blog
How to Improve Replication Performance in a MySQL or MariaDB Galera Cluster
In the comments section of one of our blogs a reader asked about the impact of wsrep_slave_threads on Galera Cluster’s I/O performance and scalability. At that time, we couldn’t easily answer that question and back it up with more data, but finally we managed to set up the environment and run some tests.
Our reader pointed towards benchmarks that showed that increasing wsrep_slave_threads did not have any impact on the performance of the Galera cluster.
To explain what the impact of that setting is, we set up a small cluster of three nodes (m5d.xlarge). This allowed us to utilize directly attached nvme SSD for the MySQL data directory. By doing this, we minimized the chance of storage becoming the bottleneck in our setup.
We set up InnoDB buffer pool to 8GB and redo logs to two files, 1GB each. We also increased innodb_io_capacity to 2000 and innodb_io_capacity_max to 10000. This was also intended to ensure that neither of those settings would impact our performance.
The whole problem with such benchmarks is that there are so many bottlenecks that you have to eliminate them one by one. Only after doing some configuration tuning and after making sure that the hardware will not be a problem, one can have hope that some more subtle limits will show up.
We generated ~90GB of data using sysbench:
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large prepareThen the benchmark was executed. We tested two settings: wsrep_slave_threads=1 and wsrep_slave_threads=16. The hardware was not powerful enough to benefit from increasing this variable even further. Please also keep in mind that we did not do a detailed benchmarking in order to determine whether wsrep_slave_threads should be set to 16, 8 or maybe 4 for the best performance. We were interested to see if we can show an impact on the cluster. And yes, the impact was clearly visible. For starters, some flow control graphs.
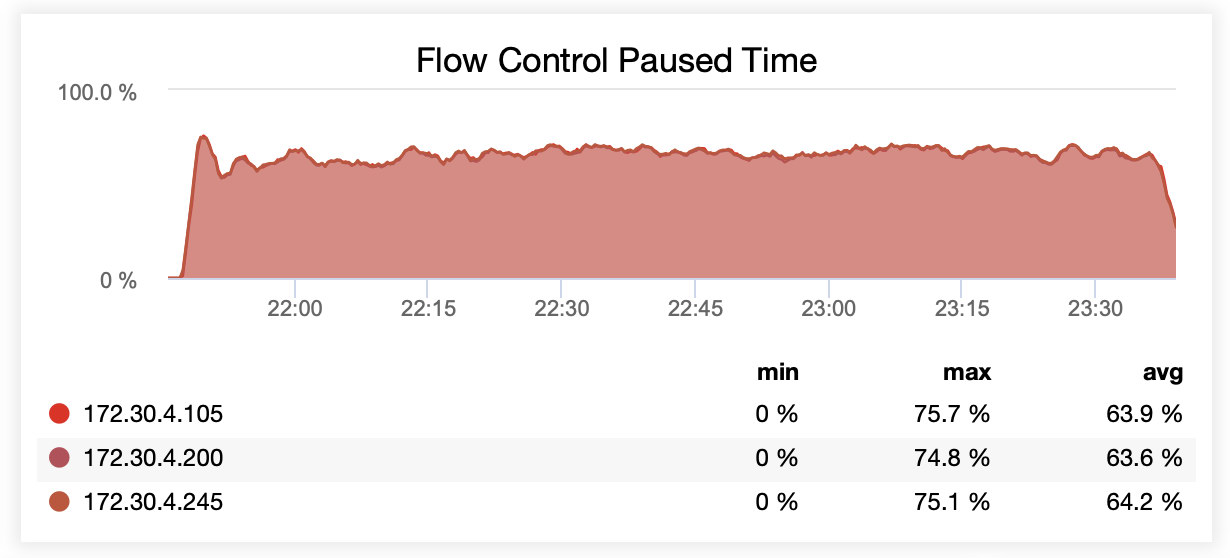
While running with wsrep_slave_threads=1, on average, nodes were paused due to flow control ~64% of the time.
