blog
Best Practices in Scaling Databases: Part Two

In the previous blog post, we have covered the basics of scaling – what it is, what are the types, what is a must-have if we want to scale. This blog post will focus on the challenges and the ways in which we can scale out.
Challenging of Scaling Out
Scaling databases is not the easiest task for multiple reasons. Let’s focus a little bit on the challenges related to scaling out your database infrastructure.
Stateful service
We can distinguish two different types of services: stateless and stateful. Stateless services are the ones, which does not rely on any kind of existing data. You can just go ahead, start such a service and it will happily just work. You do not have to worry about the state of the data nor the service. If it is up, it will work properly and you can easily spread the traffic across multiple service instances just by adding more clones or copies of existing VM’s, containers or similar. An example of such a service can be a web application – deployed from the repo, having a properly configured web server, such service will just start and work properly.
The problem with databases is that the database is everything but stateless. Data has to be inserted into the database, it has to be processed and persisted. The image of the database is nothing more than just a couple of packages installed over the OS image and, without data and proper configuration, it is rather useless. This adds to the complexity of the database scaling. For stateless services it is just to deploy them and configure some loadbalancers to include new instances in the workload. For databases deploying the database, the instance is just the starting point. Further down the lane is data management – you have to transfer the data from your existing database instance into the new one. This can be a significant part of the problem and time needed for the new instances to start handling the traffic. Only after the data has been transferred we can set up the new nodes to become a part of the existing replication topology – the data has to be updated on them in the real time, based on the traffic that is reaching out to other nodes.
Time required to scale up
The fact that databases are stateful services is a direct reason for the second challenge that we face when we want to scale out the database infrastructure. Stateless services – you just start them and that’s it. It is quite a quick process. For databases, you have to transfer the data. How long will it take, it depends on multiple factors. How large is the data set? How fast is the storage? How fast is the network? What are the other steps required to provision the new node with the fresh data? Is data compressed/decompressed or encrypted/decrypted in the process? In the real world, it may take from minutes to multiple hours to provision the data on a new node. This seriously limits the cases where you can scale up your database environment. Sudden, temporary spikes of load? Not really, they may be long gone before you’ll be able to start additional database nodes. Sudden and consistent load increase? Yes, it will be possible to deal with it by adding more nodes but it may take even hours to bring them up and let them take over the traffic from existing database nodes.
Additional load caused by the scale up process
It is very important to keep in mind that the time required to scale up is just one side of the problem. The other side is the load caused by the scaling process. As we mentioned earlier, you have to transfer the whole data set to newly added nodes. This is not something that you can ignore, after all, it may be an hours long process of reading the data from disk, sending it over the network and storing it in a new location. If the donor, the node where you read the data from, is overloaded, you need to consider how it will behave if it will be forced to perform additional heavy I/O activity? Will your cluster be able to take on an additional workload if it is already under heavy pressure and spreaded thin? The answer might not be easy to get as the load on the nodes may come in different forms. CPU-bound load will be the best case scenario as the I/O activity should be low and additional disk operations will be manageable. I/O-bound load, on the other hand, can slow down the data transfer significantly, seriously impacting cluster’s ability to scale.
Write scaling
The scale out process that we mentioned earlier is pretty much limited to scaling reads. It is paramount to understand that scaling writes is a completely different story. You can scale reads by simply adding more nodes and spreading the reads across more backend nodes. Writes are not that easy to scale. For starters, you cannot scale out writes just like that. Every node that contains the whole data set is, obviously, required to handle all writes performed somewhere in the cluster because only by applying all modifications to the data set it can maintain consistency. So, when you think of it, no matter how you design your cluster and what technology you use, every member of the cluster has to execute every write. Whether it is a replica, replicating all writes from its master or node in a multi-master cluster like Galera or InnoDB Cluster executing all changes to the data set performed on all other nodes of the cluster, the outcome is the same. Writes do not scale out simply by adding more nodes to the cluster.
How can we Scale Out the Database?
So, we know what kind of challenges we are facing. What are the options that we have? How can we scale out the database?
