blog
PostgreSQL Backup Method Features in AWS S3

Amazon released S3 in early 2006 and the first tool enabling PostgreSQL backup scripts to upload data in the cloud — s3cmd — was born just shy of a year later. By 2010 (according to my Google search skills) Open BI blogs about it. It is then safe to say that some of the PostgreSQL DBAs have been backing up data to AWS S3 for as long as 9 years. But how? And what has changed in that time? While s3cmd is still referenced by some in the context of known PostgreSQL backup tools, the methods have seen changes allowing for better integration with either the filesystem or PostgreSQL native backup options in order to achieve the desired recovery objectives RTO and RPO.
Why Amazon S3
As pointed out throughout the Amazon S3 documentation (S3 FAQs being a very good starting point) the advantages of using the S3 service are:
- 99.999999999 (eleven nines) durability
- unlimited data storage
- low costs (even lower when combined with BitTorrent)
- inbound network traffic free of charge
- only outbound network traffic is billable
AWS S3 CLI Gotchas
The AWS S3 CLI toolkit provides all the tools needed for transferring data in and out of the S3 storage, so why not use those tools? The answer lies in the Amazon S3 implementation details which include measures for handling the limitations and constraints related to object storage:
- 5TB max size per stored object
- 5GB max size of a PUT object
- multipart upload recommended for objects larger than 100MB
- choose an appropriate storage class in accordance with the S3 performance chart
- take advantage of the S3 Lifecycle
- S3 Data Consistency Model
As an example refer to the aws s3 cp help page:
–expected-size (string) This argument specifies the expected size of a stream in terms of bytes. Note that this argument is needed only when a stream is being uploaded to s3 and the size is larger than 5GB. Failure to include this argument under these conditions may result in a failed upload due to too many parts in upload.
Avoiding those pitfalls requires in-depth knowledge of the S3 ecosystem which is what the purpose-built PostgreSQL and S3 backup tools are trying to achieve.
PostgreSQL Native Backup Tools With Amazon S3 Support
S3 integration is provided by some of the well-known backup tools, implementing the PostgreSQL native backup features.
BarmanS3
BarmanS3 is implemented as Barman Hook Scripts. It does rely on AWS CLI, without addressing the recommendations and limitations listed above. The simple setup makes it a good candidate for small installations. The development is somewhat stalled, last update about a year ago, making this product a choice for those already using Barman in their environments.
S3 Dumps
S3dumps is an active project, implemented using Amazon’s Python library Boto3. Installation is easily performed via pip. Although relying on the Amazon S3 Python SDK, a search of the source code for regex keywords such as multi.*part or storage.*class doesn’t reveal any of the advanced S3 features, such as multipart transfers.
pgBackRest
pgBackRest implements S3 as a repository option. This is one of the well-known PostgreSQL backup tools, providing a feature-rich set of backup options such as parallel backup and restore, encryption, and tablespaces support. It is mostly C code, which provides the speed and throughput we are looking for, however, when it comes to interacting with the AWS S3 API this comes at the price of the additional work required for implementing the S3 storage features. Recent version implement S3 multi-part upload.
WAL-G
WAL-G announced 2 years ago is being actively maintained. This rock-solid PostgreSQL backup tool implements storage classes, but not multipart upload (searching the code for CreateMultipartUpload didn’t find any occurrence).
PGHoard
pghoard was released about 3 years ago. It is a performant and feature-rich PostgreSQL backup tool with support for S3 multipart transfers. It doesn’t offer any of the other S3 features such as storage class and object lifecycle management.
S3 as a local filesystem
Being able to access S3 storage as a local filesystem, is a highly desired feature as it opens up the possibility of using the PostgreSQL native backup tools.
For Linux environments, Amazon offers two options: NFS and iSCSI. They take advantage of the AWS Storage Gateway.
NFS
A locally mounted NFS share is provided by the AWS Storage Gateway File service. According to the link we need to create a File Gateway.
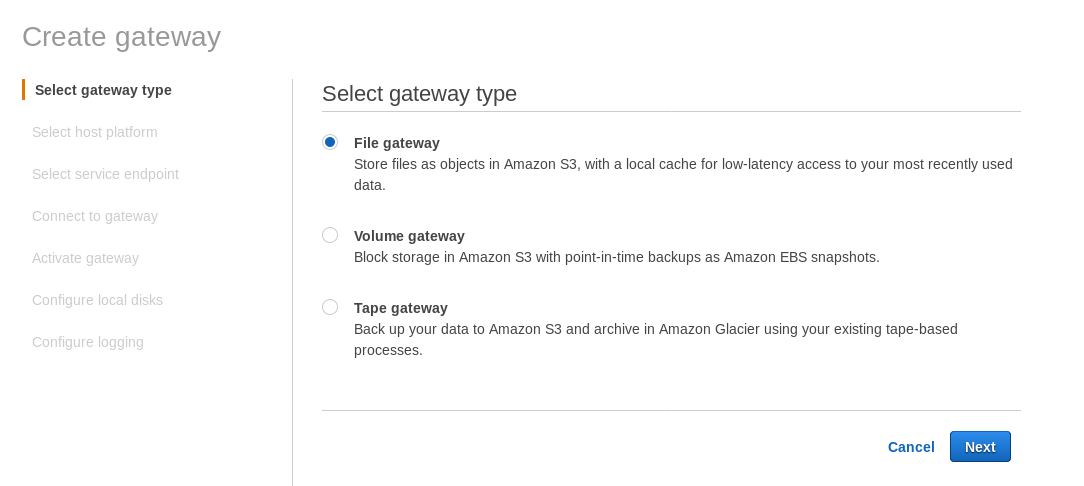
At the Select host platform screen select Amazon EC2 and click the Launch instance button to start the EC2 wizard for creating the instance.
