blog
Scaling Your Time-Series Database – How to Simply Scale TimescaleDB

Scaling your TimescaleDB instance to a multi-node cluster can seem challenging, but with ClusterControl, it’s a straightforward process. In this blog, we’ll show you how to scale your single TimescaleDB instance into a multi-node cluster in just a few simple steps.
If you’ve been following our previous blogs, you already know how to deploy TimescaleDB, monitor its performance, run backups, and enable automatic failover. This time, we’re focusing on scaling, starting with a single-node setup running on CentOS. The node is already monitored and managed by ClusterControl.
The initial setup we’ll work with looks as follows:
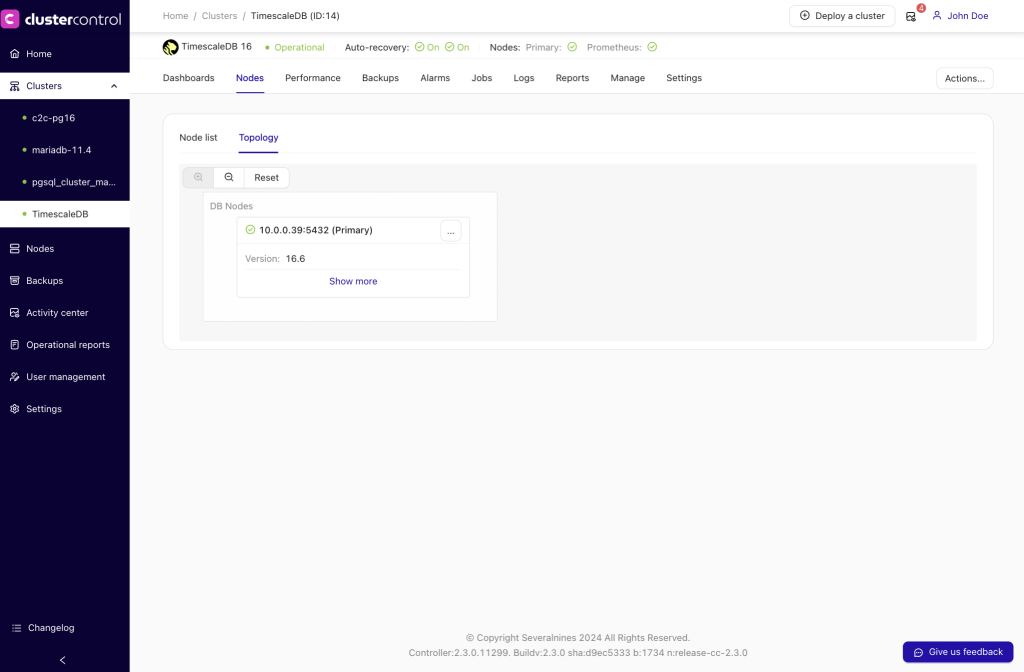
So, it’s a single production instance, and we want to convert it into a cluster with zero downtime. Our primary goal is to scale application read operations to other machines, with the option to use them as staging HA servers in case the writing server crashes.
More nodes should also help reduce application maintenance downtime, such as through patching in rolling restart method—patching one node at a time while the other nodes continue to serve database connections.
The final requirement is to create a single address for the new cluster, so the application can access all nodes from one centralized location.

We can beak out our action plan into two major steps:
- Add a Replica Node for Reads
- Install and Configure HAProxy
Adding a Replica Node for Reads
To proceed, click the Actions button under the TimescaleDB cluster dashboard, then navigate to Add new → Replica node.
- Select Create a replica node to create a new replica from scratch.
- Alternatively, choose Import a replica node if you already have an existing secondary TimescaleDB database node and want to add and register it with ClusterControl alongside your primary node.
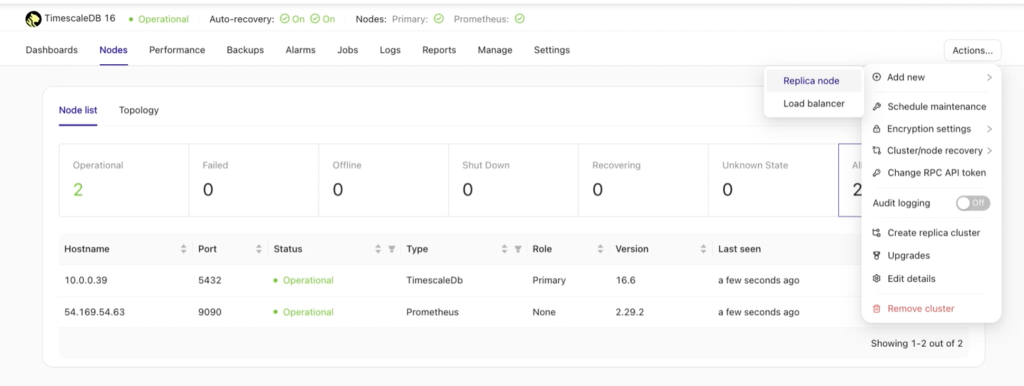
Once the Replica node is selected, a new window will appear, prompting you to choose your next action. The available options are illustrated below.
Selecting “Create a Replica Node” initiates a straightforward four-step process to set up the replica node.
In the first step, you need to specify the Node Configuration, where you define the port number for your replica (or secondary/standby) node and the data directory for your PostgreSQL server.
