blog
MySQL Replication Failover – Maxscale vs MHA: Part Two
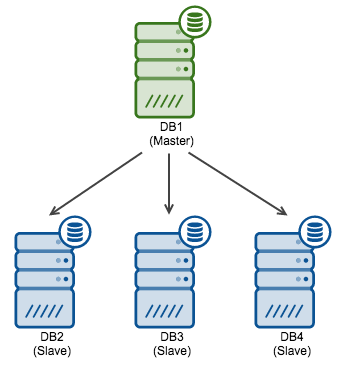
In our previous post, we described how MySQL Master-HA (MHA) performs a so called slave promotion (also known as master failover) and ensures all remaining slaves in the topology get attached under the new master and become equal in data set.
Another failover solution is the MariaDB MaxScale proxy in combination with the MariaDB Replication Manager. Let’s look at how these two separate products can work together and perform a failover. We will also describe how you can use them.
MaxScale + MariaDB Replication Manager
MaxScale
For those unfamiliar with MaxScale: MaxScale is a versatile database proxy written in C that supports not only intelligent query routing but can also function as both a binlog server and intermediate master. MaxScale consists of five plugins: Authentication, Protocol, Monitor, Routing, Filter & Logging. The Monitor and Routing plugins are working together to make intelligent query routing possible as the monitor component keeps track of the replication topology while the query router then chooses the host to send the query to. You can for instance also add the Filter plugin to only have certain specific queries to go to specific hosts. With ClusterControl we install MaxScale by default with the monitor (MySQL or Galera) and router (read connection or read-write splitter) enabled.
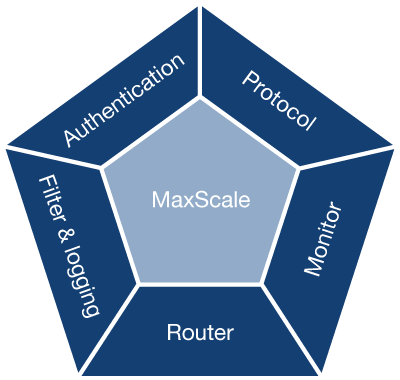
As said before: maxscale is a versatile database proxy, so the monitor plugin can also be used for other purposes as well, for instance on certain events. The event will be the trigger to run a script that can handle the event change and act accordingly, for instance if a master goes down you can promote a slave to become the new master. Such a script should be able to send commands to the MariaDB Replication Manager.
The monitor configuration only needs three extra lines:
[MySQL Monitor]
type=monitor
module=mysqlmon
servers=svr_10101811,svr_10101812,svr_10101813
user=admin
passwd=B4F3CB4FD8132F78DC2994A3C2AC7EC0
monitor_interval=1000
live_nodes=$NODELIST
script=/usr/local/bin/failover.sh
events=master_downMaxScale will send a few parameters to this script including the nodelist and the failed host. The script can then interpret this data and send it to the MariaDB Replication Manager.
MariaDB Replication Manager
The MariaDB Replication Manager (MRM) is a Go project that creates an executable after compiling. It is able to handle failover scenarios on MariaDB GTID based replication topologies. It can handle various scenarios when to failover, but the most commonly used are either failover on a dead master or promote a (most advanced) slave to become the new master. You can even have it run pre- and post-failover scripts to remove and set virtual ips for instance.
In the MaxScale + MRM combination, we don’t need to handle much more than a dead-master and create the new topology from there. There is no need for virtual ips as most probably MaxScale is already used to route the queries to the right hosts in the topology. As the MariaDB Replication Manager will promote a slave to become a master and reassign the slaves to the new master, MaxScale will almost instantly recognize the new master with its new topology and start routing the queries accordingly.