Now, just out of this Sysadmin’s curiosity, let’s inspect the AMI used by the wizard as it gives us an interesting perspective on some of the AWS internal pieces. With the image ID known ami-0bab9d6dffb52fef5 let’s look at details:
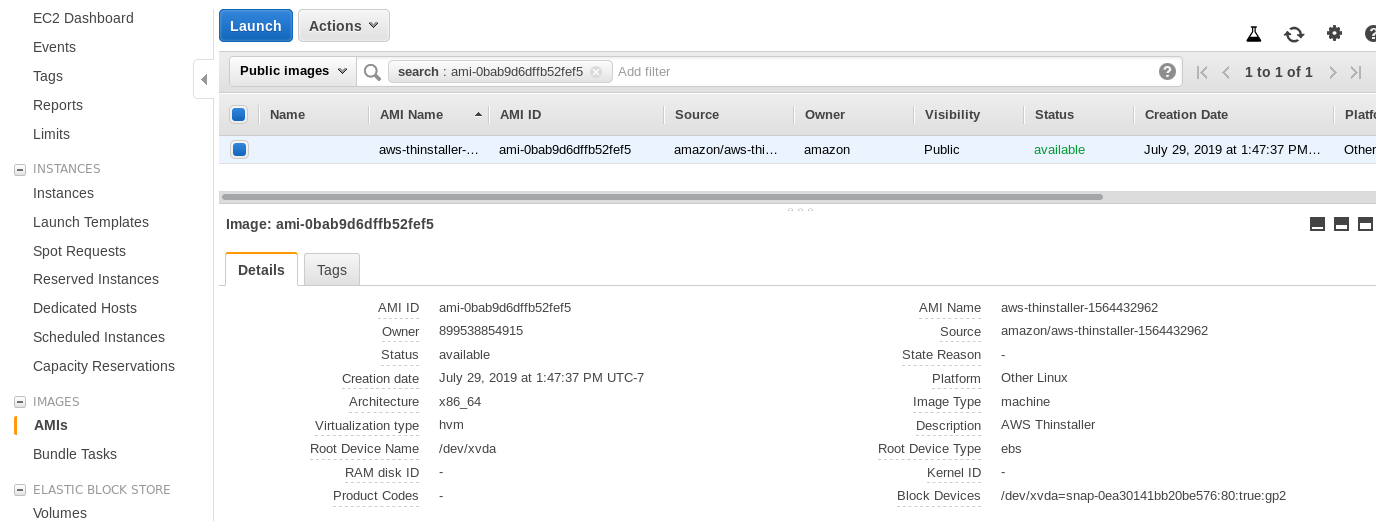
As shown above, the AMI name is aws-thinstaller — so what is a “thinstaller”? Internet searches reveal that Thinstaller is an IBM Lenovo software configuration management tool for Microsoft products and is referenced first in this 2008 blog, and later in this Lenovo forum post and this school district request for service. I had no way of knowing that one, as my Windows sysadmin job ended 3 years earlier. So was this AMI built with the Thinstaller product To make matters even more confusing, the AMI operating system is listed as “Other Linux” which can be confirmed by SSH-ing into the system as admin.
A wizard gotcha: despite the EC2 firewall setup instructions my browser was timing out when connecting to the storage gateway. Allowing port 80 is documented at Port Requirements — we could argue that the wizard should either list all required ports, or link to documentation, however in the spirit of the cloud, the answer is “automate” with tools such as CloudFormation.
The wizard also suggests to start with an xlarge size instance.
Once the storage gateway is ready, configure the NFS share by clicking the Create file share button in the Gateway menu:
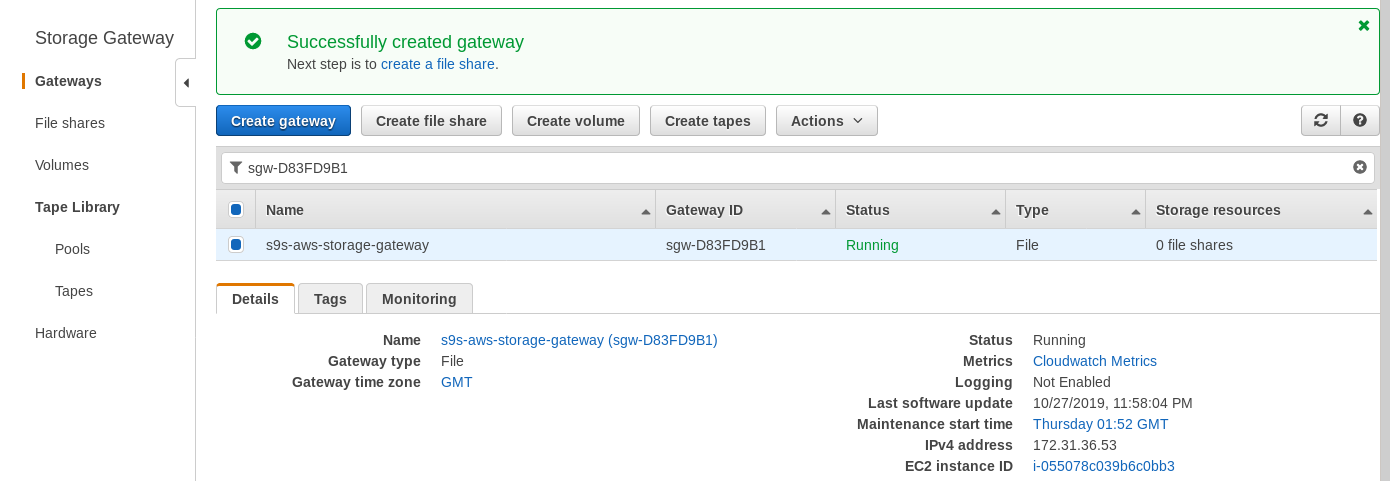
