blog
MySQL & MariaDB Query Caching With ProxySQL & ClusterControl
Queries have to be cached in every heavily loaded database, there is simply no way for a database to handle all traffic with reasonable performance. There are various mechanisms in which a query cache can be implemented. Starting from the MySQL query cache, which used to work just fine for mostly read-only, low concurrency workloads and which has no place in high concurrent workloads (to the extent that Oracle removed it in MySQL 8.0), to external key-value stores like Redis, memcached or CouchBase.
The main problem with using an external dedicated data store (as we would not recommend to use MySQL query cache to anyone) is that this is yet another datastore to manage. It is yet another environment to maintain, scaling issues to handle, bugs to debug and so on.
So why not kill two birds with one stone by leveraging your proxy? The assumption here is that you are using a proxy in your production environment, as it helps load balance queries across instances, and mask the underlying database topology by provide a simple endpoint to applications. ProxySQL is a great tool for the job, as it can additionally function as a caching layer. In this blog post, we’ll show you how to cache queries in ProxySQL using ClusterControl.
How Query Cache Works in ProxySQL?
First of all, a bit of a background. ProxySQL manages traffic through query rules and it can accomplish query caching using the same mechanism. ProxySQL stores cached queries in a memory structure. Cached data is evicted using time-to-live (TTL) setting. TTL can be defined for each query rule individually so it is up to the user to decide if query rules are to be defined for each individual query, with distinct TTL or if she just needs to create a couple of rules which will match the majority of the traffic.
There are two configuration settings that define how a query cache should be used. First, mysql-query_cache_size_MB which defines a soft limit on the query cache size. It is not a hard limit so ProxySQL may use slightly more memory than that, but it is enough to keep the memory utilization under control. Second setting you can tweak is mysql-query_cache_stores_empty_result. It defines if an empty result set is cached or not.
ProxySQL query cache is designed as a key-value store. The value is the result set of a query and the key is composed from concatenated values like: user, schema and query text. Then a hash is created off that string and that hash is used as the key.
Setting up ProxySQL as a Query Cache Using ClusterControl
As the initial setup, we have a replication cluster of one master and one slave. We also have a single ProxySQL.
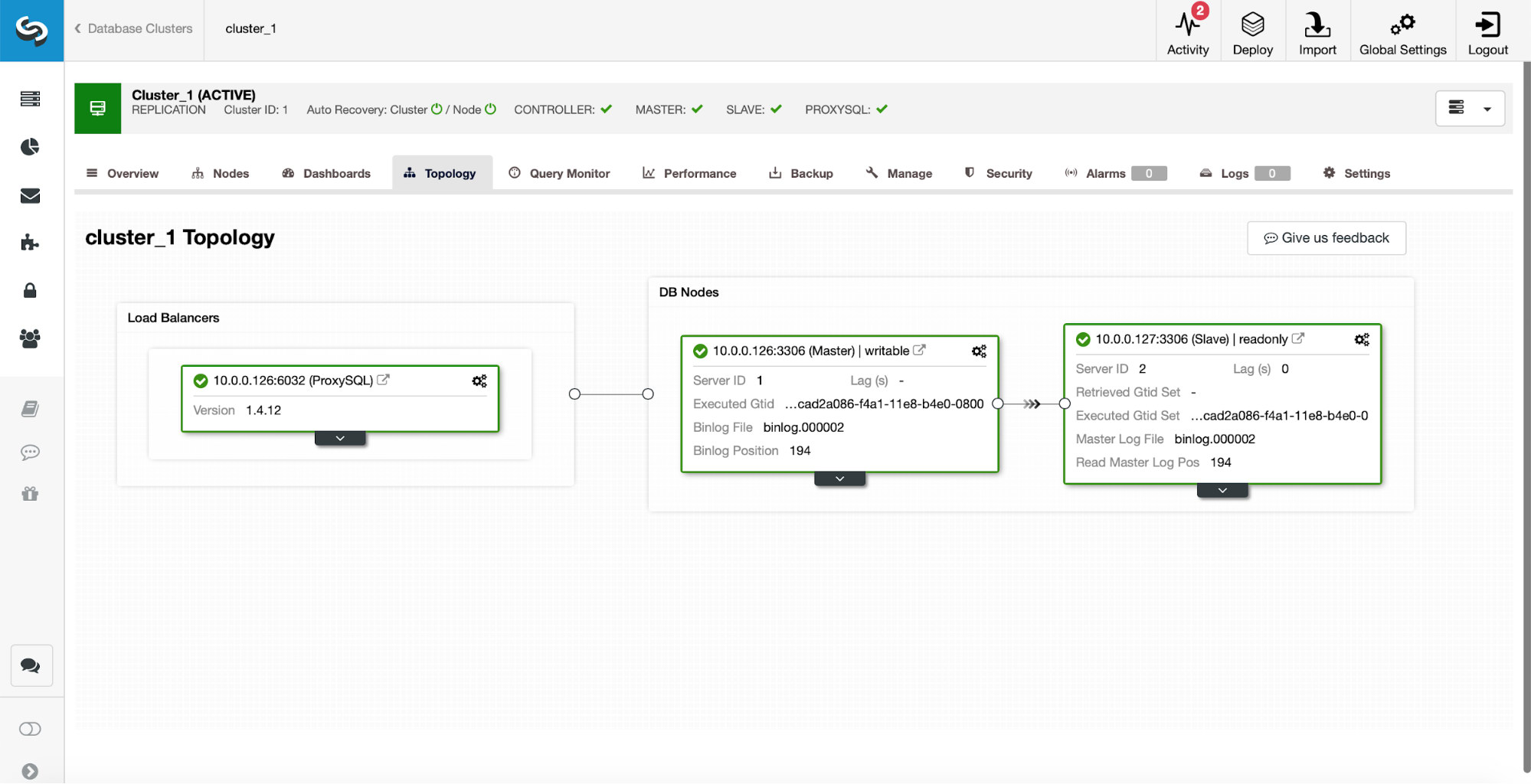
This is by no means a production-grade setup as we would have to implement some sort of high availability for the proxy layer (for example by deploying more than one ProxySQL instance, and then keepalived on top of them for floating Virtual IP), but it will be more than enough for our tests.