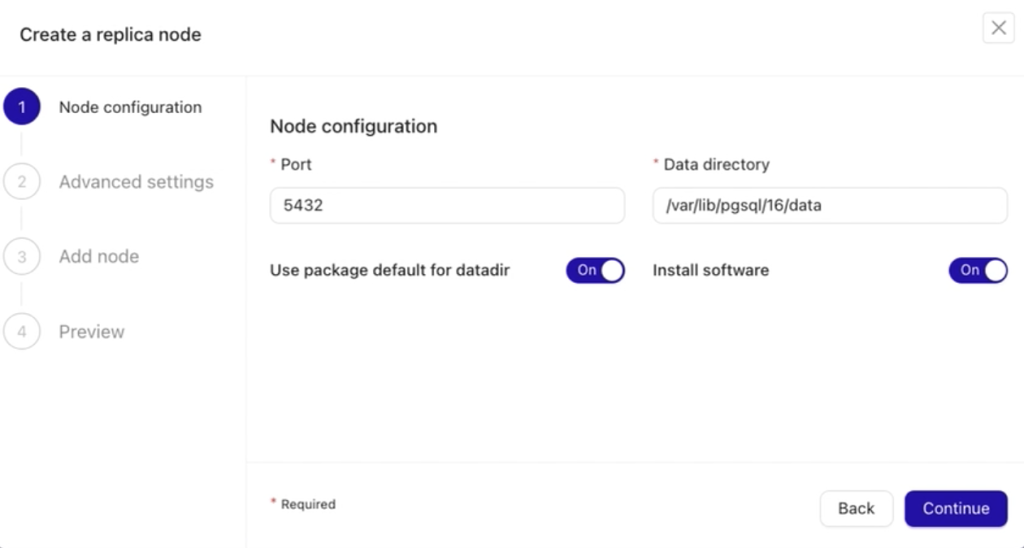
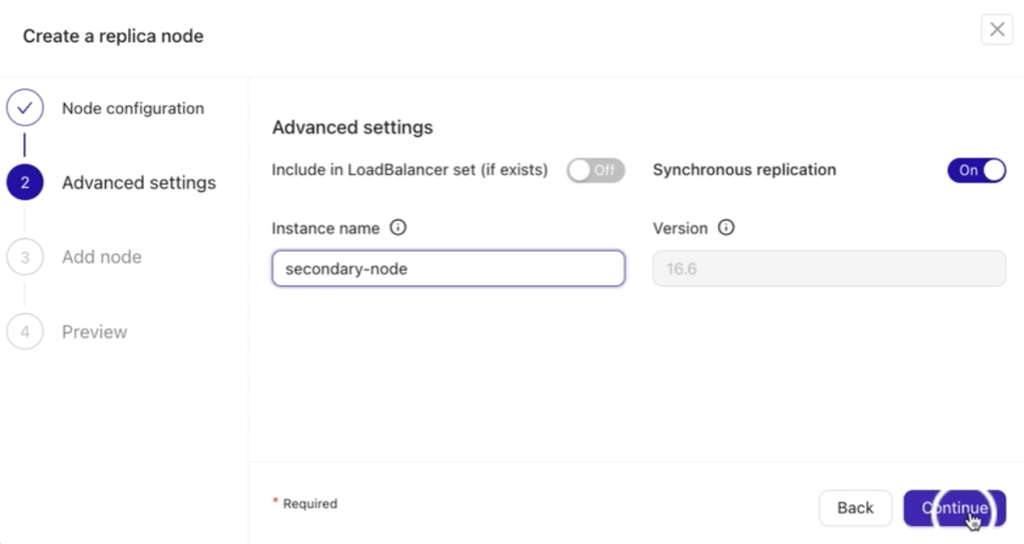
The next step is Advanced Settings. Here, you can configure additional options to tailor the replica node setup:
- Include a load balancer (if one exists or is already set up for the node).
- Enable synchronous replication for better data consistency.
- Specify an instance name (optional) for easier identification of the replica.
The version field is pre-filled and static, automatically detecting the PostgreSQL version from your current primary node, ensuring compatibility and consistency across the cluster.
