blog
My PostgreSQL Database is Out of Disk Space

Disk space is a demanding resource nowadays. You usually will want to store data as long as possible, but this could be a problem if you don’t take the necessary actions to prevent a potential “out of disk space” issue.
In this blog, we will see how we can detect this issue for PostgreSQL, prevent it, and if it is too late, some options that probably will help you to fix it.
How to Identify PostgreSQL Disk Space Issues
If you, unfortunately, are in this out of disk space situation, you will able to see some errors in the PostgreSQL database logs:
2020-02-20 19:18:18.131 UTC [4400] LOG: could not close temporary statistics file "pg_stat_tmp/global.tmp": No space left on deviceor even in your system log:
Feb 20 19:29:26 blog-pg1 rsyslogd: imjournal: fclose() failed for path: '/var/lib/rsyslog/imjournal.state.tmp': No space left on device [v8.24.0-41.el7_7.2 try http://www.rsyslog.com/e/2027 ]PostgreSQL can continue works for awhile running read-only queries, but eventually, it will fail trying to write to disk, then you will see something like this in your client session:
WARNING: terminating connection because of crash of another server process
DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
HINT: In a moment you should be able to reconnect to the database and repeat your command.
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Failed.Then, if you take a look at the disk space, you will have this unwanted output…
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/pve-vm--125--disk--0 30G 30G 0 100% /How to Prevent PostgreSQL Disk Space Issues
The main way to prevent this kind of issue is by monitoring the disk space usage, and database or disk usage growth. For this, a graph should be a friendly way to monitor the disk space increment:

And the same for the database growth:
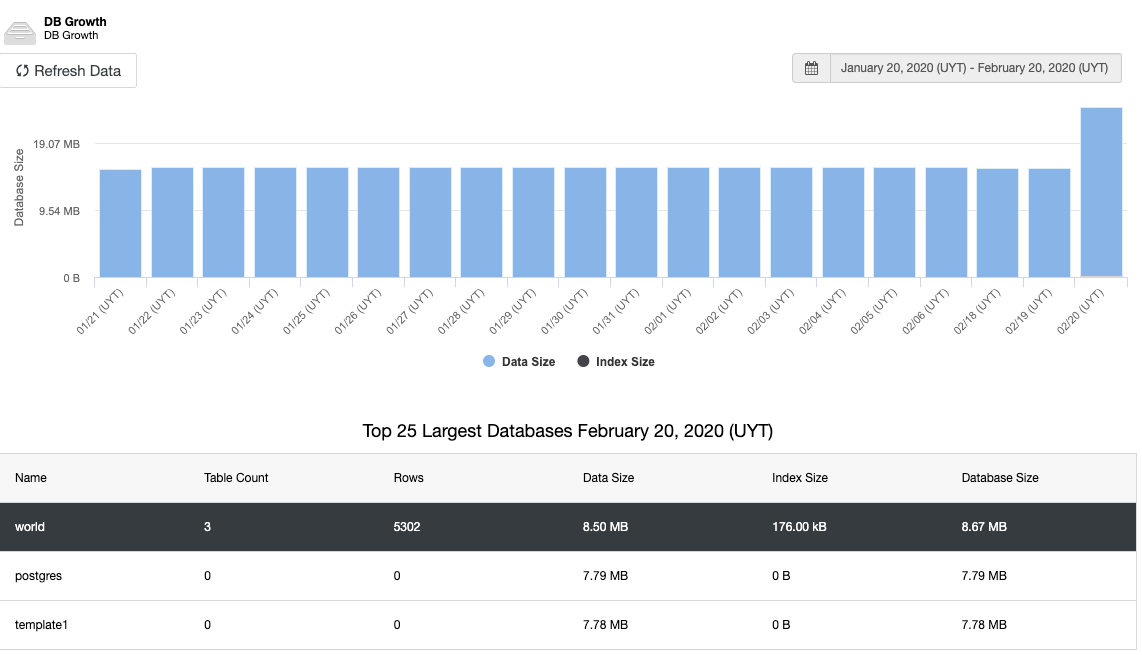
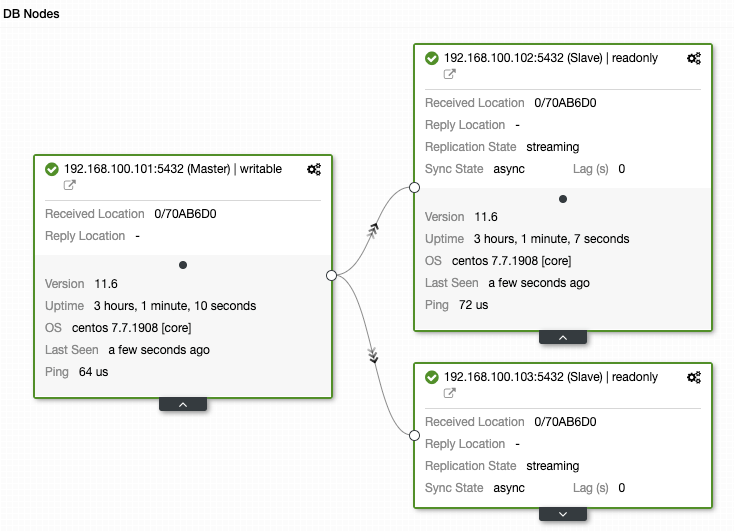
Another important thing to monitor is the replication status. If you have a replica and, for some reason, this stops working, depending on the configuration, it could be possible that PostgreSQL store all the WAL files to restore the replica when it comes back.
