blog
Kubernetes on-premises: the why, what and how to implement

The siren song of the cloud is undeniable, promising scalability, resilience, and reduced operational overhead. However, the reality can be different. Factors like vendor lock-in, limited control, and unexpected costs, mean that organizations can still benefit from on-premises (on-prem) infrastructure to deploy and manage their systems.
Kubernetes—the de facto container orchestration tool in the cloud native ecosystem today—has enabled countless organizations to maximize the cloud’s possibilities. But there’s a question from on-premises users…“Can we deploy Kubernetes on-premises?” The short answer is “YES!!” and this article will explain why and how.
In this article, I will start by discussing what Kubernetes on-premises is, why organizations would want to deploy Kubernetes on-premises and considerations for Kubernetes on-prem. Towards the end, I’ll show you how you can get started with Kubernetes on-premises the provider agnostic way.
What is Kubernetes on-premises?
Kubernetes on-premises refers to running a Kubernetes cluster on your own infrastructure, within your own data center, rather than in a cloud environment offered by a cloud service provider (CSP) like AWS.
Kubernetes is platform-agnostic, which means it can run anywhere— from your local development environment using tools like minikube to high-scale production environments in the cloud and, critically, on-premises data centers.
Deploying and running Kubernetes on-premises is not the same as doing it in the cloud. It requires navigating specific challenges and leveraging the unique advantages of your private infrastructure.
Why run Kubernetes on-premises?
Seeing that Kubernetes on-prem has its unique constraints that can vary amongst organizations, why would one deploy Kubernetes on-prem? These are the most common reasons why organizations need on-premises infrastructure.
Environment standardization
Today you can implement Serverless, WebAssembly, blockchain, etc. on Kubernetes. Seeing the ability to run Kubernetes anywhere, organizations that have on-premises infrastructure can easily innovate with new and powerful technologies using the same/similar tools and processes used in the cloud without the wholesale shift.
Essentially, Kubernetes acts as a great environment equalizer, allowing these cutting-edge technologies to run seamlessly on any infrastructure.
Compliance & data privacy
Many industries operate under strict regulations regarding data storage and access. On-premises Kubernetes deployments provide complete control over data location, ensuring compliance with industry-specific mandates like GDPR, HIPAA, or financial regulations.
Furthermore, sensitive data might require heightened security measures that are best met within a privately managed environment. Deploying on-premises allows for granular control over security protocols and minimizes exposure to external threats.
Integration with Legacy systems
Legacy systems are still the backbone of our society today, especially in industries like banking, healthcare, and insurance. Many organizations in these industries are modernizing some parts of their systems and some decide to use Kubernetes as they containerize them.
What’s the best way to manage containerized systems deployed on-prem? Kubernetes on-prem.
This approach enables organizations to modernize their infrastructure incrementally, avoiding disruptions to critical operations. By running workloads on-premises, they can minimize latency by keeping data processing close to the source, rather than relying on cloud-based solutions.
Avoid Lock-in
One of the main challenges organizations today face with CSPs is vendor lock-in. Yes, you can transfer data from one cloud to another today with tools like GCP Storage Transfer Service or AWS DataSync, but that doesn’t mean you can easily move infrastructure. Especially infrastructure that has gone through multiple iterations over the years.
While Kubernetes is platform agnostic, managed Kubernetes offerings on CSPs have key differences due to their underlying cloud platforms. Control plane architecture, networking, features, ecosystem integrations etc differences that can make migration a challenge.
Long-term cost of the cloud service providers
Aside from vendor lock-in, the long-term cost of cloud services is a major challenge for organizations, especially at scale — and you know Kubernetes is designed for scale.
While initial setup costs may be higher, on-premises Kubernetes can offer a more predictable cost model over the long term, especially for organizations with consistent and predictable workloads. On-premises deployments allow for fine-grained control over resource allocation, maximizing efficiency and potentially reducing costs compared to cloud provider pricing models.
