blog
Scaling PostgreSQL Using Connection Poolers & Load Balancers

Scalability is the property of a system to handle a growing amount of demands by adding resources. The reasons for this amount of demands could be temporary, for example, if you are launching a discount on a sale, or permanent, for an increase of customers or employees. In any case, you should be able to add or remove resources to manage these changes on the demands or increase in traffic.
There are different approaches available to scale your database. In this blog, we will look at what these approches are and how to scale your PostgreSQL database using Connection Poolers and Load Balancers.
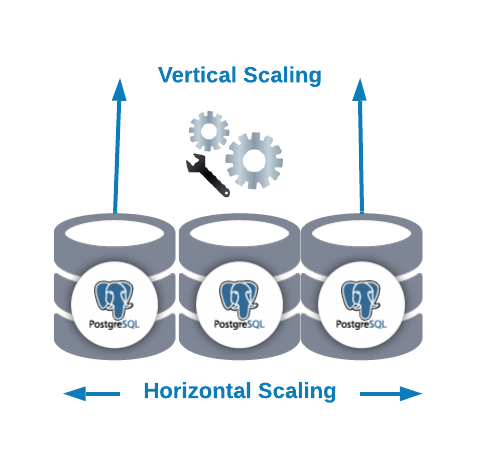
Horizontal and Vertical Scaling
There are two main ways to scale your database.
- Horizontal Scaling (scale-out): It is performed by adding more database nodes creating or increasing a database cluster. It can help you to improve the read performance balancing the traffic between the nodes.
- Vertical Scaling (scale-up): It is performed by adding more hardware resources (CPU, Memory, Disk) to an existing database node. It could be needed to change some configuration parameter to allow PostgreSQL to use a new or better hardware resource.
Connection Poolers and Load Balancers
In both Horizontal and Vertical Scaling, it could be useful to add an external tool to reduce the load on your database which will improve performance. Maybe it is not enough, but it is a good starting point. For this, it is a good idea to implement a connection pooler and a load balancer. I said “and” because they are designed for different roles.
A connection pooling is a method of creating a pool of connections and reuse them avoiding opening new connections to the database all the time, which will increase the performance of your applications considerably. PgBouncer is a popular connection pooler designed for PostgreSQL.
Using a Load Balancer is a way to have High Availability in your database topology and it is also useful to increase performance by balancing the traffic between the available nodes. For this, HAProxy is a good option for PostgreSQL, as it is an open-source proxy that can be used to implement high availability, load balancing, and proxying for TCP and HTTP based applications.
How to Implement a Combination of HAProxy, PgBouncer, and PostgreSQL
A combination of both technologies, HAProxy and PgBouncer, is probably the best way to scale and improve performance in your PostgreSQL environment. So, we will see how to implement it using the following architecture:
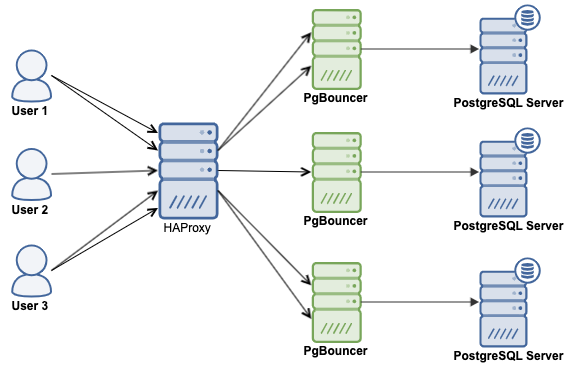
We will assume you have ClusterControl installed, if not, you can go to the official site, or even refer to the official documentation to install it.
First, you need to deploy your PostgreSQL cluster with HAProxy in front of it. For this, please follow the steps in this blog post to deploy both PostgreSQL and HAProxy using ClusterControl.
