blog
How Galera Cluster Enables High Availability for High Traffic Websites

In today’s competitive technology environment, high availability is a must. There is no way around it – if your website or service is not available, then most probably you are losing money. It could relate directly to money loss – your customers cannot access your e-commerce service and they cannot spend their money (in addition, they are likely to use your competitors instead). Or it can be less directly linked – your sales reps cannot reach your web-based CRM system and that seriously limits their productivity. No matter how, a website which cannot be reached can be more or less serious for any organization. The question is – how do we ensure that your website will stay available? Assuming you are using MySQL or MariaDB (not unlikely, if it is a website), one of the technologies that can be utilized is Galera Cluster. In this blog post, we’ll show you how to leverage a high availability database to improve the availability of your site.
High Availability is Hard with Databases
Every website is different, but in general, we’ll see some frontend webservers, a database backend, load balancers, file system storage and additional components like caching systems. To make a website highly available, we would need each component to be highly available so we do not have any single point of failure (SPOF).
The webserver tier is usually relatively easy to scale, as it is possible to deploy multiple instances behind a load balancer. If you would want to preserve session state across all webservers, one would probably store it in a shared database (Memcached, or even MySQL Cluster for a pretty robust alternative). Load balancers can be made highly available (e.g. HAProxy/Keepalived/VIP). There are a number of clustered file systems that can be used for the storage layer, we have previously covered solutions like csync2 with lsyncd, GlusterFS, OCFS2. The database service can be made highly available with e.g. DRBD, so all storage is replicated to a standby server. This means the service can be started on another host that has access to the database files.
This might not work very well for a high traffic website though, as all webservers will still be hitting the primary database instance. Failover time also can take a while, since you are failing over to a cold standby server and MySQL has to perform crash recovery when starting up.
MySQL master-slave replication is another option, and there are different ways to make it highly available. There are inconveniences though, as not all nodes are the same – you need to ensure to just write to one master and avoid diverging datasets across the nodes.
Galera Cluster for MySQL/MariaDB
Let’s start with discussing what Galera Cluster is and what it is not. It is a virtually synchronous, multi-master cluster. You can access any of the nodes and issue reads and writes – this is a significant improvement compared to replication setups – no need for failovers and master promotions, if one node is down, usually you can just connect to another node and execute queries. Galera provides a self-healing mechanism through state transfers – State Snapshot Transfer (SST) and Incremental State Transfer (IST). What it means is that when a node joins a cluster, Galera will attempt to bring it back to sync. It may just copy missing data from other node’s gcache (IST) or, if none of nodes contain data in its gcache, it will copy all of the contents of one of nodes to the joining node (via SST). This also makes it very easy for a Galera Cluster to recover even from serious failure conditions. Galera Cluster is a method to scale reads – you can increase a size of the cluster and you can read from all of the slaves.
On the other hand, you have to keep in mind what Galera is not. Galera is not a solution which implements sharding (like NDB Cluster does) – it does not shard the data automatically, each and every Galera node contains the same full data set, just like a standalone MySQL node. Therefore, Galera is not a solution which can help you scale writes. It can help you squeeze more writes than standard, single-threaded replication as it can utilize multiple writers at once, but as of MySQL 5.7, you can use multithreaded replication for every workload so it’s not the same advantage it used to be. Galera is not a solution which can be left alone – even though it has some auto healing features, it still requires user supervision and it happens pretty often that Galera cannot recover on its own.
Having said that, Galera Cluster is still a great piece of software, which can be utilized to build highly available clusters. In the next section we’ll show you different deployment patterns for Galera. Before we get there, there is one more very important bit of information that is required to understand why we want to deploy Galera clusters the way we are about to describe – quorum calculations. Galera has a mechanism which prevents split brain scenarios from happening. It detects number of available nodes and checks if there is a quorum available – Galera has to see (50% + 1) nodes to accept traffic. Otherwise it assumes that a split brain happened and it is a part of a minority segment which does not contain current data nor it can accept writes. Ok, now let’s talk about different ways in which you can deploy Galera cluster.
Deploying Galera Cluster
Basic Deployment – Three Node Cluster
The most common way in which Galera cluster is deployed is to use an odd number of nodes and just deploy them. The most basic setup for Galera is a three node cluster. This setup is enough to survive a loss of one node – it still can operate just fine even though its read capacity decreases and it cannot tolerate any more failures. Such setup is very common to be used as an entry level – you can always add more nodes in the future, keeping in mind that you should use an odd number of nodes. We have seen Galera clusters as big as 11 – 13 nodes.
Minimalistic Approach – two nodes + garbd
If you want to do some testing with Galera, you can reduce the cluster size to two nodes. A 2-node cluster does not provide any fault tolerance but we can improve this by leveraging Galera Arbitrator (garbd) – a daemon which can be started on a third node. It will receive all of the Galera traffic and for the purpose of detecting failures and forming a quorum, it acts as a Galera node. Given that garbd doesn’t need to apply writesets (it just accepts them, no further action is taken), it doesn’t require beefy hardware, like database nodes would need. This reduce the cost of hardware that’s needed to build the cluster.
One Step Further – Add Asynchronous Slave
At any point you can extend your Galera cluster by adding one or more asynchronous slaves. Ideally, your Galera cluster has GTID enabled – it makes adding and reslaving slaves so much easier. Even if not, it is still possible to create a slave, although replication is much less likely to survive a crash of the “master” galera node. Such asynchronous slave can be used for a variety of reasons. It can be used as a backup host – run your backups on it to minimize the impact on Galera cluster. It can also be used for heavier, OLAP queries – again, to remove load from the Galera cluster. Another reason why you may want to use asynchronous slave is to build a Disaster Recovery environment – set it up in a separate datacenter and, in case the location of your Galera Cluster would go up in flames, you will still have a copy of your data in a safe location.
Multi-Datacenter Galera Clusters
If you really care about availability of your data, you can improve it by spanning your Galera cluster across multiple datacenters. Galera can be used across the WAN – some reconfiguration may be needed to make it better adapted to higher latency of WAN connections but it is totally suitable to work in such environment. The only blocker would be if your application frequently modifies a very small subset of rows – this could significantly reduce number of queries per second it will be able to execute.
When talking about WAN-spanning Galera clusters it is important to mention segments. Segments are used in Galera to differentiate the nodes of the cluster which are collocated in the same DC. For example, you may want to configure all nodes in the datacenter “A” to use segment 1 and all nodes in the datacenter “B” to use segment 2. We won’t go into details here (we covered this bit extensively in one of our posts) but in short, using segments reduce inter-segment communication – something you definitely want if segments are connected using WAN.
Another important aspect of building a highly available Galera Cluster over multiple datacenters is to use an odd number of datacenters. Two is not enough to build a setup which would automatically tolerate a loss of a datacenter. Let’s analyze following setup.
