blog
Clustered Database Node Failure and its Impact on High Availability

A node crash can happen at any time, it is unavoidable in any real world situation. Back then, when giant, standalone databases roamed the data world, each fall of such a titan created ripples of issues that moved across the world. Nowadays data world has changed. Few of the titans survived, they were replaced by swarms of small, agile, clustered database instances that can adapt to the ever changing business requirements.
One example of such a database is Galera Cluster, which (typically) is deployed in the form of a cluster of nodes. What changes if one of the Galera nodes fail? How does this affect the availability of the cluster as a whole? In this blog post we will dig into this and explain the Galera High Availability basics.
Galera Cluster and Database High Availability
Galera Cluster is typically deployed in clusters of at least three nodes. This is due to the fact that Galera uses a quorum mechanism to ensure that the cluster state is clear for all of the nodes and that the automated fault handling can happen. For that three nodes are required – more than 50% of the nodes have to be alive after a node’s crash in order for cluster to be able to operate.
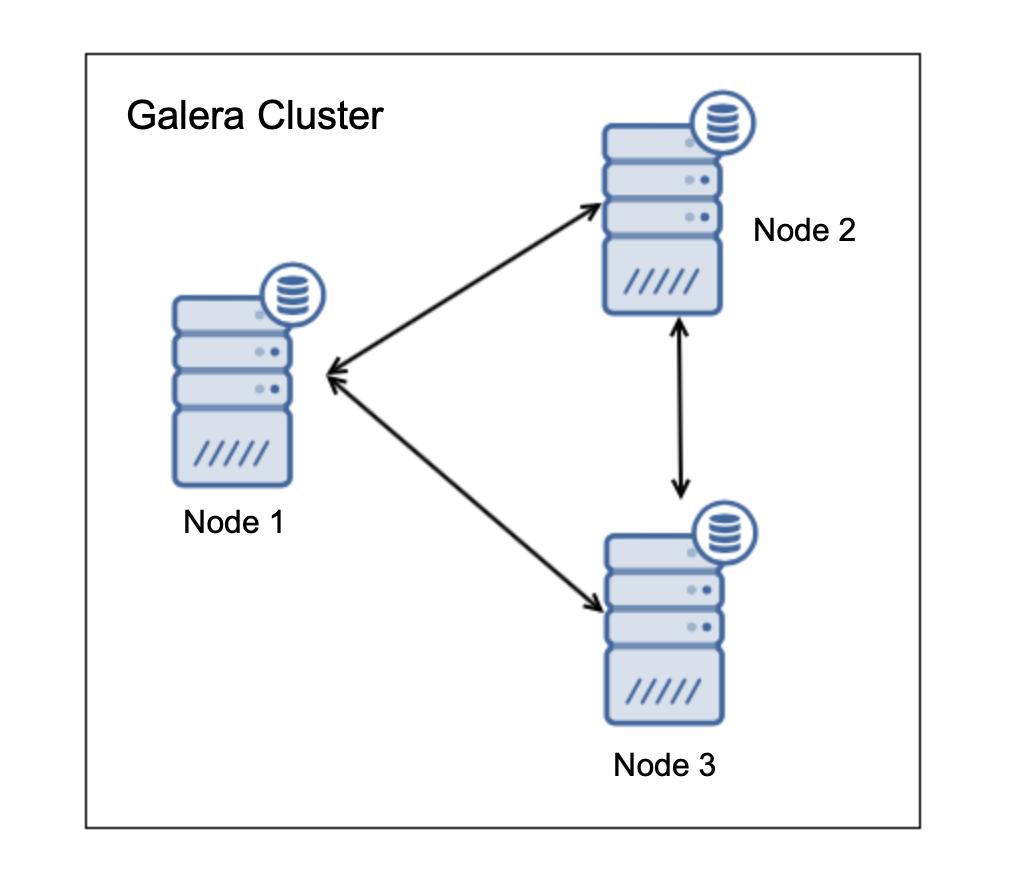
Let’s assume you have a three nodes in Galera Cluster, just as on the diagram above. If one node crashes, the situation changes into following:
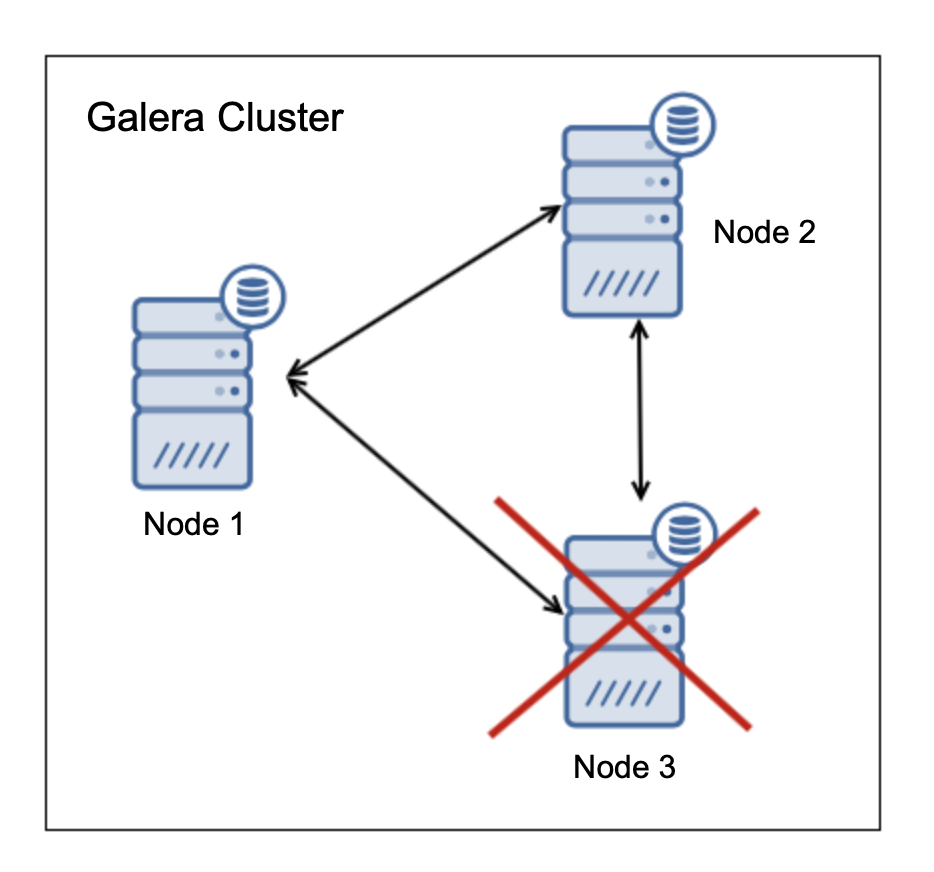