Considerations for Kubernetes on-premises
Before deploying Kubernetes on-prem, it’s crucial to approach your deployment with a clear understanding of the unique challenges it presents. Beyond the initial excitement of controlling your own infrastructure, several factors demand careful consideration to ensure a successful and sustainable Kubernetes environment.
Location
When deploying Kubernetes on-premises, the location of your infrastructure—whether in your own data center, a co-located facility, or at the edge—plays a crucial role in shaping performance, control, and cost. Owning a data center provides maximum control, but requires more configurations.
Co-locating in a third-party data center would reduce upfront costs and some maintenance overhead, but post limitations around physical access and potentially data governance.
In cases where you want to deploy on the edge, network connectivity, security, and cooling are concerns you should think about.
Hardware management
If you own/manage your data centers, hardware management is a critical consideration for running Kubernetes on-premises, as it significantly impacts the performance, reliability, and scalability of the environment.
Unlike cloud environments where infrastructure is abstracted and hardware maintenance is managed by the provider, on-premises deployments place the responsibility entirely on the organization’s IT and DevOps teams. This requires careful planning around hardware selection, capacity, maintenance, and compatibility to ensure Kubernetes can run effectively on local resources.
A common challenge is tackling over-provisioning. For example, if you’re running Kubernetes on-premises and it’s utilizing only 30% of the available CPU, you are underutilizing your CapEx investment. To make better use of this upfront cost, consider deploying or moving additional applications to the same server to fully leverage the existing infrastructure.
Network complexity
Deploying Kubernetes on-premises does not come with the built-in, automated networking features that cloud providers offer, making it essential for organizations to design, implement, and maintain their own networking infrastructure to support the cluster’s needs. Internal networking within an on-premises Kubernetes environment requires careful configuration.
Kubernetes uses a flat networking model that assumes all pods within a cluster can communicate directly with one another across nodes. Setting this up on-premises involves selecting and configuring a network overlay solution, such as Cilium, Calico, Flannel, etc. to enable seamless pod-to-pod communication while respecting network policies for security and isolation. Each of these tools brings specific configuration and maintenance needs, and they must be integrated with the existing network setup.
Storage concerns
Storage is a fundamental consideration when deploying Kubernetes on-premises, as managing data in a containerized environment presents unique challenges that require careful planning.
Yes, Kubernetes wasn’t originally designed for stateless workloads, but organizations do deploy stateful applications on Kubernetes today, from ML workloads to databases of different flavors.
Kubernetes supports a variety of storage solutions, including local storage, Network File System (NFS), and more sophisticated dynamic provisioning options through the Container Storage Interface (CSI).
In on-premises environments, persistent storage requires careful management to ensure that stateful applications have the reliability they need; this often involves integrating with existing SAN/NAS solutions or using distributed storage systems.
Managed Kubernetes services? The key to Kubernetes on-prem?
Yes, you can manually deploy and manage Kubernetes on-premises — Doing Kubernetes The Hard Way. But in production, you wouldn’t want to do that. You would want to automate as many of the deployment processes as possible with tools like kOps – Kubernetes Operations, Kubeadm, and Kubespray.
With these tools, you specify your configuration and they handle most of the details of setting up and bootstrapping the clusters for you. But this approach in itself can be challenging when issues arise. Due to this, there’s been a growing ecosystem of service providers to support on-premises data centers.
The Kubernetes on-premises landscape is supported by specialized organizations such as Rancher by SUSE, VMware vSphere and Red Hat OpenShift, and smaller, agnostic organizations like Sidero Labs, Platform9, Giant Swarm, etc also contribute to the ecosystem, offering fully managed experiences tailored to on-premises needs.
Additionally, major CSPs also offer on-premises Kubernetes solutions, namely, Amazon EKS Anywhere, Google Cloud Anthos and Azure Arc. These solutions are very attractive for organizations that have some applications running on the CSP’s Kubernetes on the cloud and want to extend it to on-premises, effectively creating a hybrid cloud solution. However, these will not be the best solutions for air-gapped environments.
