blog
MySQL Replication Best Practices

MySQL Replication has been the most common and widely used solution for high availability by huge organizations such as Github, Twitter, and Facebook. Although easy to set up, there are challenges faced when using this solution from maintenance, including software upgrades, data drift or data inconsistency across the replica nodes, topology changes, failover, and recovery. When MySQL released version 5.6, it brought a number of significant enhancements, especially to replication which includes Global Transaction IDs (GTIDs), event checksums, multi-threaded slaves, and crash-safe slaves/masters. Replication got even better with MySQL 5.7 and MySQL 8.0.
Replication enables data from one MySQL server (the primary/master) to be replicated to one or more MySQL servers (the replica/slaves). MySQL Replication is very easy to set up and is used to scale out read workloads, provide high availability and geographic redundancy, and offload backups and analytic jobs.
MySQL Replication in Nature
Let’s have a quick overview of how MySQL Replication works in nature. MySQL Replication is broad, and there are multiple ways to configure it and how it can be used. By default, it uses asynchronous replication, which works as the transaction is completed in the local environment. There is no guarantee that any event will ever reach any slave. It is a loosely coupled master-slave relationship, where:
-
Primary does not wait for a replica.
-
Replica determines how much to read and from which point in the binary log.
-
Replica can be arbitrarily behind master in reading or applying changes.
If the primary crashes, transactions that it has committed might not have been transmitted to any replica. Consequently, failover from primary to the most advanced replica, in this case, may result in a failover to the desired primary that is actually missing transactions relative to the previous server.
Asynchronous replication provides lower write latency since a write is acknowledged locally by a master before being written to slaves. It is great for read-scaling as adding more replicas does not impact replication latency. Good use cases for asynchronous replication include deployment of reading replicas for read-scaling, live backup copy for disaster recovery, and analytics/reporting.
MySQL Semi-Synchronous Replication
MySQL also supports semi-synchronous replication, where the master does not confirm transactions to the client until at least one slave has copied the change to its relay log and flushed it to disk. To enable semi-synchronous replication, extra steps for plugin installation are required and must be enabled on the designated MySQL master and slave nodes.
Semi-synchronous seems to be a good and practical solution for many cases where high availability and no data loss are important. But you should consider that semi-synchronous has a performance impact due to the additional round trip and does not provide strong guarantees against data loss. When a commit returns successfully, it is known that the data exists in at least two places (on the master and at least one slave). If the master commits but a crash occurs while the master is waiting for acknowledgment from a slave, it is possible that the transaction may not have reached any slave. This is not that big of an issue as the commit will not be returned to the application in this case. It is the application’s task to retry the transaction in the future. What is essential to keep in mind is that when the master fails, and a slave has been promoted, the old master cannot join the replication chain. Under some circumstances, this may lead to conflicts with data on the slaves, i.e., when the master crashed after the slave received the binary log event but before the master got the acknowledgment from the slave). Thus the only safe way is to discard the data on the old master and provision it from scratch using the data from the newly promoted master.
Using the Replication Format Incorrectly
Since MySQL 5.7.7, the default binary log format or binlog_format variable uses ROW, which was STATEMENT prior to 5.7.7. The different replication formats correspond to the method used to record the source’s binary log events. Replication works because events written to the binary log are read from the source and then processed on the replica. The events are recorded within the binary log in different replication formats according to the type of event. Not knowing for sure what to use can be a problem. MySQL has three formats of replication methods: STATEMENT, ROW, and MIXED.
-
The STATEMENT-based replication (SBR) format is exactly what it is–a replication stream of every statement run on the master that will be replayed on the slave node. By default, MySQL traditional (asynchronous) replication does not execute the replicated transactions to the slaves in parallel. By that, it means that the order of statements in the replication stream may not be 100% the same. Also, replaying a statement may give different results when not executed at the same time as when executed from the source. This leads to an inconsistent state against the primary and its replica(s). This wasn’t an issue for many years, as not many ran MySQL with many simultaneous threads. However, with modern multi-CPU architectures, this has actually become highly probable on a normal day-to-day workload.
-
The ROW replication format provides solutions that the SBR lacks. When using row-based replication (RBR) logging format, the source writes events to the binary log that indicate how individual table rows are changed. Replication from source to the replica works by copying the events representing the changes to the table rows to the replica. This means that more data can be generated, affecting disk space in the replica and affecting network traffic and disk I/O. Consider if a statement changes many rows, let’s say with an UPDATE statement, RBR writes more data to the binary log even for statements that are rolled back. Running point-in-time snapshots can take more time as well. Concurrency problems may come into play given the lock times needed to write large chunks of data into the binary log.