First, we are going to verify the ProxySQL configuration to make sure query cache settings are what we want them to be.
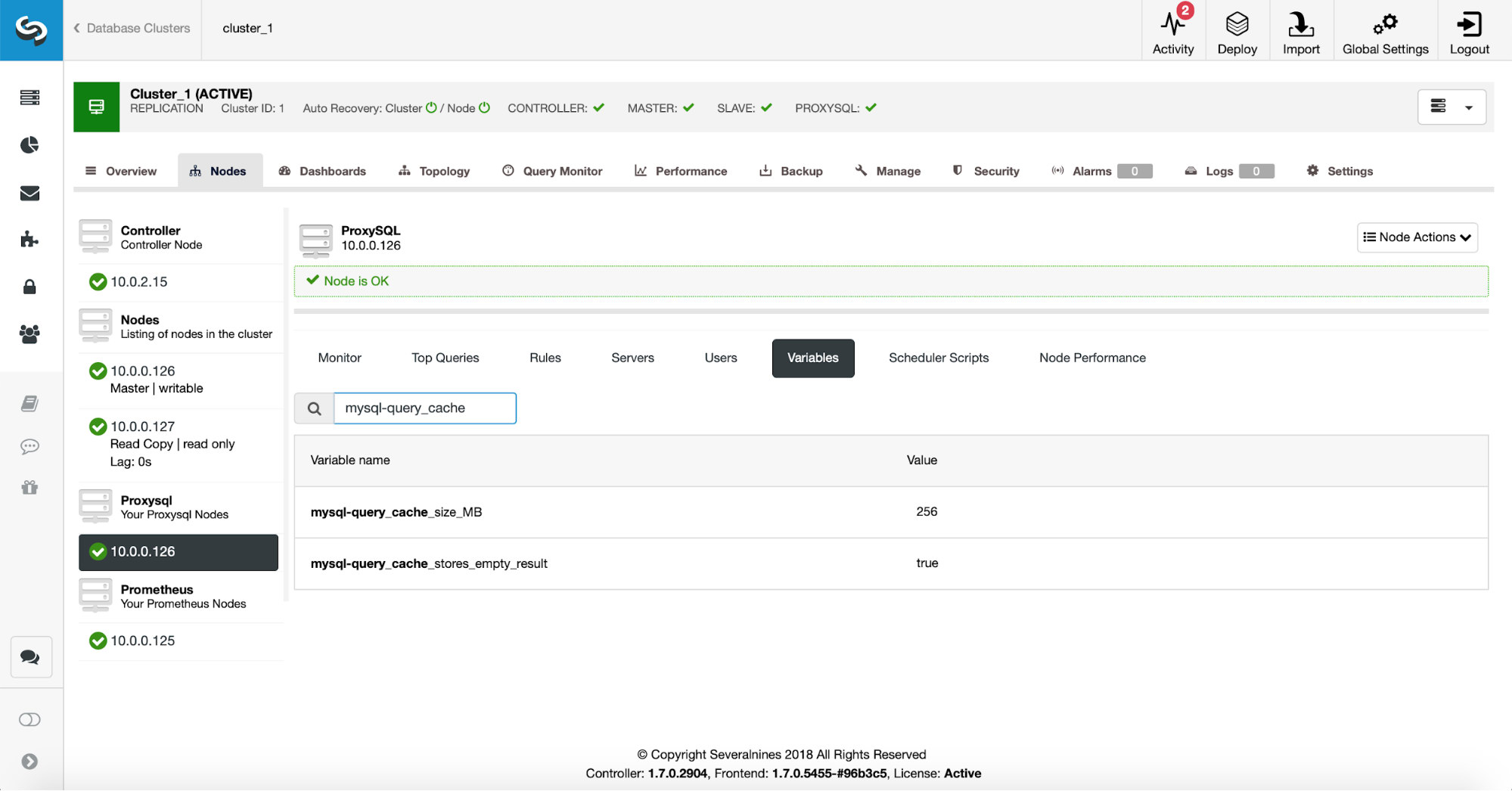
256 MB of query cache should be about right and we want to cache also the empty result sets – sometimes a query which returns no data still have to do a lot of work to verify there’s nothing to return.