By adding replicas
First and foremost, we will scale out simply by adding more nodes. Sure, it will take time and sure, it is not a process you can expect to happen immediately. Sure, you won’t be able to scale out writes like that. On the other hand, the most typical problem you will be facing is the CPU load caused by SELECT queries and, as we discussed, reads can simply be scaled by just adding more nodes to the cluster. More nodes to read from means the load on each one of them will be reduced. When you are at the beginning of your journey into the life cycle of your application, just assume that this is what you will be dealing with. CPU load, not efficient queries. It is very unlikely that you would need to scale out writes until way further in the life cycle, when your application has already matured and you have to deal with the number of customers.
By sharding
Adding nodes won’t solve the write issue, that’s what we established. What you have to do instead is sharding – splitting the data set across the cluster. In this case each node contains just a part of the data, not everything. This allows us to finally start scaling writes. Let’s say we have four nodes, each containing half of the data set.
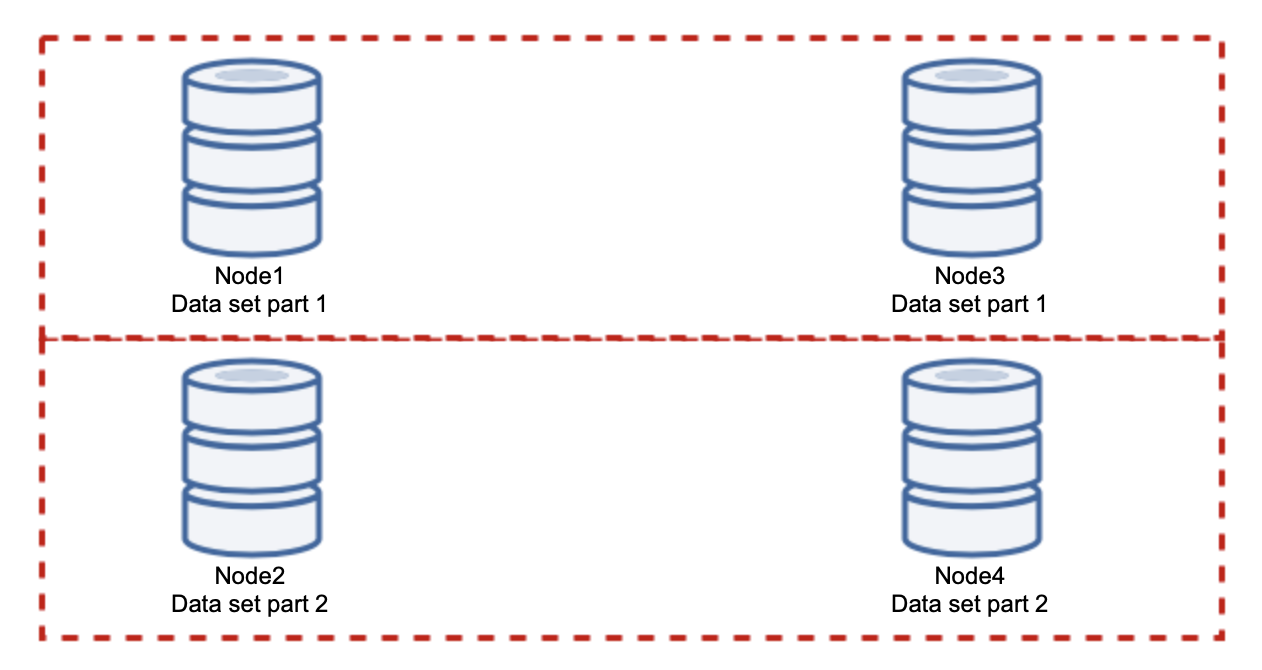
As you can see, the idea is simple. If the write is related to part 1 of the data set, it will be executed on node1 and node3. If it is related to part 2 of the data set, it will be executed on node2 and node4. You can think of