Node “3” is off but there are nodes “1” and “2”, which consist of 66% of all nodes in the cluster. This means, those two nodes can continue to operate and form a cluster. Node “3” (if it happens to be alive but it cannot connect to the other nodes in the cluster) will account for 33% of the nodes in the cluster, thus it will cease to operate.
We hope this is now clear: three nodes are the minimum. With two nodes each would be 50% of the nodes in the cluster thus neither will have majority – such cluster does not provide HA. What if we would add one more node?
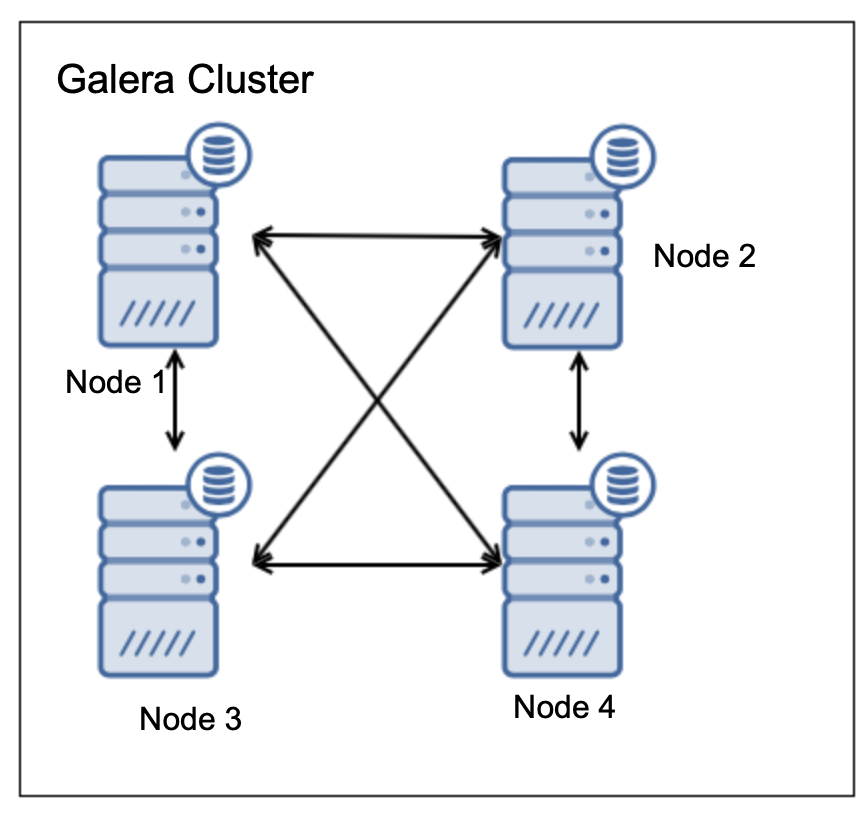
Such setup allows also for one node to fail:
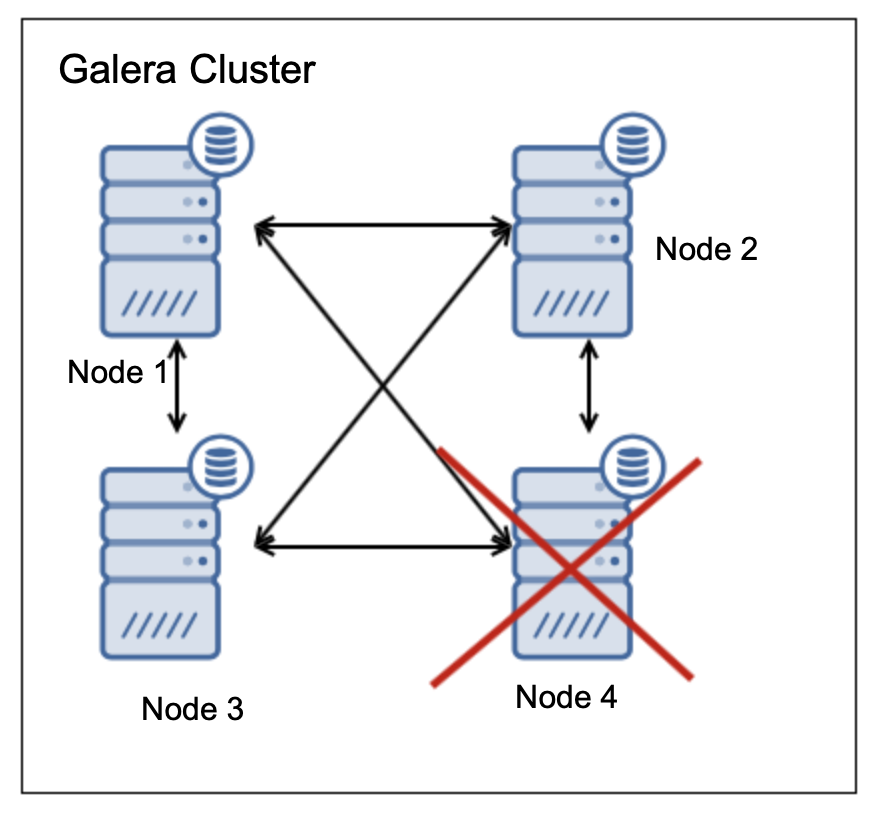
In such case we have three (75%) nodes up-and-running, which is the majority. What would happen if two nodes fail?