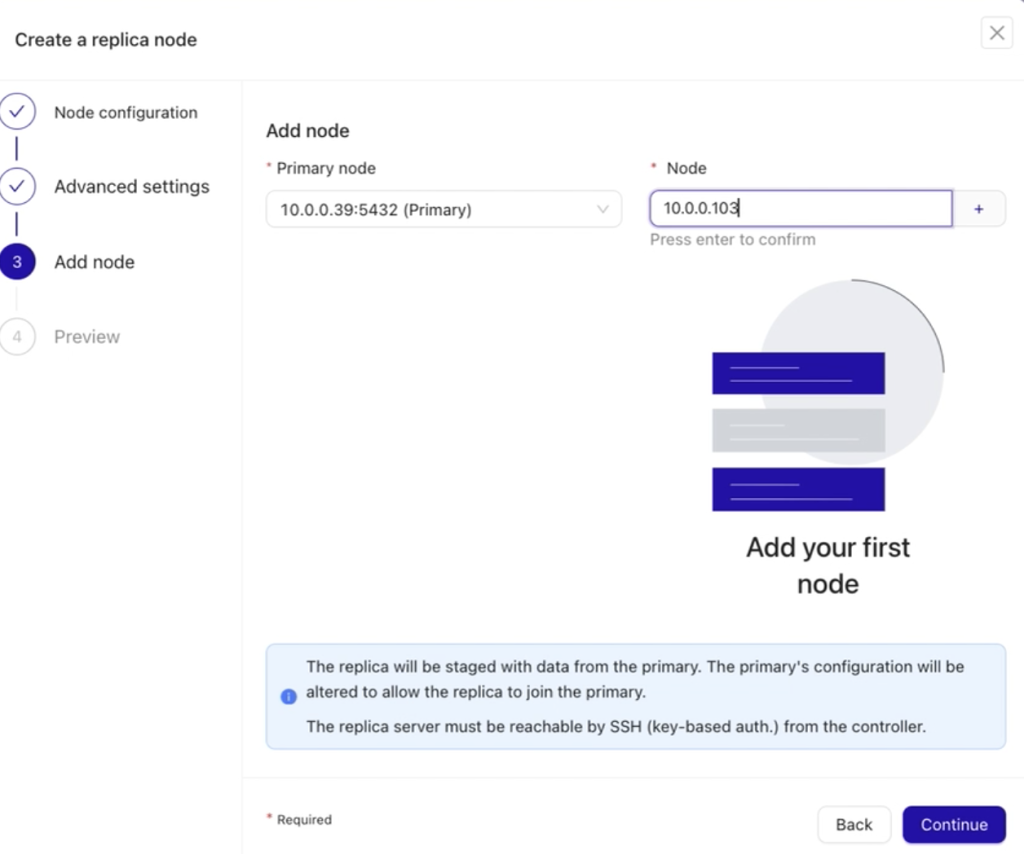
The third step is to Add Node. In this step, you’ll need to:
- Choose the primary node from your existing setup.
- Specify the IP address, hostname, or any valid Fully Qualified Domain Name (FQDN) in the Node field.
After entering the required details in the Node field, press the Enter key (↵ Enter) on your keyboard. This prompts ClusterControl to validate accessibility and establish a valid SSH connection between the ClusterControl host and the database node you wish to add.
Important: Ensure that passwordless SSH is already configured for smooth connectivity.
Once everything is validated, click the Continue button to move on to the fourth and final step.
Lastly, you’ll be presented with a preview of all the actions you’ve configured. This step allows you to carefully review your settings and ensure everything is correct before finalizing the process. Once confirmed, you can proceed to complete the setup.

If everything looks good and is properly configured, click the Finish button to complete the setup.