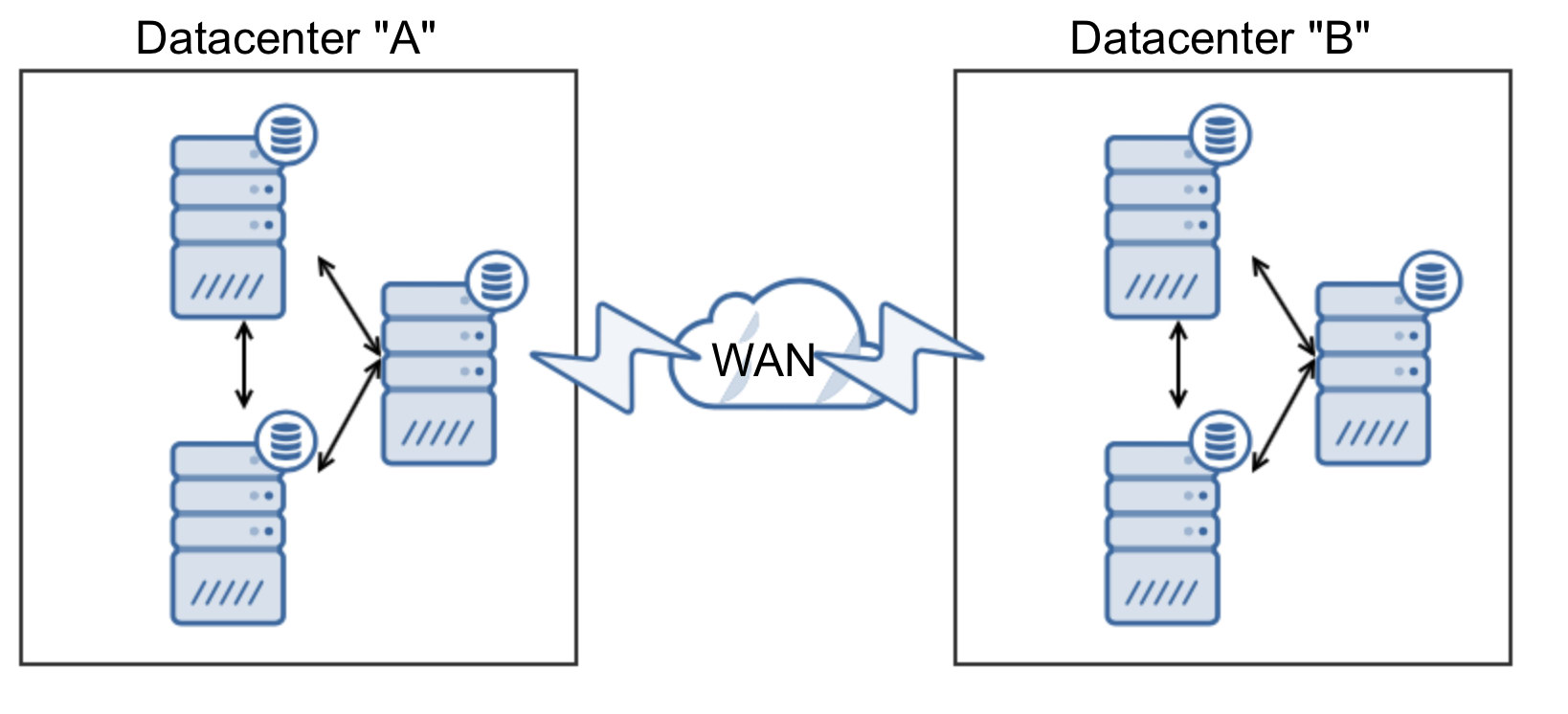
As we mentioned earlier, Galera requires a quorum to operate. Let’s see what would happen if one datacenter is not available:
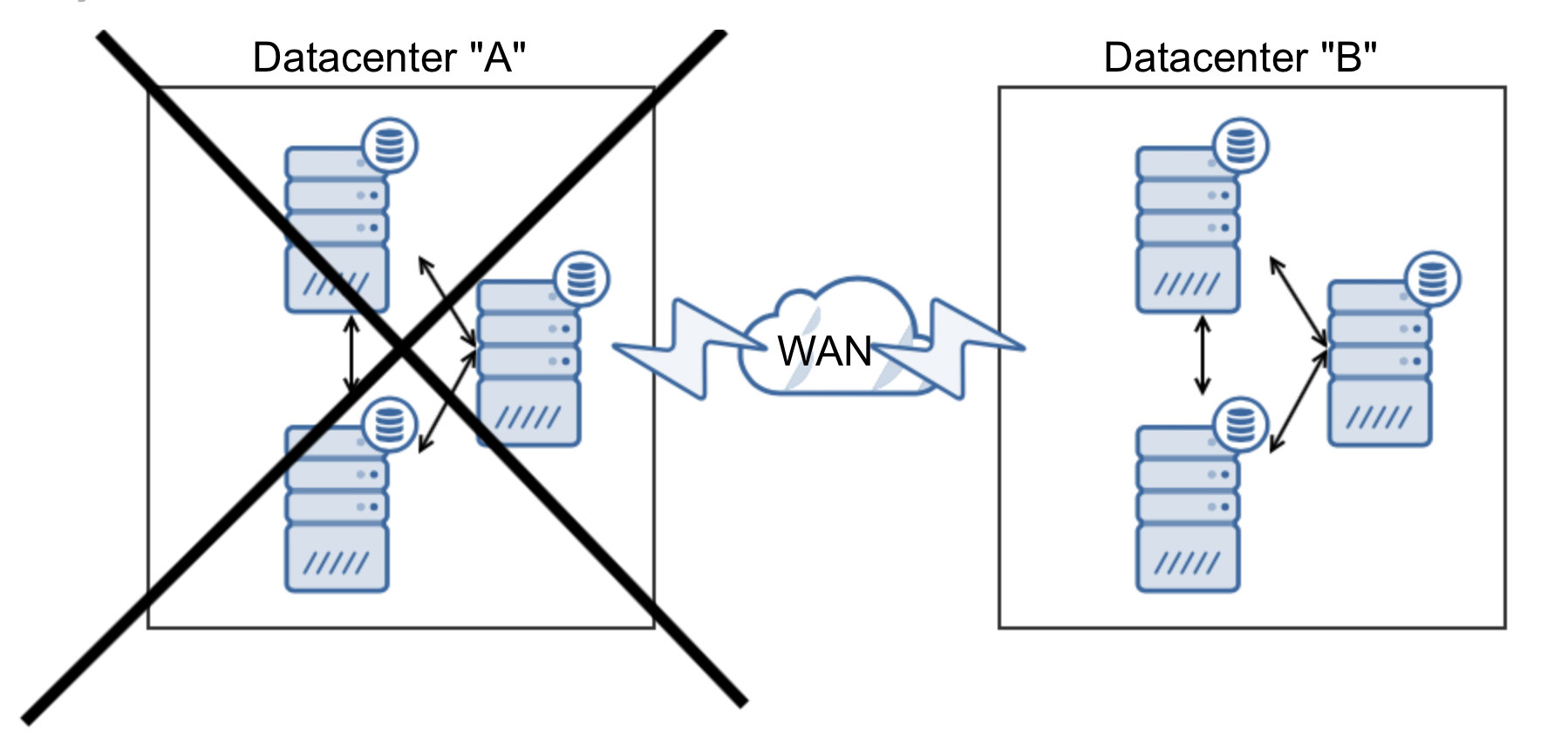
As you can clearly see, we ended up with 3 nodes up, so 50% only – not enough to form a quorum. Manual action is required to assess the situation and promote the remaining part of the cluster to form a “Primary Component” – this requires time and it prolongs downtime.
