blog
Automating PostgreSQL Daily Tasks Using Jenkins

This blog is a brief presentation about Jenkins and shows you how to use this tool to help with some of your daily PostgreSQL administration & management tasks.
About Jenkins
Jenkins is an open source software for automation. It is developed in java and is one of the most popular tools for Continuous Integration (CI) and Continuous Delivery (CD).
In 2010, after the acquisition of Sun Microsystems by Oracle, “Hudson” software was in a dispute with its open source community. This dispute became the basis for the launch of the Jenkins project.
Nowadays, “Hudson” (Eclipse public license) and “Jenkins” (MIT license) are two active and independent projects with a very similar purpose.
Jenkins has thousands of plugins you can use in order to speed up the development phase through automation for the entire development life-cycle; build, document, test, package, stage and deployment.
What Does Jenkins Do?
Although the main use of Jenkins could be Continuous Integration (CI) and Continuous Delivery (CD), this open source has a set of functionalities and it can be used without any commitment or dependence from CI or CD, thus Jenkins presents some interesting functionalities to explore:
- Scheduling period jobs (instead of using the traditional crontab)
- Monitoring jobs, its logs and activities by a clean view (as they have an option for grouping)
- Maintenance of jobs could be done easily; assuming Jenkins has a set of options for it
- Setup and scheduling software installation (by using Puppet) in the same host or in another one.
- Publishing reports and sending email notifications
Running PostgreSQL Tasks in Jenkins
There are three common tasks a PostgreSQL developer or database administrator has to do on a daily basis:
- Scheduling and execution of PostgreSQL scripts
- Executing a PostgreSQL process composed of three or more scripts
- Continuous Integration (CI) for PL/pgSQL developments
For the execution of these examples, it is assumed that Jenkins and PostgreSQL (at least the version 9.5) servers are installed and working properly.
Scheduling and Execution of a PostgreSQL Script
In most cases the implementation of daily (or periodically) PostgreSQL scripts for the execution of a usual task such as…
- Generation of backups
- Test the restore of a backup
- Execution of a query for reporting purposes
- Clean up and archiving log files
- Calling a PL/pgSQL procedure to purge tables
t’s defined on crontab:
0 5,17 * * * /filesystem/scripts/archive_logs.sh
0 2 * * * /db/scripts/db_backup.sh
0 6 * * * /db/data/scripts/backup_client_tables.sh
0 4 * * * /db/scripts/Test_db_restore.sh
*/10 * * * * /db/scripts/monitor.sh
0 4 * * * /db/data/scripts/queries.sh
0 4 * * * /db/scripts/data_extraction.sh
0 5 * * * /db/scripts/data_import.sh
0 */4 * * * /db/data/scripts/report.shAs the crontab isn’t the best user friendly tool to manage this kind of scheduling, it can be done on Jenkins with the following advantages…
- Very friendly interface to monitor their progress and current status
- The logs are immediately availables and no need any special grant to access them
- The job could be executed manually on Jenkins instead to have a scheduling
- For some kind of jobs, no need to define users and passwords in plain text files as Jenkins do it in a secure way
- The jobs could be defined as an API execution
So, it could be a good solution to migrate the jobs related to PostgreSQL tasks to Jenkins instead of crontab.
On the other hand, most database administrators and developers have strong skills in scripting languages and it would be easy for them to develop small interfaces to deal with these scripts to implement the automated processes with the goal of improving their tasks. But remember, Jenkins most likely already has a set of functions to do it and these functionalities can make life easy for developers who choose to use them.
Thus to define the execution of script it’s necessary to create a new job, selecting the “New Item” option.
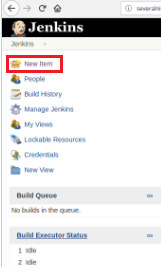
Then, after naming it, choose the type “FreeStyle projects” and click OK.
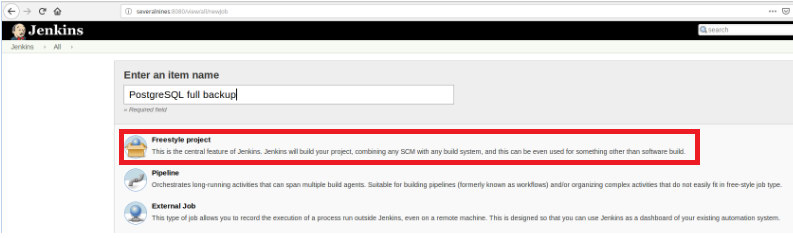
To finish the creation of this new job, in the section “Build” must be selected the option “Execute script” and in the command line box the path and parameterization of the script that will be executed:
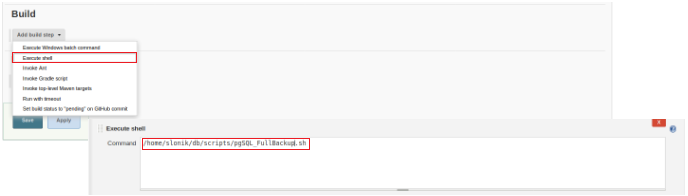
For this kind of job, it’s advisable to verify script permissions, because at least execution for the group the file belongs and for everyone must be set.