After setting up and adding your new replica, a job activity will appear in the background, indicating the progress of the task. To view more information, you can click the Job details button. Refer to the example below for guidance.
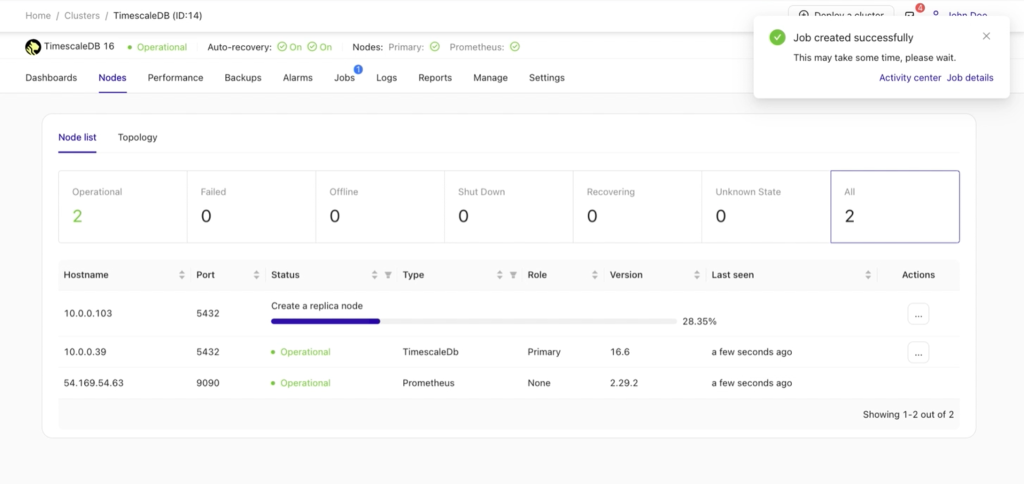
Job details:
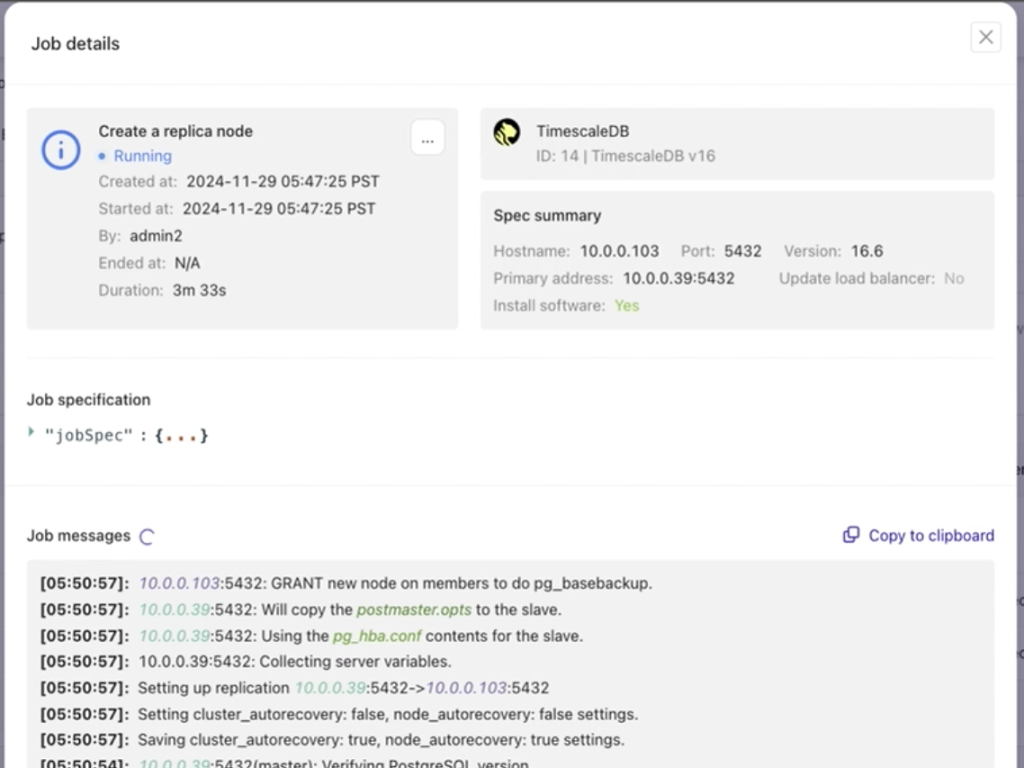
Once the job is complete, your replica is successfully added, and the setup is ready to use.
You can add or import additional replicas as needed, depending on your requirements or existing setup. For the purpose of this post, we will configure two replica nodes alongside the existing primary node, demonstrating how to expand your database cluster effectively.
Adding a Load Balancer to TimescaleDB
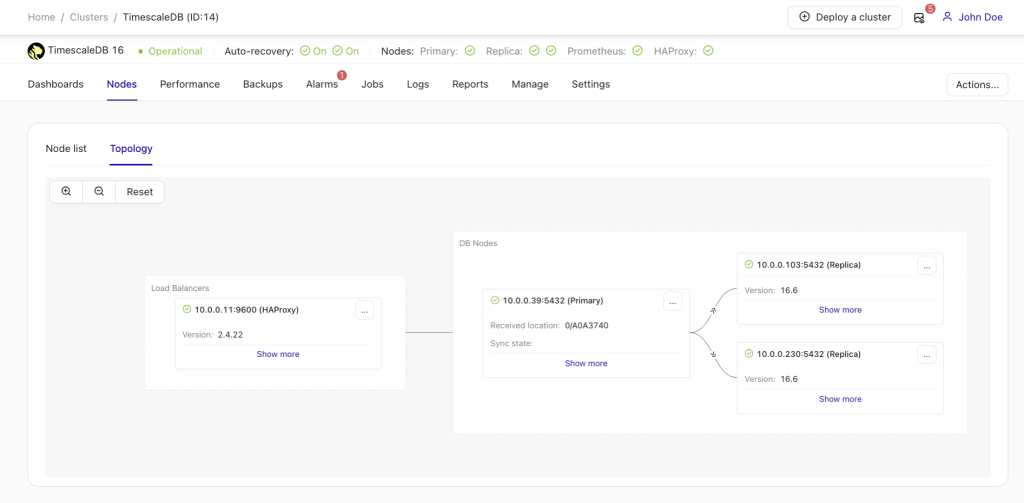
At this stage, your data is now distributed across multiple nodes, or even data centers if you’ve opted to distribute them across separate locations. We’ve scaled our cluster out to two additional read replica nodes as depicted below:
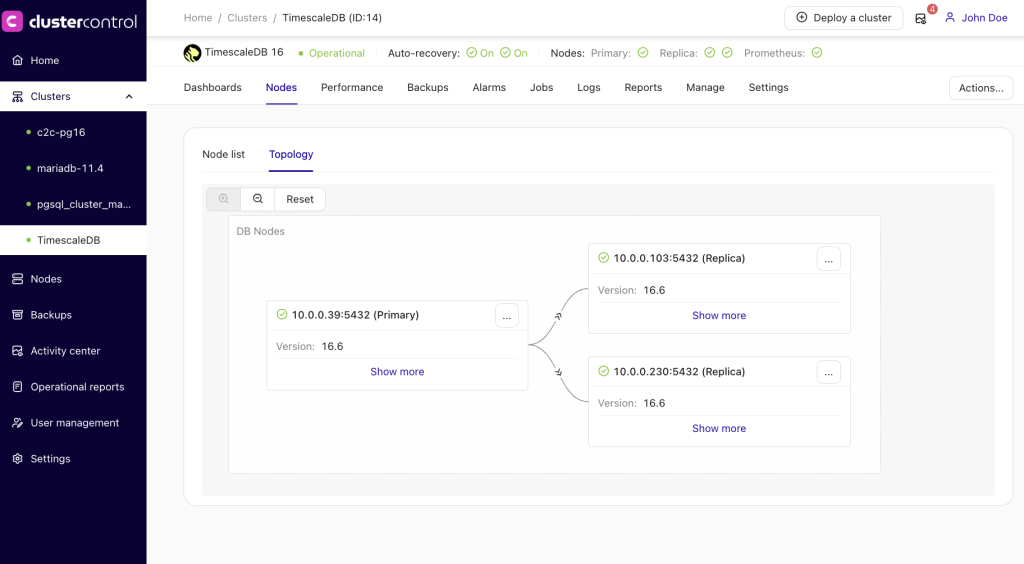
The question now is: how does the application determine which database node to access?