Let’s take a look at another option:
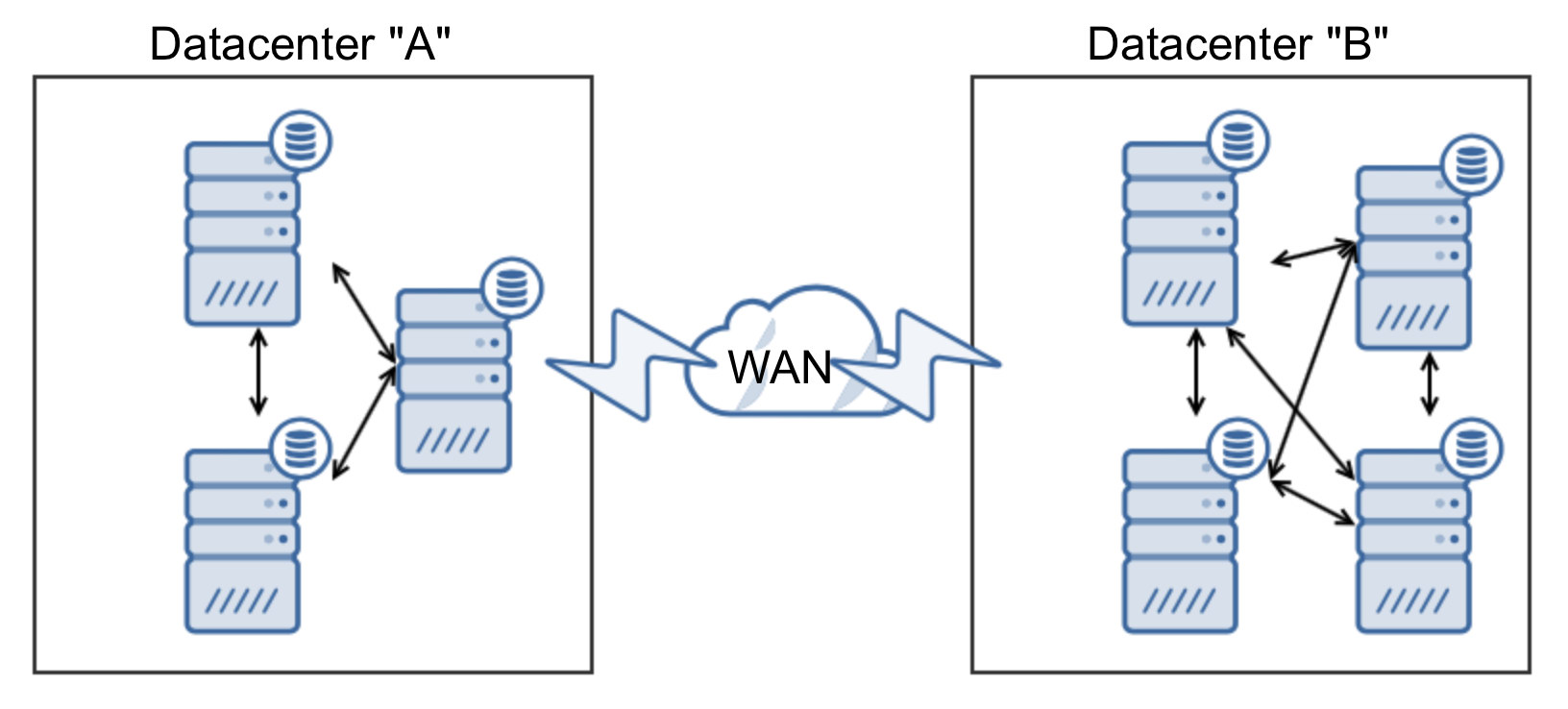
In this case we added one more node to the datacenter “B” to make sure it will take over the traffic when DC “A” is down. But what would happen if DC “B” goes down?
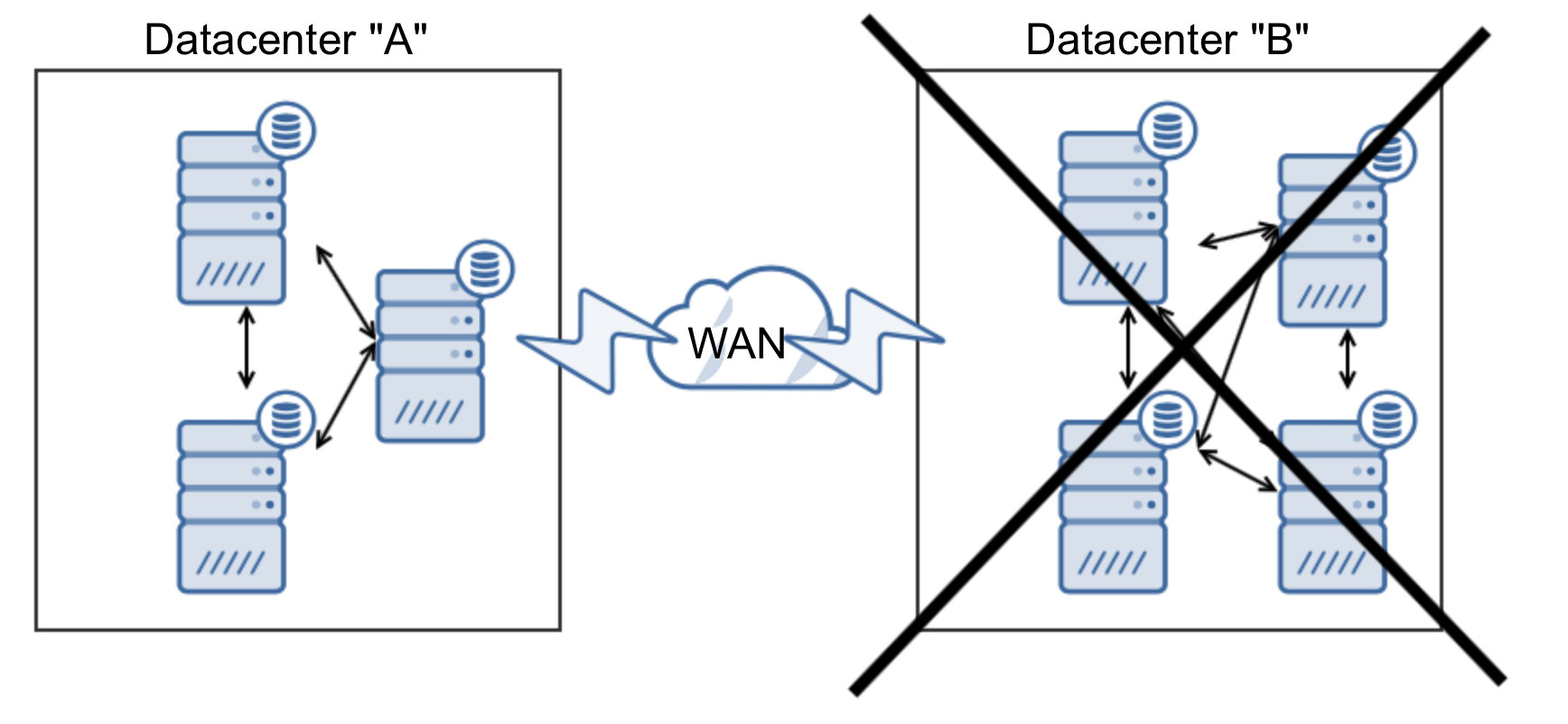
We have three nodes out of seven, less than 50%. The only way is to use a third datacenter. You can, of course, use one more segment of three nodes (or more, it’s