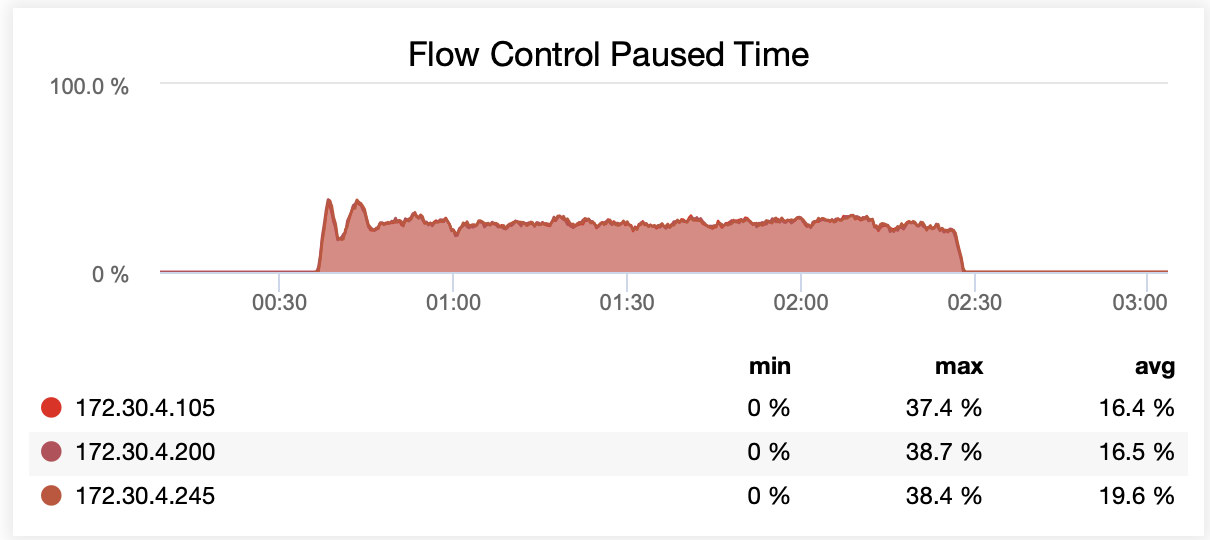
While running with wsrep_slave_threads=16, on average, nodes were paused due to flow control ~20% of the time.
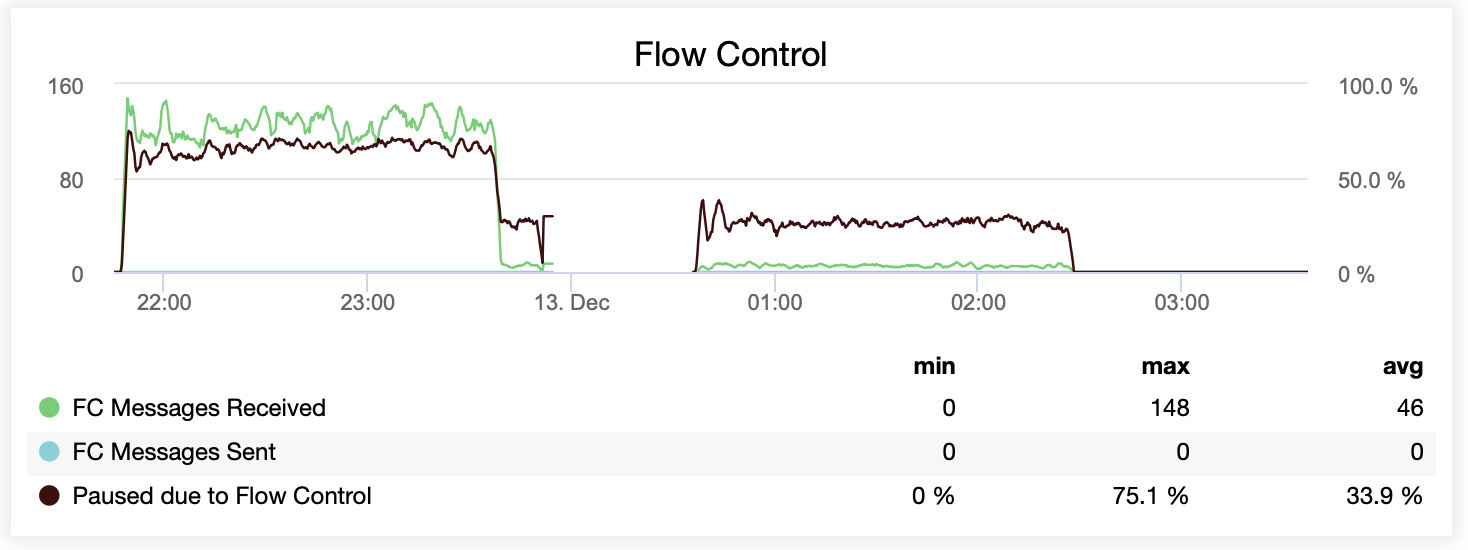
You can also compare the difference on a single graph. The drop at the end of the first part is the first attempt to run with wsrep_slave_threads=16. Servers ran out of disk space for binary logs and we had to re-run that benchmark once more at a later time.
