blog
How to Recover Galera Cluster or MySQL Replication From Split Brain Syndrome

You may have heard about the term “split brain”. What it is? How does it affect your clusters? In this blog post we will discuss what exactly it is, what danger it may pose to your database, how we can prevent it, and if everything goes wrong, how to recover from it.
Long gone are the days of single instances, nowadays almost all databases run in replication groups or clusters. This is great for high availability and scalability, but a distributed database introduces new dangers and limitations. One case which can be deadly is a network split. Imagine a cluster of multiple nodes which, due to network issues, was split in two parts. For obvious reasons (data consistency), both parts shouldn’t handle traffic at the same time as they are isolated from each other and data cannot be transferred between them. It is also wrong from the application point of view – even if, eventually, there would be a way to sync the data (although reconciliation of 2 datasets is not trivial). For a while, part of the application would be unaware of the changes made by other application hosts, which accesses the other part of the database cluster. This can lead to serious problems.
The condition in which the cluster has been divided in two or more parts that are willing to accept writes is called “split brain”.
The biggest problem with split brain is data drift, as writes happen on both parts of the cluster. None of MySQL flavors provide automated means of merging datasets that have diverged. You will not find such feature in MySQL replication, Group Replication or Galera. Once the data has diverged, the only option is to either use one of the parts of the cluster as the source of truth and discard changes executed on the other part – unless we can follow some manual process in order to merge the data.
This is why we will start with how to prevent split brain from happening. This is so much easier than having to fix any data discrepancy.
How to Prevent Split Brain
The exact solution depends on the type of the database and the setup of the environment. We will take a look at some of the most common cases for Galera Cluster and MySQL Replication.
Galera Cluster
Galera has a built-in “circuit breaker” to handle split brain: it rely on a quorum mechanism. If a majority (50% + 1) of the nodes are available in the cluster, Galera will operate normally. If there is no majority, Galera will stop serving traffic and switch to so called “non-Primary” state. This is pretty much all you need to deal with a split brain situation while using Galera. Sure, there are manual methods to force Galera into “Primary” state even if there’s not a majority. Thing is, unless you do that, you should be safe.
