blog
What's New in PostgreSQL 11

PostgreSQL 11 was released on October 10th, 2018, and on schedule, marking the 23rd anniversary of the increasingly popular open source database.
While a complete list of changes is available in the usual Release Notes, it is worth checking out the revamped Feature Matrix page which just like the official documentation has received a makeover since its first version which makes it easier to spot changes before diving into the details.
For example on the Release Notes page, the “Channel binding for SCAM authentication” is buried under the Source Code while the matrix has it under the Security section. For the curious here’s a screenshot of the interface:
Additionally, the Bucardo Postgres Release Notes page linked above, is handy in its own way, making it easy to search for a keyword across all versions.
What’s New? With literally hundreds of changes, I will go through the differences listed in the Feature Matrix.
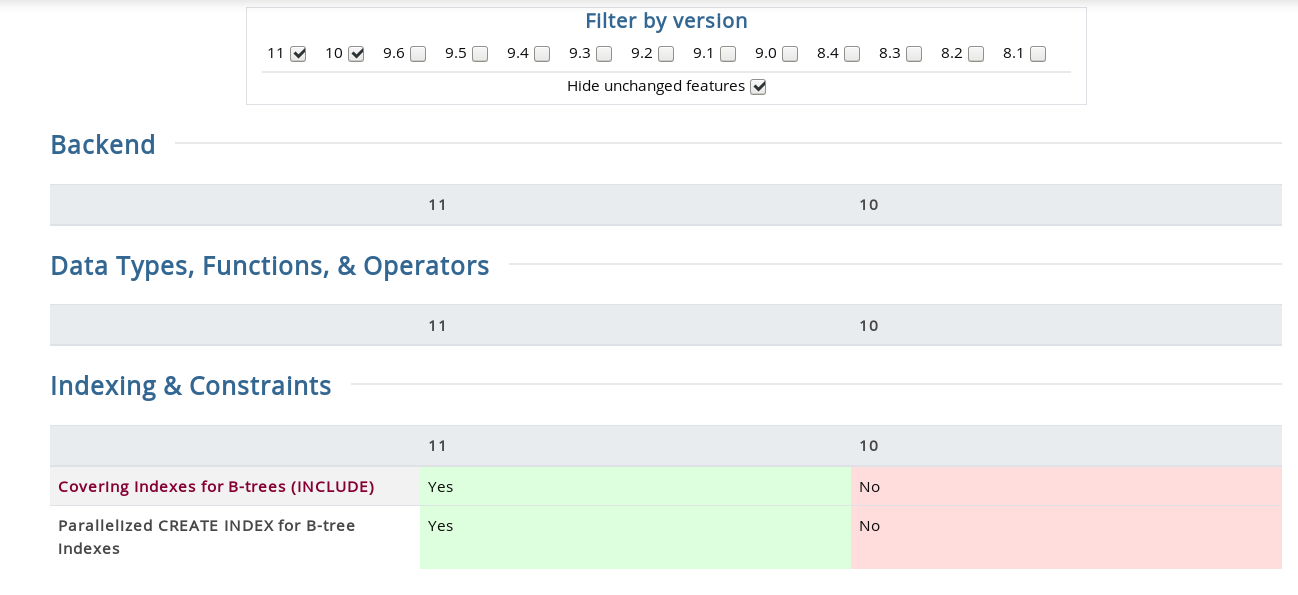
Covering Indexes for B-trees (INCLUDE)
CREATE INDEX received the INCLUDE clause which allows indexes to include non-key columns. Its use case for frequent identical queries, is well described in Tom Lane’s commit from November 22nd, which updates the development documentation (meaning that the current PostgreSQL 11 documentation doesn’t have it yet), so for the full text refer to section 11.9. Index-Only Scans and Covering Indexes in the development version.
Parallelized CREATE INDEX for B-tree Indexes
As alluded in the name, this feature is only implemented for the B-tree indexes, and from Robert Haas’ commit log we learn that the implementation may be refined in the future. As noted from the CREATE INDEX documentation, while both parallel and concurrent index creation methods take advantage of multiple CPUs, in the case of CONCURRENT only the first table scan will be performed in parallel.
Related to this new feature are the configuration parameters maintenance_work_mem and maintenance_parallel_maintenance_workers.
Lastly, the number of parallel workers can be set per table using the ALTER TABLE command and specifying a value for parallel_workers.
Just-In-Time (JIT) Compilation for Expression Evaluation and Tuple Deforming
With its own JIT chapter in the documentation, this new feature relies on PostgreSQL being compiled with LLVM support (use pg_config to verify).
The topic of JIT in PostgreSQL is complex enough (see the JIT README reference in the documentation) to require a dedicated blog, in the meantime, the CitusData blog on JIT is a very good read for those interested to dive deeper into the subject.
Parallelized Hash Joins
This performance improvement to parallel queries is the result of adding a shared hash table, which as Thomas Munro explains in his Parallel Hash for PostgreSQL blog, avoids partitioning the hash table providing that it fits in work_mem, which thus far for PostgreSQL appears to be a better solution than the partition-first algorithm. The same blog describes the PostgreSQL architecture obstacles that the author had to overcome in his quest for add parallelization to hash joins that speaks to the complexity of the work that was required in order to implement this feature.
Default Partition
This is a catch all partition to store rows that do not match any other defined partition. In cases where a new partition is added a CHECK constraint is recommended in order to avoid a scan of the default partition which can be slow when the default partition contains a large number of rows.
The default partition behavior is explained in the documentation of ALTER TABLE and CREATE TABLE.
Partitioning by a Hash Key
Also called hash partitioning, and as pointed out in the commit message, the feature allows partitioning of tables in such a way that partitions will hold a similar number of rows. This is achieved by providing a modulus, which in the more simple scenario is recommended to be equal to the number of partitions, and the remainder should be different for each partition.
For more details and an example see the CREATE TABLE documentation page.
Support for PRIMARY KEY, FOREIGN KEY, Indexes, and Triggers on Partitioned Tables
Table partitioning is already a big step in improving performance of large tables, and the addition of these features addresses the limitations that partitioned tables have had since PostgreSQL 10 when the modern-style “declarative partitioning” was introduced.
Work by Alvaro Herrera is underway for allowing foreign keys to reference primary keys, and is scheduled for the next PostgreSQL major version 12.
UPDATE on a Partition Key
As explained in the patch commit log this update prevents PostgreSQL from throwing an error when an update to the partition key invalidates a row, and instead the row will be moved to an appropriate partition.
Channel Binding for SCRAM Authentication
This is a security measure aim at preventing man-in-the-middle attacks in SASL Authentication and is thoroughly detailed in the author’s blog. The feature requires a minimum of OpenSSL 1.0.2.
CREATE PROCEDURE and CALL Syntax for SQL Stored Procedures
PostgreSQL has had CREATE FUNCTION since 1996, with version 1.0.1, however, functions cannot handle transactions. As mentioned in the documentation, the CREATE PROCEDURE command is not fully compatible with the SQL standard.
Note: Stay tuned for an upcoming blog which deep dives into this feature
Conclusion
PostgreSQL 11 major updates focus on performance improvements through parallel execution, partitioning and Just-In-Time compilation. Stored procedures allow for full transaction control and can be written in a variety of PL languages.