the database nodes as disks in a RAID. Here we have an example of RAID10, two pairs of mirrors, for redundancy. In real implementation it may be more complex, you may have more than one replica of the data for improved high availability. The gist is, assuming a perfectly fair split of the data, half of the writes will hit node1 and node3 and the other half nodes 2 and 4. If you want to split the load even further, you can introduce the third pair of nodes:
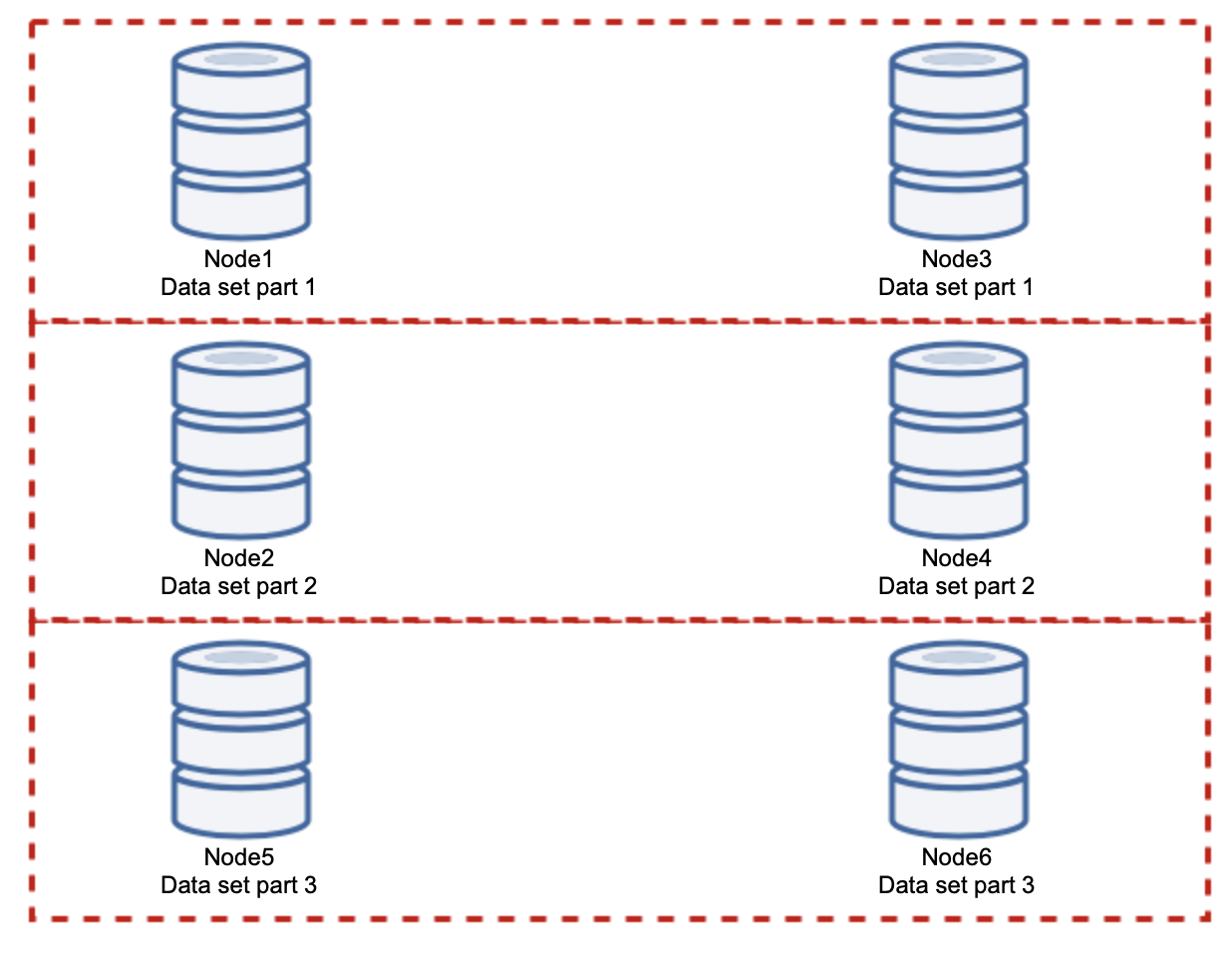
In this case, again, assuming a perfectly fair split, each pair will be responsible for 33% of all writes to the cluster.
This pretty much sums up the idea of sharding. In our example, by adding more shards, we can reduce the write activity on the database nodes to 33% of the original I/O load. As you may imagine, this does not come without drawbacks.
How am I going to find on which shard my data is located? Details are out of the scope of this call but in short, you can either implement some sort of a function on a given column (modulo or hash on the ‘id’ column) or you can build a separate metadatabase where you will store the details of how the data is distributed.
We hope that you found this short blog series informative and that you got a better understanding of the different challenges we face when we want to scale out the database environment. If you have any comments or suggestions on this topic, please feel free to comment below this post and share your experience