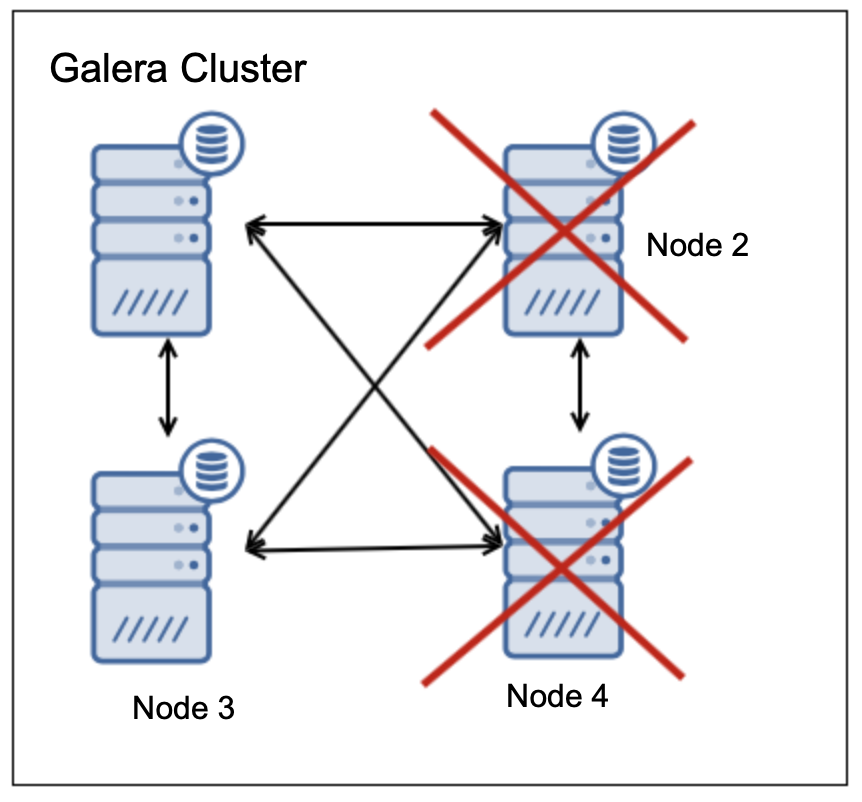
Two nodes are up, two are down. Only 50% of the nodes are available, there is no majority thus cluster has to cease its operations. The minimal cluster size to support failure of two nodes is five nodes:
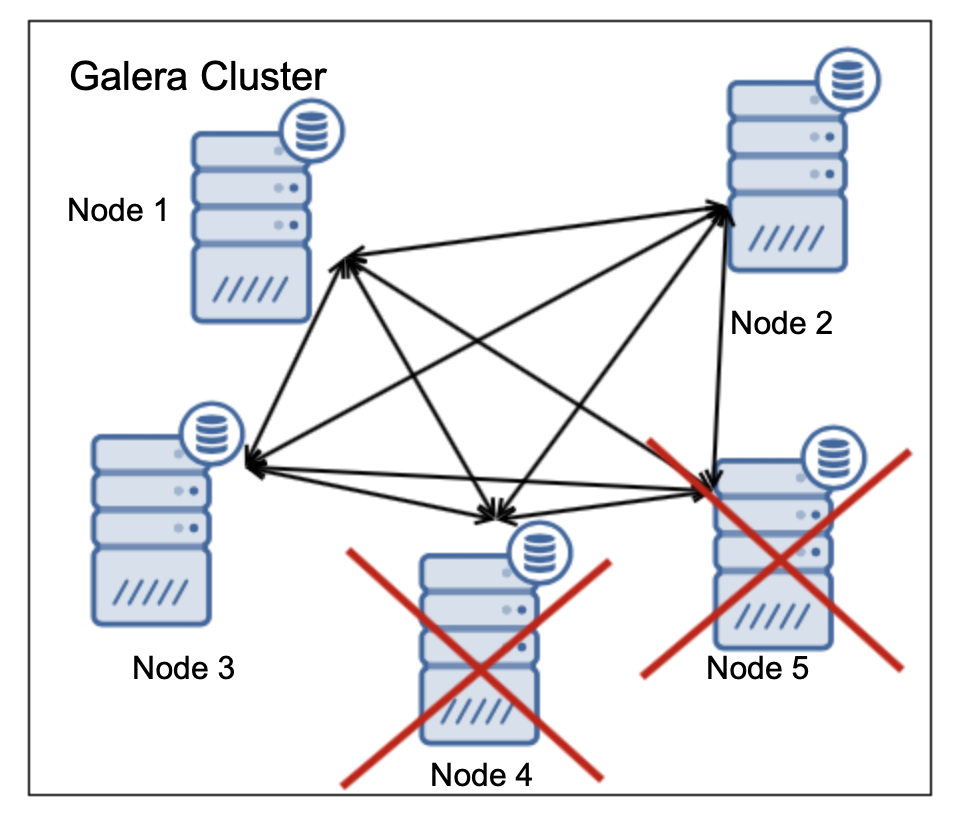
In the case as above two nodes are off, three are remaining which makes it 60% available thus the majority is reached and cluster can operate.
To sum up, three nodes are the minimum cluster size to allow for one node to fail. Cluster should have an odd number of nodes – this is not a requirement but as we have seen, increasing cluster size from three to four did not make any difference on the high availability – still only one failure at the same time is allowed. To make the cluster more resilient and support two node failures at the same time, cluster size has to be increased from three to five. If you want to increase the cluster’s ability to handle failures even further you have to add another two nodes.