Once the NFS share is ready, follow the instructions to mount the filesystem:
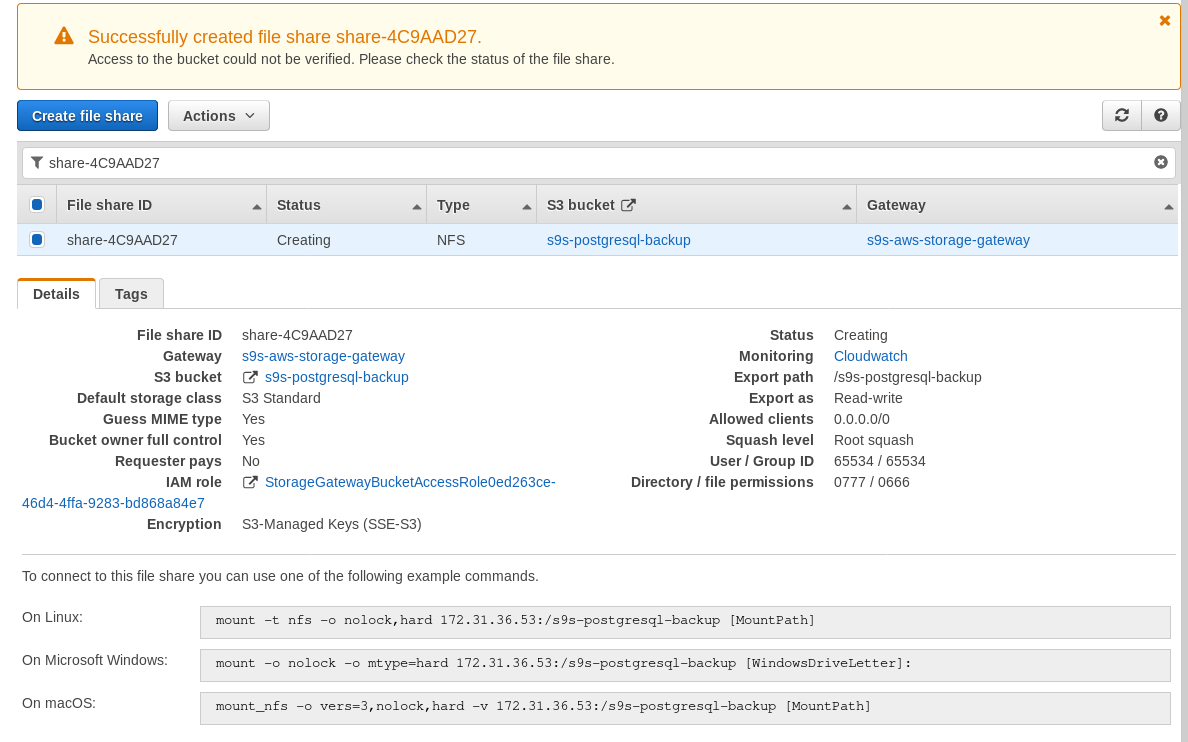
In the above screenshot, note that the mount command references the instance private IP address. To mount from a public host just use the instance public address as shown in the EC2 instance details above.
The wizard will not block if the S3 bucket doesn’t exist at the time of creating the file share, however, once the S3 bucket is created we need to restart the instance, otherwise, the mount command fails with:
[root@omiday ~]# mount -t nfs -o nolock,hard 34.207.216.29:/s9s-postgresql-backup /mnt
mount.nfs: mounting 34.207.216.29:/s9s-postgresql-backup failed, reason given by server: No such file or directoryVerify that the share has been made available:
[root@omiday ~]# df -h /mnt
Filesystem Size Used Avail Use% Mounted on
34.207.216.29:/s9s-postgresql-backup 8.0E 0 8.0E 0% /mntNow let’s run a quick test:
postgres@[local]:54311 postgres# l+ test
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
test | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 2763 MB | pg_default |
(1 row)
[root@omiday ~]# date ; time pg_dump -d test | gzip -c >/mnt/test.pg_dump.gz ; date
Sun 27 Oct 2019 06:06:24 PM PDT
real 0m29.807s
user 0m15.909s
sys 0m2.040s
Sun 27 Oct 2019 06:06:54 PM PDTNote that the Last modified timestamp on the S3 bucket is about a minute later, which as mentioned earlier has to with the Amazon S3 data consistency model.
