blog
Dealing With MySQL Replication Issues Using ClusterControl

One of the most popular ways in achieving high availability for MySQL is replication. Replication has been around for many years, and became much more stable with the introduction of GTIDs. But even with these improvements, the replication process can break due to various reasons – for instance, when master and slave are out of sync because writes were sent directly to the slave. How do you troubleshoot replication issues, and how do you fix them?
In this blog post, we will discuss some of the common issues with replication and how to fix them with ClusterControl. Let’s start with the first one.
Replication Stopped With Some Error
Most MySQL DBAs will typically see this kind of problem at least once in their career. For various reasons, a slave can get corrupted or maybe stopped syncing with the master. When this happens, the first thing to do to start the troubleshooting is to check the error log for messages. Most of the time, the error message is easily traceable in the error log or by running the SHOW SLAVE STATUS query.
Let’s take a look at the following example from the SHOW STATUS SLAVE:
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0We can clearly see the error is related to Got fatal error 1236 from master when reading data from binary log: ‘Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.’. In order words, what the error is telling us essentially is that there is inconsistency in data and the required binary log files have already been deleted.
This is one good example where the replication process stops working. Besides SHOW SLAVE STATUS, you can also track the status in the “Overview” tab of the cluster in ClusterControl. So how to fix this with ClusterControl? You have two options to try:
-
You may try to start the slave again from the “Node Action”
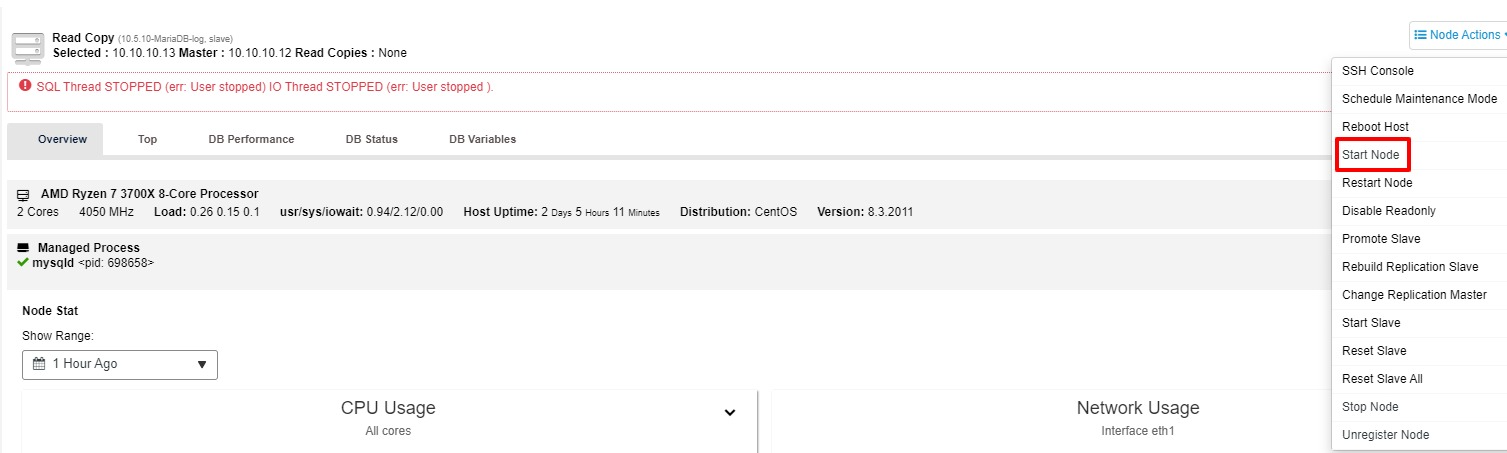
-
If the slave is still not working, you may run “Rebuild Replication Slave” job from the “Node Action”
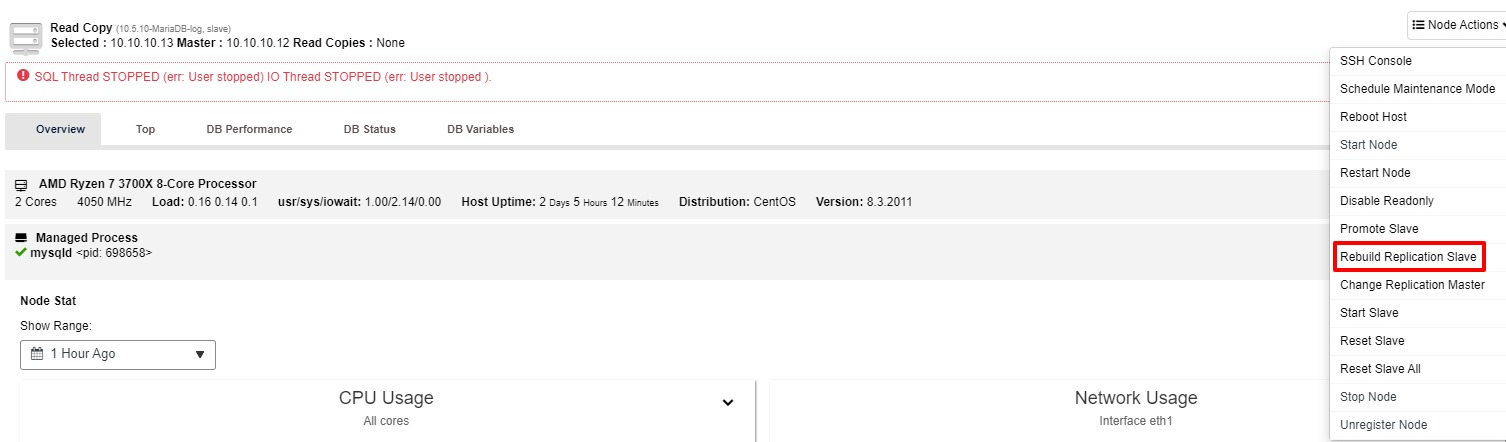
Most of the time, the second option will resolve the issue. ClusterControl will take a backup of the master, and rebuild the broken slave by restoring the data. Once the data is restored, the slave is connected to the master so it can catch up.
