blog
Tips & Tricks for Navigating the PostgreSQL Community

This blog is about the PostgreSQL community, how it works and how best to navigate it. Note that this is merely an overview … there is a lot of existing documentation.
Overview of the Community, How Development Works
PostgreSQL is developed and maintained by a globally-dispersed network of highly skilled volunteers passionate about relational database computing referred to as the PostgreSQL Global Development Group. A handful of core team members together handle special responsibilities like coordinating release activities, special internal communications, policy announcements, overseeing commit privileges and the hosting infrastructure, disciplinary and other leadership issues as well as individual responsibility for specialty coding, development, and maintenance contribution areas. About forty additional individuals are considered major contributors who have, as the name implies, undertaken comprehensive development or maintenance activities for significant codebase features or closely related projects. And several dozen more individuals are actively making various other contributions. Aside from the active contributors, a long list of past contributors are recognized for work on the project. It is the skill and high standards of this team that has resulted in the rich and robust feature set of PostgreSQL.
Many of the contributors have full-time jobs that relate directly to PostgreSQL or other Open Source software, and the enthusiastic support of their employers makes their enduring engagement with the PostgreSQL community feasible.
Contributing individuals coordinate using collaboration tools such as Internet Relay Chat (irc://irc.freenode.net/PostgreSQL) and PostgreSQL community mailing lists (https://www.PostgreSQL.org/community/lists). If you are new to IRC or mailing lists, then make an effort specifically to read up on etiquette and protocols (one good article appears at https://fedoramagazine.org/beginners-guide-irc/), and after you join, spend some time just listening to on-going conversations and search the archives for previous similar questions before jumping in with your own issues.
Note that the team is not static: Anyone can become a contributor by, well, contributing … but your contribution will be expected to meet those same high standards!
The team maintains a Wiki page (https://wiki.postgresql.org/) that, amongst a lot of very detailed and helpful information like articles, tutorials, code snippets and more, presents a TODO list of PostgreSQL bugs and feature requests and other areas where effort might be needed. If you want to be part of the team, this is a good place to browse. Items are added only after thorough discussion on the developer mailing list.
The community follows a process, visualized as the steps in Figure 1.

That is, the value of any non-trivial new code implementation is expected to be first discussed and deemed (by consensus) desirable. Then investment is made in design: design of the interface, syntax, semantics and behaviors, and consideration of backward compatibility issues. You want to get buy-in from the developer community on what is the problem to be solved and what this implementation will accomplish. You definitely do NOT want to go off and develop something in a vacuum on your own. There’s literally decades worth of very high quality collective experience embodied in the team, and you want, and they expect, to have ideas vetted early.
The PostgreSQL source code is stored and managed using the Git version control system, so a local copy can be checked out from https://git.postgresql.org/ to commence implementation. Note that for durable maintainability, patches must blend in with surrounding code and follow the established coding conventions (http://developer.postgresql.org/pgdocs/postgres/source.html), so it is a good idea to study any similar code sections to learn and emulate the conventions. Generally, the standard format BSD style is used. Also, be sure to update documentation as appropriate.
Testing involves first making sure existing regression tests succeed and that there are no compiler warnings, but also adding corresponding new tests to exercise the newly-implemented feature(s).
When the new functionality implementation in your local repository is complete, use the Git diff functionality to create a patch. Patches are submitted via email to the pgsql-hackers mailing list for review and comments, but you don’t have to wait until your work is complete … smart practise would be to ask for feedback incrementally. The Wiki page describes expectations as to format and helpful explanatory context and how to show respect for code reviewer’s time.
The core developers periodically schedule commit fests, during which all accumulated unapplied patches are added to the source code repository by authorized committers. As a contributor, your code will have undergone rigorous review and likely your own developer skills will be the better for it. To return the favor, there is an expectation that you will devote time to reviewing patches from others.