In this example, the script query.sh has read and execute permissions for everyone, read and execute permissions for the group and read write and execute for the user:
slonik@severalnines:~/db/scripts$ ls -l query.sh
-rwxr-xr-x 1 slonik slonik 365 May 11 20:01 query.sh
slonik@severalnines:~/db/scripts$ This script has a very simple set of statements, basically only calls to the utility psql in order to execute queries:
#!/bin/bash
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl" > /home/slonik/db/scripts/appl.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_users" > /home/slonik/db/scripts/appl_user.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_rights" > /home/slonik/db/scripts/appl_rights.datExecuting a PostgreSQL Process Composed of Three or More Scripts
In this example, I’ll describe what you need to execute three different scripts in order to hide sensitive data and for that, we will follow the below steps…
- Import data from files
- Prepare data to be masked
- Backup of database with data masked
So, to define this new job it’s necessary to select the option “New Item” in the Jenkins main page and then, after to assign a name, the “Pipeline” option must be chosen:
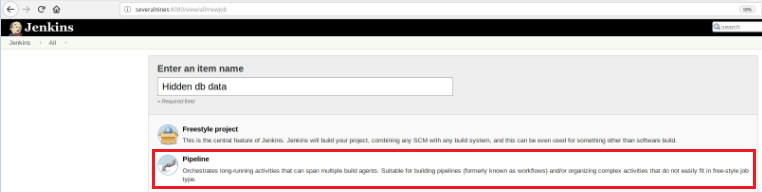
Once the job is saved in the “Pipeline” section, on the tab “Advanced project options”, the “Definition” field must be set to “Pipeline script”, as shown below:
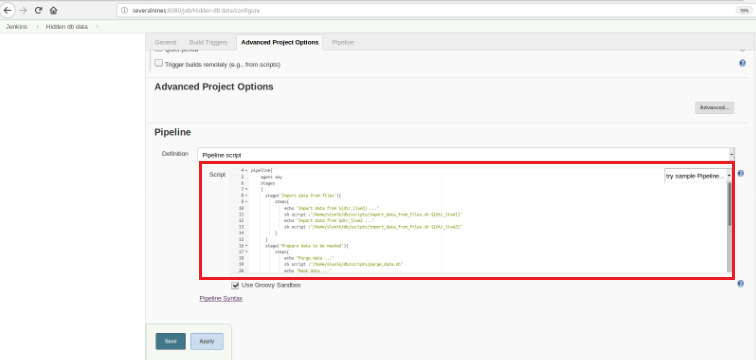
As I mentioned at the beginning of the chapter, the used Groovy script it’s composed by three stages, it means three distinct parts (stages), as presented in the following script:
def dir_live1='/data/ftp/server1'
def dir_live2='/data/ftp/server2'
pipeline{
agent any
stages
{
stage('Import data from files'){
steps{
echo "Import data from ${dir_live1} ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live1}"
echo "Import data from $dir_live2 ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live2}"
}
}
stage('Prepare data to be masked'){
steps{
echo "Purge data ..."
sh script :"/home/slonik/db/scripts/purge_data.sh"
echo "Mask data ..."
sh script :"/home/slonik/db/scripts/mask_data.sh"
}
}
stage('Backup of database with data masked'){
steps{
echo "Backup database after masking ..."
sh script :"/home/slonik/db/scripts/backup_db.sh"
}
}
}
}Groovy is a Java-syntax-compatible object oriented programming language for the Java platform. It’s both a static and dynamic language with features similar to those of Python, Ruby, Perl and Smalltalk.
It’s easy to understand since this kind of script is based in a few statements…
Stage
Means the 3 processes that will be executed: “Import data from files”, “Prepare data to be masked”
and “Backup of database with data masked”.
Step
A “step” (often called a “build step”) is a single task that is part of a sequence. Each stage could be composed of several steps. In this example, the first stage has two steps.
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server1'
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server2'The data are being imported from two distinct sources.