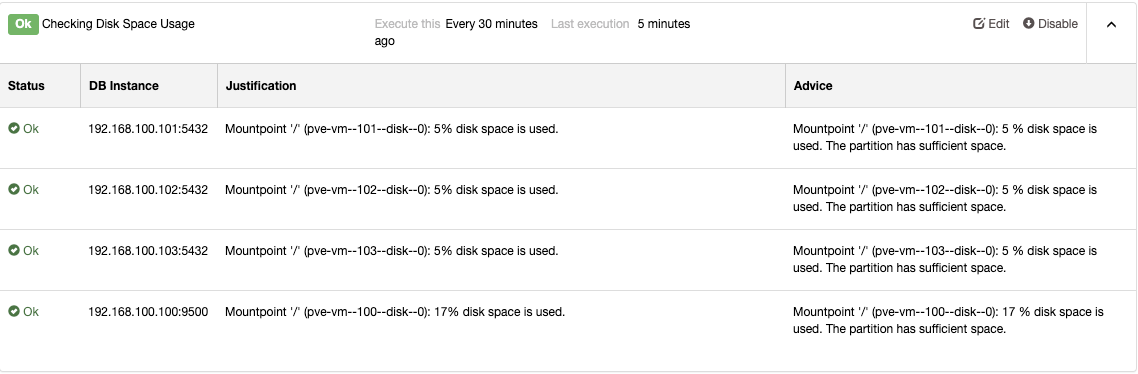
All this monitoring system doesn’t make sense without an alerting system to know when you need to take actions:
How to Fix PostgreSQL Disk Space Issues
Well, if you are facing this out of disk space issue even with the monitoring and alerting system implemented (or not), there are many options to try to fix this issue without data lost (or the less as possible).
What is Consuming Your Disk Space?
The first step should be determining where my disk space is. A best practice is having separate partitions, at least one separate partition for your database storage, so you can easily confirm if your database or your system is using excessive disk space. Another advantage of this is to minimize the damage. If your root partition is full, your database can still write in his own partition without issues.
Database Space Usage
Let’s see now some useful commands to check your database disk space usage.
A basic way to check the database space usage is checking the data directory in the filesystem:
$ du -sh /var/lib/pgsql/11/data/
819M /var/lib/pgsql/11/data/Or if you have a separate partition for your data directory, you can use df -h directly.
The PostgreSQL command “l+” list the databases adding the size information:
$ postgres=# l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace
| Description
-----------+----------+-----------+---------+-------+-----------------------+---------+------------
+--------------------------------------------
postgres | postgres | SQL_ASCII | C | C | | 7965 kB | pg_default
| default administrative connection database
template0 | postgres | SQL_ASCII | C | C | =c/postgres +| 7817 kB | pg_default
| unmodifiable empty database
| | | | | postgres=CTc/postgres | |
|
template1 | postgres | SQL_ASCII | C | C | =c/postgres +| 7817 kB | pg_default
| default template for new databases
| | | | | postgres=CTc/postgres | |
|
world | postgres | SQL_ASCII | C | C | | 8629 kB | pg_default
|
(4 rows)Using pg_database_size and the database name you can see the database size:
postgres=# SELECT pg_database_size('world');
pg_database_size
------------------
8835743
(1 row)And using the pg_size_pretty to see this value in a human-readable way could be even better:
postgres=# SELECT pg_size_pretty(pg_database_size('world'));
pg_size_pretty
----------------
8629 kB
(1 row)When you know where space is, you can take the corresponding action to fix it. Keep in mind that just deleting rows is not enough to recover the disk space, you will need to run a VACUUM or VACUUM FULL to finish the task.