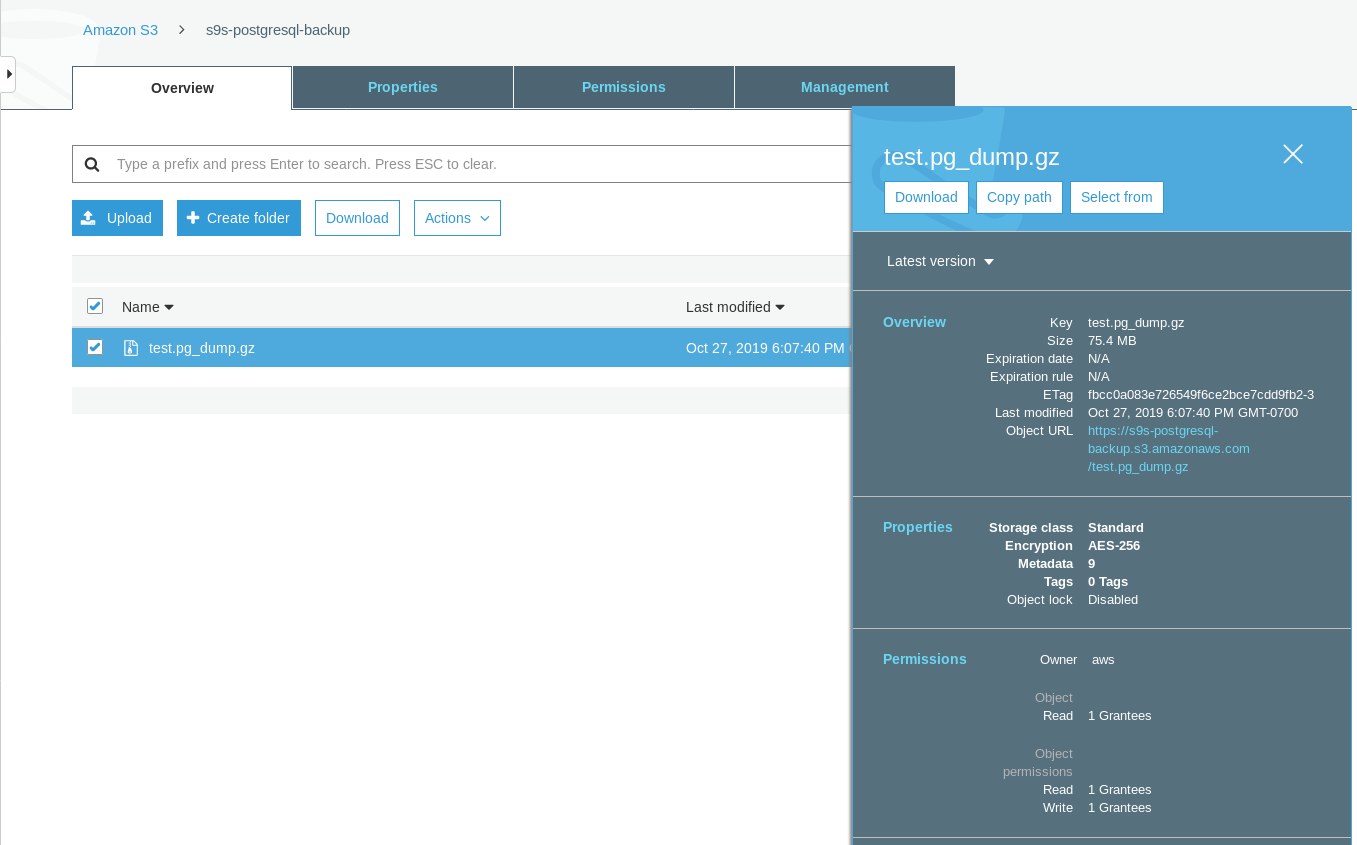
Here’s a more exhaustive test:
~ $ for q in {0..20} ; do touch /mnt/touched-at-$(date +%Y%m%d%H%M%S) ;
sleep 1 ; done
~ $ aws s3 ls s3://s9s-postgresql-backup | nl
1 2019-10-27 19:50:40 0 touched-at-20191027194957
2 2019-10-27 19:50:40 0 touched-at-20191027194958
3 2019-10-27 19:50:40 0 touched-at-20191027195000
4 2019-10-27 19:50:40 0 touched-at-20191027195001
5 2019-10-27 19:50:40 0 touched-at-20191027195002
6 2019-10-27 19:50:40 0 touched-at-20191027195004
7 2019-10-27 19:50:40 0 touched-at-20191027195005
8 2019-10-27 19:50:40 0 touched-at-20191027195007
9 2019-10-27 19:50:40 0 touched-at-20191027195008
10 2019-10-27 19:51:10 0 touched-at-20191027195009
11 2019-10-27 19:51:10 0 touched-at-20191027195011
12 2019-10-27 19:51:10 0 touched-at-20191027195012
13 2019-10-27 19:51:10 0 touched-at-20191027195013
14 2019-10-27 19:51:10 0 touched-at-20191027195014
15 2019-10-27 19:51:10 0 touched-at-20191027195016
16 2019-10-27 19:51:10 0 touched-at-20191027195017
17 2019-10-27 19:51:10 0 touched-at-20191027195018
18 2019-10-27 19:51:10 0 touched-at-20191027195020
19 2019-10-27 19:51:10 0 touched-at-20191027195021
20 2019-10-27 19:51:10 0 touched-at-20191027195022
21 2019-10-27 19:51:10 0 touched-at-20191027195024Another issue worth mentioning: after playing with various configurations, creating and destroying gateways and shares, at some point when attempting to activate a File gateway, I was getting an Internal Error:
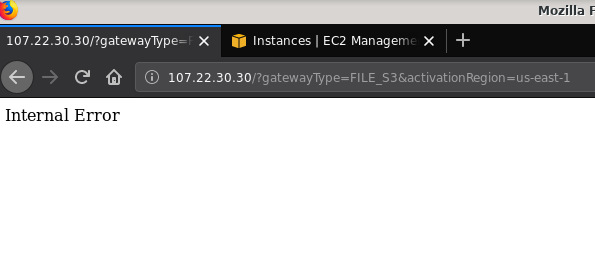
The command line gives some more details, although not pointing to any issue:
~$ curl -sv "http://107.22.30.30/?gatewayType=FILE_S3&activationRegion=us-east-1"
* Trying 107.22.30.30:80...