To manage this, we’ll use HAProxy and configure different ports for write and read operations.
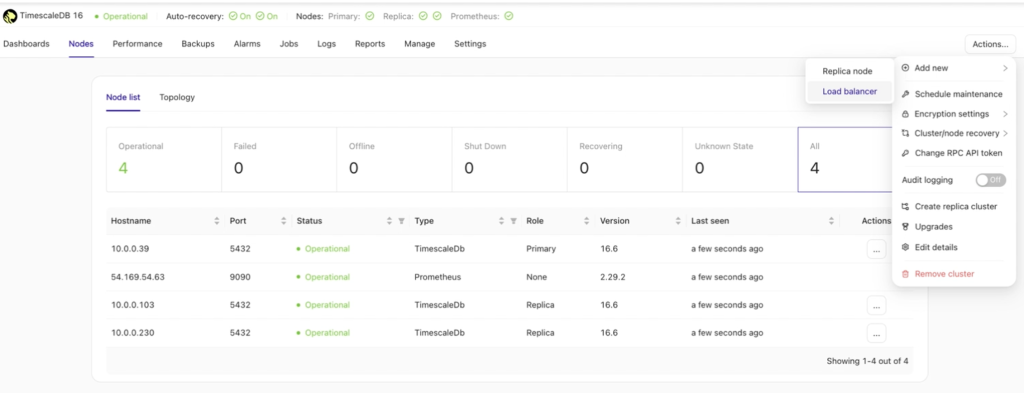
To set this up, navigate to the TimescaleDB cluster dashboard and follow these steps:
- Go to Actions.
- Select Add new.
- Choose Load balancer.
This configuration will ensure proper routing of database operations, optimizing the cluster’s performance and usability.
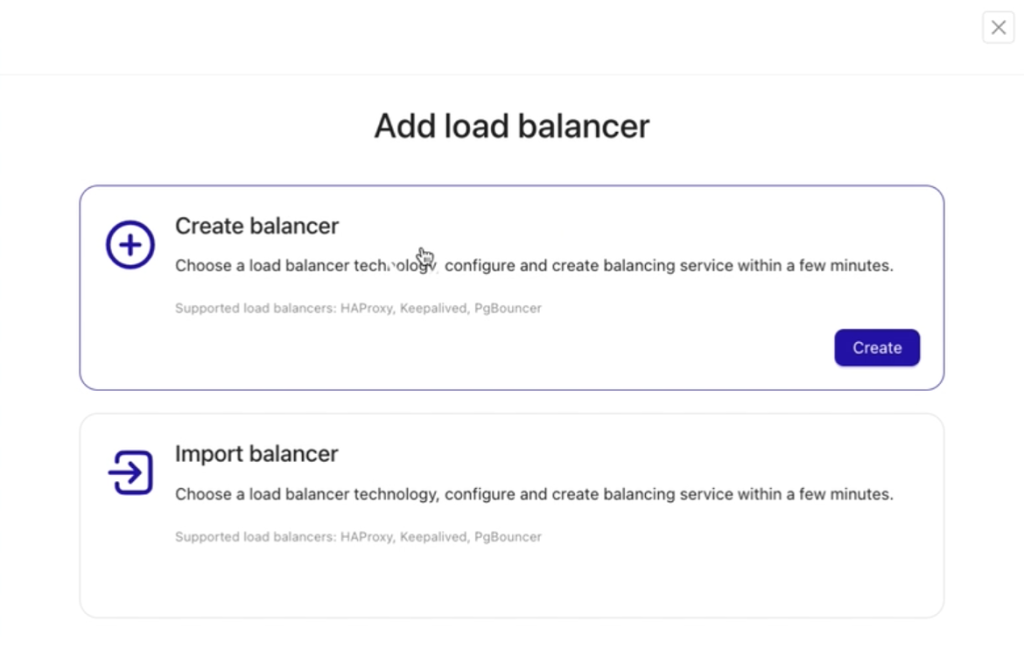
Since a load balancer has not yet been set up, select Create balancer for new installation and setup to configure a new load balancer.
Next, follow the five steps to set up the load balancer. The process is straightforward and user-friendly.
In the first step, ensure you specify the correct IP address/hostname or a valid FQDN of your target HAProxy node. If it meets your requirements, you can also choose to install HAProxy on one of your existing database nodes for convenience.