Next step is to create query rules which will match the queries you want to cache. There are two ways to do that in ClusterControl.
Manually Adding Query Rules
First way requires a bit more manual actions. Using ClusterControl you can easily create any query rule you want, including query rules that do the caching. First, let’s take a look at the list of the rules:
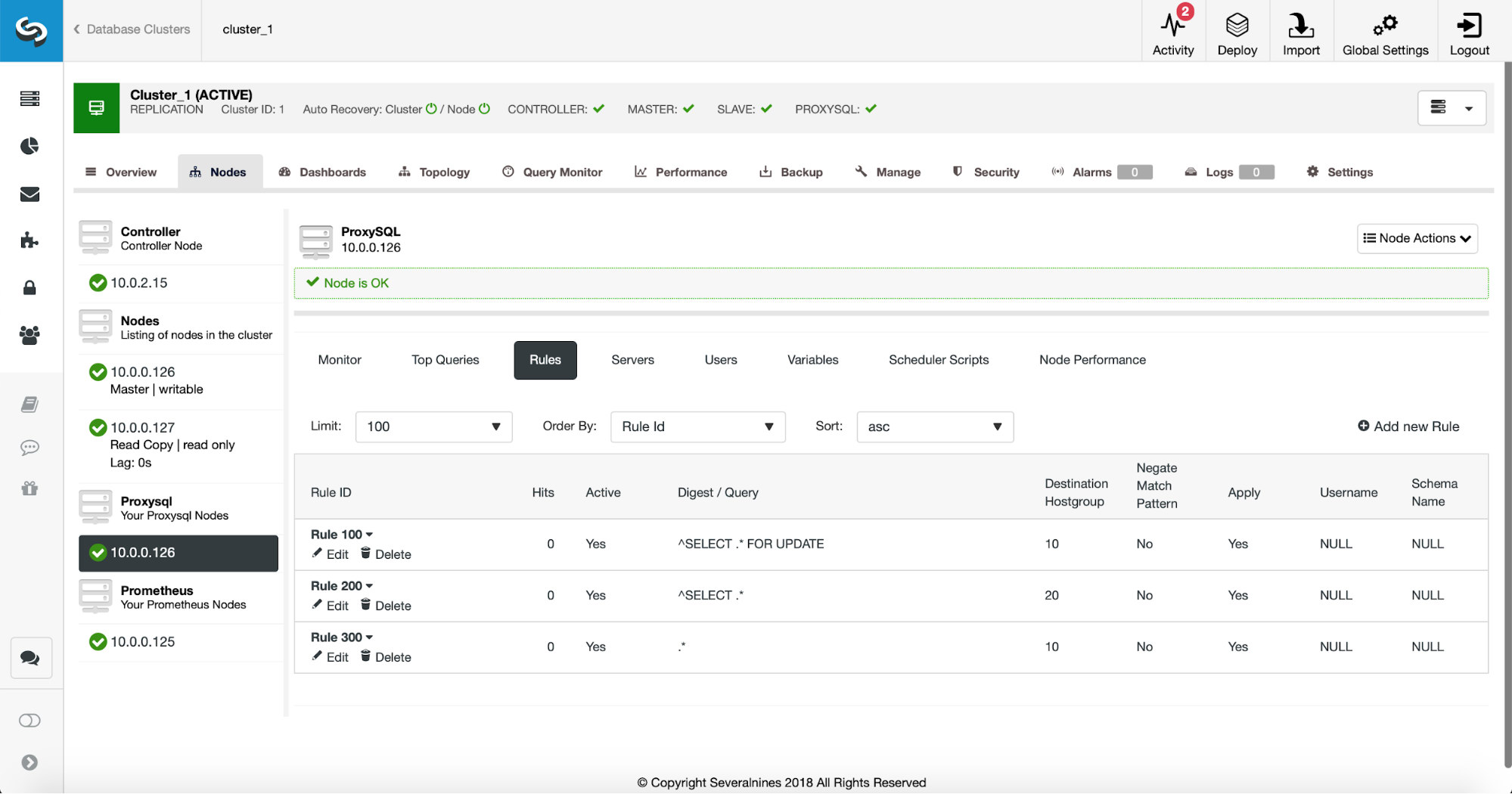
At this point, we have a set of query rules to perform the read/write split. The first rule has an ID of 100. Our new query rule has to be processed before that one so we will use lower rule ID. Let’s create a query rule which will do the caching of queries similar to this one:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY c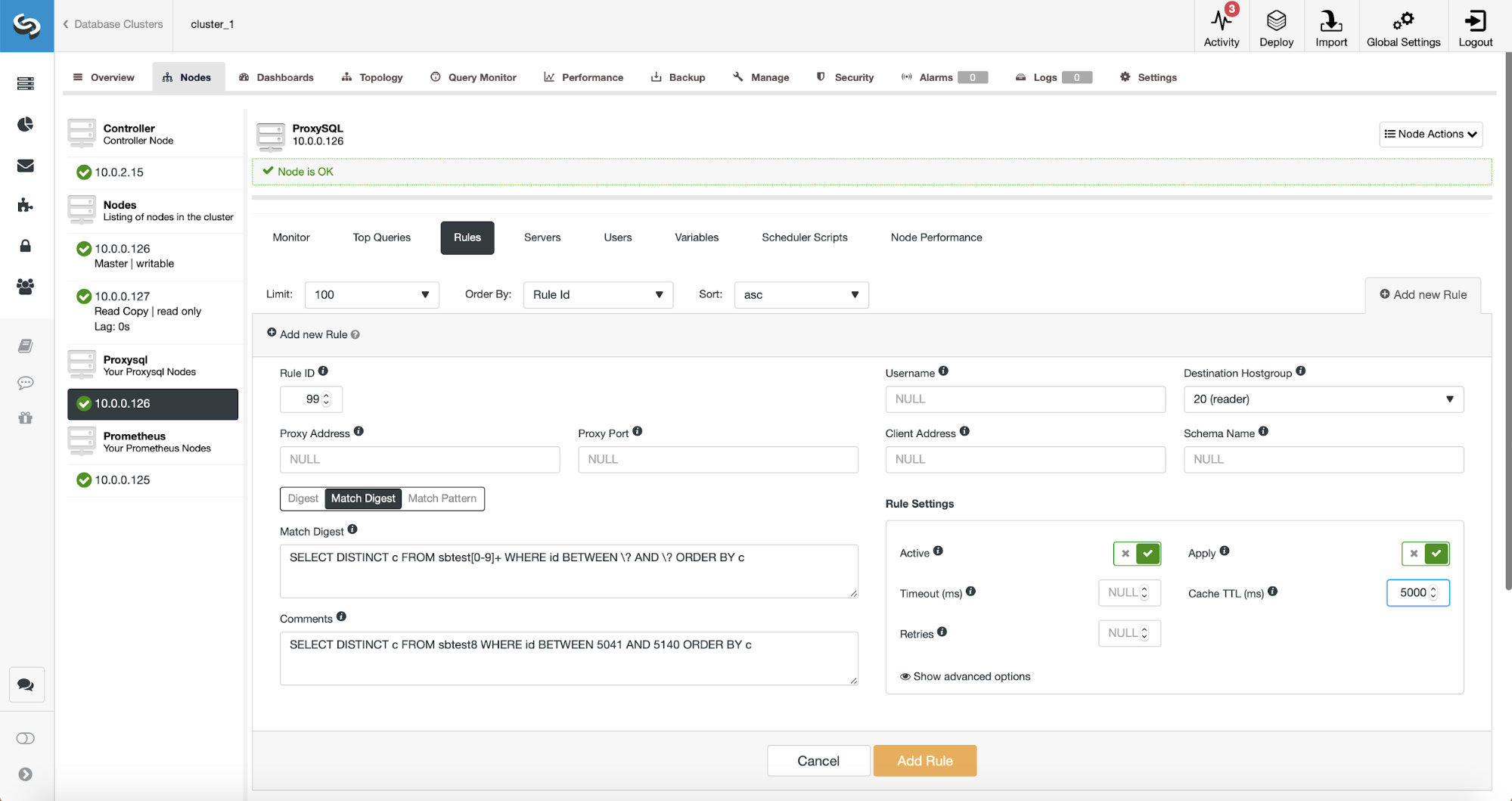
There are three ways of matching the query: Digest, Match Digest and Match Pattern. Let’s talk a bit about them here. First, Match Digest. We can set here a regular expression that will match a generalized query string that represents some query type. For example, for our query:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cThe generic representation will be:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN ? AND ? ORDER BY cAs you can see, it stripped the arguments to the WHERE clause therefore all queries of this type are represented as a single string. This option is quite nice to use because it matches whole query type and, what’s even more important, it’s stripped off any whitespaces. This makes it so much easier to write a regular expression as you don’t have to account for weird line breaks, whitespaces at the beginning or end of the string and so on.
Digest is basically a hash that ProxySQL calculates over the Match Digest form.