* TCP_NODELAY set
* Connected to 107.22.30.30 (107.22.30.30) port 80 (#0)
> GET /?gatewayType=FILE_S3&activationRegion=us-east-1 HTTP/1.1
> Host: 107.22.30.30
> User-Agent: curl/7.65.3
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 500 Internal Server Error
< Date: Mon, 28 Oct 2019 06:33:30 GMT
< Content-type: text/html
< Content-length: 14
<
* Connection #0 to host 107.22.30.30 left intact
Internal Error~ $This forum post pointed out that my issue may have something to do with the VPC Endpoint I had created. My fix was deleting the VPC endpoint I had setup during various iSCSI trial and error runs.
While S3 encrypts data at rest, the NFS wire traffic is plain text. To wit, here’s a tcpdump packet dump:
23:47:12.225273 IP 192.168.0.11.936 > 107.22.30.30.2049: Flags [P.], seq 2665:3377, ack 2929, win 501, options [nop,nop,TS val 1899459538 ecr 38013066], length 712: NFS request xid 3511704119 708 getattr fh 0,2/53
E...8.@[email protected]....... ...c..............
q7s..D.......PZ7...........................4........omiday.can.local...................................................5.......]...........!....................C...
..............&...........]....................# inittab is no longer used.
#
# ADDING CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.
#
# Ctrl-Alt-Delete is handled by /usr/lib/systemd/system/ctrl-alt-del.target
#
# systemd uses 'targets' instead of runlevels. By default, there are two main targets:
#
# multi-user.target: analogous to runlevel 3
# graphical.target: analogous to runlevel 5
#
# To view current default target, run:
# systemctl get-default
#
# To set a default target, run:
# systemctl set-default TARGET.target
..... .........0..