-
Then there is a method in between these two; mixed-mode replication. This type of replication will always replicate statements, except when the query contains the UUID() function, triggers, stored procedures, UDFs, and a few other exceptions. Mixed-mode will not solve the issue of data drift and, together with statement-based replication, should be avoided.
Planning to Have a Multi-Master Setup?
Circular Replication (also known as ring topology) is a known and common setup for MySQL replication. It is used for running a multi-master setup (see image below) and is often necessary if you have a multi-datacenter environment. Since the application can’t wait for the master in the other data center to acknowledge the writes, a local master is preferred. Normally the auto-increment offset is used to prevent data clashes between the masters. Having two masters perform writes to each other in this way is a broadly accepted solution.
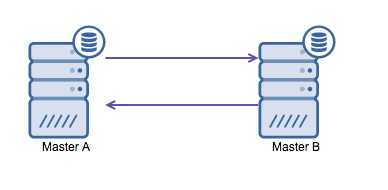
However, if you need to write in multiple data centers into the same database, you end up with multiple masters that need to write their data to each other. Before MySQL 5.7.6, there was no method to do a mesh type of replication, so the alternative would be to use a circular ring replication instead.
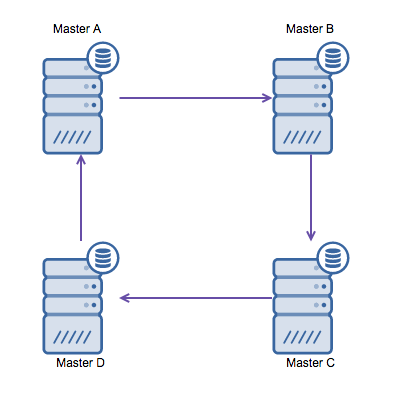
Ring replication in MySQL is problematic for the following reasons: latency, high availability, and data drift. Writing some data to server A would take three hops to end up on server D (via server B and C). Since (traditional) MySQL replication is single-threaded, any long-running query in the replication may stall the whole ring. Also, if any of the servers would go down, the ring would be broken, and currently, no failover software can repair ring structures. Then data drift may occur when data is written to server A and is altered simultaneously on server C or D.
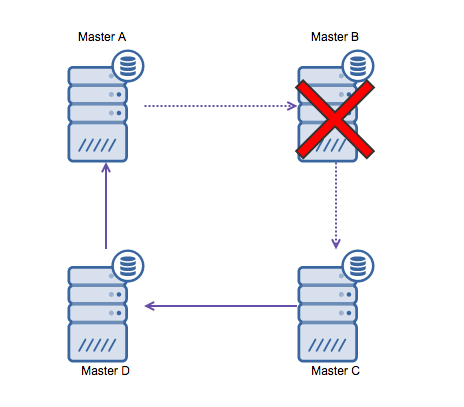
In general, circular replication is not a good fit with MySQL and should be avoided at all costs. As it was designed with that in mind, Galera Cluster would be a good alternative for multi-datacenter writes.
Stalling your Replication with Large Updates
Various housekeeping batch jobs often perform various tasks, ranging from cleaning up old data to calculating averages of ‘likes’ fetched from another source. This means a job will create a lot of database activity at set intervals and, most likely, write a lot of data back to the database. Naturally, this means the activity within the replication stream will increase equally.
Statement-based replication will replicate the exact queries used in the batch jobs, so if the query took half an hour to process on the master, the slave thread would be stalled for at least the same amount of time. This means no other data can replicate, and the slave nodes will start lagging behind the master. If this exceeds the threshold of your failover tool or proxy, it may drop these slave nodes from the available servers in the cluster. If you are using statement-based replication, you can prevent this by crunching the data for your job in smaller batches.
Now, you may think row-based replication isn’t affected by this, as it will replicate the row information instead of the query. This is partly true as, for DDL changes, the replication reverts back to a statement-based format. Also, large numbers of CRUD (Create, Read, Update, Delete) operations will affect the replication stream. In most cases, this is still a single-thread operation, and thus every transaction will wait for the previous one to be replayed via replication. This means that if you have high concurrency on the master, the slave may stall on the overload of transactions during replication.
To get around this, both MariaDB and MySQL offer parallel replication. The implementation may differ per vendor and version. MySQL 5.6 offers parallel replication as long as the queries are separated by the schema. MariaDB 10.0 and MySQL 5.7 both can handle parallel replication across schemas but have other boundaries. Executing queries via parallel slave threads may speed up your replication stream if you are writing heavy. Otherwise, it would be better to stick to the traditional single-thread replication.
