blog
PostgreSQL Schema Management Basics

Are you wondering what Postgresql schemas are and why they are important and how you can use schemas to make your database implementations more robust and maintainable? This article will introduce the basics of schemas in Postgresql and show you how to create them with some basic examples. Future articles will delve into examples of how to secure and use schemas for real applications.
Firstly, to clear up potential terminology confusion, let’s understand that in the Postgresql world, the term “schema” is maybe somewhat unfortunately overloaded. In the broader context of relational database management systems (RDBMS), the term “schema” might be understood to refer to the overall logical or physical design of the database, i.e., the definition of all the tables, columns, views, and other objects that constitute the database definition. In that broader context a schema might be expressed in an entity-relationship (ER) diagram or a script of data definition language (DDL) statements used to instantiate the application database.
In the Postgresql world, the term “schema” might be better understood as a “namespace”. In fact, in the Postgresql system tables, schemas are recorded in table columns called “name space”, which, IMHO, is more accurate terminology. As a practical matter, whenever I see “schema” in the context of Postgresql I silently reinterpret it as saying “name space”.
But you may ask: “What’s a name space?” Generally, a name space is a rather flexible means of organizing and identifying information by name. For example, imagine two neighboring households, the Smiths, Alice and Bob, and the Jones, Bob and Cathy (cf. Figure 1). If we used only first names, it might get confusing as to which person we meant when talking about Bob. But by adding the surname name, Smith or Jones, we uniquely identify which person we mean.
Oftentimes, name spaces are organized in a nested hierarchy. This allows efficient classification of vast amounts of information into very finely-grained structure, such as, for example the internet domain name system. At the top level, “.com”, “.net”, “.org”, “.edu”, and etc. define broad name spaces within which are registered names for specific entities, so for example, “severalnines.com” and “postgresql.org” are uniquely defined. But under each of those there are a number of common sub-domains such as “www”, “mail”, and “ftp”, for example, which alone are duplicative, but within the respective name spaces are unique.
Postgresql schemas serve this same purpose of organizing and identifying, however, unlike the second example above, Postgresql schemas cannot be nested in a hierarchy. While a database may contain many schemas, there is only ever one level and so within a database, schema names must be unique. Also, every database must include at least one schema. Whenever a new database is instantiated, a default schema named “public” is created. The contents of a schema include all the other database objects such as tables, views, stored procedures, triggers, and etc. To visualize, refer to Figure 2, which depicts a matryoshka doll-like nesting showing where schemas fit into the structure of a Postgresql database.
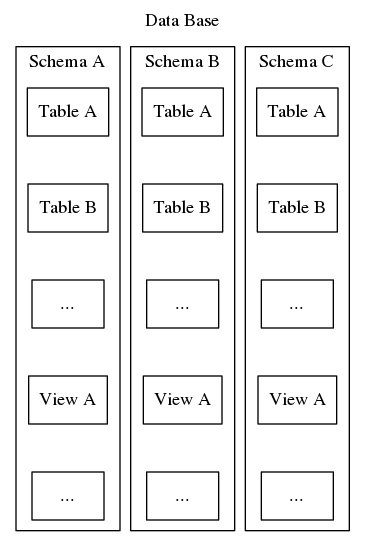
Besides simply organizing database objects into logical groups to make them more manageable, schemas serve the practical purpose of avoiding name collision. One operational paradigm involves defining a schema for each database user so as provide some degree of isolation, a space where users can define their own tables and views without interfering with each other. Another approach is to install third party tools or data base extensions in individual schemas so as to keep all the related components logically together. A later article in this series will detail a novel approach to robust application design, employing schemas as a means of indirection to limit exposure of the database physical design and instead present a user interface which resolves synthetic keys and facilitates long-term maintenance and configuration management as system requirements evolve.
Let’s do some code!
The simplest command to create a schema within a database is
CREATE SCHEMA hollywood;This command requires create privileges in the database, and the newly-created schema “hollywood” will be owned by user invoking the command. A more complex invocation may include optional elements specifying a different owner, and may even include DDL statements instantiating data base objects within the schema all in one command!
The general format is
CREATE SCHEMA schemaname [ AUTHORIZATION username ] [ schema_element [ ... ] ]where “username” is who will own the schema and “schema_element” may be one of certain DDL commands (refer to Postgresql documentation for specifics). Superuser privileges are required to use the AUTHORIZATION option.
So for example, to create a schema named “hollywood” containing a table named “films” and view named “winners” in one command, you could do
CREATE SCHEMA hollywood
CREATE TABLE films (title text, release date, awards text[])
CREATE VIEW winners AS
SELECT title, release FROM films WHERE awards IS NOT NULL;Additional database objects may be subsequently created directly, for example an additional table would be added to the schema with
CREATE TABLE hollywood.actors (name text, dob date, gender text);Note in the above example the prefixing of the table name with the schema name. This is required because by default, that is without explicit schema specification, new database objects are created within whatever is the current schema, which we will cover next.
Recall how in the first name space example above, we had two persons named Bob, and we described how to deconflict or distinguish them by including the surname. But within each of the Smith and Jones households separately, each family understands “Bob” to refer to the one that goes with that particular household. So for instance in the context of each respective household, Alice does not need to address her husband as Bob Jones, and Cathy need not refer to her husband as Bob Smith: they can each just say “Bob”.
The Postgresql current schema is kind of like the household in the above example. Objects in the current schema can be referenced unqualified, but referring to similarly-named objects in other schemas requires qualifying the name by prefixing the schema name as above.
The current schema is derived from the “search_path” configuration parameter. This parameter stores a comma-separated list of schema names and can be examined with the command
SHOW search_path;or set to a new value with
SET search_path TO schema [, schema, ...];The first schema name in the list is the “current schema” and is where new objects are created if specified without schema name qualification.
The comma-separated list of schema names also serves to determine the search order by which the system locates existing unqualified named objects. For example, back to the Smith and Jones neighborhood, a package delivery addressed just to “Bob” would require visiting at each household until the first resident named “Bob” is found. Note, this might not be the intended recipient. The same logic applies for Postgresql. The system searches for tables, views, and other objects within schemas in the order of the search_path, and then the first found name match object is used. Schema-qualified named objects are used directly without reference to the search_path.
In the default configuration, querying the search_path configuration variable reveals this value
SHOW search_path;
Search_path
--------------
"$user", publicThe system interprets the first value shown above as the current logged in user name and accommodates the use case mentioned earlier where each user is allocated a user-named schema for a work space separate from other users. If no such user-named schema has been created, that entry is ignored and the “public” schema becomes the current schema where new objects are created.
Thus, back to our earlier example of creating the “hollywood.actors” table, if we had not qualified the table name with the schema name, then the table would have been created in the public schema. If we anticipated creating all objects within a specific schema, then it might be convenient to set the search_path variable such as
SET search_path TO hollywood,public;facilitating the shorthand of typing unqualified names to create or access database objects.
There is also a system information function which returns the current schema with a query
select current_schema();In case of fat-fingering the spelling, the owner of a schema may change the name, provided the user also has create privileges for the database, with the
ALTER SCHEMA old_name RENAME TO new_name;And lastly, to delete a schema from a database, there is a drop command
DROP SCHEMA schema_name;The DROP command will fail if the schema contains any objects, so they must be deleted first, or you can optionally recursively delete a schema all its contents with the CASCADE option
DROP SCHEMA schema_name CASCADE;These basics will get you started with understanding schemas!