Finally, Match Pattern matches against full query text, as it was sent by the client. In our case, the query will have a form of:
SELECT DISTINCT c FROM sbtest8 WHERE id BETWEEN 5041 AND 5140 ORDER BY cWe are going to use Match Digest as we want all of those queries to be covered by the query rule. If we wanted to cache just that particular query, a good option would be to use Match Pattern.
The regular expression that we use is:
SELECT DISTINCT c FROM sbtest[0-9]+ WHERE id BETWEEN ? AND ? ORDER BY cWe are matching literally the exact generalized query string with one exception – we know that this query hit multiple tables therefore we added a regular expression to match all of them.
Once this is done, we can see if the query rule is in effect or not.
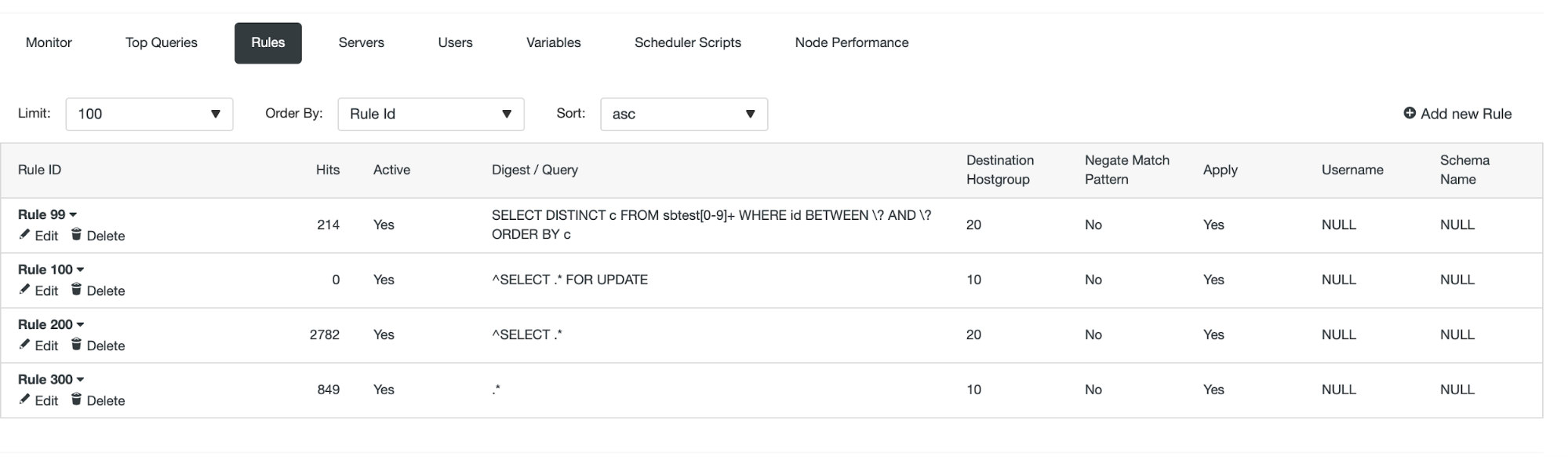
We can see that ‘Hits’ are increasing which means that our query rule is being used. Next, we’ll look at another way to create a query rule.
Using ClusterControl to Create Query Rules
