blog
How MongoDB Enables Machine Learning

MongoDB is a NoSQL database that supports a wide variety of input dataset sources. It is able to store data in flexible JSON-like documents, meaning fields or metadata can vary from document to document and data structure can be changed over time. The document model makes the data easy to work with by mapping to the objects in the application code. MongoDB is also known as a distributed database at its core, so high availability, horizontal scaling, and geographic distribution are built-in and easy to use. It comes with the ability to seamlessly modify parameters for model training. Data Scientists can easily merge the structuring of data with this model generation.
What is Machine Learning?
Machine Learning is the science of getting the computers to learn and act like humans do and improve their learning over time in autonomous fashion. The process of learning begins with observations or data, such as examples, direct experience, or instruction, in order to look for patterns in data and make better decisions in the future based on the examples that we provide. The primary aim is to allow the computers to learn automatically without human intervention or assistance and adjust actions accordingly.
A Rich Programming and Query Model
MongoDB offers both native drivers and certified connectors for developers and data scientists building machine learning models with data from MongoDB. PyMongo is a great library to embed MongoDB syntax into Python code. We can import all the functions and methods of MongoDB to use them in our machine learning code. It is a great technique to get multi-language functionality in a single code. The additional advantage is that you can use the essential features of those programming languages to create an efficient application.
The MongoDB query language with rich secondary indexes enables developers to build applications that can query and analyze the data in multiple dimensions. Data can be accessed by single keys, ranges, text search, graph, and geospatial queries through complex aggregations and MapReduce jobs, returning responses in milliseconds.
To parallelize data processing across a distributed database cluster, MongoDB provides the aggregation pipeline and MapReduce. The MongoDB aggregation pipeline is modelled along the concept of data processing pipelines. Documents enter a multi-stage pipeline that transforms the documents into an aggregated result using native operations executed within MongoDB. The most basic pipeline stages provide filters that operate like queries, and document transformations that modify the form of the output document. Other pipeline operations provide tools for grouping and sorting documents by specific fields as well as tools for aggregating the contents of arrays, including arrays of documents. In addition, pipseline stages can use operators for tasks such as calculating the average or standard deviations across collections of documents, and manipulating strings. MongoDB also provides native MapReduce operations within the database, using custom JavaScript functions to perform the map and reduce stages.
In addition to its native query framework, MongoDB also offers a high performance connector for Apache Spark. The connector exposes all of Spark’s libraries, including Python, R, Scala, and Java. MongoDB data is materialized as DataFrames and Datasets for analysis with machine learning, graph, streaming, and SQL APIs.
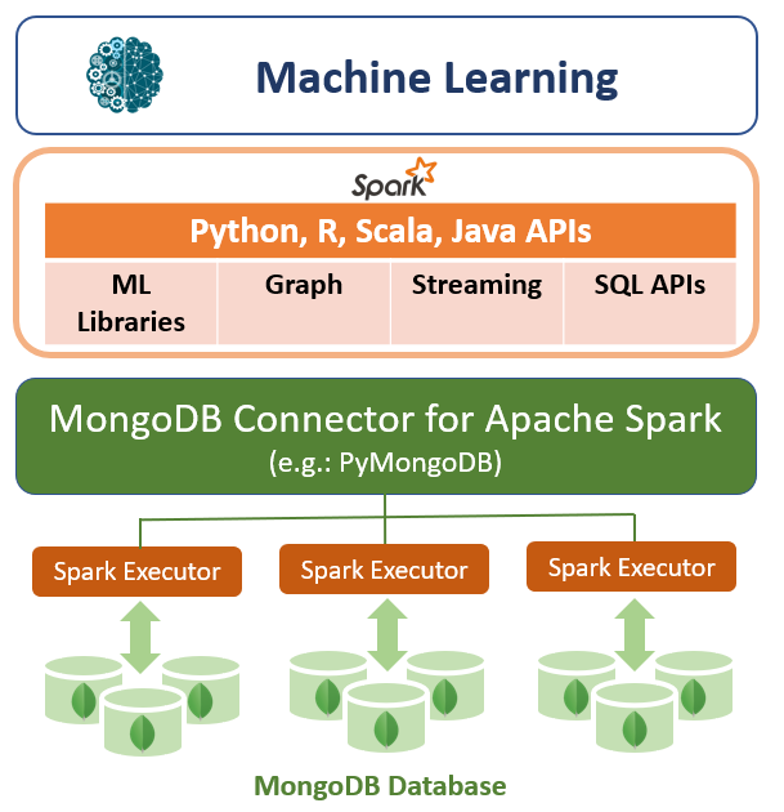
The MongoDB Connector for Apache Spark can take advantage of MongoDB’s aggregation pipeline and secondary indexes to extract, filter, and process only the range of data it needs – for example, analysing all customers located in a specific geography. This is very different from simple NoSQL datastores that do not support either secondary indexes or in-database aggregations. In these cases, Spark would need to extract all data based on a simple primary key, even if only a subset of that data is required for the Spark process. This means more processing overhead, more hardware, and longer time-to-insight for data scientists and engineers. To maximize performance across large, distributed data sets, the MongoDB Connector for Apache Spark can co-locate Resilient Distributed Datasets (RDDs) with the source MongoDB node, thereby minimizing data movement across the cluster and reducing latency.
