blog
How to Perform Schema Changes in MySQL & MariaDB in a Safe Way

Before you attempt to perform any schema changes on your production databases, you should make sure that you have a rock solid rollback plan; and that your change procedure has been successfully tested and validated in a separate environment. At the same time, it’s your responsibility to make sure that the change causes none or the least possible impact acceptable to the business. It’s definitely not an easy task.
In this article, we will take a look at how to perform database changes on MySQL and MariaDB in a controlled way. We will talk about some good habits in your day-to-day DBA work. We’ll focus on pre-requirements and tasks during the actual operations and problems that you may face when you deal with database schema changes. We will also talk about open source tools that may help you in the process.
Test and Rollback Scenarios
Backup
There are many ways to lose your data. Schema upgrade failure is one of them. Unlike application code, you can’t drop a bundle of files and declare that a new version has been successfully deployed. You also can’t just put back an older set of files to rollback your changes. Of course, you can run another SQL script to change the database again, but there are cases when the only accurate way to roll back changes is by restoring the entire database from backup.
However, what if you can’t afford to rollback your database to the latest backup, or your maintenance window is not big enough (considering system performance), so you can’t perform a full database backup before the change?
One may have a sophisticated, redundant environment, but as long as data is modified in both primary and standby locations, there is not much to do about it. Many scripts can just be run once, or the changes are impossible to undo. Most of the SQL change code falls into two groups:
- Run once – you can’t add the same column to the table twice.
- Impossible to undo – once you’ve dropped that column, it’s gone. You could undoubtedly restore your database, but that’s not precisely an undo.
You can tackle this problem in at least two possible ways. One would be to enable the binary log and take a backup, which is compatible with PITR. Such backup has to be full, complete and consistent. For xtrabackup, as long as it contains a full dataset, it will be PITR-compatible. For mysqldump, there is an option to make it PITR-compatible too. For smaller changes, a variation of mysqldump backup would be to take only a subset of data to change. This can be done with –where option. The backup should be part of the planned maintenance.
mysqldump -u -p --lock-all-tables --where="WHERE employee_id=100" mydb employees> backup_table_tmp_change_07132018.sqlAnother possibility is to use CREATE TABLE AS SELECT.
You can store data or simple structure changes in the form of a fixed temporary table. With this approach you will get a source if you need to rollback your changes. It may be quite handy if you don’t change much data. The rollback can be done by taking data out from it. If any failures occur while copying the data to the table, it is automatically dropped and not created, so make sure that your statement creates a copy you need.
Obviously, there are some limitations too.
Because the ordering of the rows in the underlying SELECT statements cannot always be determined, CREATE TABLE … IGNORE SELECT and CREATE TABLE … REPLACE SELECT are flagged as unsafe for statement-based replication. Such statements produce a warning in the error log when using statement-based mode and are written to the binary log using the row-based format when using MIXED mode.
A very simple example of such method could be:
CREATE TABLE tmp_employees_change_07132018 AS SELECT * FROM employees where employee_id=100;
UPDATE employees SET salary=120000 WHERE employee_id=100;
COMMMIT;Another interesting option may be MariaDB flashback database. When a wrong update or delete happens, and you would like to revert to a state of the database (or just a table) at a certain point in time, you may use the flashback feature.
Point-in-time rollback enables DBAs to recover data faster by rolling back transactions to a previous point in time rather than performing a restore from a backup. Based on ROW-based DML events, flashback can transform the binary log and reverse purposes. That means it can help undo given row changes fast. For instance, it can change DELETE events to INSERTs and vice versa, and it will swap WHERE and SET parts of the UPDATE events. This simple idea can dramatically speed up recovery from certain types of mistakes or disasters. For those who are familiar with the Oracle database, it’s a well known feature. The limitation of MariaDB flashback is the lack of DDL support.
Create a Delayed Replication Slave
Since version 5.6, MySQL supports delayed replication. A slave server can lag behind the master by at least a specified amount of time. The default delay is 0 seconds. Use the MASTER_DELAY option for CHANGE MASTER TO to set the delay to N seconds:
CHANGE MASTER TO MASTER_DELAY = N;It would be a good option if you didn’t have time to prepare a proper recovery scenario. You need to have enough delay to notice the problematic change. The advantage of this approach is that you don’t need to restore your database to take out data needed to fix your change. Standby DB is up and running, ready to pick up data which minimizes the time needed.