There are also multiple manual ways to rebuild slave as listed below, you may also refer to this link for more details:
-
Using Mysqldump to Rebuild an Inconsistent MySQL Slave
-
Using Mydumper to Rebuild an Inconsistent MySQL Slave
-
Using a Snapshot to Rebuild an Inconsistent MySQL Slave
-
Using a Xtrabackup or Mariabackup to Rebuild an Inconsistent MySQL Slave
Promote A Slave To Become A Master
Over time, the OS or database needs to be patched or upgraded to maintain stability and security. One of the best practices to minimize the downtime especially for a major upgrade is promoting one of the slaves to master after the upgrade was successfully done on that particular node.
By performing this, you could point your application to the new master and the master-slave replication will continue to work. In the meantime, you also could proceed with the upgrade on the old master with peace of mind. With ClusterControl this can be executed with a few clicks only assuming the replication is configured as Global Transaction ID-based or GTID-based for short. To avoid any data loss, it’s worth stopping any application queries in case the old master is operating correctly. This is not the only situation that you could promote the slave. In the event the master node is down, you also could perform this action.
Without ClusterControl, there are a few steps to promote the slave. Each of the steps requires a few queries to run as well:
-
Manually take down the master
-
Select the most advanced slave to be a master and prepare it
-
Reconnect other slaves to the new master
-
Changing the old master to be a slave
Nevertheless, the steps to Promote Slave with ClusterControl is only a few clicks: Cluster > Nodes > choose slave node > Promote Slave as per the screenshot below:
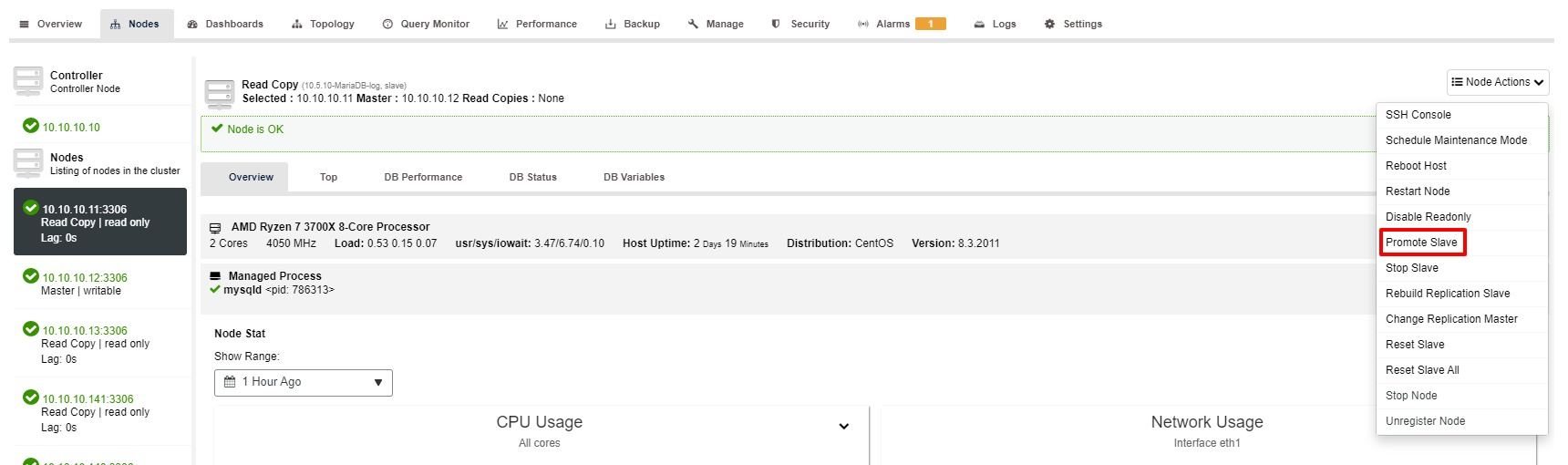
Master Becomes Unavailable
Imagine you have large transactions to run but the database is down. It does not matter how careful you are, this is probably the most serious or critical situation for a replication setup. When this happens, your database is not able to accept a single write, which is bad. Besides, your application(s), of course, will not work properly.