important to have the same number of nodes in each datacenter) but you can minimize costs by utilizing Galera Arbitrator:
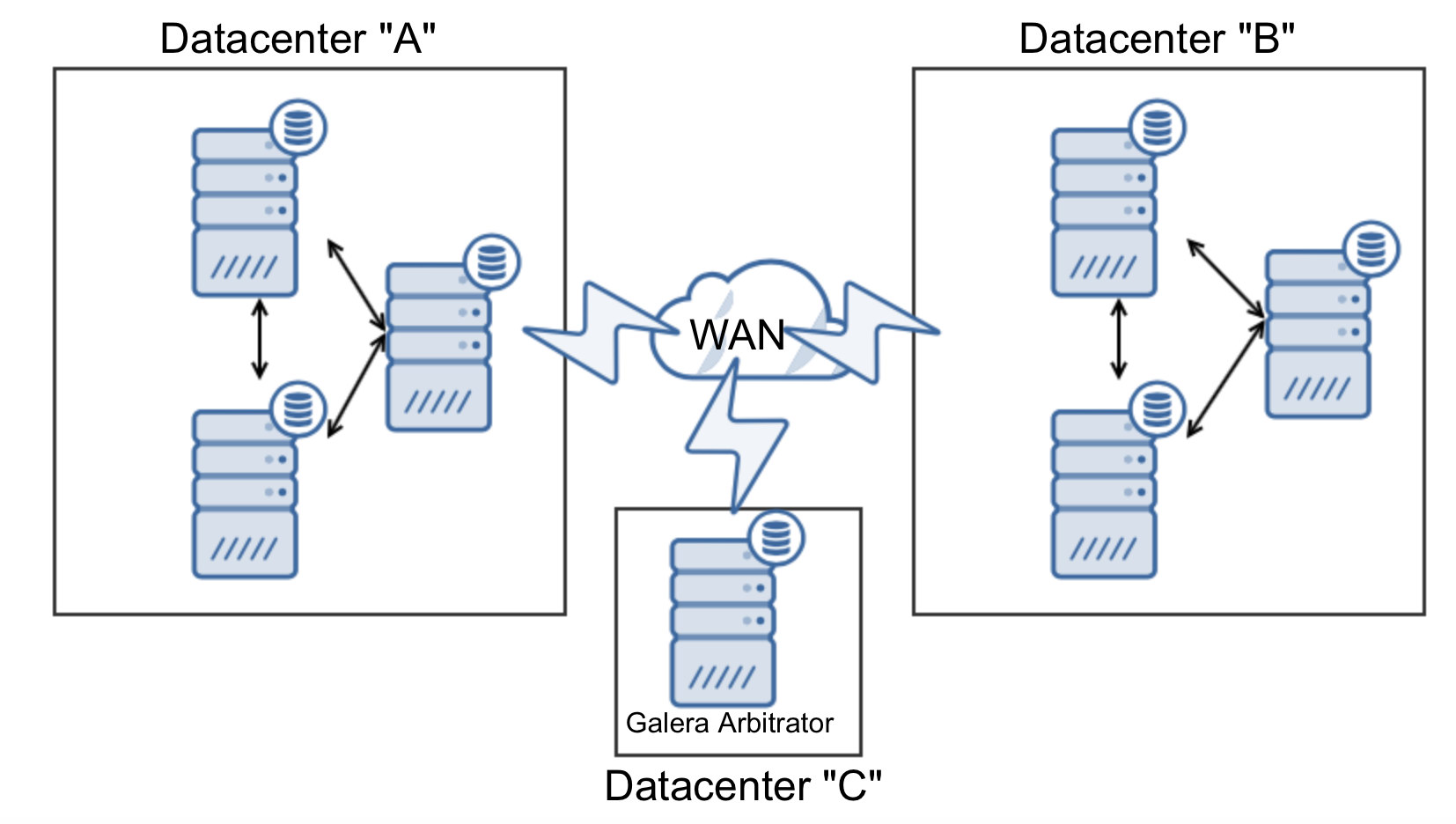
In this case, no matter which datacenter will stop operating, as long as it will be only one of them, with garbd we have a quorum:
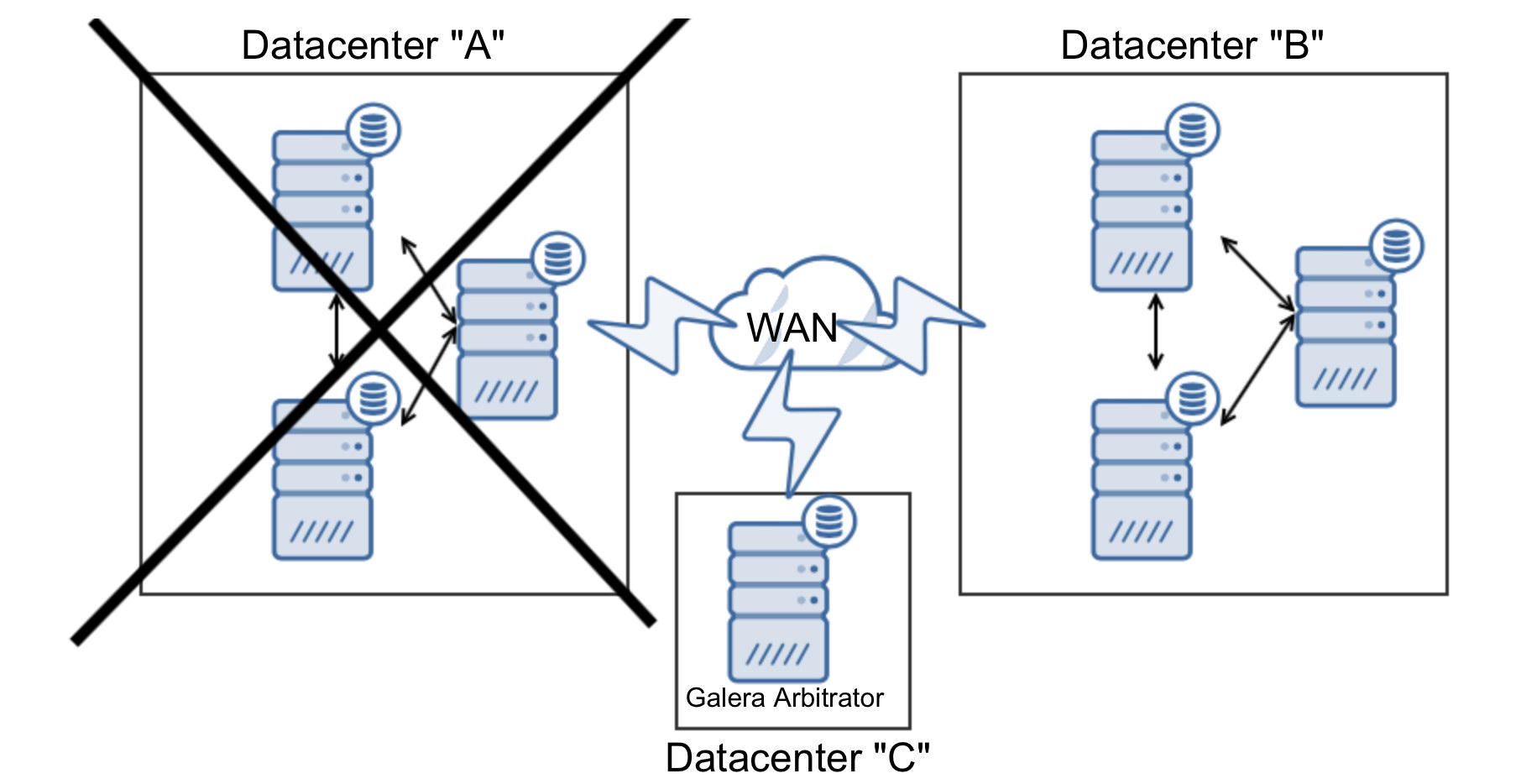
In our example it is: seven nodes in total, three down, four (3 + garbd) up – enough to form a quorum.
