blog
PostgreSQL: Query Parallelism in Action

Here we are. Almost two decades into the 21st century and the need for more computing power is still an issue. Technology companies are pounding the pavement to tackle this massive problem head-on. Hardware engineers have found a solution by altering the way they design and manufacture a computer’s central processing unit (CPU). They now contain multiple cores, which allows for concurrency to take place. In turn, software developers have adjusted the way they write programs to adapt to this change in hardware.
The PostgreSQL community has taken full advantage of these multi-core CPUs to improve query performance. By merely updating to versions 9.6 or higher, you can utilize a feature called query parallelism to perform various operations. It breaks down tasks into smaller parts and spreads each task across multiple CPU cores. Each core can process the tasks at the same time. Due to hardware limitations, this is the only way to improve computer performance as we move into the future.
Before using the parallelism feature in the PostgreSQL database, it’s essential to recognize how it makes a query parallel. You will be able to debug and resolve any problems that arise.
How Does Query Parallelism Work?
To have a better understanding of how parallelism is executed, it’s a good idea to start at the client level. To access PostgreSQL, a client must send a connection request to the database server called the postmaster. The postmaster will complete authentication and then fork to create a new server process for each connection. It is also responsible for creating an area of shared memory which contains a buffer pool. The buffer pool oversees the transfer of data between the shared memory and storage. Therefore, the moment a connection is established, the buffer pool will transfer data and allow query parallelism can take place.
It is not necessary for all queries to be parallel. There are instances where only a small amount of data is needed, and it can be quickly processed by only one core. This feature is only used when a query will take a substantial amount of time to complete. The database optimizer determines whether parallelism should be executed. If it is necessary, the database will use an additional portion of memory called dynamic shared memory (DSM). This allows for the leader process and the parallel aware worker processes to divide the query amongst multiple cores and gather pertinent data.
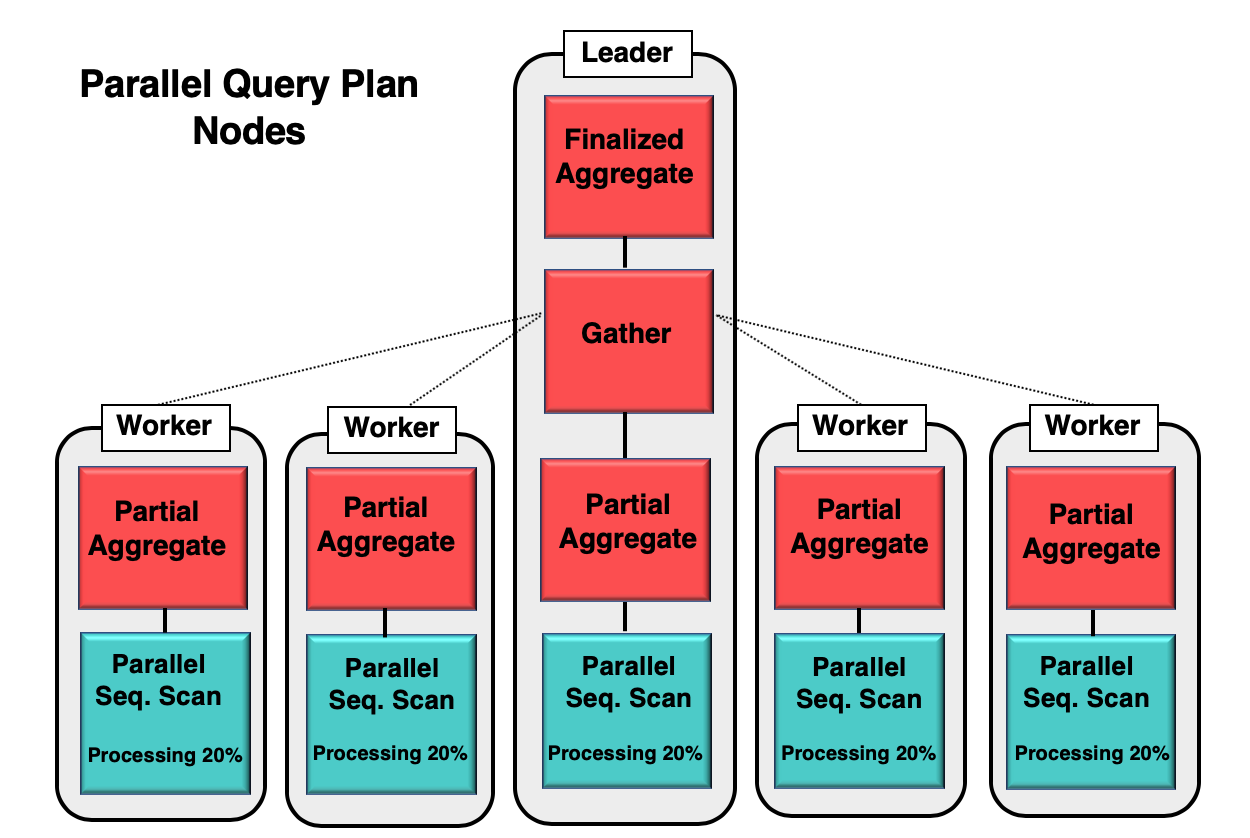
Figure 1 gives you an example of how parallelism takes place inside the database. The leader process runs the initial query, while the individual worker processes are initiating a copy of the same process. The partial aggregate node, or CPU core, is responsible for implementing the parallel sequential scan of the database table.