At this point, you will have something like this:
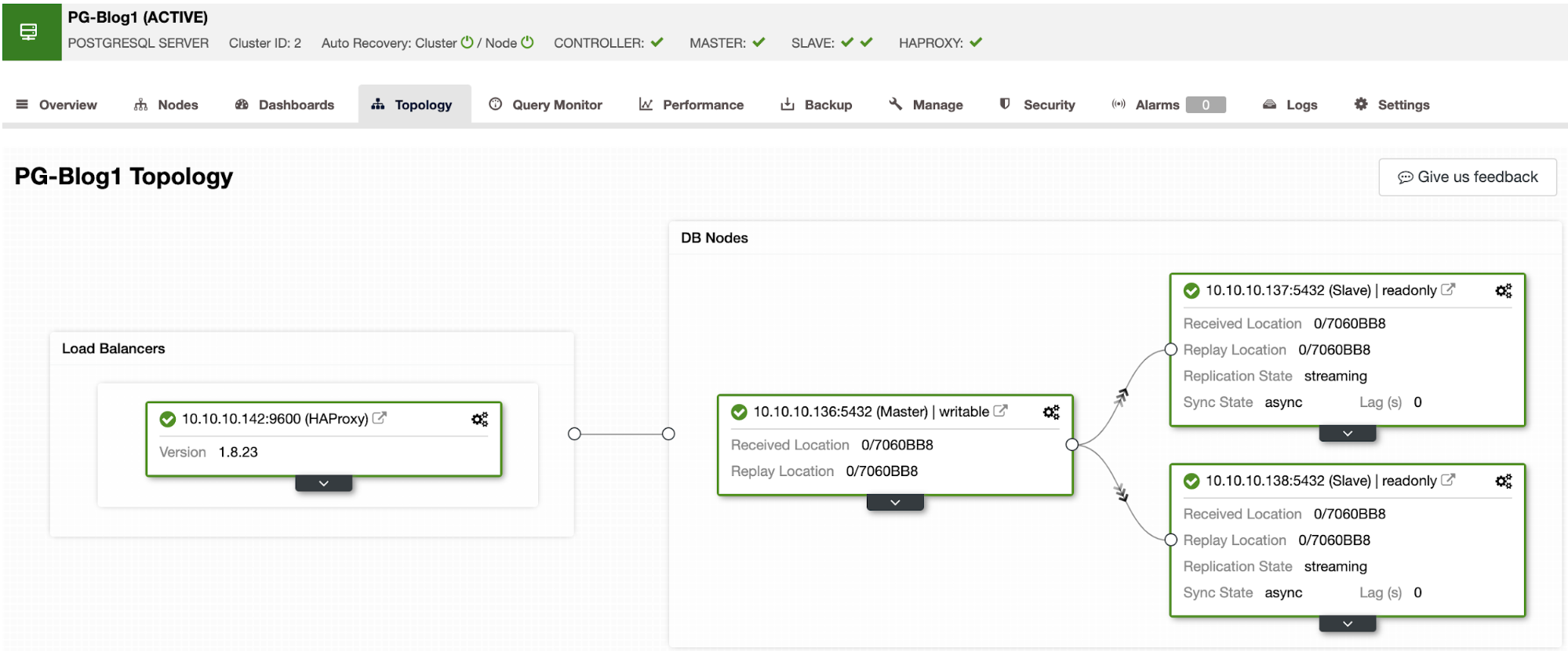
Now, you can install PgBouncer on each database node or on an external machine.
To get the PgBouncer software you can go to the PgBouncer download section, or use the RPM or DEB repositories. For this example, we will use CentOS 8 and will install it from the official PostgreSQL repository.
First, download and install the corresponding repository from the PostgreSQL site (if you don’t have it in place yet):
$ wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
$ rpm -Uvh pgdg-redhat-repo-latest.noarch.rpmThen, install the PgBouncer package:
$ yum install pgbouncerWhen it is completed, you will have a new configuration file located in /etc/pgbouncer/pgbouncer.ini. As a default configuration file you can use the following example:
$ cat /etc/pgbouncer/pgbouncer.ini
[databases]
world = host=127.0.0.1 port=5432 dbname=world
[pgbouncer]
logfile = /var/log/pgbouncer/pgbouncer.log
pidfile = /var/run/pgbouncer/pgbouncer.pid
listen_addr = *
listen_port = 6432
auth_type = md5
auth_file = /etc/pgbouncer/userlist.txt
admin_users = admindbAnd the authentication file:
$ cat /etc/pgbouncer/userlist.txt
"admindb" "root123"This is just a basic example. To get all the available parameters, you can check the official documentation.
So, in this case, I have installed PgBouncer in the same database node, listening in all IP addresses, and it connects to a PostgreSQL database called “world”. I am also managing the allowed users in the userlist.txt file with a plain-text password that can be encrypted if needed.
To start the PgBouncer service, you just need to run the following command:
$ pgbouncer -d /etc/pgbouncer/pgbouncer.iniNow, run the following command using your local information (port, host, username, and database name) to access the PostgreSQL database:
$ psql -p 6432 -h 127.0.0.1 -U admindb world
Password for user admindb:
psql (12.4)
Type "help" for help.
world=#This is a basic topology. You can improve it, for example, adding two or more load balancer nodes to avoid a single point of failure, and using some tool like “Keepalived”, to ensure the availability. It can also be done using ClusterControl.
For more information about PgBouncer and how to use it, you can refer to this blog post.
Conclusion
If you need to scale your PostgreSQL cluster, adding HAProxy and PgBouncer is a good way to scale-out and scale-up at the same time, as you can add more hot standby nodes to balance the traffic and you will improve performance reusing opened connections.
ClusterControl provides a whole range of features, from monitoring, alerting, automatic failover, backup, point-in-time recovery, backup verification, to scaling of read replicas. This can help you to scale your PostgreSQL database in a horizontal or vertical way from a friendly and intuitive UI.