How did this translate in performance terms? The difference is visible although definitely not that spectacular.
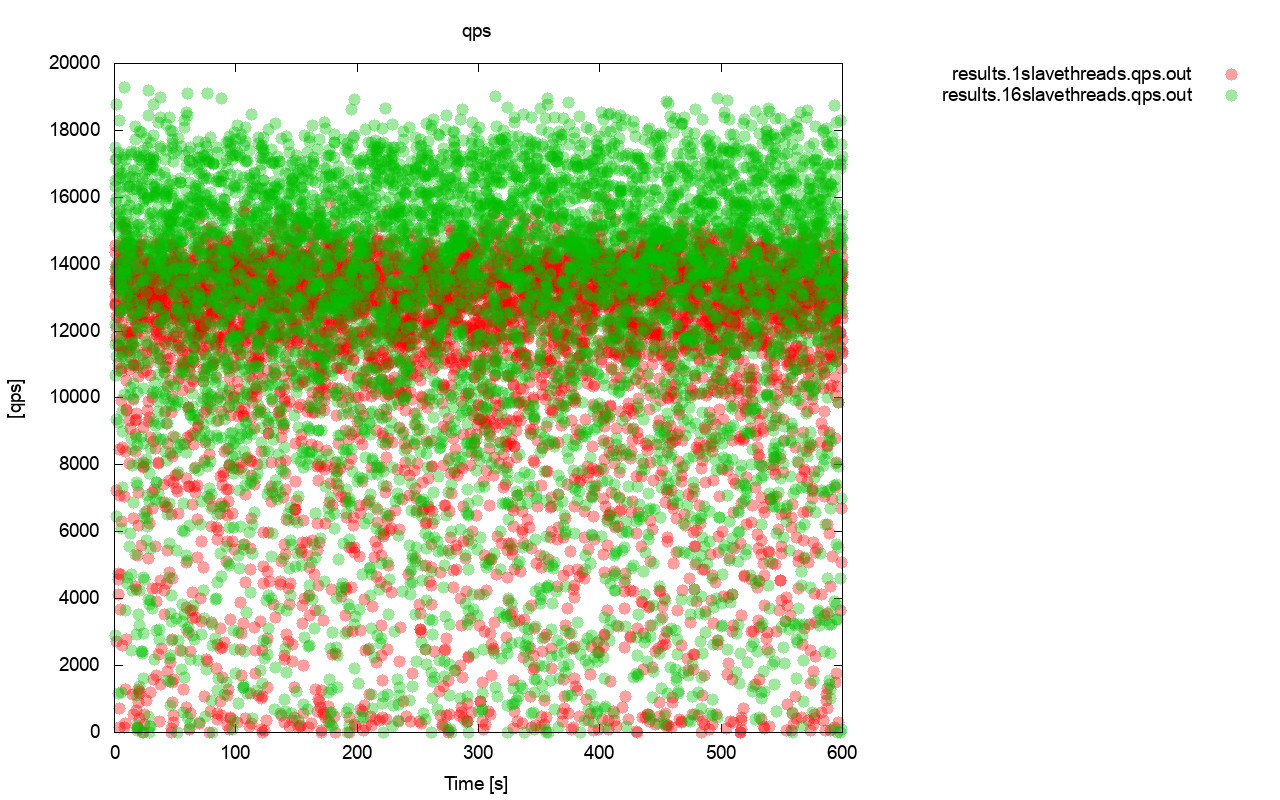
First, the query per second graph. First of all, you can notice that in both cases results are all over the place. This is mostly related to the unstable performance of the I/O storage and the flow control randomly kicking in. You can still see that the performance of the “red” result (wsrep_slave_threads=1) is quite lower than the “green” one (wsrep_slave_threads=16).