In this case, each sequential scan node is processing 20% of data in 8kb blocks. These same nodes can coordinate their activity by using a technique called parallel aware. Each node has full knowledge of what data has already been processed, and what data needs to be scanned in the table to complete the query. Once the tuples are collected in full, it is sent to the gather node to be compiled and finalized.
Parallel Operations
Various types of queries can be used to fetch data from a database to produce result-sets. Here are specific operations that give you the ability to leverage the use of multiple cores effectively.
Sequential Scan
This is operation reads data in a table from the beginning to the end to gather data. It evenly distributes the workload between multiple cores to increase the queries processing speed. It is aware of each cores activity, making it easier to determine if the entire query has been completed. The gather node then receives the data extracted based on the query.
Aggregation
A standard operation, which takes a large amount of data and condenses it into a smaller number of rows. This happens during the parallel processing by only extracting from a table or indexes, the appropriate information based on the query. Performing an average of specific data is an excellent example of aggregation.
Hash Join
A technique that is used to join the data between two tables. It is the fastest join algorithm, which is typically performed with a small table and a large one. You first create a hash table and load all the data from one table into there. Then you can scan all the data from the hash and second table, using parallel sequential scan. Each tuple that’s extracted from the scan is compared to the hash table to see if there is a match. If a match is identified, the data is joined together. With the release of PostgreSQL 11, using parallelism to complete a hash join takes about one-third of its previous processing time.
Merge Join
If the optimizer determines that a hash join is going to exceed the memory capacity, it will perform a merge join instead. The process involves scanning through two sorted lists at the same time and joins together the same elements. If the items are not equal, the data will not be joined together.
Nested Loop Join
This operation is used when you had to join two tables containing different programming languages, such as Quick Basic, Python, etc. Each table is scanned and processed by using multiple cores. If the data matches, it’s sent to the gather node to be joined. The indexes are scanned as well, which is why this process contains multiple loops to retrieve the data. On average, it will take only one third the time to complete the join by using the parallel process.
B-tree Index Scan
This operation scans through a tree of sorted data to locate specific information. This process takes longer than the typical sequential scan because there is a lot of waiting while looking for records. However, the work of scanning for the appropriate data is split between multiple processors.
Bitmap Heap Scan
You can merge multiple indexes is by using this operation. You first want to create the equivalent number of bitmaps, as you have indexes. For example, if you have three indexes, you must first create three bitmaps. Each bitmap will fetch and compile tuples based in the query.
Partition Parallelism
There is another form of parallelism that can take place within PostgreSQL database. However, it doesn’t come from scanning tables and breaking up the tasks. You can partition or divide the data by specific values. For example, you can take the value buyers, and have one single core process the data only within that value. That way, you know precisely what each core is processing at any given time.
Hash Partitioning
This operation is used by spreading table rows into sub-tables. Again, the divide generally determined by a distinct value or value list from a table. This is an excellent method to use If you do not have efficient storage management technique across all your devices. You would want to use partitioning to randomly distribute the data to prevent I/O bottlenecks.
Partition-wise Join
A technique used to break down tables by partitions and joining them by matching together similar partitions. For example, you may have a large table of buyers from all across the United States. You can first break down the table by different cities and then join some cities together based on the region in each state. Partition-wise join simplifies your data and allows for the manipulation of tables to take place.
Parallel Unsafe
PostgreSQL 11 automatically executes query parallelism if the optimizer determines that this is the fastest way to complete the query. The higher the PostgreSQL version you are using, the more parallel capability your database will have. Unfortunately, not all queries should be executed in a parallel manner, even if it has the ability. The type of query you’re performing may have specific limitations and it will require that only one core complete all the processing. This will slow the performance of your system, but it will guarantee that the data received is whole.
To ensure that your queries are never put at risk, developers have created a function called parallel unsafe. You can manually override the database optimizer and request for the query to never be parallel. The process of parallelism will not be performed.
Parallelism within the PostgreSQL database is a feature that is only getting better with each database version. Even though the future of technology is uncertain, it seems as though the use of this feature is here to stay.
For more information, you can check out the following…
- https://www.postgresql.org/docs/10/parallel-query.html
- https://www.postgresql.org/docs/10/how-parallel-query-works.html
- https://www.bbc.com/news/business-42797846
- https://www.technologyreview.com/s/421186/why-cpus-arent-getting-any-faster/
- https://www.percona.com/blog/2019/02/21/parallel-queries-in-postgresql/
- https://malisper.me/postgres-merge-joins/
- https://www.enterprisedb.com/blog/partition-wise-joins-“divide-and-conquer-joins-between-partitioned-table



