blog
Database Load Balancing in the Cloud – MySQL Master Failover with ProxySQL 2.0: Part Two (Seamless Failover)

In the previous blog we showed you how to set up an environment in Amazon AWS EC2 that consists of a Percona Server 8.0 Replication Cluster (in Master – Slave topology). We deployed ProxySQL and we configured our application (Sysbench).
We also used ClusterControl to make the deployment easier, faster and more stable. This is the environment we ended up with…
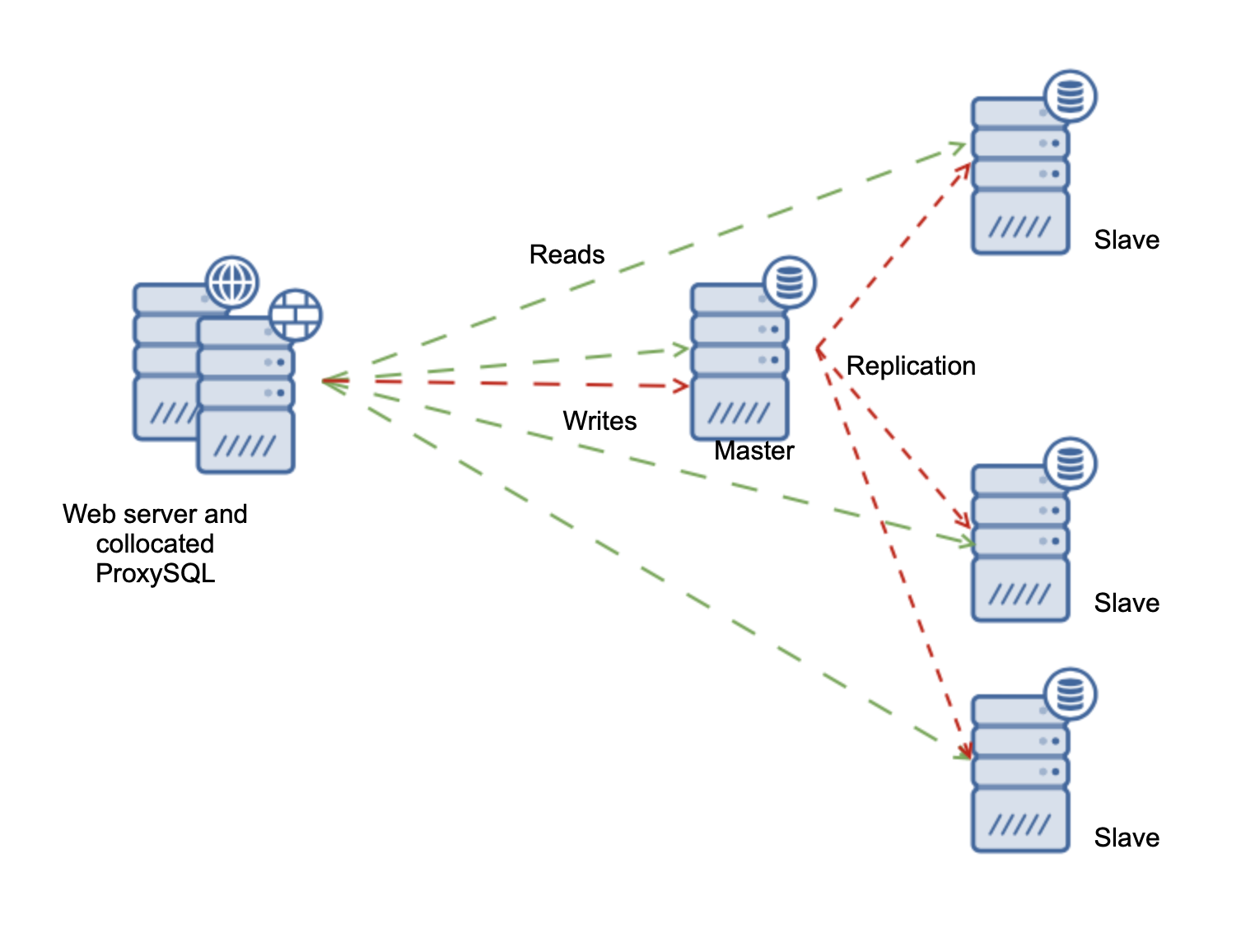
This is how it looks in ClusterControl:
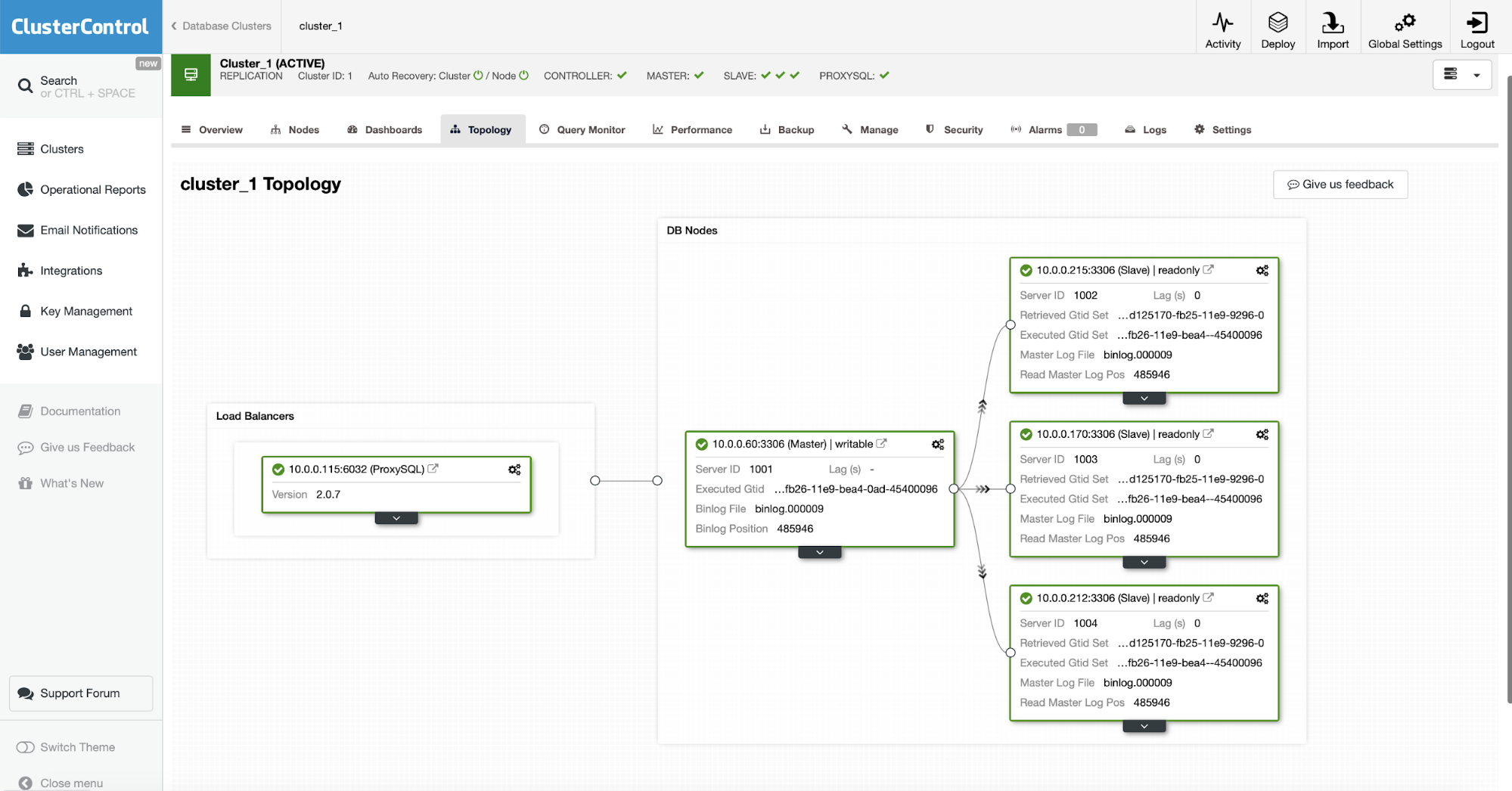
In this blog post we are going to review the requirements and show you how, in this setup, you can seamlessly perform master switches.