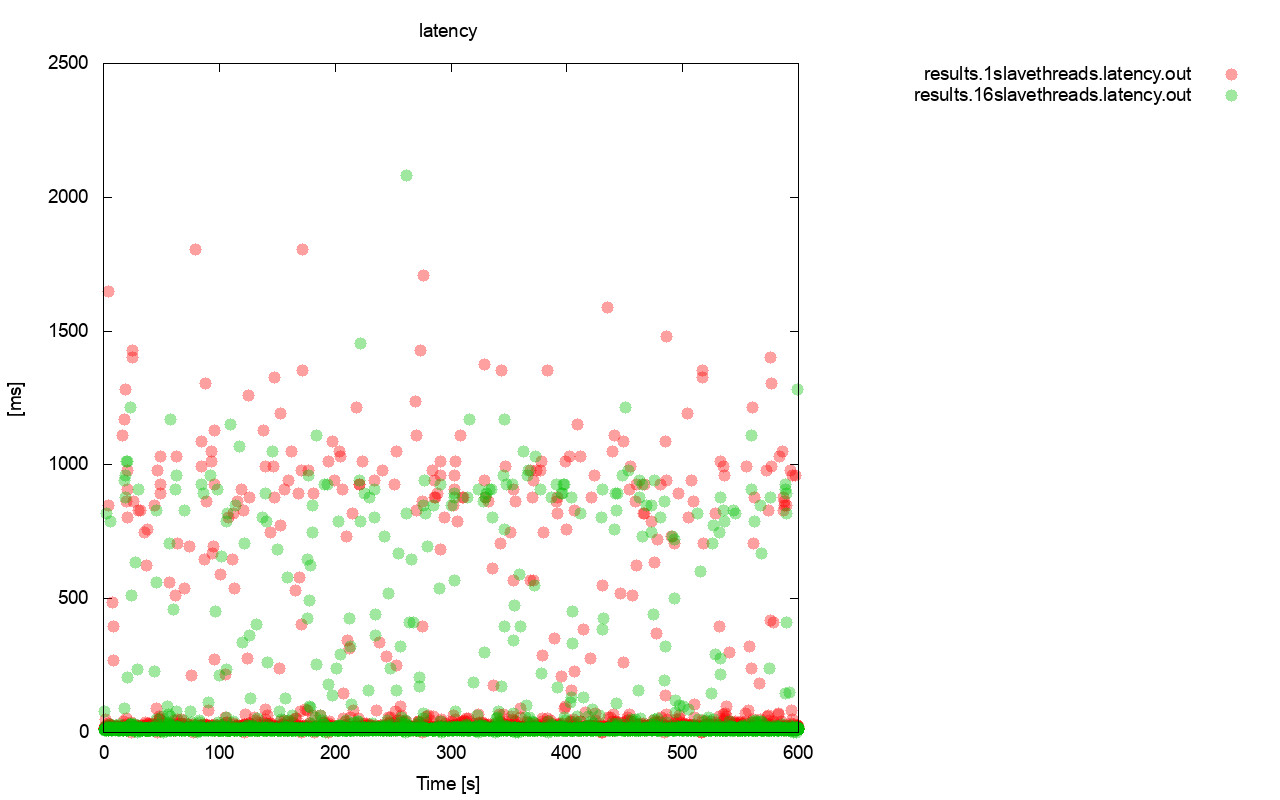
Quite similar picture is when we look at the latency. You can see more (and typically deeper) stalls for the run with wsrep_slave_thread=1.