Create an Asynchronous Slave Which is not Part of the Cluster
When it comes to Galera cluster, testing changes is not easy. All nodes run the same data, and heavy load can harm flow control. So you not only need to check if changes applied successfully, but also what the impact to the cluster state was. To make your test procedure as close as possible to the production workload, you may want to add an asynchronous slave to your cluster and run your test there. The test will not impact synchronization between cluster nodes, because technically it’s not part of the cluster, but you will have an option to check it with real data. Such slave can be easily added from ClusterControl.
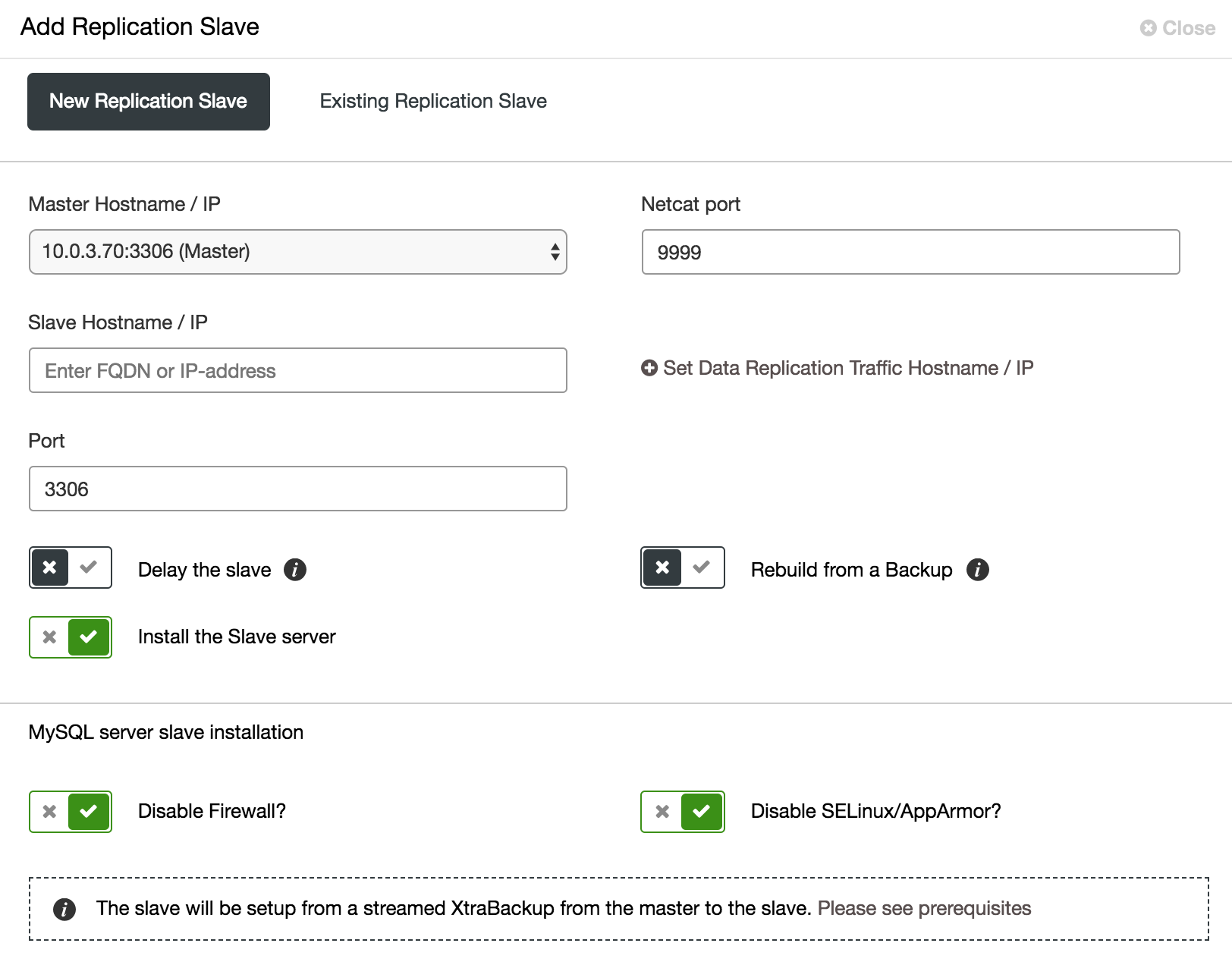
As shown in the above screenshot, ClusterControl can automate the process of adding an asynchronous slave in a few ways. You can add the node to the cluster, delay the slave. To reduce the impact on the master, you can use an existing backup instead of the master as the data source when building the slave.