Seamless Master Switch with ProxySQL 2.0
We are going to benefit from ProxySQL ability to queue connections if there are no nodes available in a hostgroup. ProxySQL utilizes hostgroups to differentiate between backend nodes with different roles. You can see the configuration on the screenshot below.
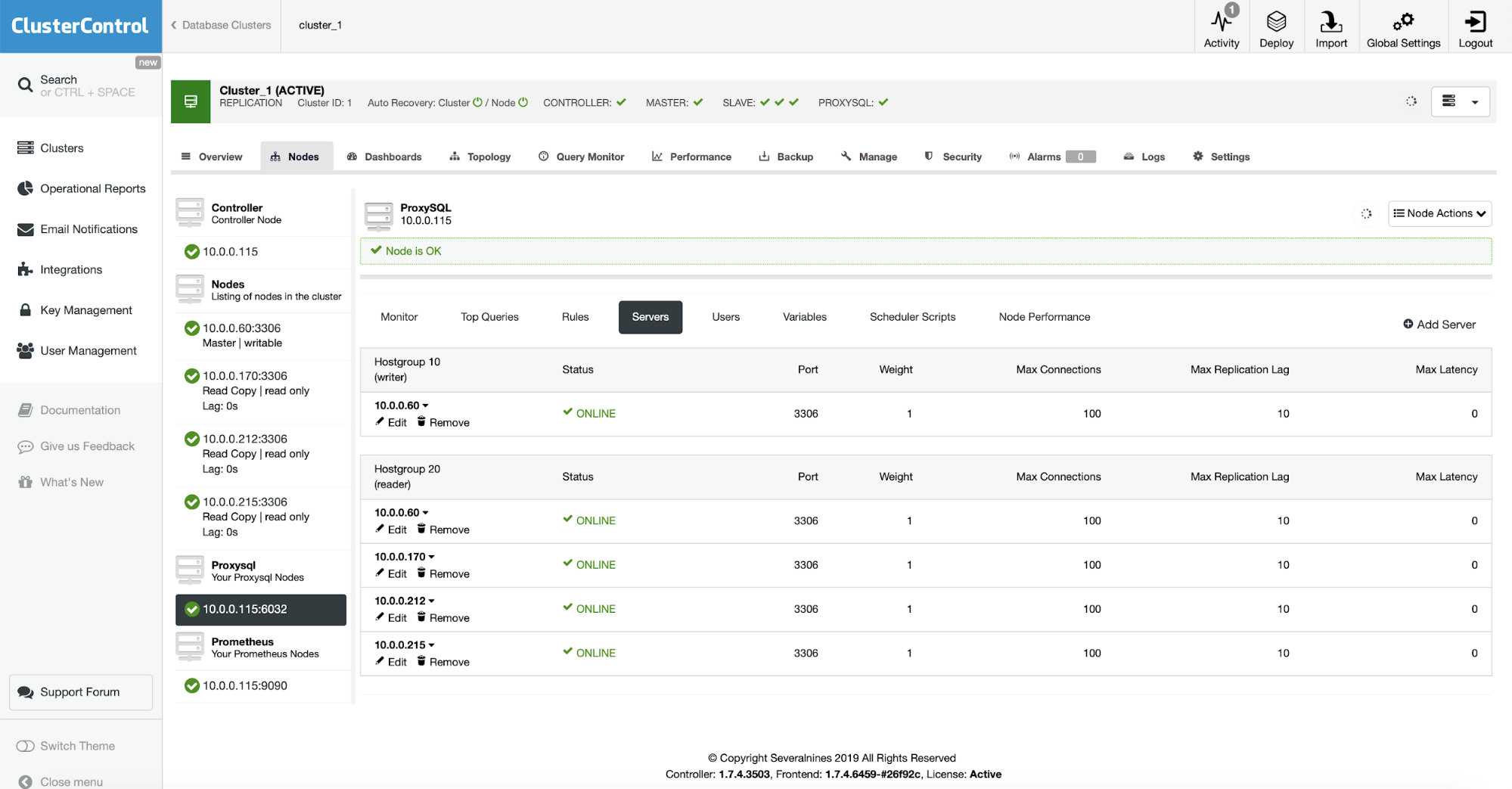
In our case we have two host groups – hostgroup 10 contains writers (master) and hostgroup 20 contains slaves (and also it may contain master, depends on the configuration). As you may know, ProxySQL uses SQL interface for configuration. ClusterControl exposes most of the configuration options in the UI but some settings cannot be set up via ClusterControl (or they are configured automatically by ClusterControl). One of such settings is how the ProxySQL should detect and configure backend nodes in replication environment.