Impact of Database Node Failure on the Cluster Load
In the previous section we have discussed the basic math of the high availability in Galera Cluster. One node can be off in a three node cluster, two off in a five node cluster. This is a basic requirement for Galera.
You have to also keep in mind other aspects too. We’ll take a quick look at them just now. For starters, the load on the cluster.
Let’s assume all nodes have been created equal. Same configuration, same hardware, they can handle the same load. Having load on one node only doesn’t make too much sense cost-wise on three node cluster (not to mention five node clusters or larger). You can safely expect that if you invest in three or five galera nodes you want to utilize all of them. This is quite easy – load balancers can distribute the load across all Galera nodes for you. You can send the writes to one node and balance reads across all nodes in the cluster. This poses additional threat you have to keep in mind. How does the load will look like if one node will be taken out of the cluster? Let’s take a look at the following case of a five node cluster.
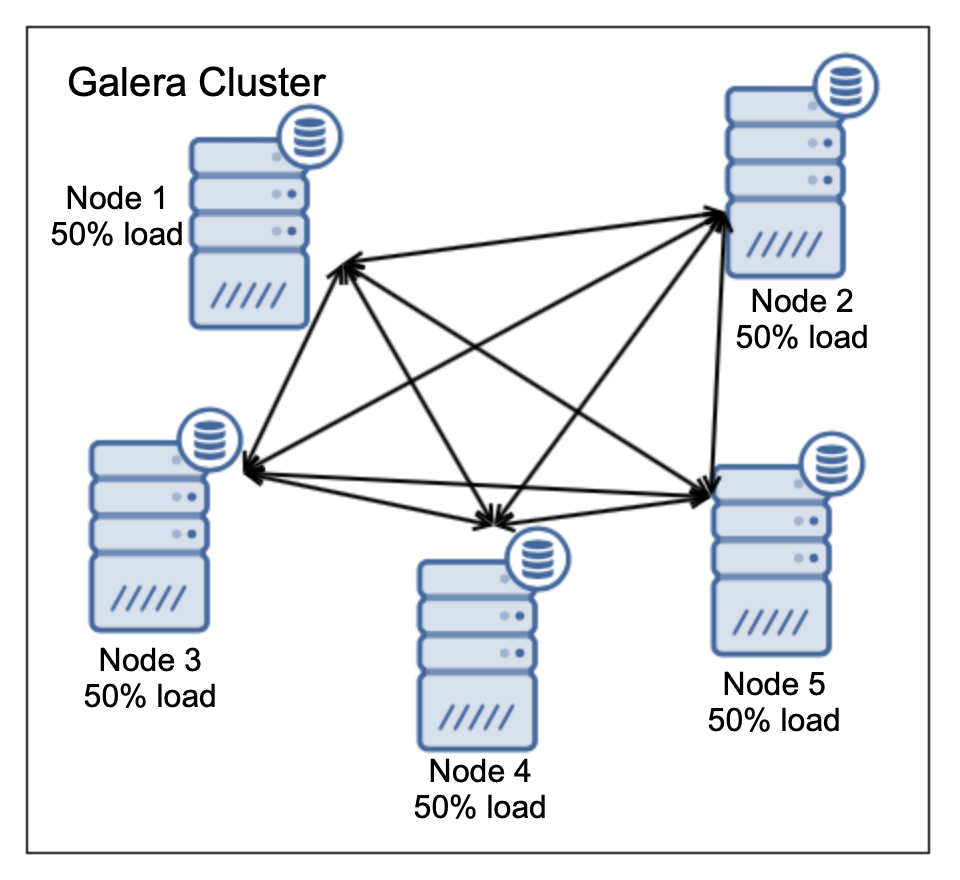
We have five nodes, each one is handling 50% load. This is quite ok, nodes are fairly loaded yet they still have some capacity to accommodate unexpected spikes in the workload. As we discussed, such cluster can handle up to two node failures. Ok, let’s see how this would look like:
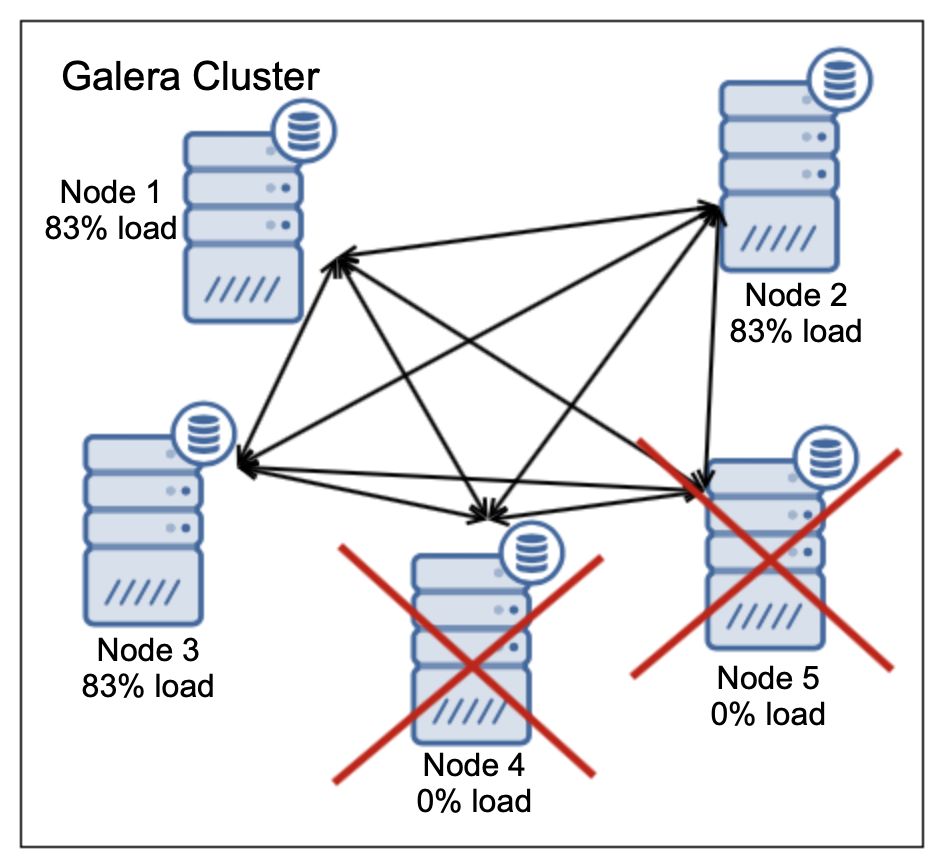
Two nodes are down, that’s ok. Galera can handle it. 100% of the load has to be redistributed across three remaining nodes. This makes it a total 250% of the load distributed across three nodes. As a result, each of them will be running at 83% of their capacity. This may be acceptable but 83% of the load on average means that the response time will be increased, queries will take longer and any spike in the workload most likely will cause serious issues.
Will our five node cluster (with 50% utilization of all nodes) really able to handle failure of two nodes? Well, not really, no. It will definitely not be as performant as the cluster before the crashes. It may survive but it’s availability may be seriously affected by temporary spikes in the workload.