Top Websites to Get Information or Learn PostgreSQL
| Community Website – this is the main launching place into life with PostgreSQL | https://www.postgresql.org/ |
| Wiki – Wide-ranging topics related to PostgreSQL | https://wiki.postgresql.org/ |
| IRC Channel – Developers are active participants here | irc://irc.freenode.net/PostgreSQL |
| Source code repository | https://git.postgresql.org/ |
| pgAdmin GUI client | https://www.pgadmin.org/ |
| Biographies of significant community members | https://www.postgresql.org/community/contributors/ |
| Eric Raymond’s famous post on smart questions | http://www.catb.org/esr/faqs/smart-questions.html |
| Database schema change control | http://sqitch.org/ |
| Database unit testing | http://pgtap.org/ |
The Few Tools You Can’t Live Without
The fundamental command line tools for working with a PostgreSQL database are part of the normal distribution. The workhorse is the psql command line utility, which provides an interactive interface with lots of functionality for querying, displaying, and modifying database metadata, as well as executing data definition (DDL) and data manipulation (DML) statements.
Other included utilities of note include pg_basebackup for establishing a baseline for replication-based backup, pg_dump for extracting a database into a script file or other archive file, pg_restore for restoring a from a pg_dump archive, and others. All of these tools have excellent manual pages as well as being detailed in the standard documentation and numerous on-line tutorials.
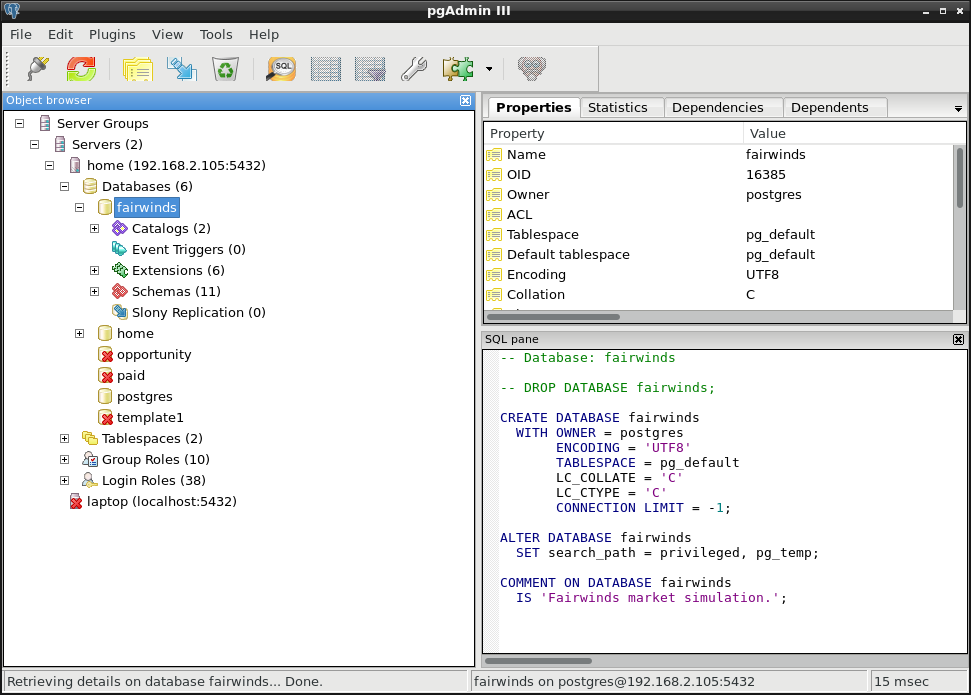
pgAdmin is a very popular graphical user interface tool that provides similar functionality as the psql command line utility, but with point-and-click convenience. Figure 2 shows a screenshot of pgAdmin III. On the left is a panel showing all the database objects in the cluster on the attached-to host server. You can drill down into the structure to list all databases, schemas, tables, views, functions, etc, and even open tables and views to examine the contained data. For each object, the tool will create the SQL DML for dropping and re-creating the object, too, as shown on the lower right panel. This is a convenient way to make modifications during database development.
A couple of my favorites tools for application developer teams are Sqitch (http://sqitch.org/), for database change control, and pgTAP (http://pgtap.org/). Sqitch enables stand-alone change management and iterative development by means of scripts written in the SQL dialect native to your implementation, not just PostgreSQL. For each database design change, you write three scripts: one to deploy the change, one to undo the change in case reverting to a previous version is necessary, and one to verify or test the change. The scripts and related files can be maintained in your revision control system right alongside your application code. PgTAP is a testing framework that includes a suite of functionality for verifying integrity of the database. All the pgTAP scripts are similarly plain text files compliant with normal revision management and change control processes. Once I started using these two tools, I found it hard to imagine ever again doing database work without.
