blog
Utilizing Encryption to Strengthen PostgreSQL Database Security

Please Note: Portions of the blog contain references and examples from “ANNOUNCING AVAILABILITY OF POSTGRESQL INSTANCE LEVEL ENCRYPTION” by CyberTec, a company which provides support, consulting and training for PostgreSQL.
Organizations deal with different types of data including very crucial information that needs to be stored in a database. Security is a key aspect of consideration for ensuring sensitive data such as medical records and financial transactions do not end up in the hands of people with nefarious means. Over the years, developers come up with multiple measures of improving data integrity and protection. One of the most employed techniques is encryption in order to prevent data breaches.
As much as you may have used complex protection measures, some people may still end up getting access to your system. Encryption is an additional layer of security. PostgreSQL offers encryption at different levels besides providing flexibility in protecting data from disclosure as a result of untrustworthy administrators, insecure network connections and database server theft. PostgreSQL provides different encryption options such as:
- SSL Host authentication
- Encrypting data across a network
- Data partition encryption
- Encryption for specific columns
- Password storage encryption
- Client-side encryption
However, the more sophisticated encryption strategy you employ, the greater the likelihood you will be locked out of your data. Besides, the reading process will not only be difficult but also require plenty of resources to query and decrypt. The encryption option you select depends on the nature of data you are dealing with in terms of sensitivity. The diagram below illustrates the overall procedure of data encryption and decryption during server transactions.
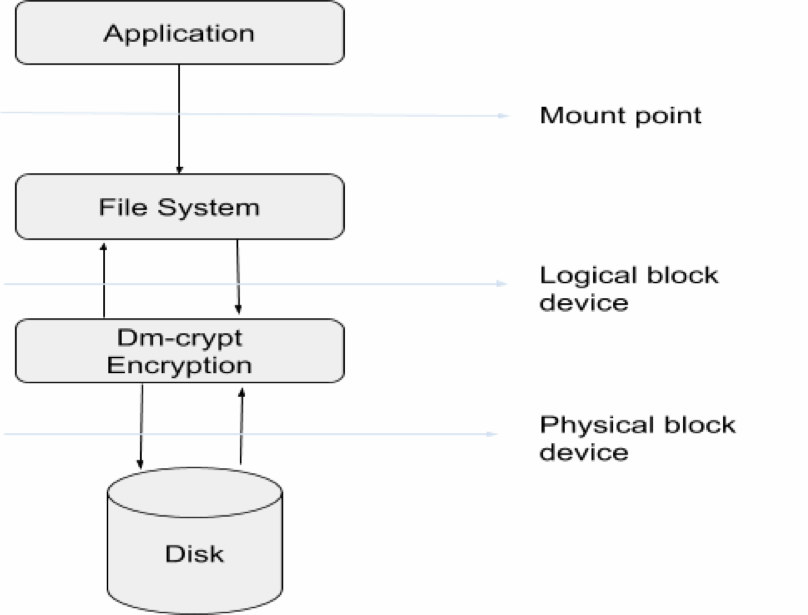
This article discusses different ways in which an enterprise can secure sensitive information but the main point of interest will be the instance-level encryption that was mentioned earlier.
Encryption
Encryption is a practice of encoding data so that it is no longer in its original format and cannot be read. There are 2 types of data as much as the database is concerned: data at rest and data in motion. When data is stored in the database, it is referred to as data at rest. On the other end, if a client, for example, sends a request to the database, if some data is returned and needs to reach the client, then it is referred to as data in motion. The two different types of data need to be protected using similar technology. For instance, if an application is developed such that a user needs to submit a password, this password will not be stored in the database as plain text. There are some encoding procedures that are used to change this plain text into some different string before storage. Besides, if the user needs to use this password for example for a login system, then we need a way of comparing one which will be submitted in the decryption process.
Database encryption can be implemented in different ways but many developers fail to take into account the transport level. However, the different approaches are also associated with different pitfalls among slowed down data access times, especially when virtual memory is being heavily accessed.
Encryption of Data at Rest
Data at rest means inactive data that is stored physically on disk. When it comes to hosting a database in a cloud environment, where the cloud vendor has full access to the infrastructure, encryption might be a good measure to retain control over the data. Some of the encryption strategies you can use are discussed below.