The way how quorum is calculated has important repercussions – at a single datacenter level, you want to have an odd number of nodes. Three nodes give you a tolerance for failure of one node (2 nodes match the requirement of more than 50% of the nodes in the cluster being available). Five nodes will give you a tolerance for failure of two nodes (5 – 2 = 3 which is more than 50% from 5 nodes). On the other hand, using four nodes will not improve your tolerance over three node cluster. It would still handle only a failure of one node (4 – 1 = 3, more than 50% from 4) while failure of two nodes will render the cluster unusable (4 – 2 = 2, just 50%, not more).
While deploying Galera cluster in a single datacenter, please keep in mind that, ideally, you would like to distribute nodes across multiple availability zones (separate power source, network, etc.) – as long as they do exist in your datacenter, that is. A simple setup may look like below:
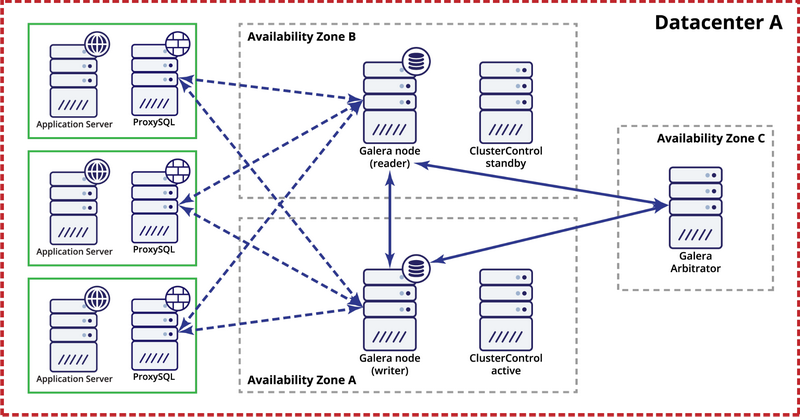
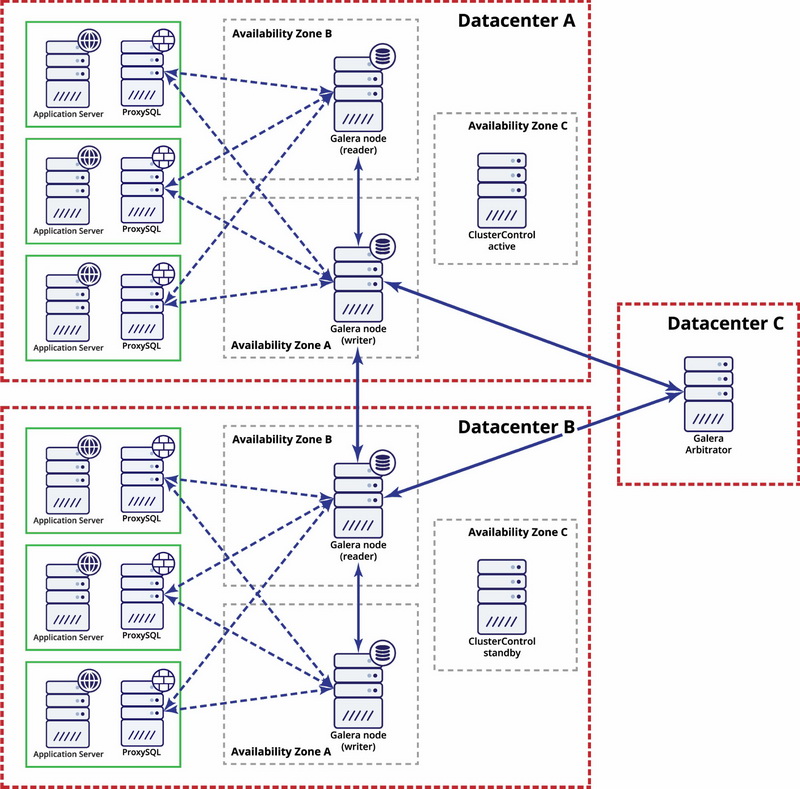
At the multi-datacenter level, those considerations are also applicable. If you want Galera cluster to automatically handle datacenter failures, you should use an odd number of datacenters. To reduce costs, you can use a Galera arbitrator in one of them instead of a database node. Galera arbitrator (garbd) is a process which takes part in the quorum calculation but it does not contain any data. This makes it possible to use it even on very small instances as it is not resource-intensive – although the network connectivity has to be good as it ‘sees’ all the replication traffic. Example setup may look like on a diagram below:
MySQL Replication
With MySQL replication the biggest issue is that there is no quorum mechanism builtin, as it is in Galera cluster. Therefore more steps are required to ensure that your setup will not be affected by a split brain.
One method is to avoid cross-datacenter automated failovers. You can configure your failover solution (it can be through ClusterControl, or MHA or Orchestrator) to failover only within single datacenter. If there was a full datacenter outage, it would be up to the admin to decide how to failover and how to ensure that the servers in the failed datacenter will not be used.
There are options to make it more automated. You can use Consul to store data about the nodes in the replication setup, and which one of them is the master. Then it will be up to the admin (or via some scripting) to update this entry and move writes to the second datacenter. You can benefit from an Orchestrator/Raft setup where Orchestrator nodes can be distributed across multiple datacenters and detect split brain. Based on this you could take different actions like, as we mentioned previously, update entries in our Consul or etcd. The point is that this is a much more complex environment to setup and automate than Galera cluster. Below you can find example of multi-datacenter setup for MySQL replication.