Agnostic guide to setting up Kubernetes on-premises
As mentioned earlier, there are several ways to deploy Kubernetes on-prem. You can choose to do “Kubernetes The Hard Way”, automate some processes with the likes of kOps, or use a managed service or an agnostic tool.
On the Severalnines blog, over the past decade, we’ve been supporting organizations all over the world in implementing a Sovereign DBaaS model that lets them have control not just of their data, but the infrastructure and tooling that surrounds it through cloud-agnostic tools like ClusterControl. So we will also let you know ways to have more control over your environments with no manual overhead.
If you google Kubernetes on-premises, aside from the specialized providers, you would frequently see a tool called Talos Linux among the results you would get on Reddit threads.
Talos Linux is a modern, open-source Linux distribution built for Kubernetes. Talos can help you deploy a secure, immutable, and minimal Kubernetes cluster on any environment including bare metal, virtualized, and single-board platforms.
I got to try out Talos running on a single-board computer at the SREDay London Conference 2024, and it was indeed a great experience.
Overview
In this demo, I will introduce you to Talos by taking you through the steps to create a KVM-based cluster of 2 control plane nodes and 1 worker node with Vagrant and its libvirt plugin as outlined in the Talos documentation. KVM is ideal for building a Kubernetes cluster on your local system or in a private data center, as it offers flexibility, performance, and low overhead.
For this, we’ll mount the Talos ISO onto the VMs using a virtual CD-ROM and configure the VMs to prioritize booting from the disk, with the CD-ROM as a fallback option.
Prerequisites
To follow along with the demo in this article, you need to have the following prerequisites.
- Linux OS — For this article, we will be using an Ubuntu 22.04 Server of 8GB RAM and 160GB Disk.
- Vagrant installed — If you are using Vagrant version greater than 2.4.1-1, you might have issues installing plugins due to Logger dependency conflict with Vagrant 2.4.2, you should downgrade to 2.4.1-1.
- vagrant-libvirt plugin installed
- talosctl installed
- kubectl installed
Setting up Talos Linux on virtualized platforms with Vagrant & Libvirt
We will start by downloading the latest Talos ISO image — metal-amd64.iso — from GitHub releases into the /tmp directory with
wget --timestamping curl https://factory.talos.dev/image/376567988ad370138ad8b2698212367b8edcb69b5fd68c80be1f2ec7d603b4ba/v1.8.0/metal-amd64.iso -O /tmp/metal-amd64.isoNext create the demo Vagrant file with the following configuration:
Vagrant.configure("2") do |config|
config.vm.define "control-plane-node-1" do |vm|
vm.vm.provider :libvirt do |domain|
domain.cpus = 2
domain.memory = 2048
domain.serial :type => "file", :source => {:path => "/tmp/control-plane-node-1.log"}
domain.storage :file, :device => :cdrom, :path => "/tmp/metal-amd64.iso"
domain.storage :file, :size => '4G', :type => 'raw'
domain.boot 'hd'
domain.boot 'cdrom'
end
end
config.vm.define "control-plane-node-2" do |vm|
vm.vm.provider :libvirt do |domain|
domain.cpus = 2
domain.memory = 2048
domain.serial :type => "file", :source => {:path => "/tmp/control-plane-node-2.log"}
domain.storage :file, :device => :cdrom, :path => "/tmp/metal-amd64.iso"
domain.storage :file, :size => '4G', :type => 'raw'
domain.boot 'hd'
domain.boot 'cdrom'
end
end
config.vm.define "worker-node-1" do |vm|
vm.vm.provider :libvirt do |domain|
domain.cpus = 1
domain.memory = 1024
domain.serial :type => "file", :source => {:path => "/tmp/worker-node-1.log"}
domain.storage :file, :device => :cdrom, :path => "/tmp/metal-amd64.iso"
domain.storage :file, :size => '4G', :type => 'raw'
domain.boot 'hd'
domain.boot 'cdrom'
end
end
endThe above configuration creates a small cluster of three VMs:
- Two control-plane nodes (each with 2 CPUs and 2GB of RAM).