Handling your Schema Change or DDLs
Since the release of 5.7, managing the schema change or DDL (Data Definition Language ) change in MySQL has improved a lot. Until MySQL 8.0, DDL changes algorithms supported are COPY and INPLACE.
-
COPY: This algorithm creates a new temporary table with the altered schema. Once it migrates the data completely to the new temporary table, it swaps and drops the old table.
-
INPLACE: This algorithm performs operations in place to the original table and avoids the table copy and rebuild whenever possible.
-
INSTANT: This algorithm has been introduced since MySQL 8.0 but still has limitations.
In MySQL 8.0, the algorithm INSTANT was introduced, making instant and in-place table alterations for column addition and allowing concurrent DML with improved responsiveness and availability in busy production environments. This helps avoid huge lags and stalls in the replica that were usually big problems in the application perspective, causing stale data to be retrieved as the reads in the slave have not yet been updated due to lag.
Although that is a promising improvement, there are still limitations with them, and sometimes it is not possible to apply those INSTANT and INPLACE algorithms. For example, for INSTANT and INPLACE algorithms, changing a column’s data type is also a usual DBA task, especially in the application development perspective due to data change. These occasions are inevitable; thus, you cannot go on with the COPY algorithm as this locks up the table causing delays in the slave. It also impacts the primary/master server during this execution as it piles up incoming transactions that also reference the table affected. You cannot perform a direct ALTER or schema change on a busy server as this accompanies downtime or possibly corrupts your database if you lose patience, especially if the target table is huge.
It is true that performing schema changes on a running production setup is always a challenging task. A frequently used workaround is to apply the schema change to the slave nodes first. This works fine for statement-based replication, but this can only work up to a certain degree for row-based replication. Row-based replication allows extra columns to exist at the end of the table, so as long as it can write the first columns, it will be fine. First, apply the change to all slaves, then failover to one of the slaves and then apply the change to the master and attach that as a slave. If your change involves inserting a column in the middle or removing a column, this will work with row-based replication.
There are tools available that can perform online schema changes more reliably. The Percona Online Schema Change (as known as pt-osc) and gh-ost by Schlomi Noach are commonly used by DBAs. These tools handle schema changes effectively by grouping the affected rows into chunks, and these chunks can be configured accordingly depending on how many you want to group.
If you are going to jump with pt-osc, this tool will create a shadow table with the new table structure, insert new data via triggers and backfill data in the background. Once it is done creating the new table, it will simply swap the old for the new table inside a transaction. This doesn’t work in all cases, especially if your existing table already has triggers.
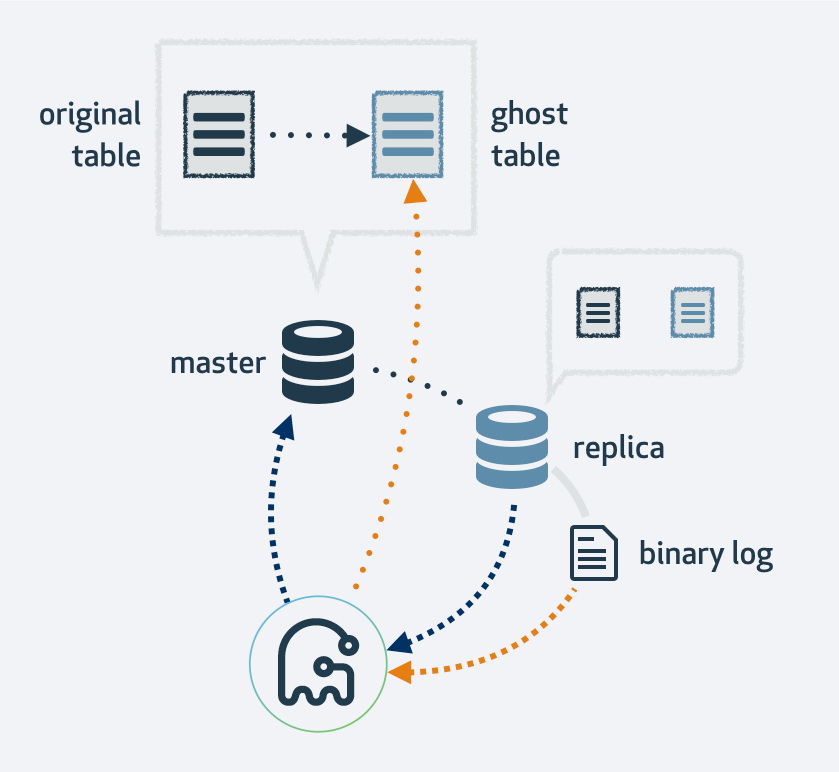
Using gh-ost will first make a copy of your existing table layout, alter the table to the new layout, and then hook up the process as a MySQL replica. It will use the replication stream to find new rows that have been inserted into the original table and, at the same time, backfills the table. Once it is done backfilling, the original and new tables will switch. Naturally, all operations to the new table will end up in the replication stream; thus, on each replica, the migration happens simultaneously.