Performance, Scalability & Redundancy
Model training time can be reduced by building the machine learning platform on top of a performant and scalable database layer. MongoDB offers a number of innovations to maximize throughput and minimize latency of machine learning workloads:
- WiredTiger is known as the default storage engine for MongoDB, developed by the architects of Berkeley DB, the most widely deployed embedded data management software in the world. WiredTiger scales on modern, multi-core architectures. Using a variety of programming techniques such as hazard pointers, lock-free algorithms, fast latching and message passing, WiredTiger maximizes computational work per CPU core and clock cycle. To minimize on-disk overhead and I/O, WiredTiger uses compact file formats and storage compression.
- For the most latency-sensitive machine learning applications, MongoDB can be configured with the In-Memory storage engine. Based on WiredTiger, this storage engine gives users the benefits of in-memory computing, without trading away the rich query flexibility, real-time analytics, and scalable capacity offered by conventional disk-based databases.
- To parallelize model training and scale input datasets beyond a single node, MongoDB uses a technique called sharding, which distributes processing and data across clusters of commodity hardware. MongoDB sharding is fully elastic, automatically rebalancing data across the cluster as the input dataset grows, or as nodes are added and removed.
- Within a MongoDB cluster, data from each shard is automatically distributed to multiple replicas hosted on separate nodes. MongoDB replica sets provide redundancy to recover training data in the event of a failure, reducing the overhead of checkpointing.
MongoDB’s Tunable Consistency
MongoDB is strongly consistent by default, enabling machine learning applications to immediately read what has been written to the database, thus avoiding the developer complexity imposed by eventually consistent systems. Strong consistency will provide the most accurate results for machine learning algorithms; however, in some scenarios it is acceptable to trade consistency against specific performance goals by distributing queries across a cluster of MongoDB secondary replica set members.
Flexible Data Model in MongoDB
MongoDB‘s document data model makes it easy for developers and data scientists to store and aggregate data of any form of structure inside the database, without giving up sophisticated validation rules to govern data quality. The schema can be dynamically modified without an application or database downtime that results from costly schema modifications or redesign incurred by relational database systems.
Saving models in a database and loading them, using python, is also an easy and much-required method. Choosing MongoDB is also an advantage as it is an open-source document database and also a leading NoSQL database. MongoDB also serves as a connector for apache spark distributed framework.
MongoDB’s Dynamic Nature
MongoDB’s dynamic nature enables its usage in database manipulation tasks in developing Machine Learning applications. It is a very efficient and easy way to carry out an analysis of datasets and databases. The output of the analysis can be used in training machine learning models. It has been recommended that data analysts and Machine Learning programmers gain mastery in MongoDB and apply it in many different applications. MongoDB’s Aggregation framework is used for data science workflow for performing data analysis for numerous applications.
Conclusion
MongoDB offers several different capabilities such as: flexible data model, rich programming, data model, query model and its tunable consistency that make training and using machine learning algorithms much easier than with traditional, relational databases. Running MongoDB as the backend database will enable storing and enriching machine learning data allows for persistence and increased efficiency.