23:47:12.331592 IP 107.22.30.30.2049 > 192.168.0.11.936: Flags [P.], seq 2929:3109, ack 3377, win 514, options [nop,nop,TS val 38013174 ecr 1899459538], length 180: NFS reply xid 3511704119 reply ok 176 getattr NON 4 ids 0/33554432 sz -2138196387Until this IEE draft is approved the only secure option for connecting from outside AWS is by using a VPN tunnel. This complicates the setup, making the on-premise NFS option less appealing than the FUSE based tools I’m going to discuss a bit later.
iSCSI
This option is provided by the AWS Storage Gateway Volume service. Once the service is configured head to the Linux iSCSI client setup section.
The advantage of using iSCSI over NFS consists in the ability of taking advantage of the Amazon cloud native backup, cloning, and snapshot services. For details and step by step instructions, follow the links to AWS Backup, Volume Cloning, and EBS Snapshots
While there are plenty of advantages, there is an important restriction that will likely throw off many users: it is not possible to access the gateway via its public IP address. So, just as the NFS option, this requirement adds complexity to the setup.
Despite the clear limitation and convinced that I will not be able to complete this setup, I still wanted to get a feeling of how it’s done. The wizard redirects to an AWS Marketplace configuration screen.
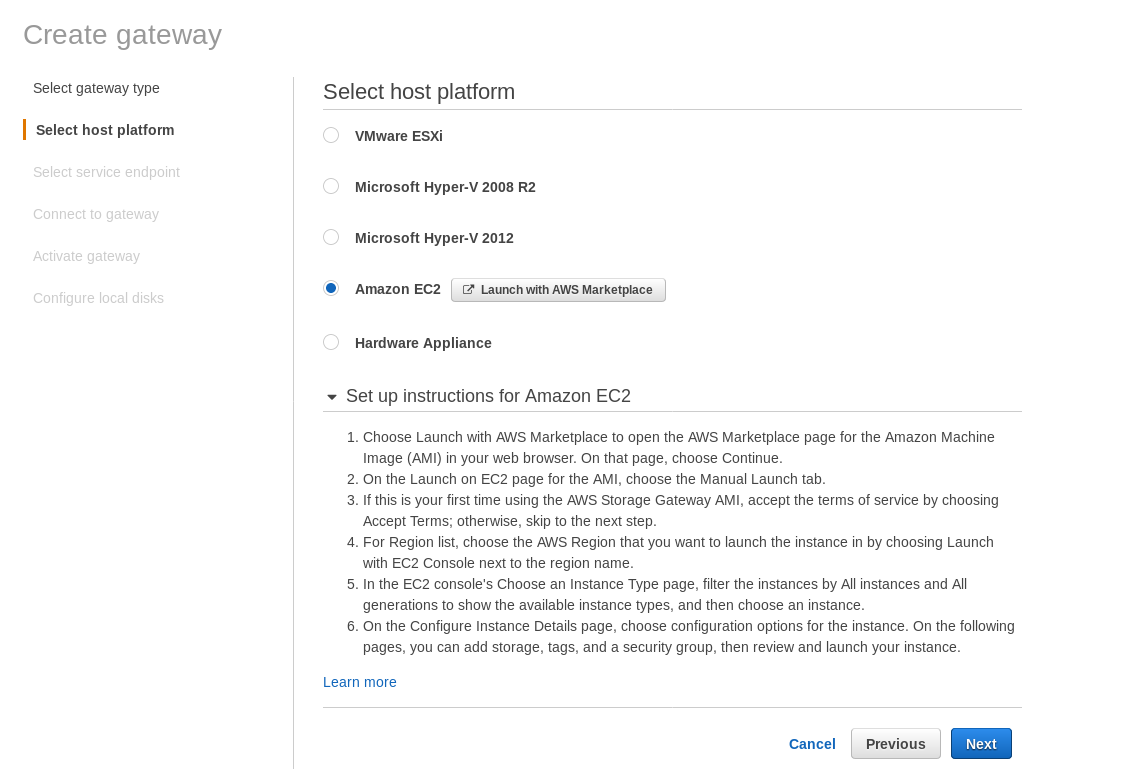
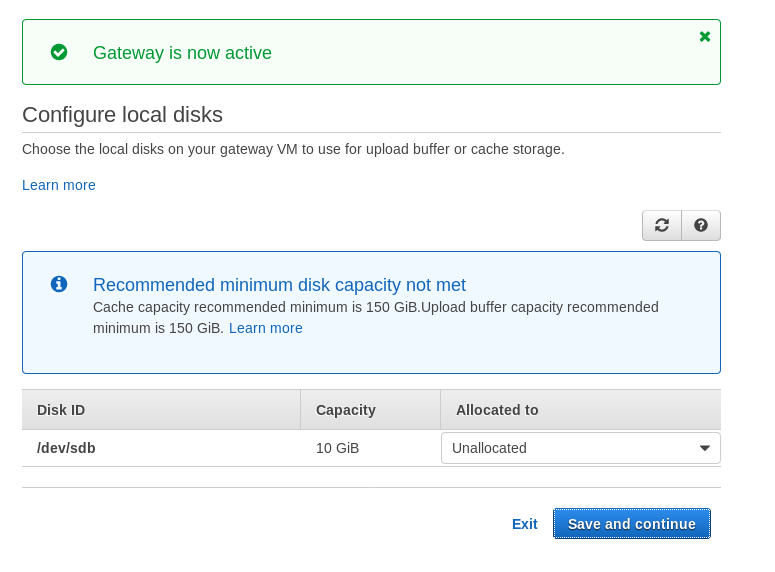