Memory Tables and Replication
While we are on the subject of DDLs, a common issue is the creation of memory tables. Memory tables are non-persistent tables, their table structure remains, but they lose their data after a restart of MySQL. When creating a new memory table on both a master and a slave, they will have an empty table, which will work perfectly fine. Once either one gets restarted, the table will be emptied, and replication errors will occur.
Row-based replication will break once the data in the slave node returns different results, and statement-based replication will break once it attempts to insert data that already exists. For memory tables, this is a frequent replication-breaker. The fix is easy: make a fresh copy of the data, change the engine to InnoDB, and it should now be replication safe.
Setting the read_only={True|1}
This is, of course, a possible case when you are using a ring topology, and we discourage the use of ring topology if possible. We described earlier, that not having the same data in the slave nodes can break replication. Often, this is caused by something (or someone) altering the data on the slave node but not on the master node. Once the master node’s data gets altered, this will be replicated to the slave where it can’t apply the change, and this causes the replication to break. This can also lead to data corruption at the cluster level, especially if the slave has been promoted or has failed over due to a crash. That can be a disaster.
Easy prevention for this is to make sure read_only and super_read_only (only on > 5.6) are set in ON or 1. You might have understood how these two variables differ and how it affects if you disable or enable them. With super_read_only (since MySQL 5.7.8) disabled, the root user can prevent any changes in the target or replica. So when both are disabled, this will disallow anyone to make changes to the data, except for the replication. Most failover managers, such as ClusterControl, set this flag automatically to prevent users from writing to the used master during failover. Some of them even retain this after the failover.
Enabling GTID
In MySQL replication, starting the slave from the correct position in the binary logs is essential. Obtaining this position can be done when making a backup (xtrabackup and mysqldump support this) or when you have stopped slaving on a node that you are making a copy of. Starting replication with the CHANGE MASTER TO command would look like this:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='master-bin.00001',
MASTER_LOG_POS=4;Starting replication at the wrong spot can have disastrous consequences: data may be double written or not updated. This causes data drift between the master and the slave node.
Also, failing over a master to a slave involves finding the correct position and changing the master to the appropriate host. MySQL doesn’t retain the binary logs and positions from its master, but instead creates its own binary logs and positions. This could become a serious problem for re-aligning a slave node to the new master. The exact position of the master on failover has to be found on the new master, and then all slaves can be realigned.
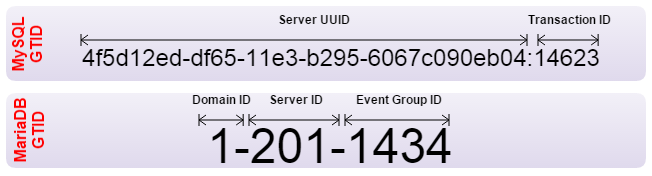
Both Oracle MySQL and MariaDB have implemented the Global Transaction Identifier (GTID) to solve this issue. GTIDs allow auto aligning of slaves, and the server figures out by itself what the correct position is. However, both have implemented the GTID differently and are therefore incompatible. If you need to set up replication from one to another, the replication should be set up with traditional binary log positioning. Also, your failover software should be made aware of not using GTIDs.
Crash-Safe Slave
Crash safe means even if a slave MySQL/OS crashes, you can recover the slave and continue replication without restoring MySQL databases onto the slave. To make crash-safe slave work, you have to use the InnoDB storage engine only, and in 5.6, you need to set relay_log_info_repository=TABLE and relay_log_recovery=1.
Conclusion
Practice makes perfect indeed, but without proper training and knowledge of these vital techniques, it could be troublesome or lead to a disaster. These practices are commonly adhered to by experts in MySQL and are adapted by large industries as part of their daily routine job when administering the MySQL Replication in the production database servers.
If you’d like to read more about MySQL Replication, check out this tutorial on MySQL replication for high availability.
For more updates on database management solutions and best practices for your open-source-based databases, follow us on Twitter and LinkedIn and subscribe to our newsletter.