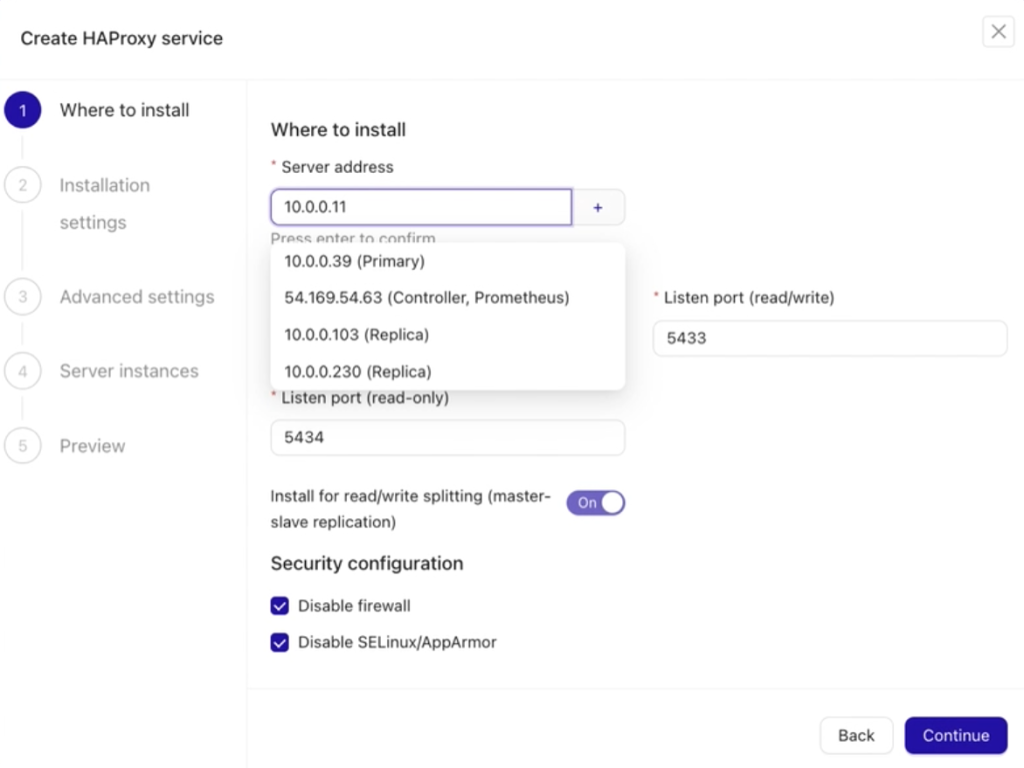
After clicking the Continue button, you can proceed to step three. If you’re unsure about specific configurations, it’s fine to leave the default values as they are and move forward.
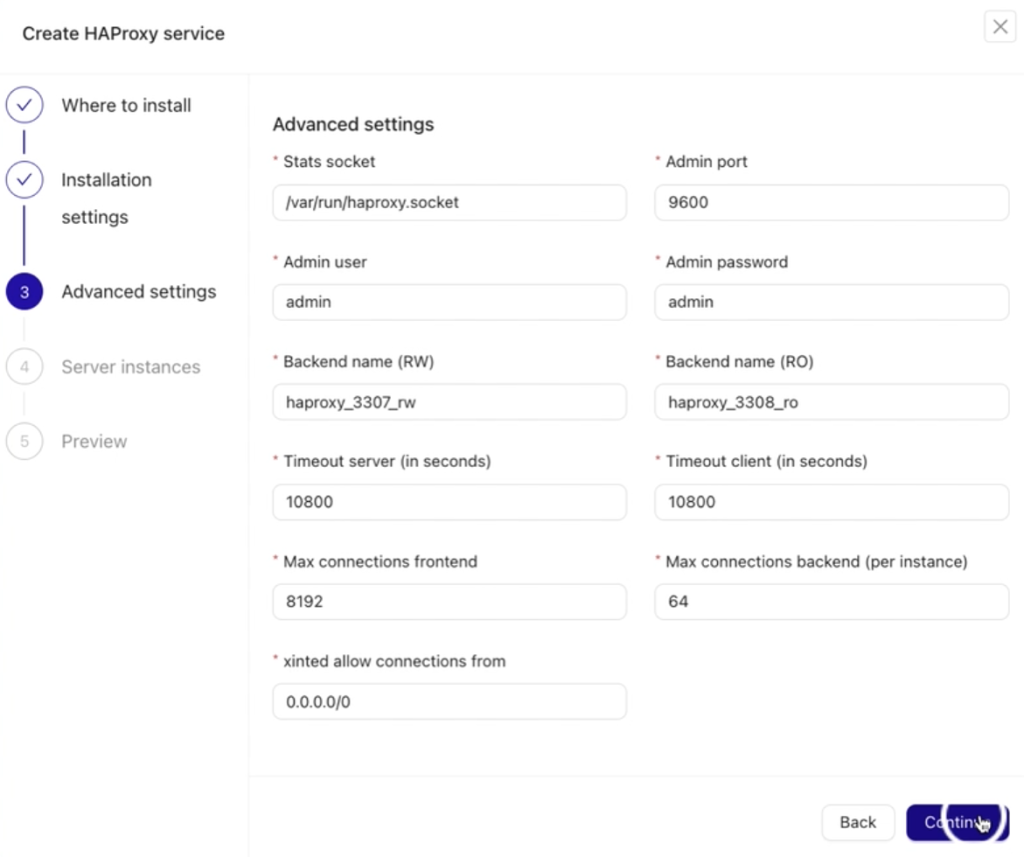
In step three, the Advanced Settings section includes various fields to configure your HAProxy node. These fields allow you to specify:
- Admin port for managing HAProxy.
- Admin user and password for secure access.
- Backend names for read and write nodes.
- Max connections and other performance-related parameters.
These settings ensure your HAProxy is tailored to your needs. Refer to the example below for more details.