You also have to keep in mind one more thing – failed nodes will have to be rebuilt. Galera has an internal mechanism that allows it to provision nodes which join the cluster after the crash. It can either be IST, incremental state transfer, when one of the remaining nodes have required data in gcache. If not, full data transfer will have to happen – all data will be transferred from one node (donor) to the joining node. The process is called SST – state snapshot transfer. Both IST and SST requires some resources. Data has to be read from disk on the donor and then transferred over the network. IST is more light-weight, SST is much heavier as all the data has to be read from disk on the donor. No matter which method will be used, some additional CPU cycles will be burnt. Will the 17% of the free resources on the donor enough to run the data transfer? It’ll depend on the hardware. Maybe. Maybe not. What doesn’t help is that most of the proxies, by default, remove donor node from the pool of nodes to send traffic to. This makes perfect sense – node in “Donor/Desync” state may lag behind the rest of the cluster.
When using Galera, which is virtually a synchronous cluster, we don’t expect nodes to lag. This could be a serious issue for the application. On the other hand, in our case, removing donor from the pool of nodes to load balance the workload ensures that the cluster will be overloaded (250% of the load will be distributed across two nodes only, 125% of node’s capacity is, well, more than it can handle). This would make the cluster definitely not available at all.
Conclusion
As you can see, high availability in the cluster is not just a matter of quorum calculation. You have to account for other factors like workload, its change in time, handling state transfers. When in doubt, test yourself. We hope this short blog post helped you to understand that high availability is quite a tricky subject even if only discussed based on two variables – number of nodes and node’s capacity. Understanding this should help you design better and more reliable HA environments with Galera Cluster.