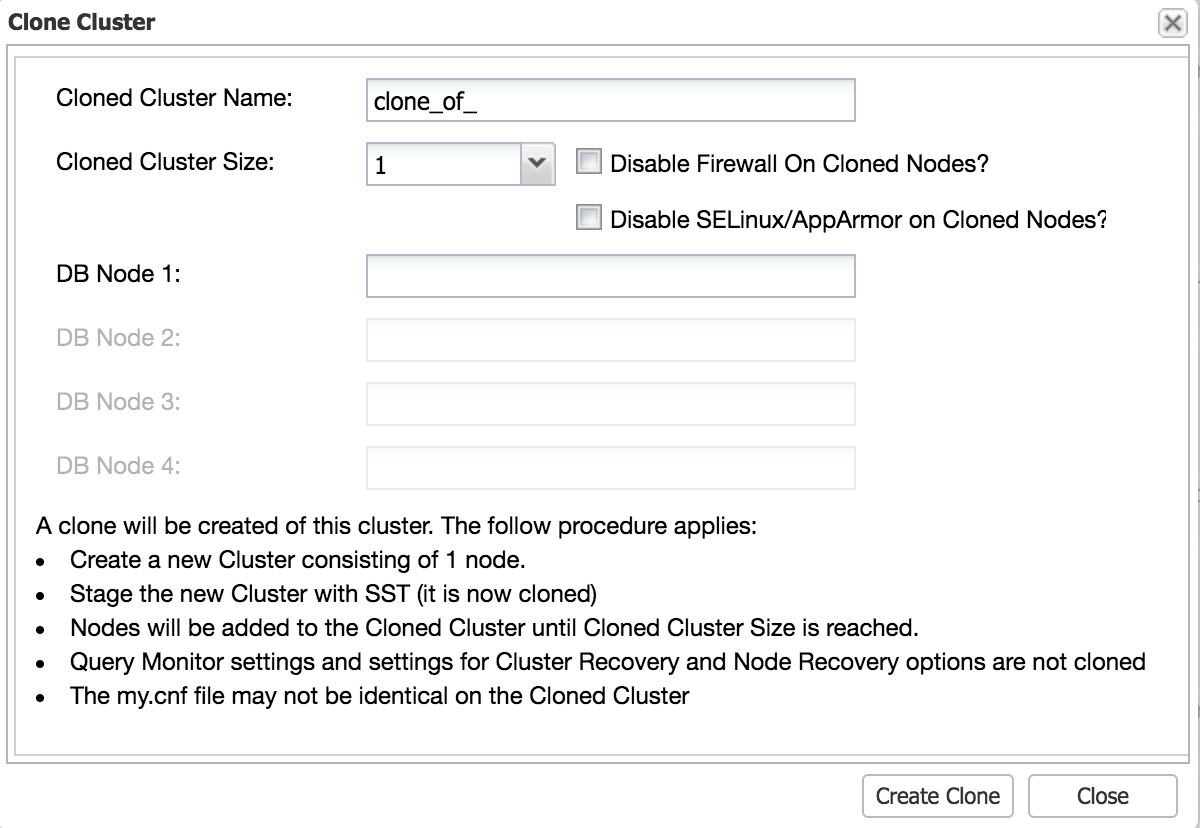
Clone Database and Measure Time
A good test should be as close as possible to the production change. The best way to do this is to clone your existing environment.
Perform Changes via Replication
To have better control over your changes, you can apply them on a slave server ahead of time and then do the switchover. For statement-based replication, this works fine, but for row-based replication, this can work up to a certain degree. Row-based replication enables extra columns to exist at the end of the table, so as long as it can write the first columns, it will be fine. First apply these setting to all slaves, then failover to one of the slaves and then implement the change to the master and attach that as a slave. If your modification involves inserting or removing a column in the middle of the table, it will work with row-based replication.