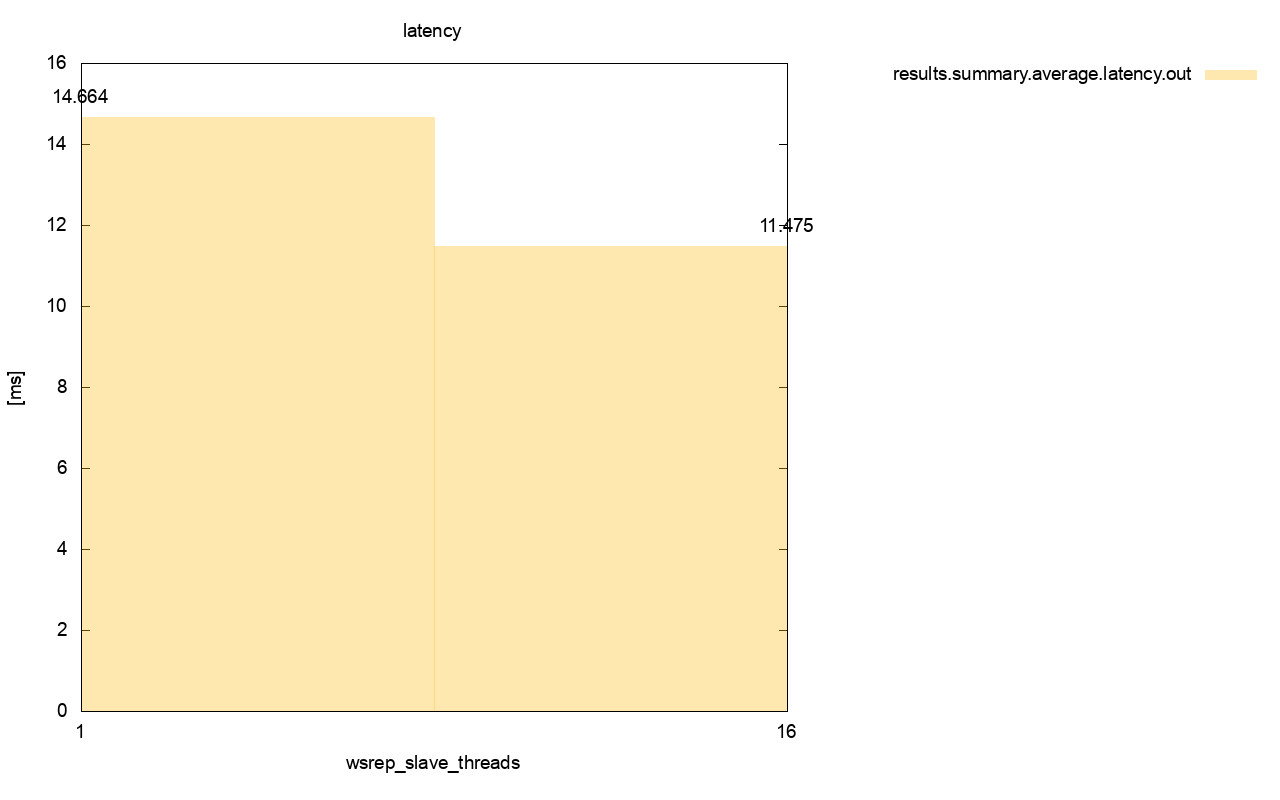
The difference is even more visible when we calculated average latency across all the runs and you can see that the latency of wsrep_slave_thread=1 is 27% higher of the latency with 16 slave threads, which obviously is not good as we want latency to be lower, not higher.