In the previous example, it’s important to note that there are two variables defined at the beginning and with a global scope:
dir_live1
dir_live2The scripts used in these three steps are calling the psql, pg_restore and pg_dump utilities.
Once the job is defined, it’s time to execute it and for that, it’s only necessary to click the option “Build Now”:
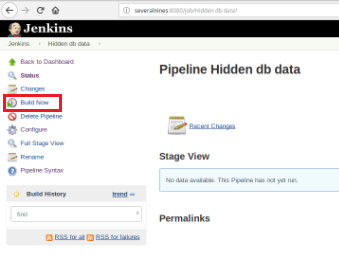
After the build starts it’s possible to verify its progress.
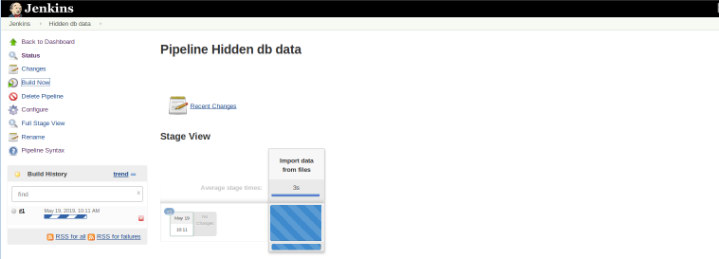
The Pipeline Stage View plugin includes an extended visualization of Pipeline build history on the index page of a flow project under Stage View. This view is built as soon as the tasks are completed and each task is represented by column from the left to the right and it’s possible to view and compare the elapsed time for the serval executions (known as a Build in Jenkins).
Once the execution (also called a Build) finishes, it’s possible to get additional details, clicking on the finished thread (red box).
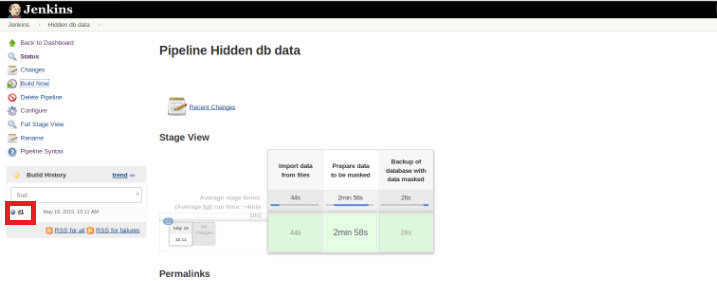
and then in “Console Output” option.
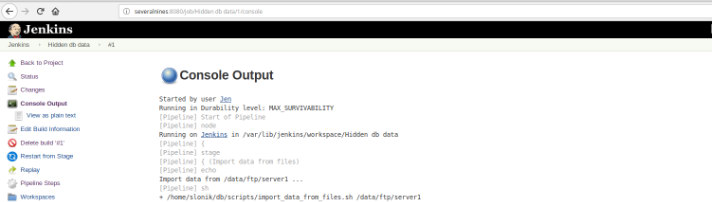
The previous views are extreme utility since they allow to have a perception of the runtime required of each stage.
Pipelines, also known as workflow, it’s a plugin that allows the definition of the application lifecycle and it’s a functionality used in Jenkins for Continuous delivery (CD).vThis plugin was built with requirements for a flexible, extensible and script-based CD workflow capability in mind.
This example is to hide sensitive data but for sure there are many other examples on a daily basis of PostgreSQL database administrator that can be executed on a pipeline job.
Pipeline has been available on Jenkins since version 2.0 and it’s an incredible solution!

Continuous Integration (CI) for PL/pgSQL Developments
The continuous integration for the database development is not as easy as in other programming languages due to the data that can be lost, so it isn’t easy to keep the database in source control and deploy it on a dedicated server particularly once there are scripts that contain DDL (Data Definition Language) and DML (Data Manipulation Language) statements. This is because these kinds of statements modify the current state of the database and unlike other programming languages there is no source code to compile.
On the other hand, there are a set of database statements for which it’s possible the continuous integration as for other programming languages.
This example it’s based only in the development of procedures and it will illustrate the triggering of a set of tests (written in Python) by Jenkins once PostgreSQL scripts, on which are stored the code of the following functions, are committed in a code repository.