There are a few reasons or causes that lead to this issue. Some of the examples are hardware failure, OS corruption, database corruption and so on. As a DBA, you need to act quickly to restore the master database.
Thanks to the “Auto Recovery” cluster function that is available in ClusterControl, the failover process can be automated. It can be enabled or disabled with a single click. As the name goes, what it will do is bring up the entire cluster topology when necessary. For example, a master-slave replication must have at least one master alive at any given time, regardless of the number of available slaves. When the master is not available, it will automatically promote one of the slaves.
Let’s take a look at the screenshot below:
In the above screenshot, we can see that “Auto Recovery” is enabled for both Cluster and Node. In the topology, notice that the current master IP address is 10.10.10.11. What will happen if we take down the master node for testing purposes?
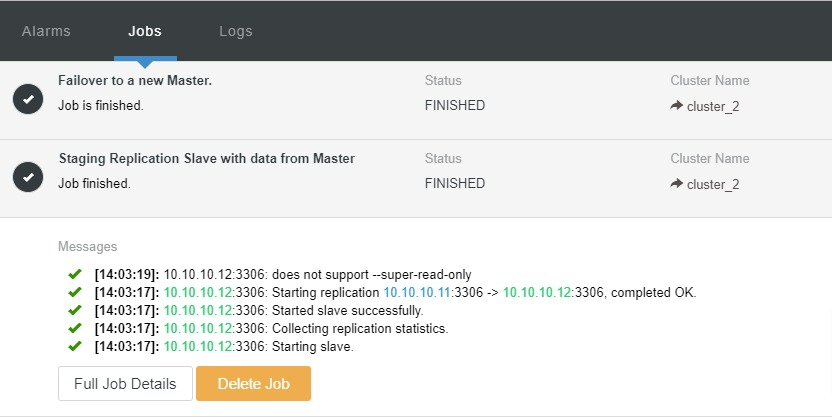
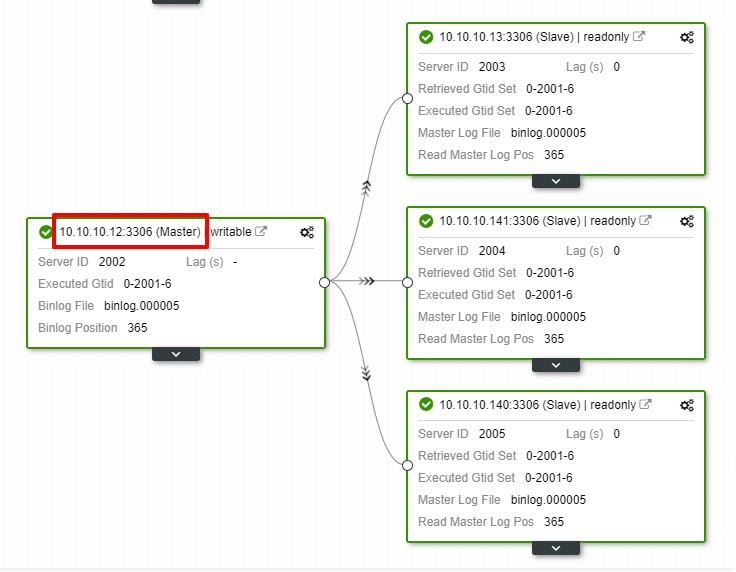
As you can see, the slave node with IP 10.10.10.12 is automatically promoted to master, so that the replication topology is reconfigured. Instead of doing it manually which, of course, will involve a lot of steps, ClusterControl helps you to maintain your replication setup by taking the hassle off your hands.
Conclusion
In any unfortunate event with your replication, the fix is very simple and less hassle with ClusterControl. ClusterControl helps you recover your replication issues quickly, which increases the uptime of your databases.