- One worker node (with 1 CPU and 1GB of RAM).
Each VM has a bootable ISO mounted as a virtual CD-ROM and a 4GB primary disk, and they attempt to boot from the disk with a fallback to the CD-ROM. Serial output for each VM is logged to a corresponding file in /tmp.
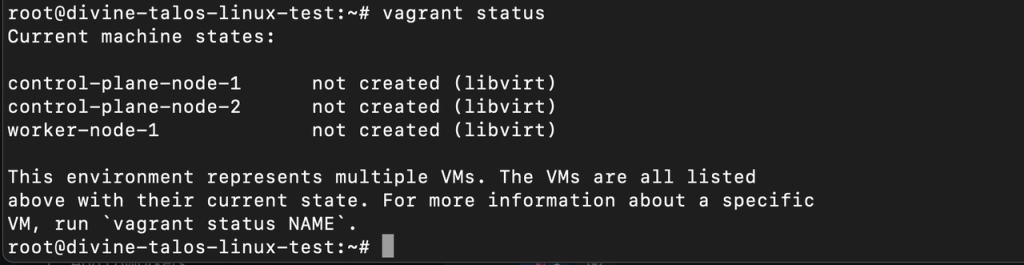
Next, check the status of the node with vagrant status and you will see the VMs in “not created” state:
Now spin up the vagrant environment with the following command:
vagrant up --provider=libvirtAfter a few seconds run vagrant status again and you see the VMs in running state.

You can find out the IP addresses assigned by the libvirt DHCP by running:
virsh list | grep root | awk '{print $2}' | xargs -t -L1 virsh domifaddrThe above command grep’s the string root because by default Vagrant creates the VMs prefixing your user. If, for example, your user is demo, edit the above command to demo.
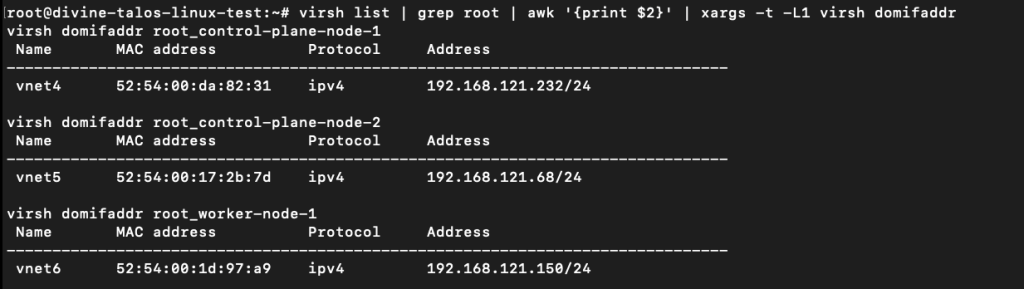
For this demo, the control plane nodes have the following IPs:
- 192.168.121.232
- 192.168.121.68
And worker node IP:
- 192.168.121.150
Note the IP addresses as we will use them further in the workflow. Also, we should now be able to interact (maintenance mode) with the nodes with the talosctl through the following command:
talosctl -n 192.168.121.232 disks --insecureYou should get an output similar to the image below.

Installing Talos
Before installing Talos, we first need to generate a “machine configuration”. A machine configuration is a YAML file you’d use to configure a Talos Linux machine.
We will start by picking an endpoint IP in the vagrant-libvirt subnet that’s not used by any nodes, e.g. — 192.168.121.100.
Run the following command to generate the machine configuration:
talosctl gen config my-cluster https://192.168.121.100:6443 --install-disk /dev/vdaThe above generates YAML configuration files for a cluster named “mycluster”. We will use these files to configure Talos nodes by applying them with talosctl commands, allowing each node to join and operate as part of the Kubernetes cluster.