After clicking the Continue button, proceed to step 4, where you specify the instances or database nodes to be balanced.
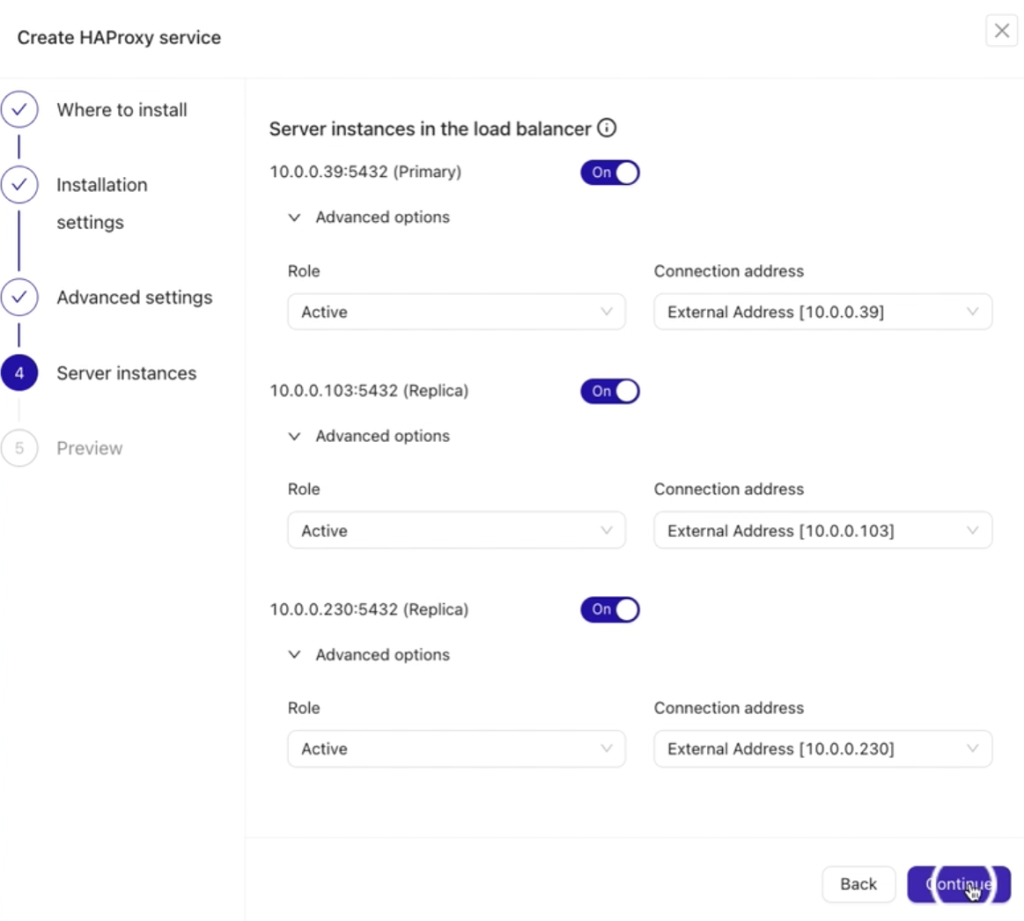
In this step:
- Clearly define each node’s Role.
- Provide the Connection Address for each node. Ensure these addresses align with your planned load balancing setup.
Ideally, the connection address should be locally native or the fastest to reach, minimizing latency during communication between the database nodes and the HAProxy load balancer.
Proper configuration here is essential for efficient load balancing and smooth database operations.
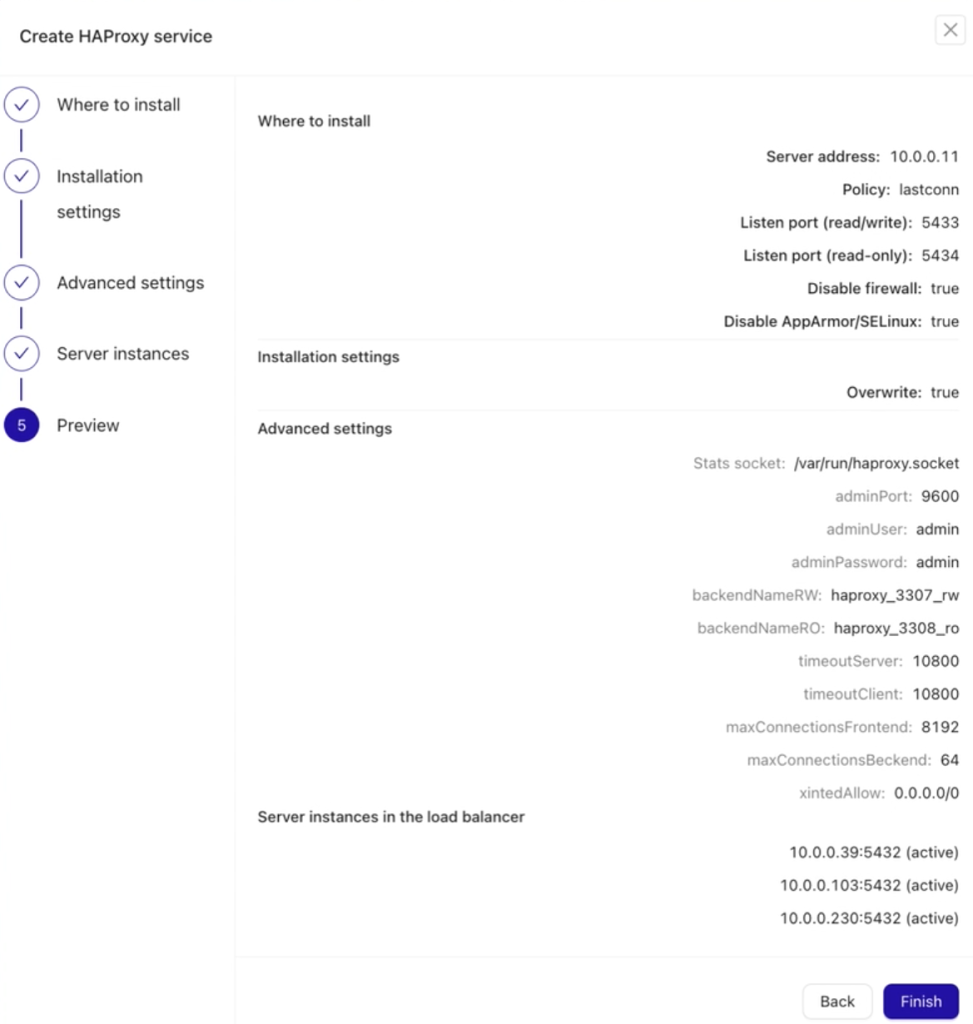
In the final step, Preview, review all your settings to ensure they are correct before deploying your HAProxy node. Once verified, proceed with deployment. See below:
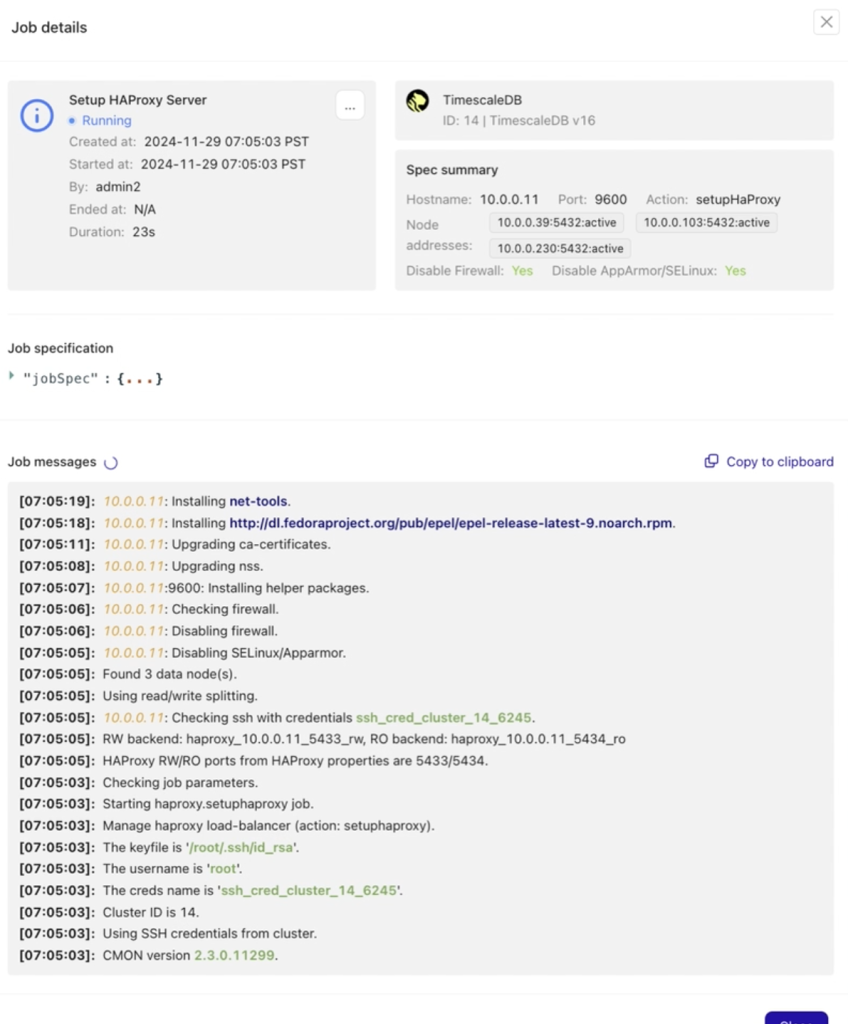
Be sure to follow the job activity log to monitor the deployment and setup of your HAProxy node and track the actions performed by ClusterControl.
After a few minutes, your cluster configuration should be ready. ClusterControl handles all the prerequisites and configurations needed to deploy the load balancer.
Once the deployment is successful, you’ll see the updated cluster topology, now featuring load balancing along with your additional read nodes. With more nodes added, ClusterControl automatically enables auto recovery, ensuring that if the master node goes down, failover operations will initiate automatically, maintaining high availability.
Conclusion
TimescaleDB is an open-source database designed to make SQL scalable for time-series data. Automating cluster extension is crucial for maintaining performance and efficiency. As demonstrated above, scaling TimescaleDB with ClusterControl is now a straightforward and seamless process.
Try it out yourself by signing up for ClusterControl free for 30 days – no credit card required. Stay updated on the latest in open-source database operations and best practices by following us on LinkedIn and X or by signing up for our monthly newsletter.