Multiple Galera Clusters Connected Using Asynchronous Replication
We mentioned that you can deploy an asynchronous slave to Galera cluster and use it, for example, as a DR host. You also have to keep in mind that Galera cluster, to some extent, can be treated as a single MySQL instance. This means there’s no reason why you couldn’t connect two separate Galera clusters using asynchronous replication. Such setup is pretty common. Again, as with regular slaves, it’s better to have GTID because it allows you to quickly reslave your “standby” Galera cluster to another Galera node in the “active” cluster. Without GTID this is also possible but it’s so much more time-consuming and error-prone. Of course, such setup does work together as the multi-DC Galera cluster would – there’s no automated recovery of the replication link between datacenters, there’s no automated reslaving if a “master” Galera node goes down. You may need to build your own tools to automate this process.
Proxy Layer
There is no high availability without a proxy layer (unless you have built-in HA in your application). Static connections to a single host does not scale. What you need is a middleman – something that will sit between your application and your database tier and mask the complexity of your database setup. Ideally, your application will have just a single point of access to your databases – connect to a given host and port – that’s it.
You can choose between different proxies – HAProxy, MaxScale, ProxySQL – all of them can work with Galera Cluster. Some of them, though, may require additional configuration – you need to know what and how it needs to be done. Additionally, it’s extremely important so you won’t end up with a proxy as a single point of failure. Each of those proxies can be deployed in a highly available fashion, and you will need to have a few components work together.
How ClusterControl can Help you to Build Highly Available Galera Clusters?
ClusterControl can help deploy Galera using all the vendors that are available: Codership, Percona XtraDB Cluster and MariaDB Cluster.
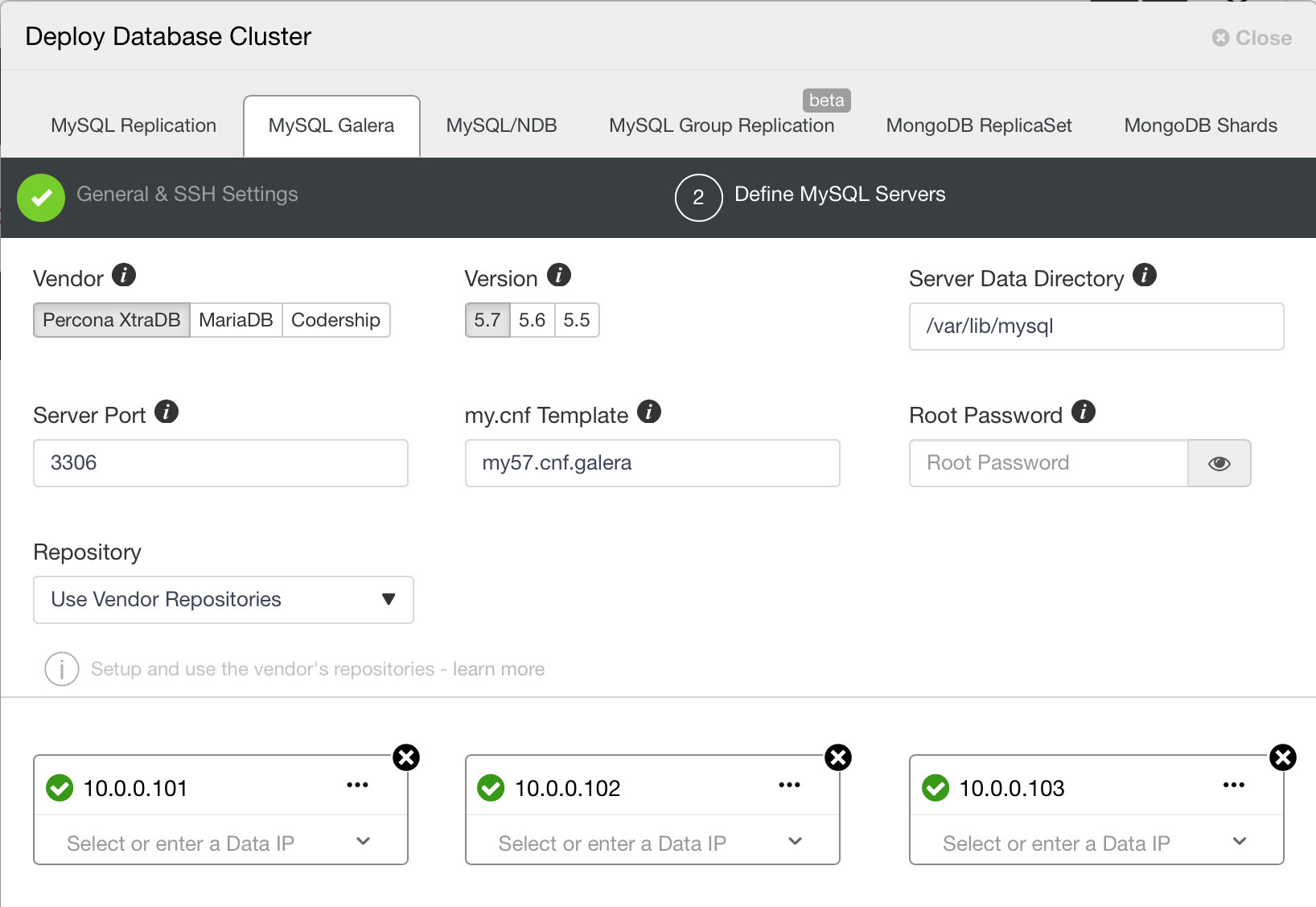
When you deployed a cluster, you can easily scale it up. If needed, you can define different segments for WAN-spanning cluster.