mysql> SELECT * FROM mysql_replication_hostgroups;
+------------------+------------------+------------+-------------+
| writer_hostgroup | reader_hostgroup | check_type | comment |
+------------------+------------------+------------+-------------+
| 10 | 20 | read_only | host groups |
+------------------+------------------+------------+-------------+
1 row in set (0.00 sec)Configuration stored in mysql_replication_hostgroups table defines if and how ProxySQL will automatically assign master and slaves to correct hostgroups. In short, the configuration above tells ProxySQL to assign writers to HG10, readers to HG20. If a node is a writer or reader is determined by the state of variable ‘read_only’. If read_only is enabled, node is marked as reader and assigned to HG20. If not, node is marked as writer and assigned to HG10. On top of that we have a variable:
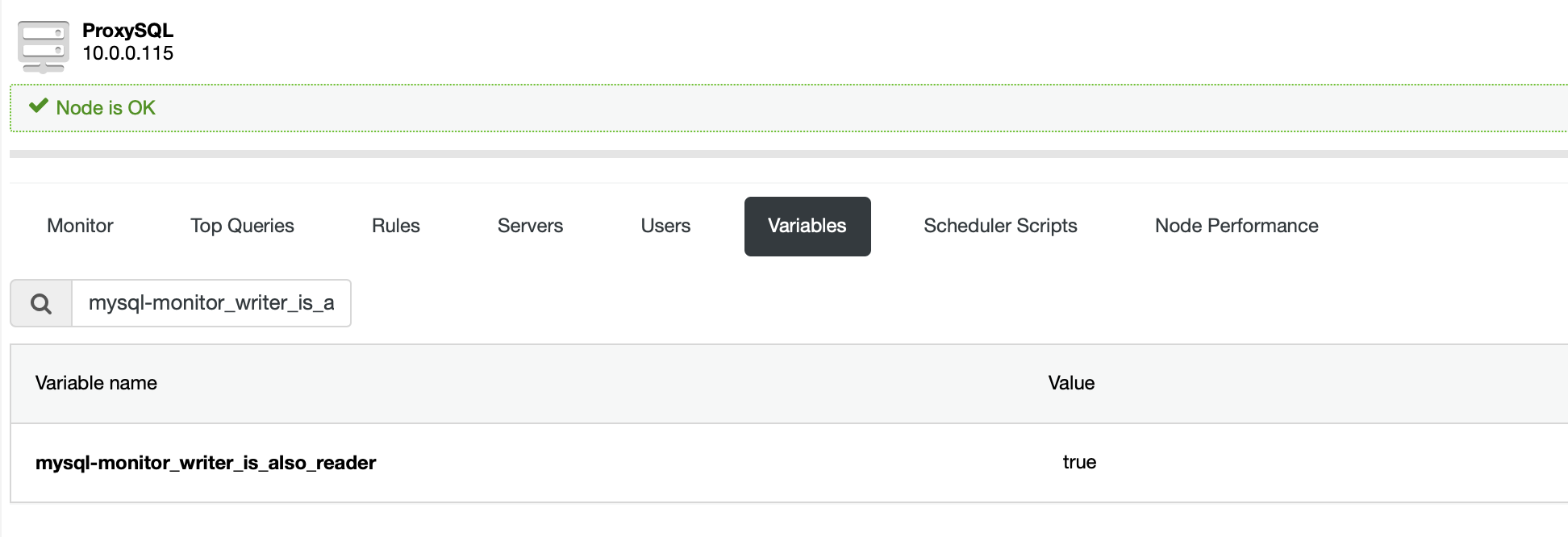
Which determines if writer should also show up in the readers’ hostgroup or not. In our case it is set to ‘True’ thus our writer (master) is also a part of HG20.