Edit controlplane.yaml to add the virtual IP 192.168.121.100 to a network interface under .machine.network.interfaces:
machine:
network:
interfaces:
- interface: eth0
dhcp: true
vip:
ip: 192.168.121.100Apply this configuration to one of the control plane nodes:
talosctl -n 192.168.121.232 apply-config --insecure --file controlplane.yamlAfter applying the above config, we will enable our shell to use the generated talosconfig and configure its endpoints (the IPs of the control plane nodes):
export TALOSCONFIG=$(realpath ./talosconfig)talosctl config endpoint 192.168.121.232 192.168.121.68Now we can bootstrap the Kubernetes cluster from the first control plane node:
talosctl -n 192.168.121.232 bootstrapThe bootstrap command sets up the initial etcd database (used for storing cluster state) on that node becoming the initial leader in the control plane, and once the bootstrap is complete, additional control plane and worker nodes can join the cluster.
Now apply the machine configurations to the remaining nodes:
talosctl -n 192.168.121.68 apply-config --insecure --file controlplane.yamltalosctl -n 192.168.121.150 apply-config --insecure --file worker.yamlAfter a while, we can see that all the members have joined by running the following command:
talosctl -n 192.168.121.232 get members
Interacting with the Kubernetes cluster
To interact with the Kubernetes cluster we need to first retrieve the kubeconfig from the cluster using the following command:
talosctl -n 192.168.121.232 kubeconfig ./kubeconfigNow we can view all the nodes in the cluster with the kubectl get node command:
kubectl --kubeconfig ./kubeconfig get node -owideYou will see an output similar to the image below:

Now you have a highly available Talos cluster running!!!
Troubleshooting
While walking through the demo, you might encounter a “Call to virStoragePoolLookupByName failed” fail error as shown in the image below.
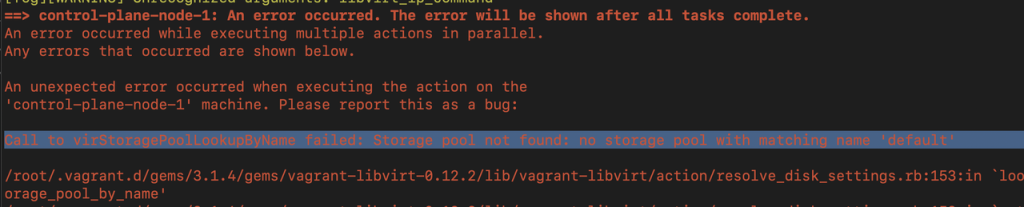
The error message indicates that libvirt (via virsh) is trying to access a storage pool named ‘default’, but it can’t find it. This typically occurs when the default storage pool has either been deleted, is not defined, or has not been started.
You can check if the default storage exists with the following command:
virsh pool-list --allIf the default storage pool does not exist, you can define with the following command:
virsh pool-define-as default dir --target /var/lib/libvirt/imagesCleaning up
We can destroy the vagrant environment and remove the ISO image by running the following commands:
vagrant destroy -fsudo rm -f /tmp/metal-amd64.isoKubernetes Anywhere: The future of Kubernetes?
In this article, we’ve explored what Kubernetes on-premises is, the reasons why organizations might choose to deploy it in their own infrastructure, and the key considerations involved in such a deployment.
Finally, we’ve provided a guide on how to get started with Kubernetes on-premises in a provider-agnostic manner, helping you take the first steps toward a successful on-prem deployment.
Kubernetes has evolved significantly over the years, and its growth shows no signs of slowing down, driven by one key factor: its vibrant and ever-expanding community. Today we see Kubernetes used in many industries across the world, tomorrow, we might see Kubernetes more in our homes as smart IoT technologies grow.
At Severalnines, we’ve been contributing to the database on Kubernetes community over the years, building CCX Cloud and CCX for CSPs, Kubernetes-based DBaaS implementations for end-users and Cloud Service Providers, respectively.
In our next post, we will dive into the world of Container Storage Interfaces (CSIs) and walk you through how they help make Kubernetes run stateful applications at scale. In the meantime, don’t forget to follow us on LinkedIn and X or sign up for our newsletter to stay informed of the latest in the database world.