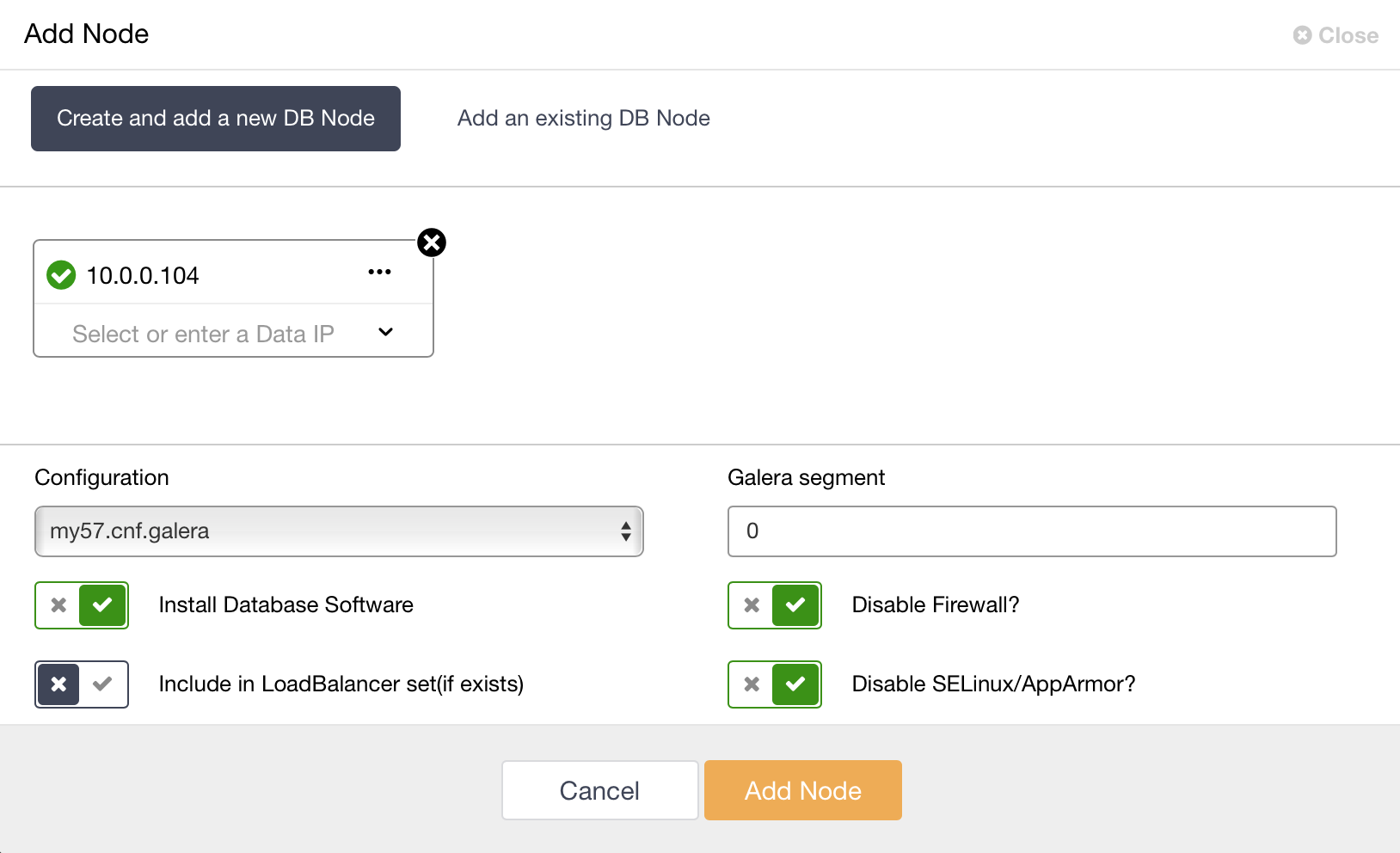
You can also, if you want, deploy an asynchronous slave to the Galera Cluster.
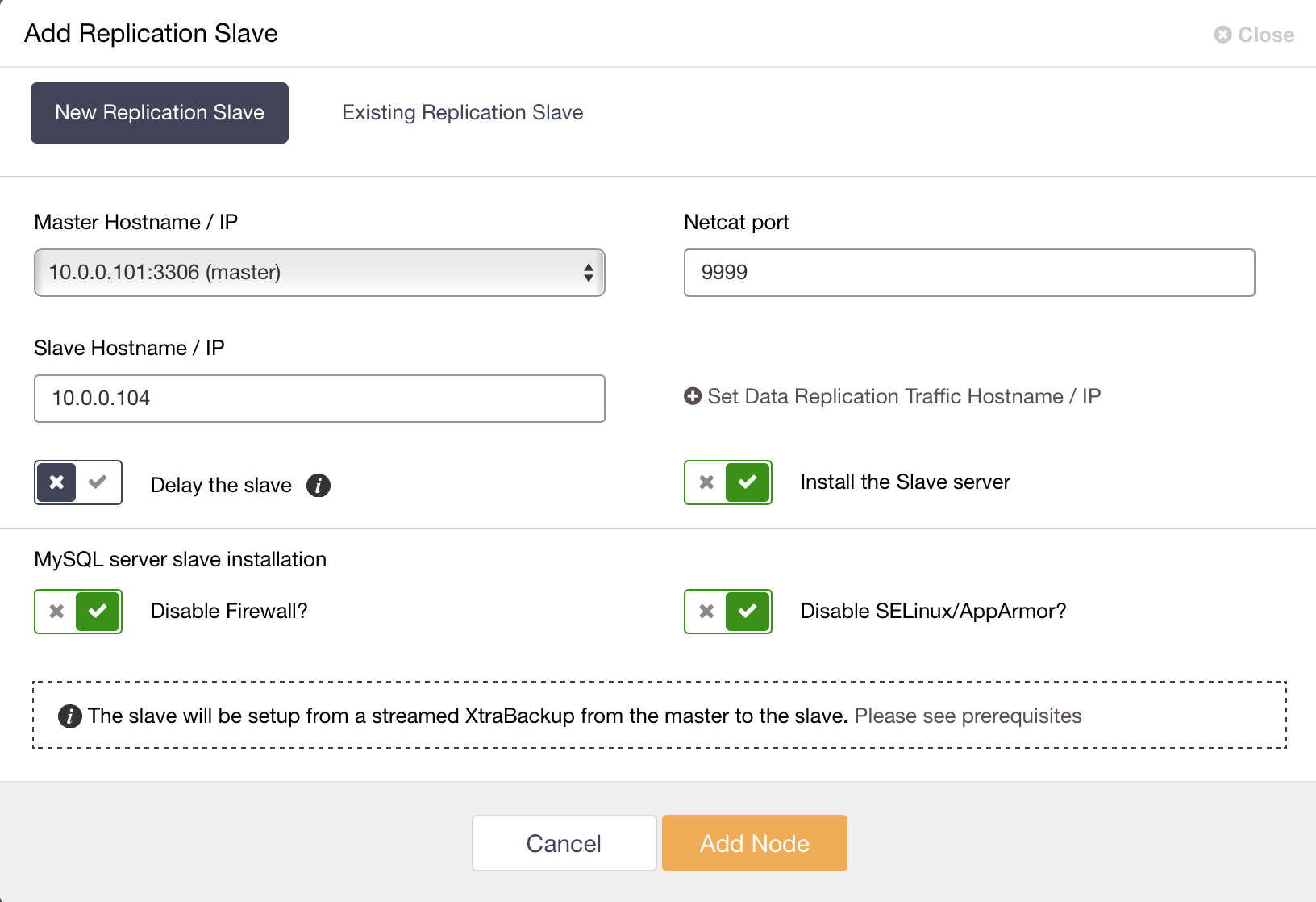
You can use ClusterControl to deploy Galera Arbitrator, which can be very helpful (as we shown previously) in multi-datacenter deployments.
Proxy layer
ClusterControl gives you ability to deploy different proxies with your Galera Cluster. It support deployments of HAProxy, MaxScale and ProxySQL. For HAProxy and ProxySQL, there are additional options to deploy redundant instances with Keepalived and VirtualIP.