Log Files
The easiest way to recover disk space is by deleting log files. You can check the PostgreSQL log directory or even the system logs to verify if you can gain some space from there. If you have something like this:
$ du -sh /var/lib/pgsql/11/data/log/
18G /var/lib/pgsql/11/data/log/You should check the directory content to see if there is a log rotation/retention problem or something is happening in your database and writing it to the logs.
$ ls -lah /var/lib/pgsql/11/data/log/
total 18G
drwx------ 2 postgres postgres 4.0K Feb 21 00:00 .
drwx------ 21 postgres postgres 4.0K Feb 21 00:00 ..
-rw------- 1 postgres postgres 18G Feb 21 14:46 postgresql-Fri.log
-rw------- 1 postgres postgres 9.3K Feb 20 22:52 postgresql-Thu.log
-rw------- 1 postgres postgres 3.3K Feb 19 22:36 postgresql-Wed.logBefore deleting the logs, if you have a huge one, a good practice is to keep the last 100 lines or so, and then delete it. So, you can check what is happening after generating free space.
$ tail -100 postgresql-Fri.log > /tmp/log_temp.logAnd then:
$ cat /dev/null > /var/lib/pgsql/11/data/log/postgresql-Fri.logIf you just delete it with “rm” and the log file is being used by the PostgreSQL server (or another service) space won’t be released, so you should truncate this file using this cat /dev/null command instead.
This action is only for PostgreSQL and system log files. Don’t delete the pg_wal content or another PostgreSQL file as it could generate critical damage to your database.
Bloat
In a normal PostgreSQL operation, tuples that are deleted or obsoleted by an update are not physically removed from the table; they are present until a VACUUM is performed. So, it is necessary to do the VACUUM periodically (AUTOVACUUM), especially in frequently-updated tables.
The problem here is space is not returned to the operating system using just VACUUM, it is only available for use in the same table.
VACUUM FULL rewrites the table into a new disk file, returning the unused space to the operating system. Unfortunately, it requires an exclusive lock on each table while it is running.
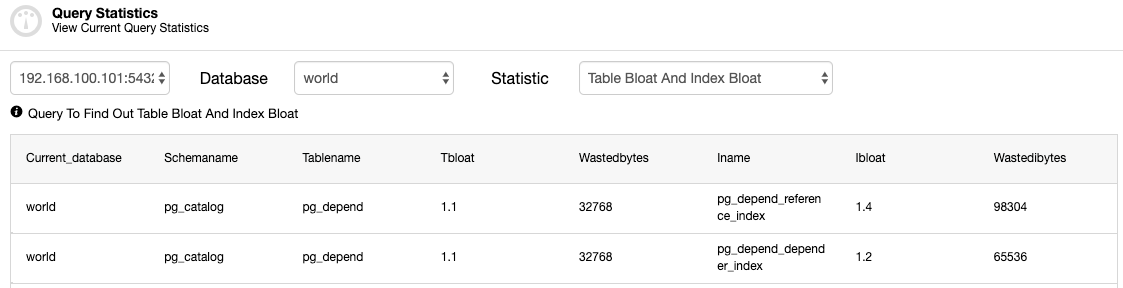
You should check the tables to see if a VACUUM (FULL) process is required.
Replication Slots
If you are using replication slots, and it is not active for some reason:
postgres=# SELECT slot_name, slot_type, active FROM pg_replication_slots;
slot_name | slot_type | active
-----------+-----------+--------
slot1 | physical | f
(1 row)It could be a problem for your disk space because it will store the WAL files until they have been received by all the standby nodes.
The way to fix it is recovering the replica (if possible), or deleting the slot:
postgres=# SELECT pg_drop_replication_slot('slot1');
pg_drop_replication_slot
--------------------------
(1 row)So, the space used by the WAL files will be released.
Conclusion
As we mentioned, monitoring and alerting systems are the keys to avoiding these kinds of issues. In this way, ClusterControl can help you to have your systems up and running, sending you alarms when needed or even taking recovery action to keep your database cluster working. You can also deploy/import different database technologies and scaling them out if needed.