ProxySQL does not manage backend nodes but it does access them and check the state of them, including the state of the read_only variable. This is done by monitoring user, which has been configured by ClusterControl according to your input at the deployment time for ProxySQL. If the state of the variable changes, ProxySQL will reassign it to proper hostgroup, based on the value for read_only variable and based on the settings in mysql-monitor_writer_is_also_reader variable in ProxySQL.
Here enters ClusterControl. ClusterControl monitors the state of the cluster. Should master is not available, failover will occur. It is more complex than that and we explained this process in detail in one of our earlier blogs. What is important for us is that, as long as it is safe, ClusterControl will execute the failover and in the process it will reconfigure read_only variables on old and new master. ProxySQL will see the change and modify its hostgroups accordingly. This will also happen in case of the regular slave promotion, which can easily be executed from ClusterControl by starting this job:
The final outcome will be that the new master will be promoted and assigned to HG10 in ProxySQL while the old master will be reconfigured as a slave (and it will be a part of HG20 in ProxySQL). The process of master change may take a while depending on environment, application and traffic (it is even possible to failover in 11 seconds, as my colleague has tested). During this time database (master) will not be reachable in ProxySQL. This leads to some problems. For starters, the application will receive errors from the database and user experience will suffer – no one likes to see errors. Luckily, under some circumstances, we can reduce the impact. The requirement for this is that the application does not use (at all or at that particular time) multi-statement transactions. This is quite expected – if you have a multi-statement transaction (so, BEGIN; … ; COMMIT;) you cannot move it from server to server because this will no longer be a transaction. In such cases the only safe way is to rollback the transaction and start once more on a new master. Prepared statements are also a no-no: they are prepared on a particular host (master) and they do not exist on slaves so once one slave will be promoted to a new master, it is not possible for it to execute prepared statements which has been prepared on old master. On the other hand if you run only auto-committed, single-statement transactions, you can benefit from the feature we are going to describe below.
One of the great features ProxySQL has is an ability to queue incoming transactions if they are directed to a hostgroup that does not have any nodes available. This is defined by following two variables:

ClusterControl increases them to 20 seconds, allowing even for quite some long failovers to perform without any error being sent to the application.