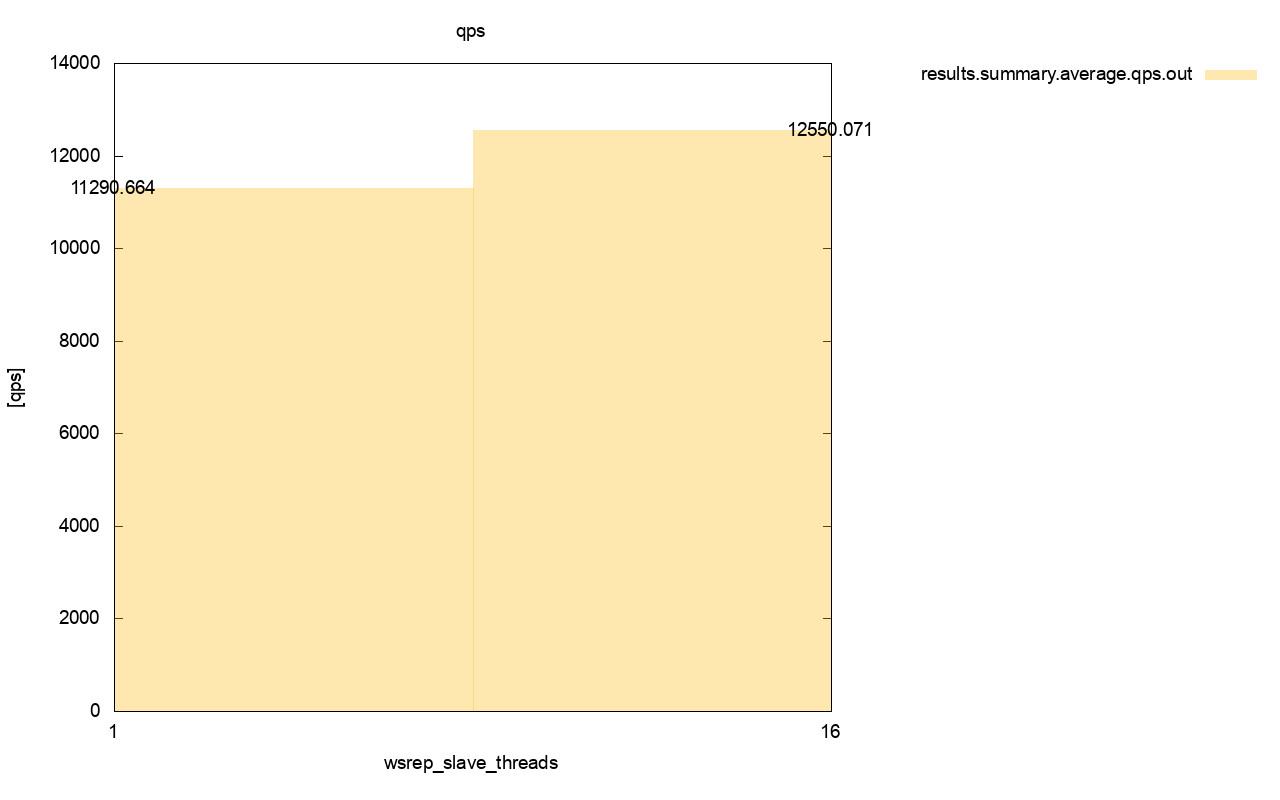
The difference in throughput is also visible, around 11% of the improvement when we added more wsrep_slave_threads.
As you can see, the impact is there. It is by no means 16x (even if that’s how we increased the number of slave threads in Galera) but it is definitely prominent enough so that we cannot classify it as just a statistical anomaly.
Please keep in mind that in our case we used quite small nodes. The difference should be even more significant if we are talking about large instances running on EBS volumes with thousands of provisioned IOPS.
Then we would be able to run sysbench even more aggressively, with higher number of concurrent operations. This should improve parallelization of the writesets, improving the gain from the multithreading even further. Also, faster hardware means that Galera will be able to utilize those 16 threads in more efficient way.
When running tests like this you have to keep in mind you need to push your setup almost to its limits. Single-threaded replication can handle quite a lot of load and you need to run heavy traffic to actually make it not performant enough to handle the task.
We hope this blog post gives you more insight into Galera Cluster’s abilities to apply writesets in parallel and the limiting factors around it.