Tips and Tricks
The PostgreSQL general mailing list is the most active of the various community lists and is the main community interface for free support to users. A pretty broad range of questions appear on this list, sometimes generating lengthy back-and-forth, but most often getting quick, informative, and to-the-point responses.
When posting a question related to using PostgreSQL, you generally want to always include background information including the version of PostgreSQL you are using (listed by the psql command line tool with “psql –version”), the operating system on which the server is running, and then maybe a description of the operating environment, such as whether it may be predominately read heavy or write heavy, typical number of users and concurrency concerns, changes you have made from the default server configuration (i.e., the pg_hba.conf and postgresql.conf files), etc. Oftentimes, a description of what you are trying to accomplish is valuable, rather than some obtuse analogy, as you may well get suggestions for improvement that you had not even thought of on your own. Also, you will get the best response if you include actual DDL, DML, and sample data illustrating the problem and facilitating others to recreate what you are seeing — yes, people will actually run your sample code and work with you.
Additionally, if you are asking about improving query performance, you will want to provide the query plan, i.e., the EXPLAIN output. This is generated by running your query unaltered except for prefixing it literally with the word “EXPLAIN”, as shown in Figure 3 in the pgAdmin tool or the psql command line utility.
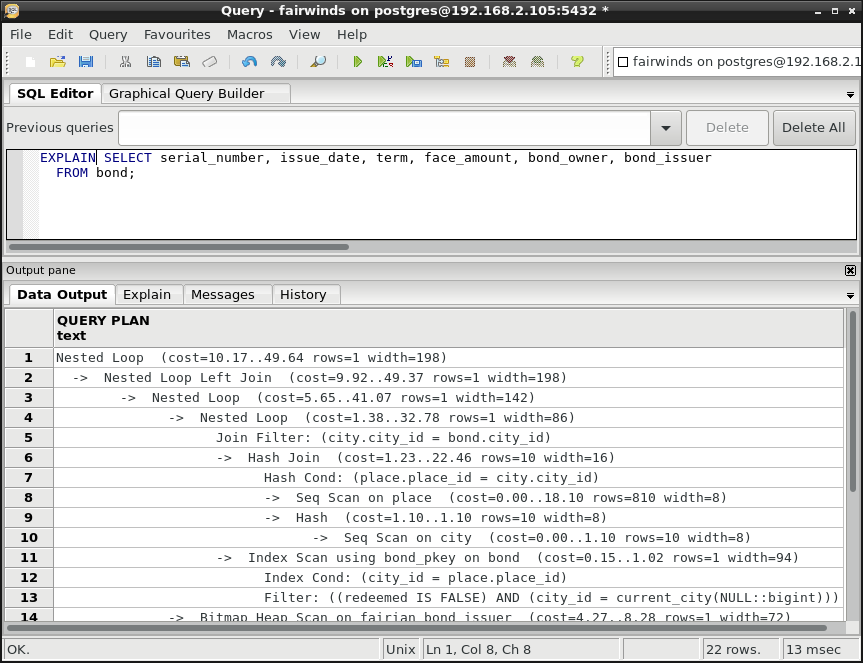
Under EXPLAIN, instead of actually running the query, the server returns the query plan, which lists detailed output of how the query will be executed, including which indexes will be used to optimize data access, where table scans might happen, and estimates of the cost and amount of data involved with each step. The kind of help you will get from the experienced practitioners monitoring the mailing list may pinpoint issues and help to suggest possible new indexes or changes to the filtering or join criteria.
Lastly, when participating in mailing list discussions there are two important things you want to keep in mind.
First, the mail list server is set up to send messages configured so that when you reply, by default your email software will reply only to the original message author. To be sure your message goes to the list, you must use your mail software “reply-all” feature, which will then include both the message author and the list address.
Second, the convention on the PostgreSQL mailing lists is to reply in-line and to NOT TOP POST. This last point is a long-standing convention in this community, and for many newcomers seems unusual enough that gentle admonishments are very common. Opinions vary on how much of the original message to retain for context in your reply. Some people chafe at the sometimes unwieldy growth in size of the message when the entire original message is retained in lots of back-and-forth discussion. Me personally, I like to delete anything that is not relevant to what specifically I am replying to so as to keep the message terse and focussed. Just bear in mind that there is decades of mailing list history retained on-line for historical documentation and future research, so retaining context and flow IS considered very important.
This article gets you started, now go forth, and dive in!



