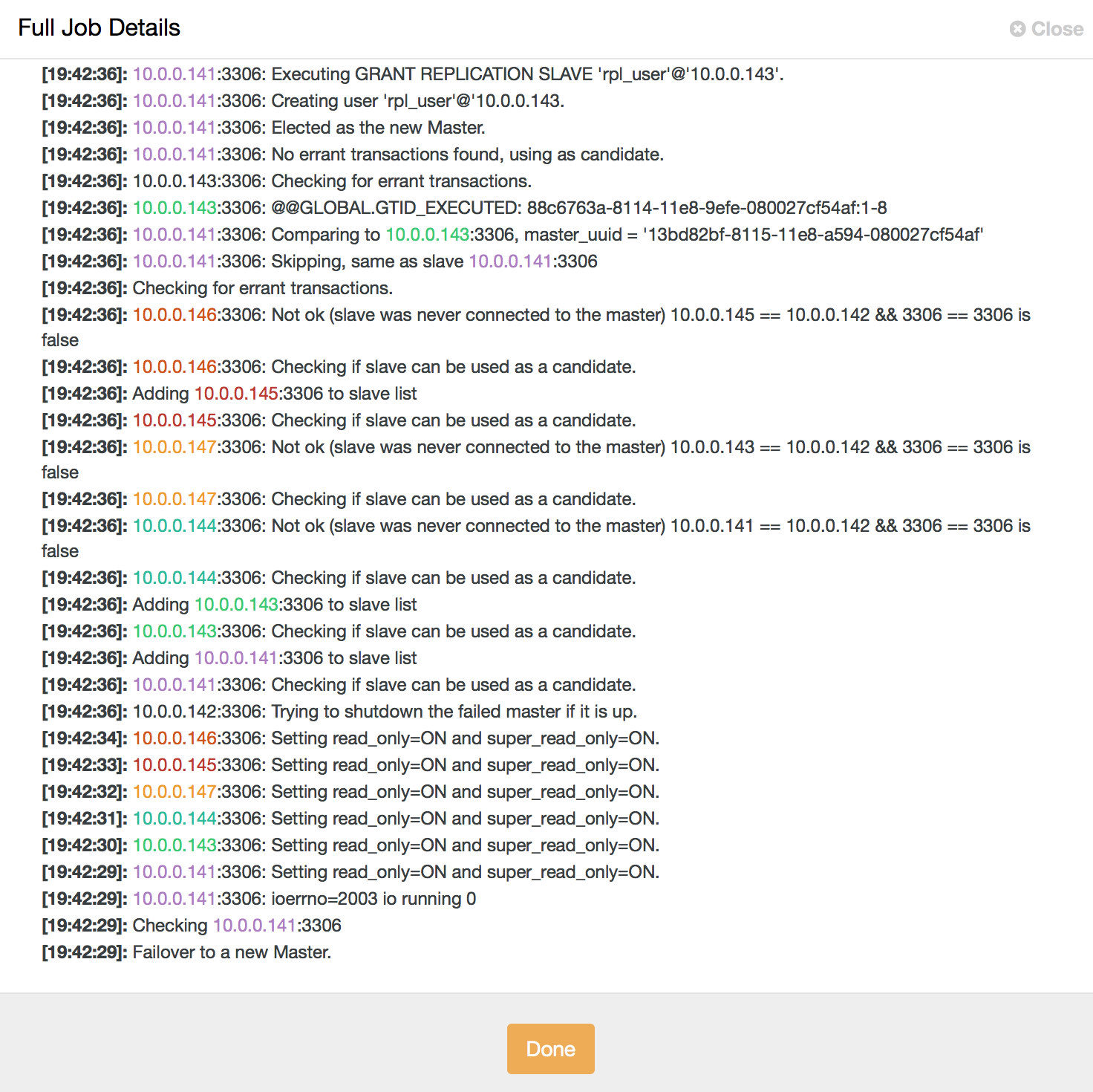
service cmon restartLet’s assume our master has crashed and cannot be reached by ClusterControl. A failover job will be initiated:
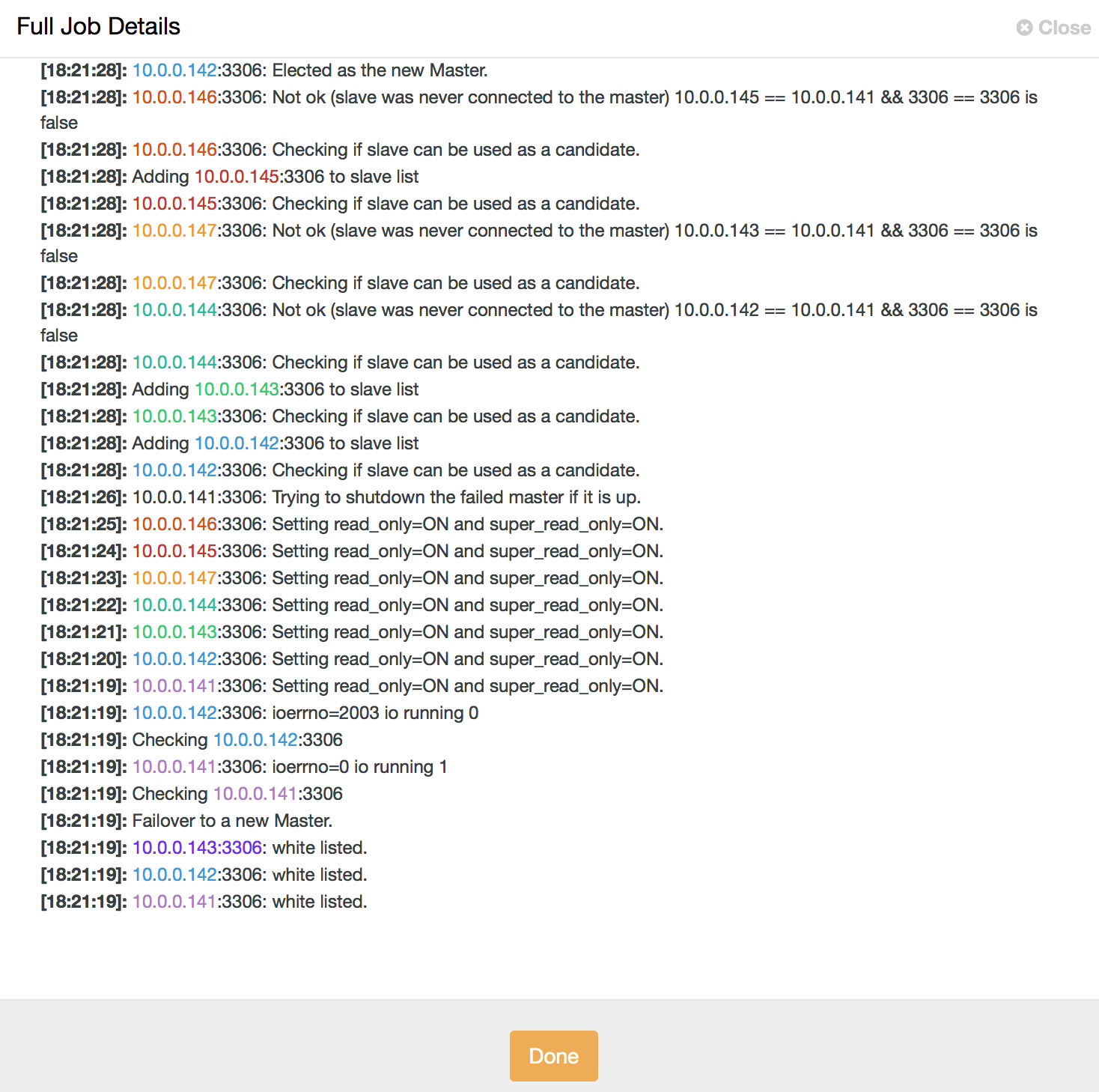
The topology will look like below:
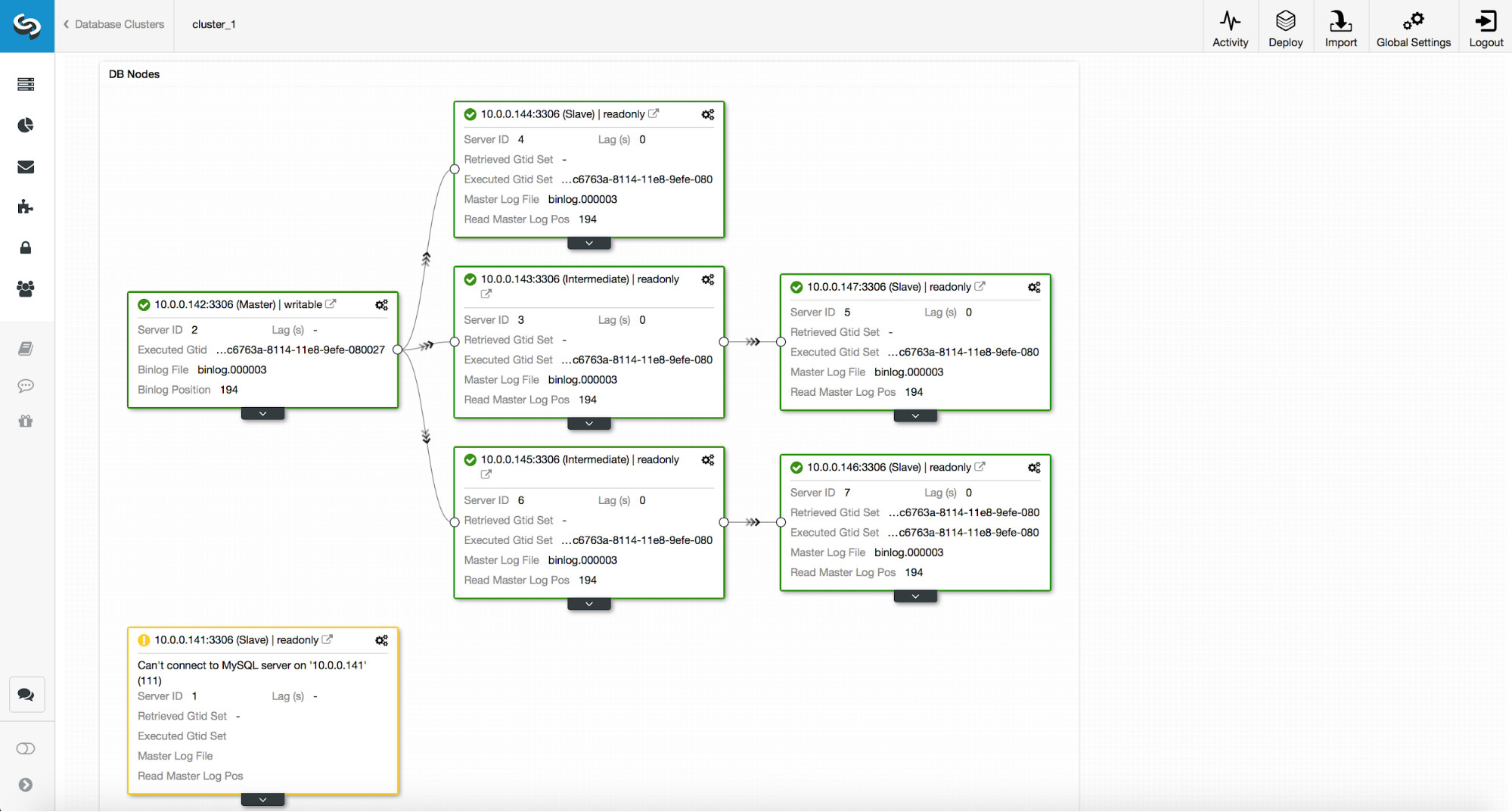
As you can see, the old master is disabled and ClusterControl will not attempt to automatically recover it. It is up to the user to check what has happened, copy any data which may not have been replicated to the master candidate and rebuild the old master:
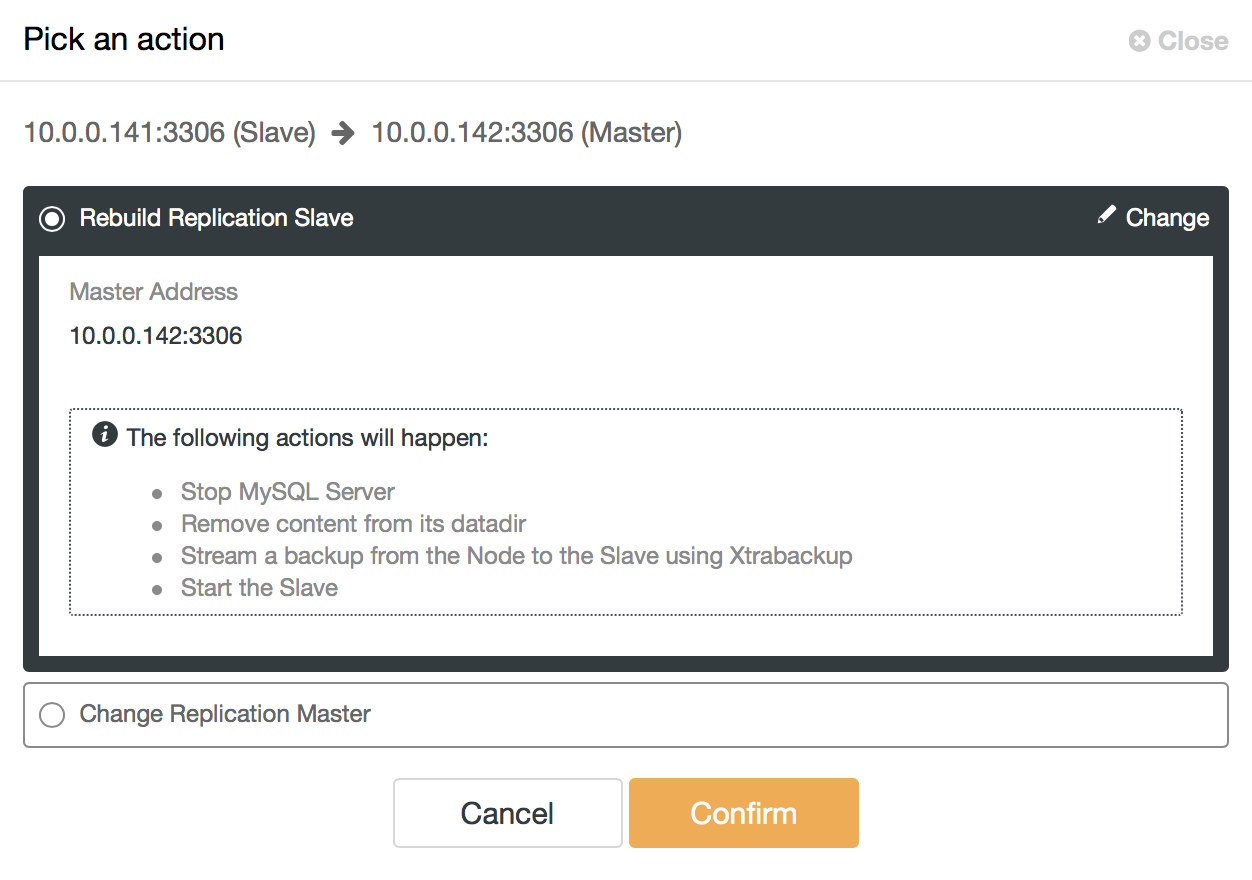
Then it’s a matter of a few topology changes and we can bring the topology to the original state, just replacing 10.0.0.141 with 10.0.0.142:
Blacklist Configuration
Now we are going to see how the blacklist works. We mentioned that, in our example, it may not be the best option but we will try it for the sake of illustration. We will blacklist every host except 10.0.0.141, 10.0.0.142 and 10.0.0.143 as those are the hosts we want to see as master candidates.