Full Disk Encryption (FDE)
The concept behind FDE is generally to protect every file and temporary storage that may contain parts of the data. It is quite efficient especially when you have a hard time selecting what you want to protect or rather if you do not want to miss a file out. The main advantage with this strategy is that it requires no special attention on the part of the end user after having access to the system. This approach has got some pitfalls though. These include:
- The encrypting and decrypting process slows down the overall data access time.
- Data may not be protected when the system is on since the information will be decrypted and ready for reading. You therefore need to engage some other encryption strategies such as file-based encryption.
File-Based Encryption
In this case, the files or directories are encrypted by the stackable cryptographic file system itself. In PostgreSQL, we often use the pg_crypto approach as discussed in this article.
Some of the advantages of the file system encryption include:
- Action control can be enforced through use of public-key cryptography
- Separate management of encrypted files such that backups of individually changed files even in encrypted form, rather than backup of the entire encrypted volume.
However, this is not a much reliable encryption method you may use for your clustered data. The reason being, some file-based encryption solution may leave a remnant of encrypted files over which an attacker may recover from. The best combination approach is therefore to combine this with full disk encryption.
Instance Level Encryption
Instance level uses buffers such that all files making up the PostgreSQL cluster are stored on disk as data-at-rest encryption. They are then presented as decrypt blocks as they are read from disk into shared buffers. After writing out these blocks to disk from the shared buffers, they are again encrypted automatically. The database is first initialized with encryption using the initdb command. Secondly, during startup, the encryption key is fetched by the server in either of these two ways; through pgcrypto.keysetup_command parameter or through an environment variable.
Setting Up Instance Level Encryption
A small recap on how you can setup the instance level encryption is outlined in the steps below:
- Check if you have “contrib” installed using the command rpm -qa |grep contrib for RedHat based OS or dpkg -l |grep contrib for Debian Based OS. If it’s not in the list, then install it with apt-get install postgresql-contrib if you are using the Debian Based environment or yum install postgresql-contrib if you are using a RedHat Based OS.
- Build the PostgreSQL code.
- Cluster initializing by establishing the encryption key and the running he initdb command
read -sp "Postgres passphrase: " PGENCRYPTIONKEY export PGENCRYPTIONKEY=$PGENCRYPTIONKEY initdb –data-encryption pgcrypto --data-checksums -D cryptotest - Start the server with the command
$ postgres -D /usr/local/pgsql/data - Setting the PGENCRYPTIONKEY environment variable with the command:
export PGENCRYPTIONKEY=topsecret pg_ctl -D cryptotest startThe key can also be set through a custom and more secure key reading procedure via the mentioned above command “pgcrypto.keysetup_command” postgresql.conf parameter.
Performance Expectations
Encryption always comes at the cost of performance, as there are no options without a cost. If your workload is IO-oriented, you may expect a considerably reduced performance but this may not be the case. Sometimes on the typical server hardware, if the dataset is less shared in the buffers or its time of stay in the buffers is small, the performance hit may be negligible.
After doing the encryption of my database, I ran some small test to check if encryption really affects the performance and the results are tabulated below.
| Workload | No encryption | With encryption | Performance cost |
|---|---|---|---|
| Bulk insert operation | 26s | 68s | 161% |
| Read-write fitting into shared buffers (in the ratio of 1:3) | 3200TPS | 3068TPS | 4.13% |
| Read only from shared buffers | 2234 TPS | 2219 TPS | 0.68% |
| Read only not fitting into shared buffers | 1845 TPs | 1434 TPS | 22.28% |
| Read-write not fitting into shared buffers in the ratio of 1:3 | 3422 TPS | 2545 TPS | 25.6% |
As depicted in the table above, we can see that the performance is non-linear as it sometimes jumps from 161% to 0.7%. This is a simple indication that encryption performance is workload specific besides being sensitive to the amount of pages moved between shared buffers and disk. This may also affect the power of the CPU depending on the involved workload. Instance level encryption is a quite viable option and the simplest approach for a number of environments.
Conclusion
Data encryption is an important undertaking especially for sensitive information in database management. There are a number of options available for data encryption as far as PostgreSQL is concerned. When determining which approach to use, it is important to understand the data, the application architecture and data usage since encryption comes at the cost of performance. This way you will be able to understand: when to enable encryption, where is your data exposed and where is it safe, which is the best encryption approach to use.