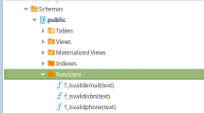
These functions are simple and its content only have a few logic or a query in PLpg/SQL or plperlu language as the function f_IsValidEmail:
CREATE OR REPLACE FUNCTION f_IsValidEmail(email text) RETURNS bool
LANGUAGE plperlu
AS $$
use Email::Address;
my @addresses = Email::Address->parse($_[0]);
return scalar(@addresses) > 0 ? 1 : 0;
$$;All the functions presented here do not depend on each other, and then there is no precedence either in its development or in its deployment. Also, as it will be verified ahead, there is no dependence on their validations.
So, in order to execute a set of validation scripts once a commit it’s performed in a code repository it’s necessary the creation of a build job (new item) in Jenkins:
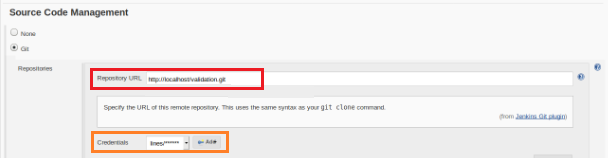
This new build job should be created as “Freestyle” project and in the “Source code repository” section must be defined the repository URL and its credentials (orange box):
In the section “Build Triggers” the option “GitHub hook trigger for GITScm polling” must be checked:
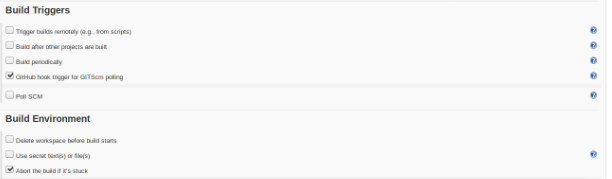
Finally, in the “Build” section, the option “Execute Shell” must be selected and in the command box the scripts that will do the validation of the developed functions:
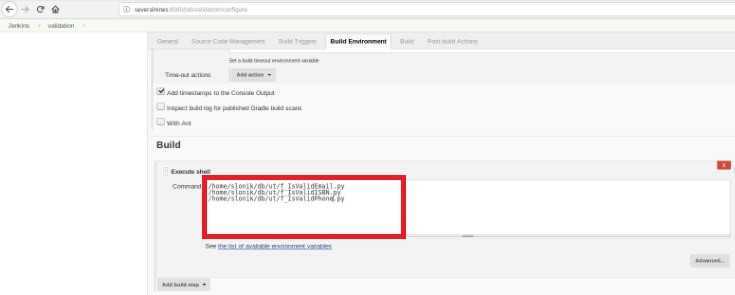
The purpose is to have one validation script for each developed function.
This Python script has a simple set of statements that will call these procedures from a database with some predefined expected results:
#!/usr/bin/python
import psycopg2
con = psycopg2.connect(database="db_deploy", user="postgres", password="postgres10", host="localhost", port="5432")
cur = con.cursor()
email_list = { '[email protected]' : True,
'tintinmail.com' : False,
'.@severalnines' : False,
'director#mail.com': False,
'[email protected]' : True
}
result_msg= "f_IsValidEmail -> OK"
for key in email_list:
cur.callproc('f_IsValidEmail', (key,))
row = cur.fetchone()
if email_list[key]!=row[0]:
result_msg= "f_IsValidEmail -> Nok"
print result_msg
cur.close()
con.close()This script will test the presented PLpg/SQL or plperlu functions and it will be executed after each commit in the code repository in order to avoid regressions on the developments.
Once this job build is executed, the log executions could be verified.
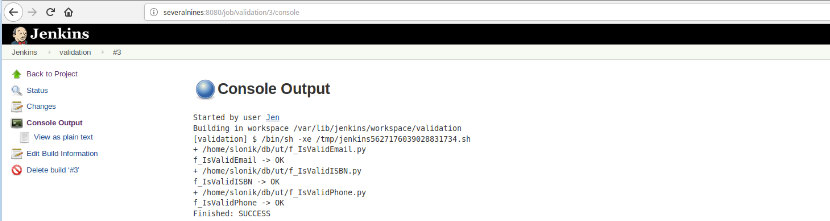
This option presents the final status: SUCCESS or FAILURE, the workspace, the executed files/script, the created temporary files and the error messages (for the failure ones)!
Conclusion
In summary, Jenkins is known as a great tool for Continuous Integration (CI) and Continuous Delivery (CD), however, it can be used for various functionalities like,
- Scheduling tasks
- Execution of scripts
- Monitoring Processes
For all of these purposes on each execution (Build on Jenkins vocabulary) it can be analyzed the logs and elapsed time.
Due to a large number of available plugins it could avoid some developments with a specific aim, probably there is a plugin that does exactly what you’re looking for, it’s just a matter of searching the update center or Manage Jenkins>>Manage Plugins inside the web application.