ProxySQL has a useful functionality of collecting statistics of the queries it routed. You can track data like execution time, how many times a given query was executed and so on. This data is also present in ClusterControl:
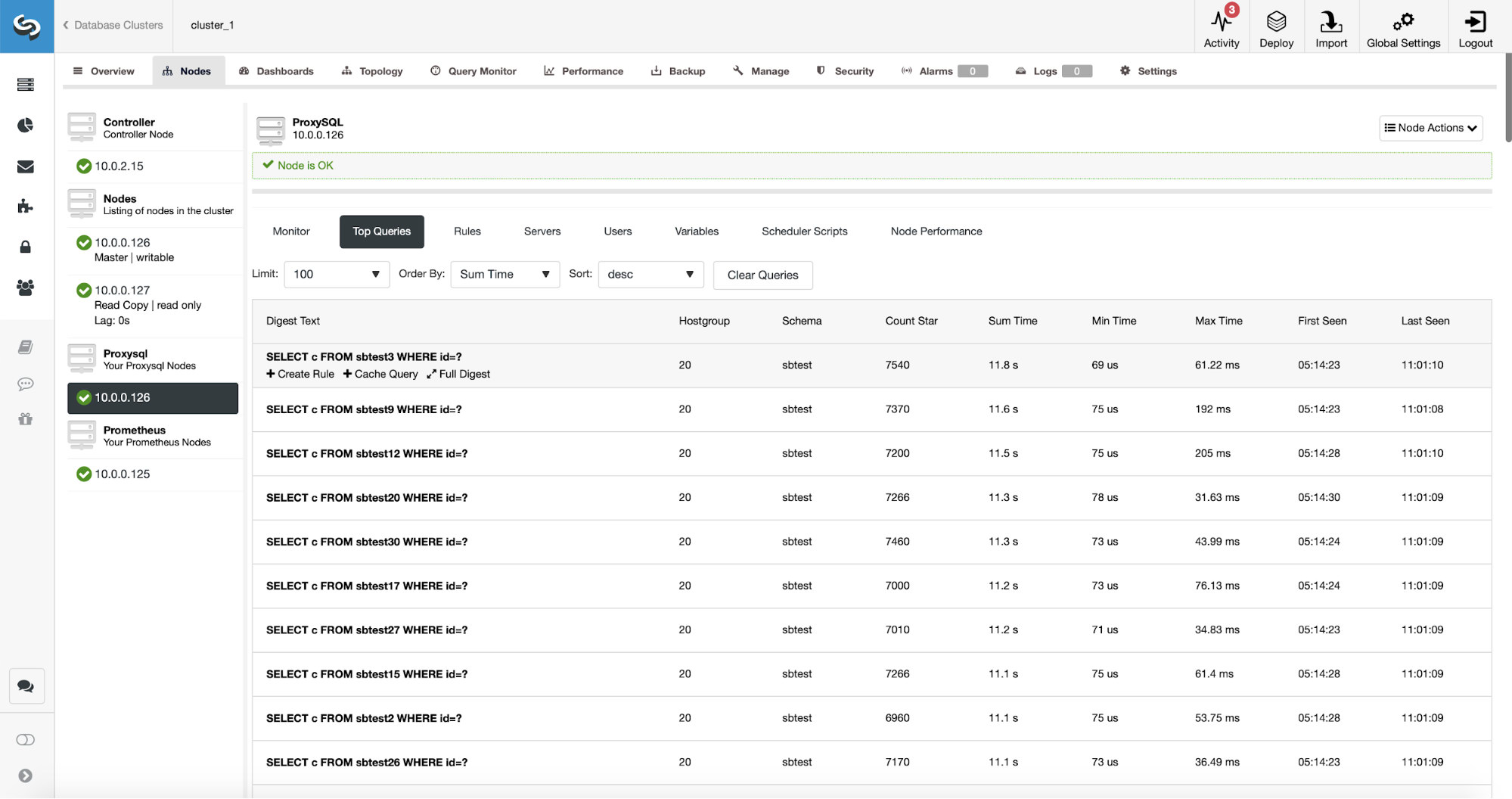
What is even better, if you point on a given query type, you can create a query rule related to it. You can also easily cache this particular query type.
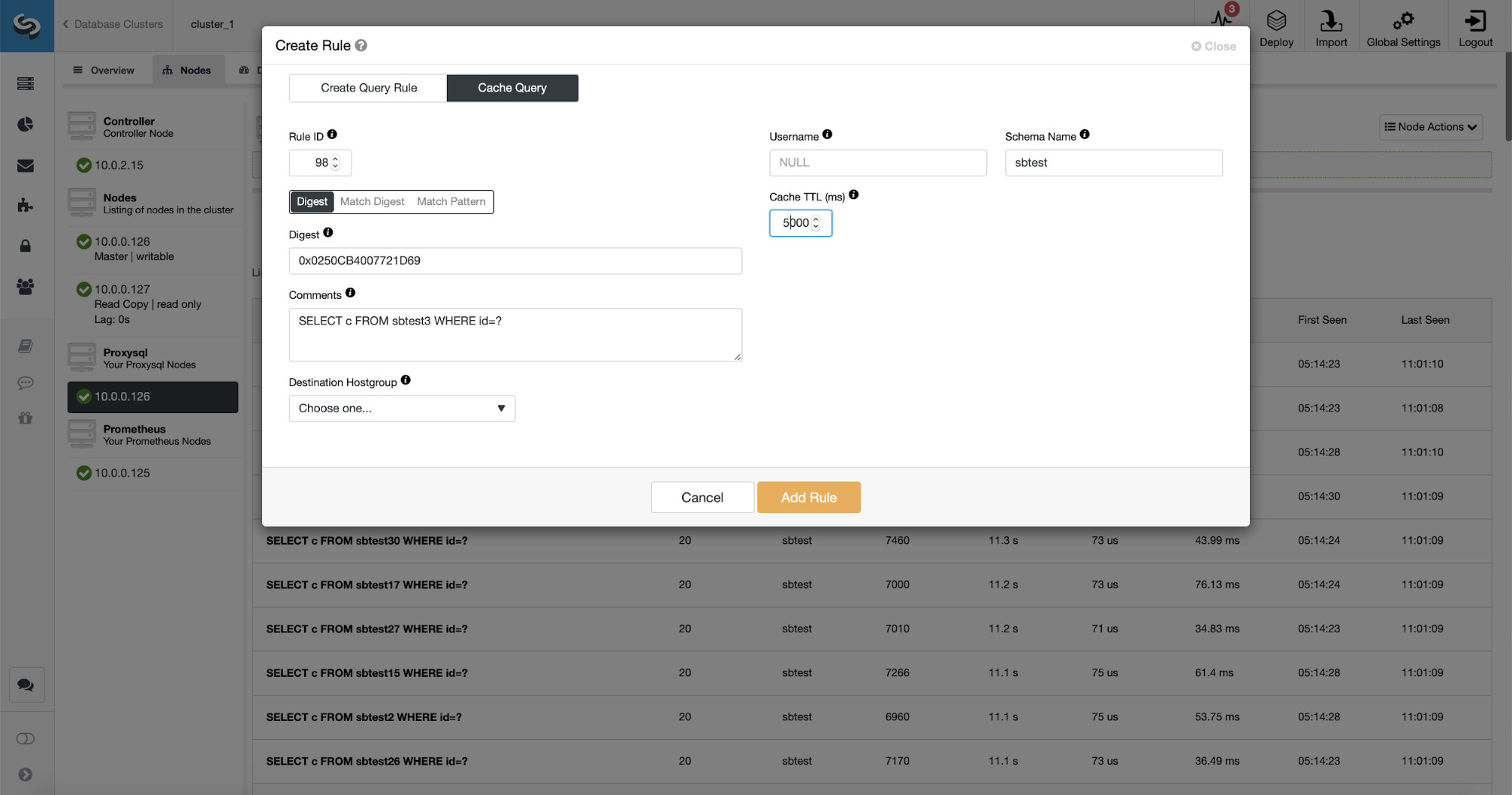
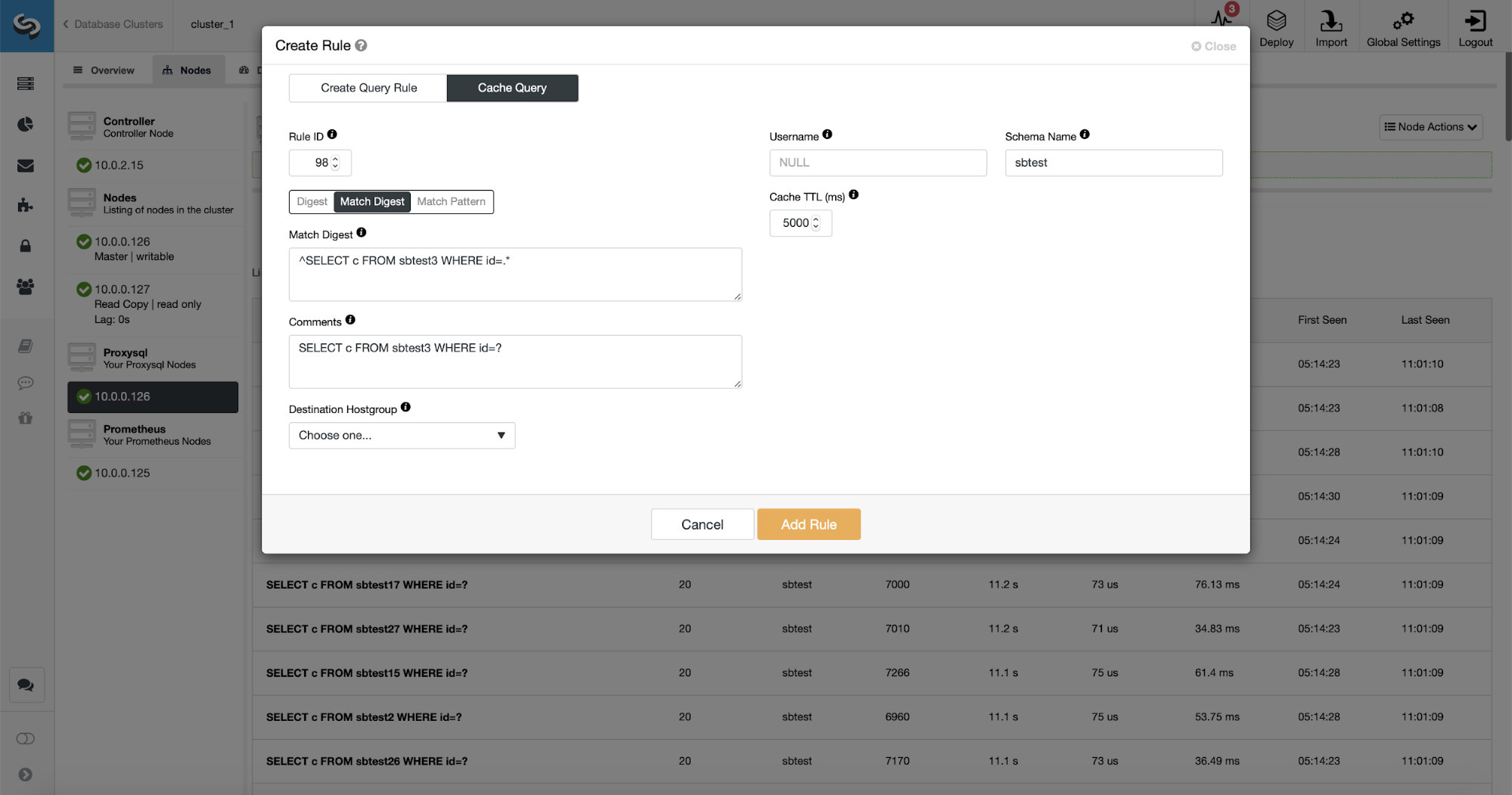
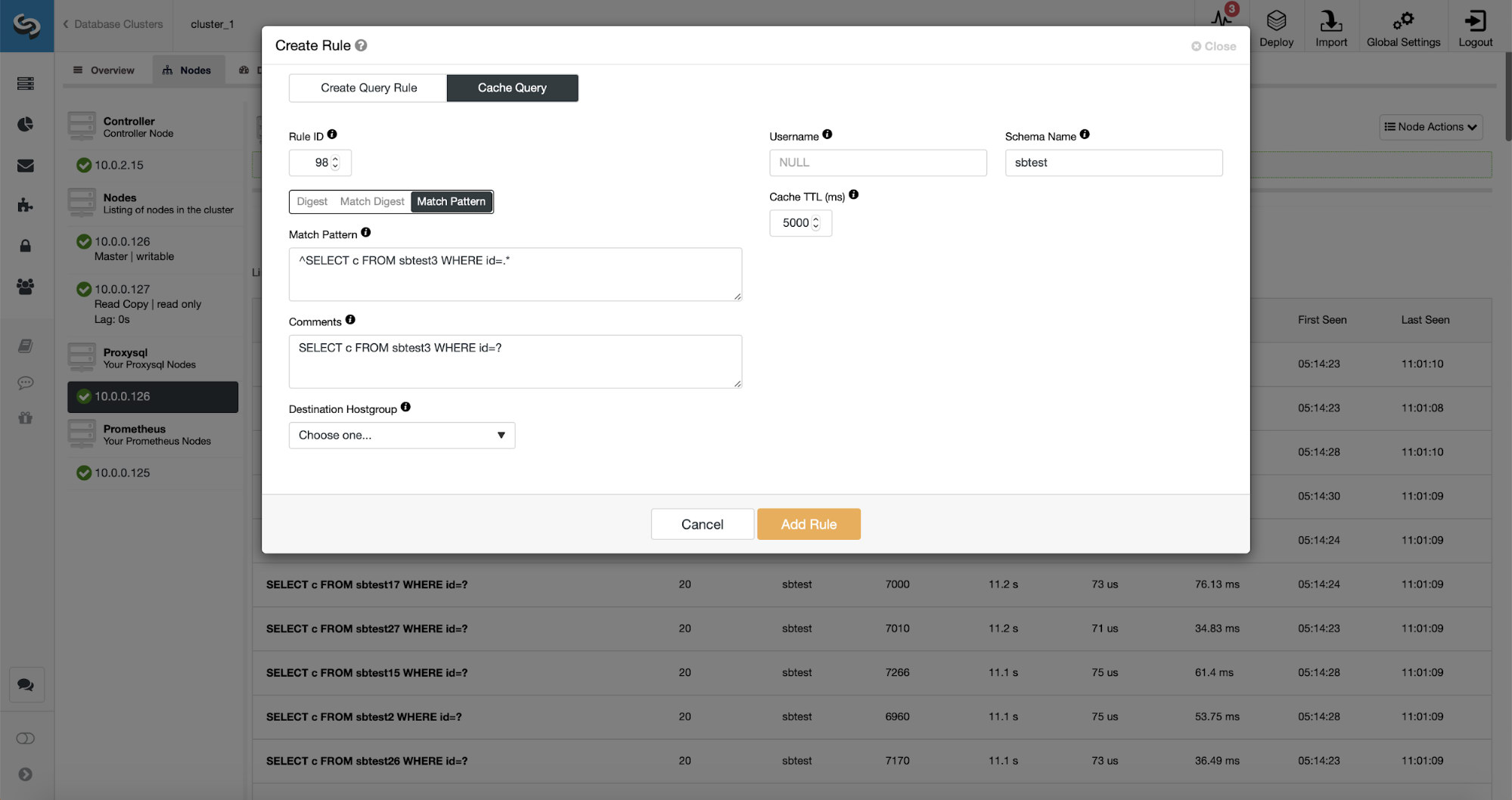
As you can see, some of the data like Rule IP, Cache TTL or Schema Name are already filled. ClusterControl will also fill data based on which matching mechanism you decided to use. We can easily use either hash for a given query type or we can use Match Digest or Match Pattern if we would like to fine-tune the regular expression (for example doing the same as we did earlier and extending the regular expression to match all the tables in sbtest schema).
This is all you need to easily create query cache rules in ProxySQL. Download ClusterControl to try it today.