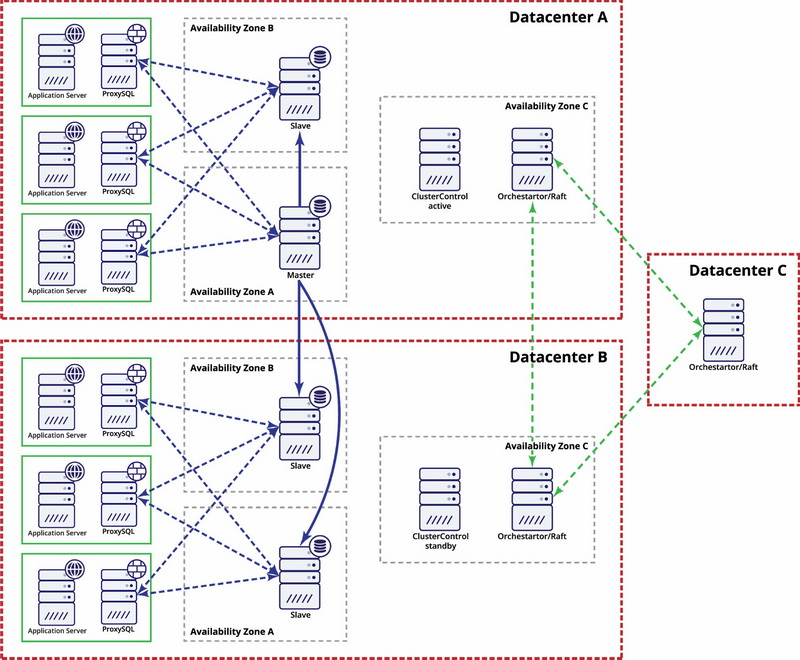
Please keep in mind that you still have to create scripts to make it work, i.e. monitor Orchestrator nodes for a split brain and take necessary actions to implement STONITH and ensure that the master in datacenter A will not be used once the network converge and connectivity will be restored.
Split Brain Happened – What to do Next?
The worst case scenario happened and we have data drift. We will try to give you some hints what can be done here. Unfortunately, the exact steps will depend mostly on your schema design so it will not be possible to write a precise how-to guide.
What you have to keep in mind is that the ultimate goal will be to copy data from one master to the other and recreate all relations between tables.
First of all, you have to identify which node will continue serving data as master. This is a dataset to which you will merge data stored on the other “master” instance. Once that’s done, you have to identify data from old master which is missing on the current master. This will be manual work. If you have timestamps in your tables, you can leverage them to pinpoint the missing data. Ultimately, binary logs will contain all data modifications so you can rely on them. You may also have to rely on your knowledge of the data structure and relations between tables. If your data is normalized, one record in one table could be related to records in other tables. For example, your application may insert data to “user” table which is related to “address” table using user_id. You will have to find all related rows and extract them.
Next step will be to load this data into the new master. Here comes the tricky part – if you prepared your setups beforehand, this could be simply a matter of running a couple of inserts. If not, this may be rather complex. It’s all about primary key and unique index values. If your primary key values are generated as unique on each server using some sort of UUID generator or using auto_increment_increment and auto_increment_offset settings in MySQL, you can be sure that the data from the old master you have to insert won’t cause primary key or unique key conflicts with data on the new master. Otherwise, you may have to manually modify data from the old master to ensure it can be inserted correctly. It sounds complex, so let’s take a look at an example.
Let’s imagine we insert rows using auto_increment on node A, which is a master. For the sake of simplicity, we will focus on a single row only. There are columns ‘id’ and ‘value’.
If we insert it without any particular setup, we’ll see entries like below:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’Those will replicate to the slave (B). If the split brain happens and writes will be executed on both old and new master, we will end up with following situation:
A
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’B
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’As you can see, there’s no way to simply dump records with id of 1004, 1005 and 1006 from node A and store them on node B because we will end up with duplicated primary key entries. What needs to be done is to change values of id column in the rows that will be inserted to a value larger than the maximum value of the id column from the table. This is all what’s needed for single rows. For more complex relations, where multiple tables are involved, you may have to make the changes in multiple locations.
On the other hand, if we had anticipated this potential problem and configured our nodes to store odd id’s on node A and even id’s on node B, the problem would have been so much easier to solve.
Node A was configured with auto_increment_offset = 1 and auto_increment_increment = 2
Node B was configured with auto_increment_offset = 2 and auto_increment_increment = 2
This is how the data would look on node A before the split brain:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’When split brain happened, it will look like below.
Node A:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Node B:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’Now we can easily copy missing data from node A:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’And load it to node B ending up with following data set:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’Sure, rows are not in the original order, but this should be ok. In the worst case scenario you will have to order by ‘value’ column in queries and maybe add an index on it to make the sorting fast.
Now, imagine hundreds or thousands of rows and a highly normalized table structure – to restore one row may mean you will have to restore several of them in additional tables. With a need to change id’s (because you didn’t have protective settings in place) across all related rows and all of this being manual work, you can imagine that this is not the best situation to be in. It takes time to recover and it is an error-prone process. Luckily, as we discussed at the beginning, there are means to minimize chances that split brain will impact your system or to reduce the work that needs to be done to sync back your nodes. Make sure you use them and stay prepared.