Testing the Seamless Master Switch
We are going to run the test in our environment. As the application we are going to use SysBench started as:
while true ; do sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=4 --events=0 --time=3600 --reconnect=1 --mysql-socket=/tmp/proxysql.sock --mysql-user=sbtest --mysql-password=sbtest --tables=32 --report-interval=1 --skip-trx=on --table-size=100000 --db-ps-mode=disable --rate=5 run ; doneBasically, we will run sysbench in a loop (in case an error show up). We will run it in 4 threads. Threads will reconnect after every transaction. There will be no multi-statement transactions and we will not use prepared statements. Then we will trigger the master switch by promoting a slave in the ClusterControl UI. This is how the master switch looks like from the application standpoint:
[ 560s ] thds: 4 tps: 5.00 qps: 90.00 (r/w/o: 70.00/20.00/0.00) lat (ms,95%): 18.95 err/s: 0.00 reconn/s: 5.00
[ 560s ] queue length: 0, concurrency: 0
[ 561s ] thds: 4 tps: 5.00 qps: 90.00 (r/w/o: 70.00/20.00/0.00) lat (ms,95%): 17.01 err/s: 0.00 reconn/s: 5.00
[ 561s ] queue length: 0, concurrency: 0
[ 562s ] thds: 4 tps: 7.00 qps: 126.00 (r/w/o: 98.00/28.00/0.00) lat (ms,95%): 28.67 err/s: 0.00 reconn/s: 7.00
[ 562s ] queue length: 0, concurrency: 0
[ 563s ] thds: 4 tps: 3.00 qps: 68.00 (r/w/o: 56.00/12.00/0.00) lat (ms,95%): 17.95 err/s: 0.00 reconn/s: 3.00
[ 563s ] queue length: 0, concurrency: 1We can see that the queries are being executed with low latency.
[ 564s ] thds: 4 tps: 0.00 qps: 42.00 (r/w/o: 42.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 564s ] queue length: 1, concurrency: 4Then the queries paused – you can see this by the latency being zero and transactions per second being equal to zero as well.
[ 565s ] thds: 4 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 565s ] queue length: 5, concurrency: 4
[ 566s ] thds: 4 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00
[ 566s ] queue length: 15, concurrency: 4Two seconds in queue is growing, still no response coming from the database.
[ 567s ] thds: 4 tps: 20.00 qps: 367.93 (r/w/o: 279.95/87.98/0.00) lat (ms,95%): 3639.94 err/s: 0.00 reconn/s: 20.00
[ 567s ] queue length: 1, concurrency: 4After three seconds application was finally able to reach the database again. You can see the traffic is now non-zero and the queue length has been reduced. You can see the latency around 3.6 seconds – this is for how long the queries have been paused
[ 568s ] thds: 4 tps: 10.00 qps: 116.04 (r/w/o: 84.03/32.01/0.00) lat (ms,95%): 539.71 err/s: 0.00 reconn/s: 10.00
[ 568s ] queue length: 0, concurrency: 0
[ 569s ] thds: 4 tps: 4.00 qps: 72.00 (r/w/o: 56.00/16.00/0.00) lat (ms,95%): 16.12 err/s: 0.00 reconn/s: 4.00
[ 569s ] queue length: 0, concurrency: 0
[ 570s ] thds: 4 tps: 8.00 qps: 144.01 (r/w/o: 112.00/32.00/0.00) lat (ms,95%): 24.83 err/s: 0.00 reconn/s: 8.00
[ 570s ] queue length: 0, concurrency: 0
[ 571s ] thds: 4 tps: 5.00 qps: 98.99 (r/w/o: 78.99/20.00/0.00) lat (ms,95%): 21.50 err/s: 0.00 reconn/s: 5.00
[ 571s ] queue length: 0, concurrency: 1
[ 572s ] thds: 4 tps: 5.00 qps: 80.98 (r/w/o: 60.99/20.00/0.00) lat (ms,95%): 17.95 err/s: 0.00 reconn/s: 5.00
[ 572s ] queue length: 0, concurrency: 0
[ 573s ] thds: 4 tps: 2.00 qps: 36.01 (r/w/o: 28.01/8.00/0.00) lat (ms,95%): 14.46 err/s: 0.00 reconn/s: 2.00
[ 573s ] queue length: 0, concurrency: 0Everything is stable again, total impact for the master switch was 3.6 second increase in the latency and no traffic hitting database for 3.6 seconds. Other than that the master switch was transparent to the application. Of course, whether it will be 3.6 seconds or more depends on the environment, traffic and so on but as long as the master switch can be performed under 20 seconds, no error will be returned to the application.
Conclusion
As you can see, with ClusterControl and ProxySQL 2.0 you are just a couple of clicks from achieving a seamless failover and master switch for your MySQL Replication clusters.