Operation
During the maintenance window, we do not want to have application traffic on the database. Sometimes it is hard to shut down all applications spread over the whole company. Alternatively, we want to allow only some specific hosts to access MySQL from remote (for example the monitoring system or the backup server). For this purpose, we can use the Linux packet filtering. To see what packet filtering rules are available, we can run the following command:
iptables -L INPUT -vTo close the MySQL port on all interfaces we use:
iptables -A INPUT -p tcp --dport mysql -j DROPand to open the MySQL port again after the maintenance window:
iptables -D INPUT -p tcp --dport mysql -j DROPFor those without root access, you can change max_connection to 1 or ‘skip networking’.
Logging
To get the logging process started, use the tee command at the MySQL client prompt, like this:
mysql> tee /tmp/my.out;That command tells MySQL to log both the input and output of your current MySQL login session to a file named /tmp/my.out .Then execute your script file with source command.
To get a better idea of your execution times, you can combine it with the profiler feature. Start the profiler with
SET profiling = 1;Then execute your Query with
SHOW PROFILES;you see a list of queries the profiler has statistics for. So finally, you choose which query to examine with
SHOW PROFILE FOR QUERY 1;Schema Migration Tools
Many times, a straight ALTER on the master is not possible – most of the cases it causes lag on the slave, and this may not be acceptable to the applications. What can be done, though, is to execute the change in a rolling mode. You can start with slaves and, once the change is applied to the slave, migrate one of the slaves as a new master, demote the old master to a slave and execute the change on it.
A tool that may help with such a task is Percona’s pt-online-schema-change. Pt-online-schema-change is straightforward – it creates a temporary table with the desired new schema (for instance, if we added an index, or removed a column from a table). Then, it creates triggers on the old table. Those triggers are there to mirror changes that happen on the original table to the new table. Changes are mirrored during the schema change process. If a row is added to the original table, it is also added to the new one. It emulates the way that MySQL alters tables internally, but it works on a copy of the table you wish to alter. It means that the original table is not locked, and clients may continue to read and change data in it.
Likewise, if a row is modified or deleted on the old table, it is also applied in the new table. Then, a background process of copying data (using LOW_PRIORITY INSERT) between old and new table begins. Once data has been copied, RENAME TABLE is executed.
Another intresting tool is gh-ost. Gh-ost creates a temporary table with the altered schema, just like pt-online-schema-change does. It executes INSERT queries, which use the following pattern to copy data from old to new table. Nevertheless it does not use triggers. Unfortunately triggers may be the source of many limitations. gh-ost uses the binary log stream to capture table changes and asynchronously applies them onto the ghost table. Once we verified that gh-ost can execute our schema change correctly, it’s time to actually execute it. Keep in mind that you may need to manually drop old tables that were created by gh-ost during the process of testing the migration. You can also use –initially-drop-ghost-table and –initially-drop-old-table flags to ask gh-ost to do it for you. The final command to execute is exactly the same as we used to test our change, we just added –execute to it.
pt-online-schema-change and gh-ost are very popular among Galera users. Nevertheless Galera has some additional options.The two methods Total Order Isolation (TOI) and Rolling Schema Upgrade (RSU) have both their pros and cons.
TOI – This is the default DDL replication method. The node that originates the writeset detects DDL at parsing time and sends out a replication event for the SQL statement before even starting the DDL processing. Schema upgrades run on all cluster nodes in the same total order sequence, preventing other transactions from committing for the duration of the operation. This method is good when you want your online schema upgrades to replicate through the cluster and don’t mind locking the entire table (similar to how default schema changes happened in MySQL).
SET GLOBAL wsrep_OSU_method='TOI';RSU – perfom the schema upgrades locally. In this method, your writes are affecting only the node on which they are run. The changes do not replicate to the rest of the cluster.This method is good for non-conflicting operations and it will not slow down the cluster.
SET GLOBAL wsrep_OSU_method='RSU';While the node processes the schema upgrade, it desynchronizes with the cluster. When it finishes processing the schema upgrade, it applies delayed replication events and synchronizes itself with the cluster. This could be a good option to run heavy index creations.
Conclusion
We presented here several different methods that may help you with planning your schema changes. Of course it all depends on your application and business requirements. You can design your change plan, perform necessary tests, but there is still a small chance that something will go wrong. According to Murphy’s law – “things will go wrong in any given situation, if you give them a chance”. So make sure you try out different ways of performing these changes, and pick the one that you are the most comfortable with.