Note that the Marketplace wizard creates a secondary disk, however not big enough in size, and therefore we still need to add the two required volumes as indicated by the host setup instructions. If the storage requirements aren’t met the wizard will block at the local disks configuration screen:
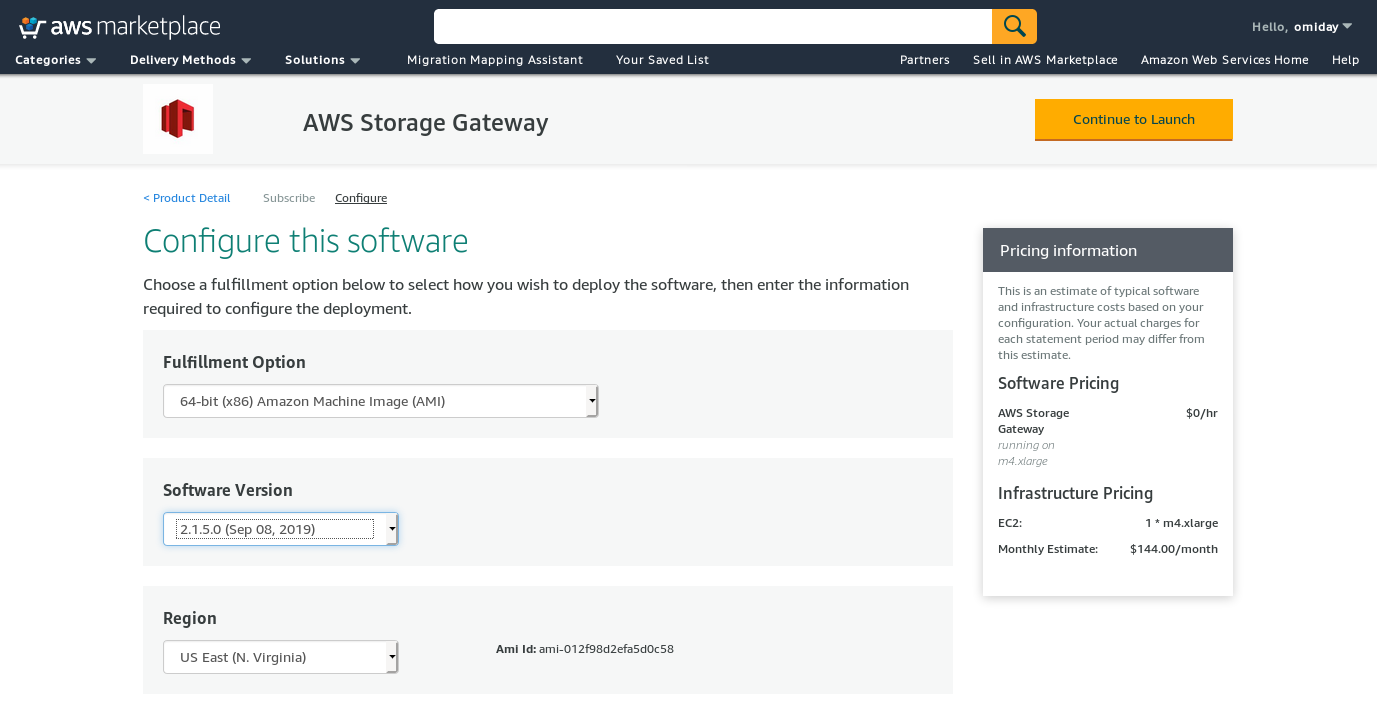
Here’s a glimpse of Amazon Marketplace configuration screen:
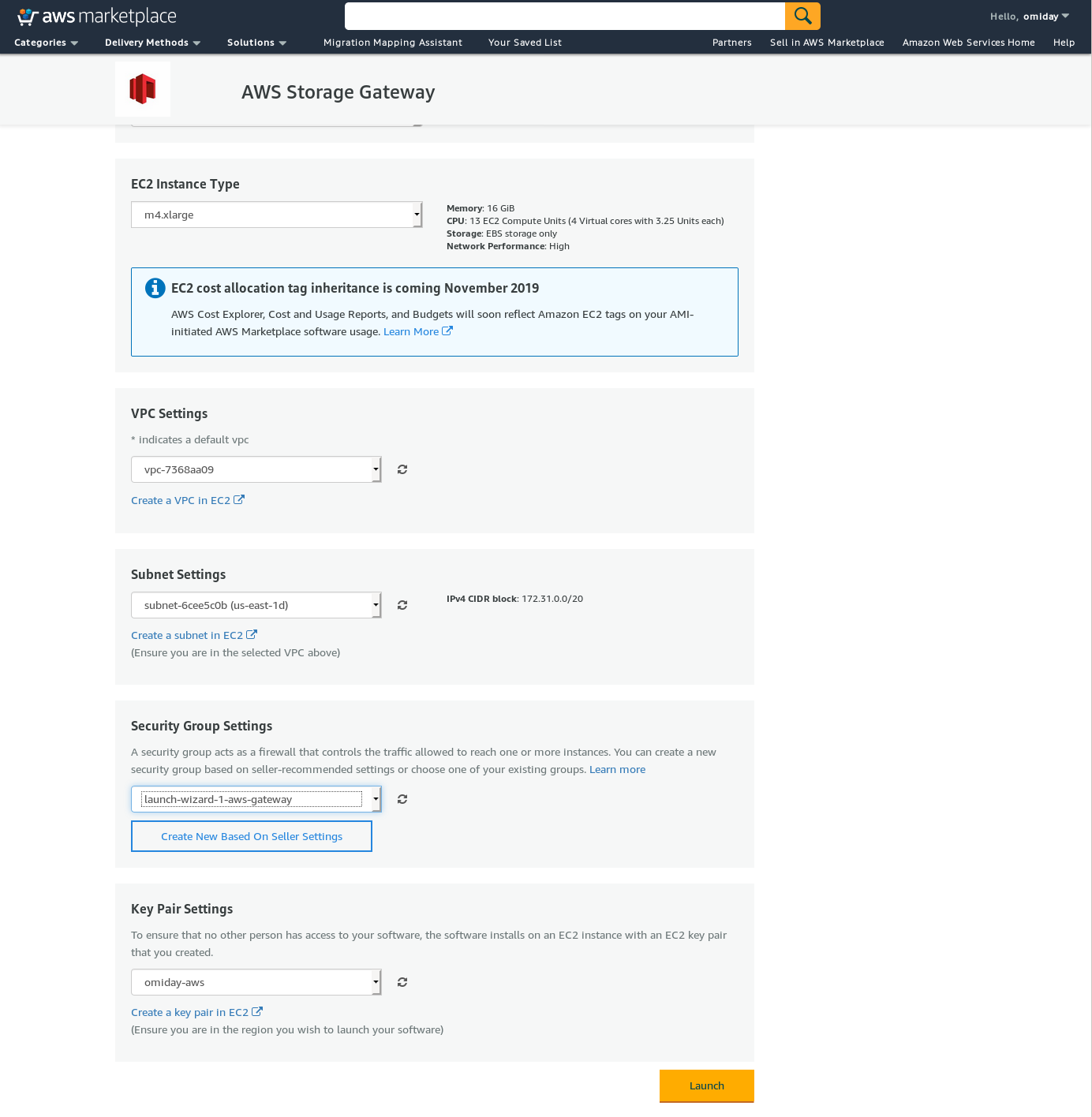
There is a text interface accessible via SSH (log in as user sguser) which provides basic network troubleshooting tools and other configuration options which cannot be performed via the web GUI:
~ $ ssh [email protected]
Warning: Permanently added 'ec2-3-231-96-109.compute-1.amazonaws.com,3.231.96.109' (ECDSA) to the list of known hosts.
'screen.xterm-256color': unknown terminal type.
AWS Storage Gateway Configuration
#######################################################################
## Currently connected network adapters:
##
## eth0: 172.31.1.185
#######################################################################
1: SOCKS Proxy Configuration
2: Test Network Connectivity
3: Gateway Console
4: View System Resource Check (0 Errors)
0: Stop AWS Storage Gateway
Press "x" to exit session
Enter command:And a couple of other important points:
- Contrary to the NFS setup, there is no direct access to the S3 storage as noted at the Volume Gateway FAQ section.
- AWS documentation insists on customizing the iSCSI settings in order to improve the performance and security of the connection.