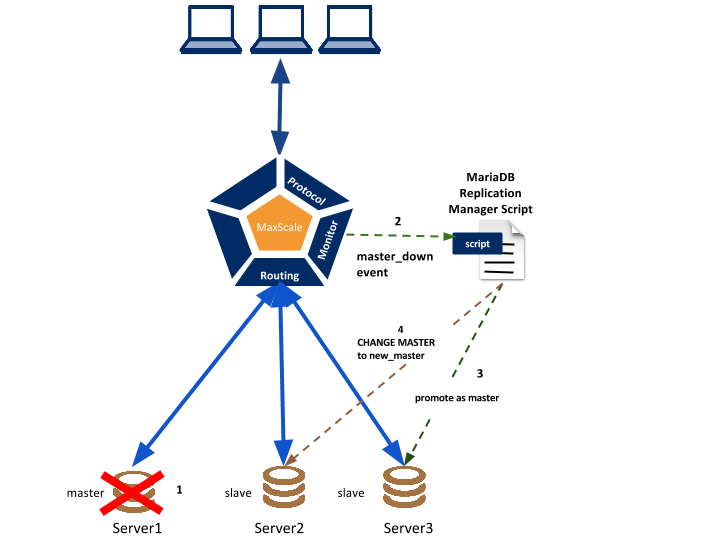
Installation
MRM is open source and available from the MariaDB Replication Manager repository on Github. It is easy to compile your own version of MRM, these are the steps I had to take on my test box (make sure to install Go first!):
git clone https://github.com/mariadb-corporation/replication-manager
cd replication-manager
go get github.com/go-sql-driver/mysql
go get github.com/nsf/termbox-go
go get github.com/tanji/mariadb-tools/dbhelper
go build
cp replication-manager /usr/local/bin
chmod 755 /usr/local/bin/replication-managerThat’s it and after this you should have a binary in /usr/local/bin to make it available for MaxScale to invoke.
A simple wrapper script is necessary to control MRM from the MaxScale triggers and have it translate the information given to the MRM parameters.
#!/bin/bash
# failover.sh
# wrapper script to repmgr
# user:password pair, must have administrative privileges.
user=root:admin
# user:password pair, must have REPLICATION SLAVE privileges.
repluser=repluser:replpass
ARGS=$(getopt -o '' --long 'event:,initiator:,nodelist:' -- "$@")
eval set -- "$ARGS"
while true; do
case "$1" in
--event)
shift;
event=$1
shift;
;;
--initiator)
shift;
initiator=$1
shift;
;;
--nodelist)
shift;
nodelist=$1
shift;
;;
--)
shift;
break;
;;
esac
done
/usr/local/bin/replication-manager -user $user -rpluser $repluser -hosts $nodelist -failover=force >> /var/log/mrm.log 2>&1Note that this script is an “improved” version of the one from MariaDB’s blog post as our binary is named differently, we added logging and some of the MRM parameters have changed since.
Quick slave promotion
The MaxScale monitor plugin will immediately trigger the event once the master has changed state. We have looked into the code of MaxScale and this seems to be instant if the master is unreachable (correct us if we’re wrong here). The monitoring interval of MaxScale can be altered accordingly. We have set the interval to every 1000 ms which means MaxScale will start the failover procedure within 1-2 seconds. The failover procedure by the MariaDB Replication Manager is also only a few seconds. Detection of the new replication topology by MaxScale will also take a few seconds, so all in all, the failover should be done somewhere in the 10-20 seconds range.
Conclusion
The MaxScale proxy has a big advantage: it knows your replication topology by heart, sees queries being sent to the master and slaves and therefore it can detect master failure at a very early stage. It would also be able to react on different events sent from the monitor plugin and therefore it sounds like a quite flexible tool.
The MariaDB Replication Manager seems to implement the topology discovery for a second time and this can be a double edged sword: since it would be able to detect the topology by itself, it is not a blind tool that just executes a command. So, it could contradict what MaxScale’s intentions were and take a different decision. Also, it also doesn’t allow you to set up specific roles or filter out less preferable hosts, although that’s something you could do with some bash magic.
In our third part we’ll compare side by side the combination of MaxScale + MariaDB Replication Manager and MySQL Master-HA.