replication_failover_blacklist=10.0.0.145:3306,10.0.0.146:3306,10.0.0.144:3306,10.0.0.147:3306We will also restart the cmon process to apply configuration changes:
service cmon restartThe failover process is similar. Again, once the master crash is detected, ClusterControl will start a failover job.
When a Replica May Not be a Good Master Candidate
In this short section, we would like to discuss in more details some of the cases in which you may not want to promote a given replica to become a new master. Hopefully, this will give you some ideas of the cases where you may need to consider inducing more manual control of the failover process.
Different MySQL Version
First, if your replica uses a different MySQL version than the master, it is not a good idea to promote it. Generally speaking, a more recent version is always a no-go as replication from the new to the old MySQL version is not supported and may not work correctly. This is relevant mostly to major versions (for example, 8.0 replicating to 5.7) but the good practice is to avoid this setup altogether, even if we are talking about small version differences (5.7.x+1 -> 5.7.x). Replicating from lower to higher/newer version is supported as it is a must for the upgrade process, but still, you would rather want to avoid this (for example, if your master is on 5.7.x+1 you would rather not replace it with a replica on 5.7.x).
Different Roles
You may assign different roles to your replicas. You can pick one of them to be available for developers to test their queries on a production dataset. You may use one of them for OLAP workload. You may use one of them for backups. No matter what it is, typically you would not want to promote such replica to master. All of those additional, non-standard workloads may cause performance problems due to the additional overhead. A good choice for a master candidate is a replica which is handling “normal” load, more or less the same type of load as the current master. You can then be certain it will handle the master load after failover if it handled it before that.
Different Hardware Specifications
We mentioned different roles for replicas. It is not uncommon to see different hardware specifications too, especially in conjunction with different roles. For example, a backup slave most likely doesn’t have to be as powerful as a regular replica. Developers may also test their queries on a slower database than the production (mostly because you would not expect the same level of concurrency on development and production database) and, for example, CPU core count can be reduced. Disaster recovery setups may also be reduced in size if their main role would be to keep up with the replication and it is expected that DR setup will have to be scaled (both vertically, by sizing up the instance and horizontally, by adding more replicas) before traffic can be redirected to it.
Delayed Replicas
Some of the replicas may be delayed – it is a very good way of reducing recovery time if data has been lost, but it makes them very bad master candidates. If a replica is delayed by 30 minutes, you will either lose that 30 minutes of transactions or you will have to wait (probably not 30 minutes as, most likely, the replica can catch up faster) for the replica to apply all delayed transactions. ClusterControl allows you to pick if you want to wait or if you want to failover immediately, but this would work ok for a very small lag – tens of seconds at most. If failover is supposed to take minutes, it’s just no point on using such a replica and therefore it’s a good idea to blacklist it.
Different Datacenter
We mentioned scaled-down DR setups but even if your second datacenter is scaled to the size of production, it still may be a good idea to keep the failovers within a single DC only. For starters, your active application hosts may be located in the main datacenter thus moving the master to a standby DC would significantly increase latency for write queries. Also, in case of a network split, you may want to manually handle this situation. MySQL does not have a quorum mechanism built in therefore it is kind of tricky to correctly handle (in an automatic way) network loss between two datacenters.