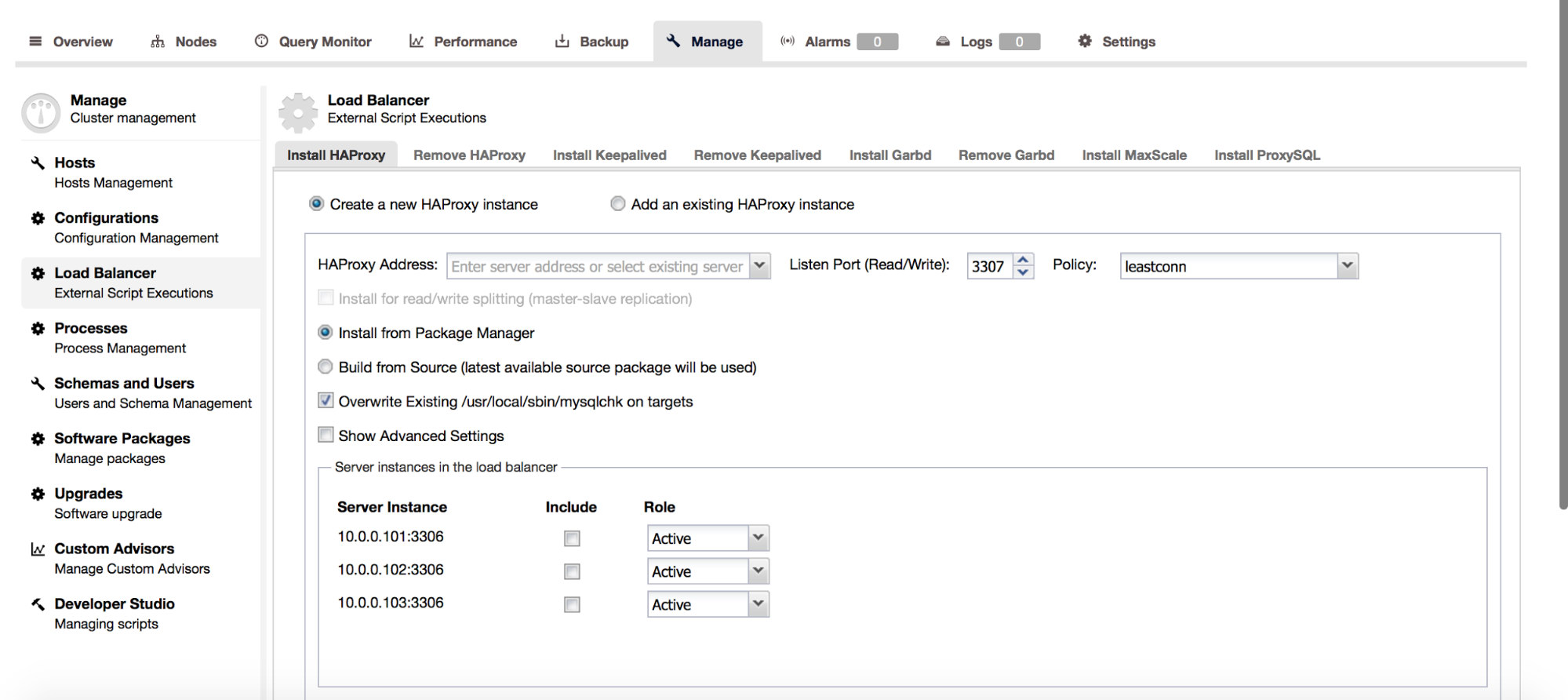
For HAProxy, ClusterControl has a statistics page. You can also set a node to maintenance state:
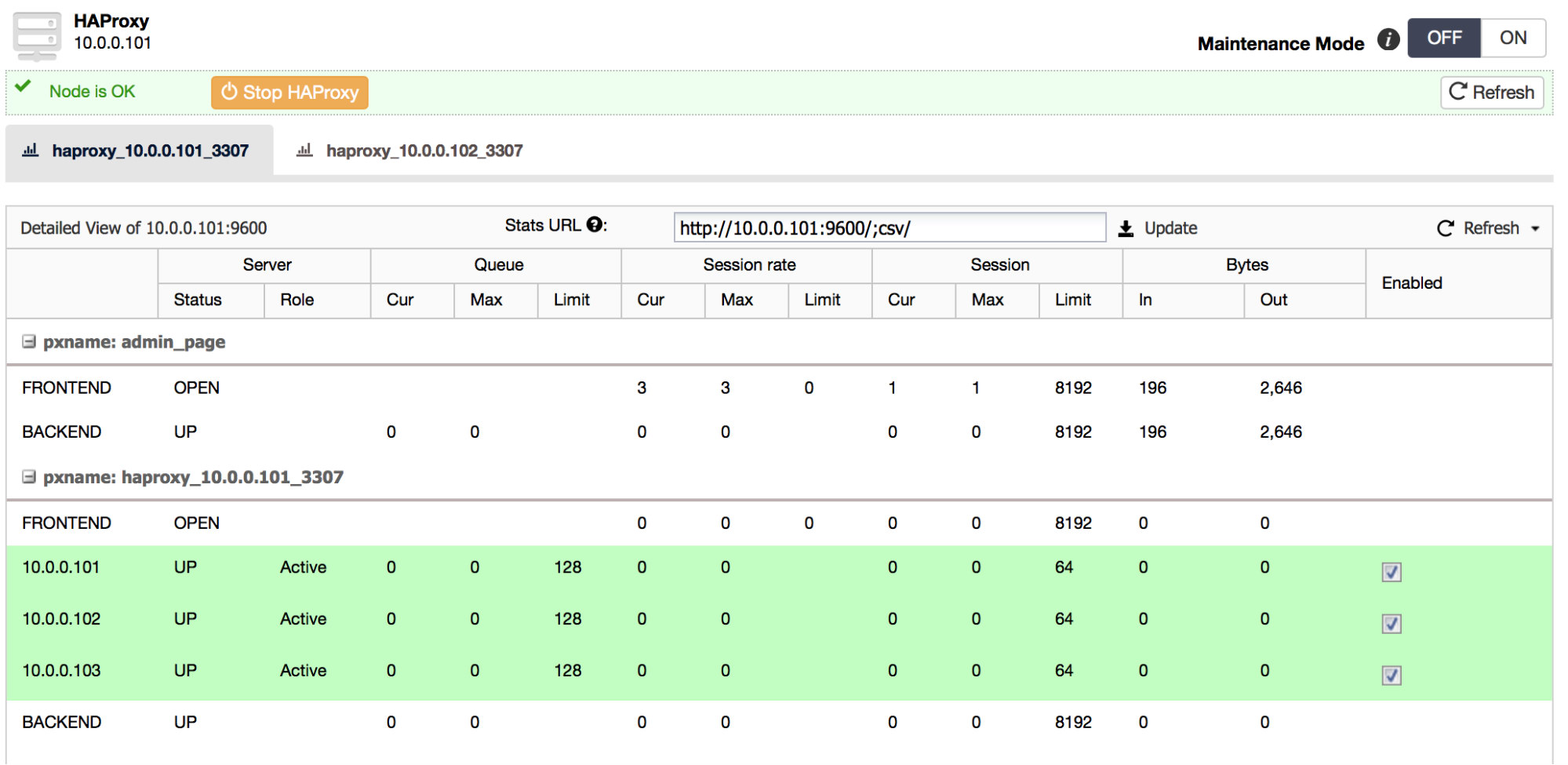
For MaxScale, using ClusterControl, you have access to MaxScale’s CLI and you can perform any actions that are possible from it. Please note we deploy MaxScale version 1.4.3 – more recent versions introduced licensing limitations.