FUSE
In this category, I have listed the FUSE based tools that provide a more complete S3 compatibility compared to the PostgreSQL backup tools, and in contrast with Amazon Storage Gateway, allow data transfers from an on-premise host to Amazon S3 without additional configuration. Such a setup could provide S3 storage as a local filesystem that PostgreSQL backup tools can use in order to take advantage of features such as parallel pg_dump.
s3fs-fuse
s3fs-fuse is written in C++, a language supported by the Amazon S3 SDK toolkit, and as such is well suited for implementing advanced S3 features such as multipart uploads, caching, S3 storage class, server-side encryption, and region selection. It is also highly POSIX compatible.
The application is included with my Fedora 30 making the installation straightforward.
To test:
~/mnt/s9s $ time pg_dump -d test | gzip -c >test.pg_dump-$(date +%Y%m%d-%H%M%S).gz
real 0m35.761s
user 0m16.122s
sys 0m2.228s
~/mnt/s9s $ aws s3 ls s3://s9s-postgresql-backup
2019-10-28 03:16:03 79110010 test.pg_dump-20191028-031535.gzNote that the speed is somewhat slower than using the Amazon Storage Gateway with the NFS option. It does make up for the lower performance by providing a highly POSIX compatible filesystem.
S3QL
S3QL provides S3 features such as storage class, and server side encryption. The many features are described in the exhaustive S3QL Documentation, however, if you are looking for multipart upload it is nowhere mentioned. This is because S3QL implements its own file splitting algorithm in order to provide the de-duplication feature. All files are broken into 10 MB blocks.
The installation on a Red Hat based system is straightforward: install the required RPM dependencies via yum:
sqlite-devel-3.7.17-8.14.amzn1.x86_64
fuse-devel-2.9.4-1.18.amzn1.x86_64
fuse-2.9.4-1.18.amzn1.x86_64
system-rpm-config-9.0.3-42.28.amzn1.noarch
python36-devel-3.6.8-1.14.amzn1.x86_64
kernel-headers-4.14.146-93.123.amzn1.x86_64
glibc-headers-2.17-260.175.amzn1.x86_64
glibc-devel-2.17-260.175.amzn1.x86_64
gcc-4.8.5-1.22.amzn1.noarch
gcc48-4.8.5-28.142.amzn1.x86_64
mpfr-3.1.1-4.14.amzn1.x86_64
libmpc-1.0.1-3.3.amzn1.x86_64
libgomp-6.4.1-1.45.amzn1.x86_64
libgcc48-4.8.5-28.142.amzn1.x86_64
cpp48-4.8.5-28.142.amzn1.x86_64
python36-pip-9.0.3-1.26.amzn1.noarch
python36-libs-3.6.8-1.14.amzn1.x86_64
python36-3.6.8-1.14.amzn1.x86_64
python36-setuptools-36.2.7-1.33.amzn1.noarchThen install the Python dependencies using pip3:
pip-3.6 install setuptools cryptography defusedxml apsw dugong pytest requests llfuse==1.3.6A notable characteristic of this tool is the S3QL filesystem created on top of the S3 bucket.
Goofys
goofys is an option when performance trumps the POSIX compliance. It’s goals are the opposite of s3fs-fuse. Focus on speed is also reflected in the distribution model. For Linux there are pre-built binaries. Once downloaded run:
~/temp/goofys $ ./goofys s9s-postgresql-backup ~/mnt/s9s/And backup:
~/mnt/s9s $ time pg_dump -d test | gzip -c >test.pg_dump-$(date +%Y%m%d-%H%M%S).gz
real 0m27.427s
user 0m15.962s
sys 0m2.169s
~/mnt/s9s $ aws s3 ls s3://s9s-postgresql-backup
2019-10-28 04:29:05 79110010 test.pg_dump-20191028-042902.gzNote that the object creation time on S3 is only 3 seconds away from file timestamp.
ObjectFS
ObjectFS appears to have been maintained until about 6 months ago. A check for multipart upload reveals that it is not implemented, From the author’s research paper we learn that the system is still in development, and since the paper was released in 2019 I thought it’d be worth mentioning it.
S3 Clients
As mentioned earlier, in order to use the AWS S3 CLI, we need to take into consideration several aspects specific to object storage in general, and Amazon S3 in particular. If the only requirement is the ability to transfer data in and out of the S3 storage, then a tool that closely follows the Amazon S3 recommendations can do the job.
s3cmd is one of the tools that stood the test of time. This 2010 Open BI blog talks about it, at a time when S3 was the new kid on the block.
Notable features:
- server-side encryption
- automatic multipart uploads
- bandwidth throttling
Head to the S3cmd: FAQ and Knowledge Base for more information.
Conclusion
The options available for backing up a PostgreSQL cluster to Amazon S3 differ in the data transfer methods and how they align with the Amazon S3 strategies.
AWS Storage Gateway complements the Amazon’s S3 object storage, at the cost of increased complexity along with additional knowledge required in order to get the most out of this service. For example, selecting the correct number of disks requires careful planning, and a good grasp of Amazon’s S3 related costs is a must in order to minimize the operational costs.
While applicable to any cloud storage not only Amazon S3, the decision of storing the data in a public cloud has security implications. Amazon S3 provides encryption for data at rest and data in transit, with no guarantee of zero knowledge, or no knowledge proofs. Organizations wishing to have full control over their data should implement client-side encryption and storing the encryption keys outside their AWS infrastructure.
For commercial alternatives to mapping S3 to a local filesystem it’s worth checking out the products from ObjectiveFS or NetApp.
Lastly, organizations seeking to developing their own backup tools, either by building on the foundation provided by the many open source applications, or starting from zero, should consider using the S3 compatibility test, made available by the Ceph project.




{kind=link}