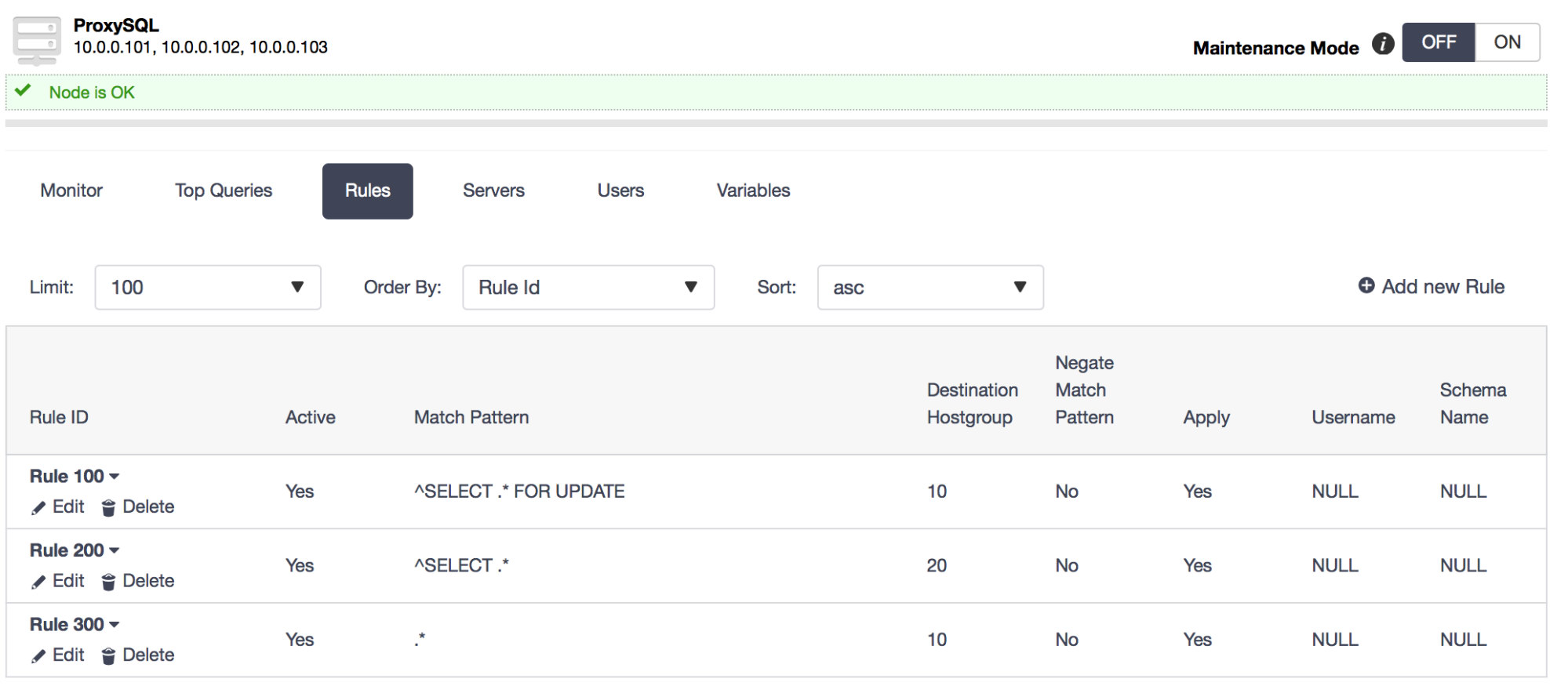
ClusterControl provides quite a bit of functionality for managing ProxySQL, including creating query rules and query caching, including creating query rules and query caching. If you are interested in more details, we encourage you to watch the replay of one of our webinars in which we demoed this UI.
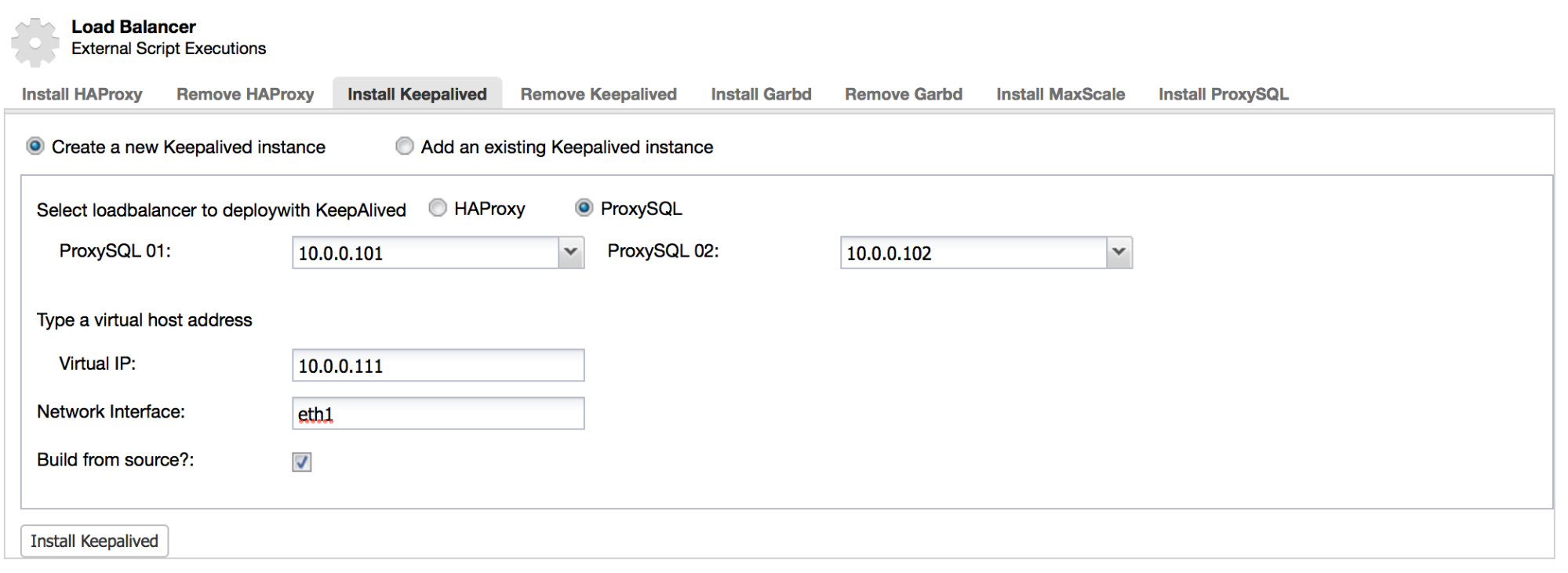
As mentioned previously, ClusterControl can also deploy HAProxy and ProxySQL in a highly available setup. We use virtual IP and Keepalived to track the state of services and perform a failover if needed.
As we have seen in this blog, Galera Cluster can be used in a number of ways to provide high availability of your database, which is a key part of the web infrastructure. You are welcome to download ClusterControl and try the different topologies we discussed above.



